一、基于Consul的自动发现
1、背景
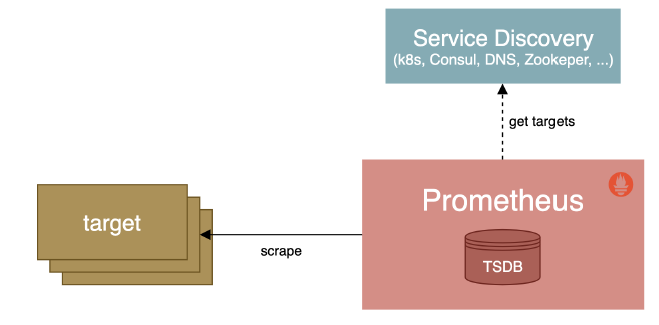
Prometheus配置文件 prometheus-config.yaml 配置了大量的采集规则,基本上都是运维小伙伴手动处理,如果后面增加了节点或者组件信息,就得手动修改此配置,并热加载 promethues;那么能否动态的监听微服务呢?Prometheus 提供了多种动态服务发现的功能,这里以 consul 为例。
官网:Consul Documentation | Consul | HashiCorp Developer
2、基于Consul的自动发现
Consul是分布式k/v数据库,是一个服务注册组件,其他服务都可以注册到consul上,Prometheus也不例外,通过consul的服务发现,我们可以避免在Prometheus中指定大
量的target。
prometheus基于consul的服务发现流程如下:
- 在consul注册服务或注销服务(监控targets)
- Prometheus一直监视consul服务,当发现consul中符合要求的服务有新变化就会更新Prometheus监控对象
3、Prometheus支持的多种服务发现机制
Prometheus数据源的配置主要分为 静态配置 和 动态发现 , 常用的为以下几类:
- static_configs: #静态服务发现
- file_sd_configs: #文件服务发现
- dns_sd_configs: DNS #服务发现
- kubernetes_sd_configs: #Kubernetes 服务发现
- consul_sd_configs: Consul #服务发现
在监控kubernetes的应用场景中,频繁更新pod,svc等资源配置应该是最能体现Prometheus监控目标自动发现服务的好处
4、工作原理
- Prometheus通过Consul API查询Consul的KV存储中保存的配置信息,然后从中获取关于服务的元数据;
- Prometheus使用这些信息来构造目标服务的URL,并将其添加到服务发现的目标列表中。
- 当服务被注销或不可用时,Prometheus将自动从其目标列表中删除该服务。
5、容器化Consul集群
测试验证,不可作为线上使用。线上一定要基于集群的方式做整体的部署验证,并做服务进程的守护及监控
创建一个只有一个节点的consul集群
[root@master-1-230 7.5]# docker run -id -expose=[8300,8301,8302,8500,8600] --restart always -p 18300:8300 -p 18301:8301 -p 18302:8302 -p 18500:8500 -p 18600:8600 --name server1 -e 'CONSUL_LOCAL_CONFIG={"skip_leave_on_interrupt": true}' consul:1.15.4 agent -server -bootstrap-expect=1 -node=server1 -bind=0.0.0.0 -client=0.0.0.0 -ui -datacenter dc1
7980ebd262a9d0e322bf81de29fb63769e31637b08ee822d3a22ea6188b6524a
[root@master-1-230 7.5]# docker ps|grep consul
7980ebd262a9 consul:1.15.4 "docker-entrypoint.s…" 35 seconds ago Up 35 seconds 8301-8302/udp, 8600/udp, 0.0.0.0:18300->8300/tcp, :::18300->8300/tcp, 0.0.0.0:18301->8301/tcp, :::18301->8301/tcp, 0.0.0.0:18302->8302/tcp, :::18302->8302/tcp, 0.0.0.0:18500->8500/tcp, :::18500->8500/tcp, 0.0.0.0:18600->8600/tcp, :::18600->8600/tcp server1参数说明:
-expose:暴露出出来的端口,即consul启动所需的端口:8300,8301,8302,8500,8600
--restart:always表示容器挂了就自动重启
-p:建立宿主机与容器的端口映射
--name:容器名称
-e:环境变量,这里用于对consul进行配置
consul:这是consul镜像名,不是consul命令
agent:容器中执行的命令,各参数含义:
-server:表示节点是server类型
-bootstrap-expect:表示集群中有几个server节点后开始选举leader,既然是单节点集群,那自然就是1了
-node:节点名称
-bind:集群内部通信地址,默认是0.0.0.0
-client:客户端地址,默认是127.0.0.1
-ui:启用consul的web页面管理
-datacenter:数据中心验证:
可通过web端访问,例如:http://192.168.1.230:18500
[root@master-1-230 7.5]# curl http://192.168.1.230:18500
<a href="/ui/">Moved Permanently</a>.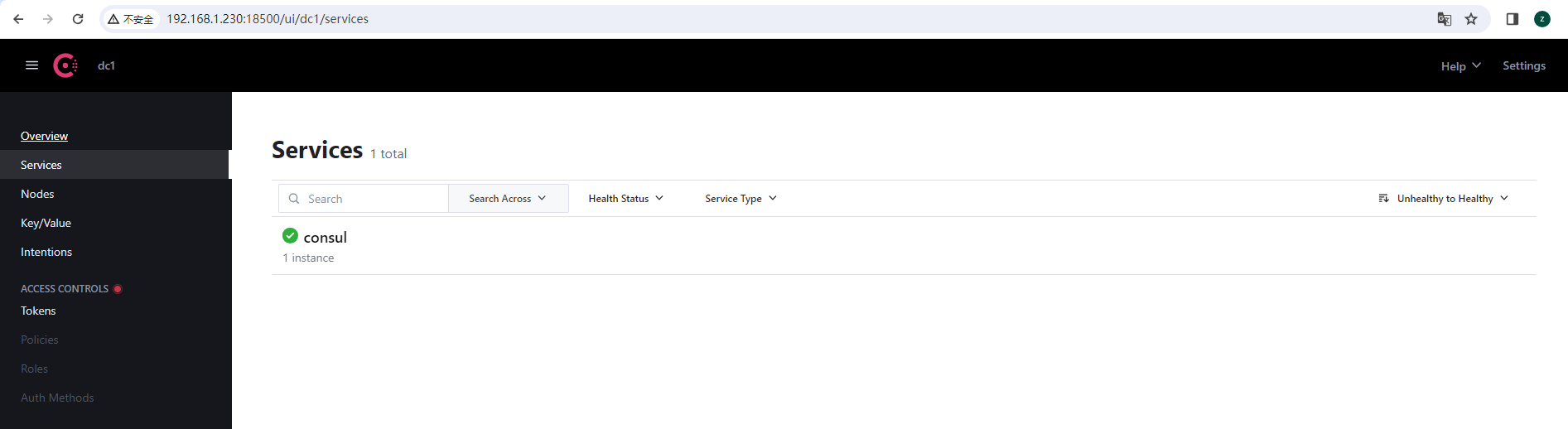
6、注册主机到Consul
例如:将某台虚拟机上的node-exporter注册到consul
添加:
## 格式
$ curl -X PUT -d '{"id": "'${host_name}'","name": "node-exporter","address": "'${host_addr}'","port":9100,"tags": ["dam"],"checks": [{"http": "http://'${host_addr}':9100/","interval": "5s"}]}' http://192.168.1.230:18500/v1/agent/service/register
## 示例
$ curl -X PUT -d '{"id": "sh-middler2","name": "node-exporter","address": "192.10.192.134","port":9100,"tags": ["middleware"],"checks": [{"http": "http://192.10.192.134:9100/metrics","interval": "3s"}]}' http://192.168.1.230:18500/v1/agent/service/register
## 参数说明
id : 注册ID 在consul中为唯一标识
name :Service名称
address:自动注册绑定ip
port:自动注册绑定端口
tags:注册标签,可多个
checks : 健康检查
http: 检查数据来源
interval: 检查时间间隔
http://192.168.1.230:18500/v1/agent/service/register consul注册接口删除:
## 格式
$ curl -X PUT http://192.168.1.230:18500/v1/agent/service/deregister/${id}
## 示例
[root@master-1-230 7.5]# curl -X PUT http://192.168.1.230:18500/v1/agent/service/deregister/sh-middler2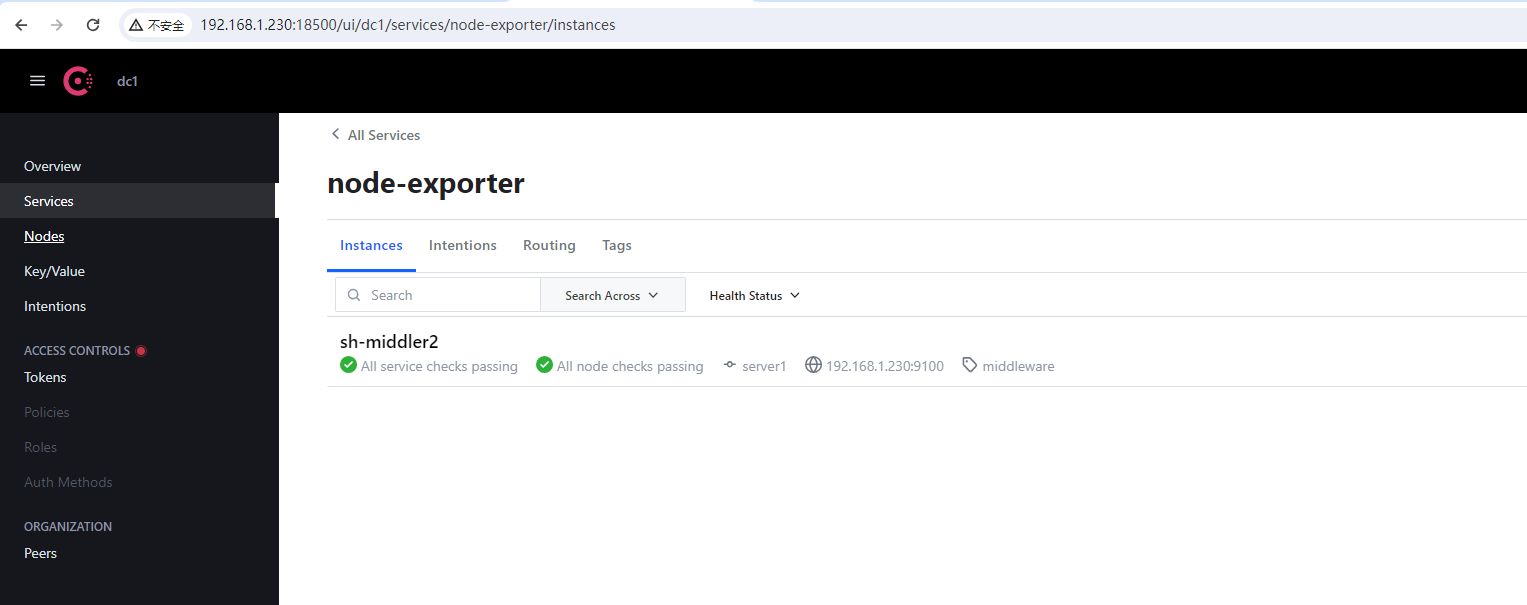
7、Prometheus配置实现自动发现服务
prometheus-config.yaml
- job_name: consul
honor_labels: true
metrics_path: /metrics
scheme: http
consul_sd_configs: #基于consul服务发现的配置
- server: 192.168.1.230:18500 #consul的监听地址
services: [] #匹配consul中所有的service
relabel_configs: #relabel_configs下面都是重写标签相关配置
- source_labels: ['__meta_consul_tags'] #将__meta_consul_tags标签的至赋值给product
target_label: 'servername'
- source_labels: ['__meta_consul_dc'] #将__meta_consul_dc的值赋值给idc
target_label: 'idc'
- source_labels: ['__meta_consul_service']
regex: "consul" #匹配为"consul"的service
action: drop #执行的动作为删除 按上面方法重载 Prometheus,打开 Prometheus 的 Target 页面,就会看到 上面定义的 consul 任务
curl -XPOST http://prometheus.ikubernetes.cloud/-/reload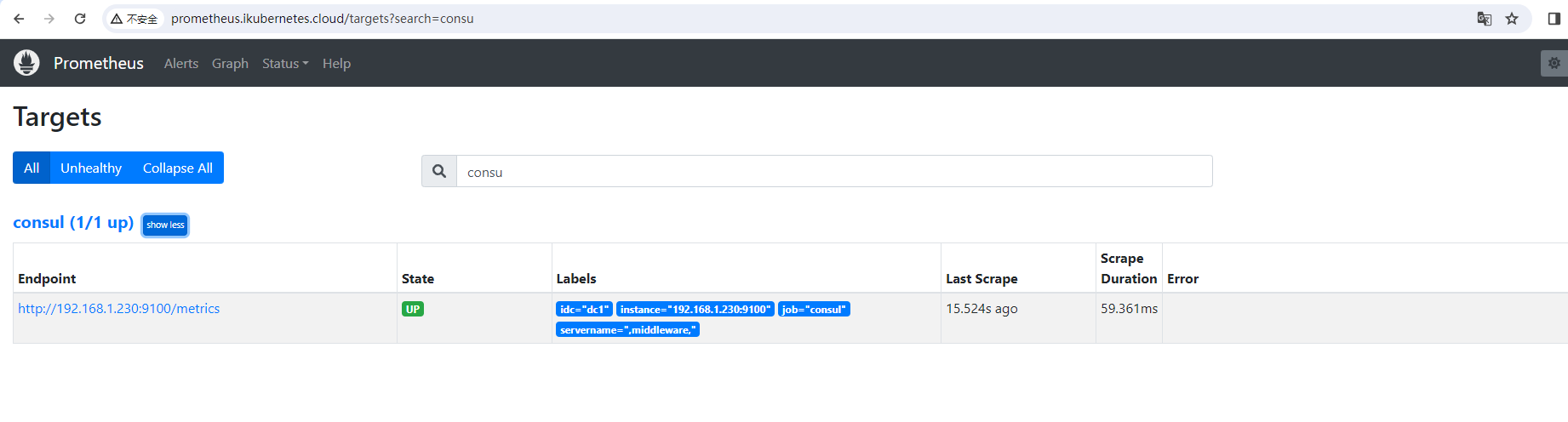
二、告警平台部署管理(上)
1、AlertManger 简介
1.1 AlertManger 常用功能
- 抑制:指的是当某一告警信息发送后,可以停止由此告警引发的其它告警,避免相同的告警信息重复发送。
- 静默:静默也是一种机制,指的是依据设置的标签,对告警行为进行静默处理。
- 发送告警:支持配置多种告警规则,可以根据不同的路由配置,采用不同的告警方式发送告警通知。
- 告警分组:分组机制可以将详细的告警信息合并成一个通知。
1.2 Prometheus 和AlertManager的关系
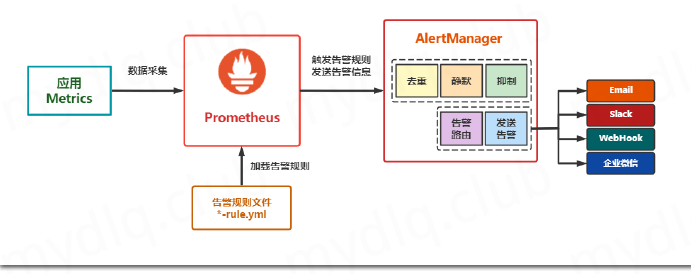
2、部署搭建AlertManager
2.1 创建AlertManager 数据的存储PVC资源 alertmanager-storage.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager-pvc
namespace: monitor
spec:
accessModes:
- ReadWriteMany
storageClassName: "nfs-storageclass"
resources:
requests:
storage: 5Gi应用yaml文件
[root@master-1-230 7.6]# kubectl apply -f alertmanager-storage.yaml
persistentvolumeclaim/alertmanager-pvc created2.2 创建AlertManager 配置文件ConfigMap(邮件方式)
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: monitor
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.163.com:465' # 邮箱服务器的SMTP主机配置
smtp_from: 'xxxx@163.com' # 发送邮件主题
smtp_auth_username: 'xxxxxx@163.com' # 登录用户名
smtp_auth_password: '123456' # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是企微邮箱,仅做测试,不需要开启此功能。
templates:
- '/etc/alertmanager/*.tmpl'
route:
group_by: ['env','instance','type','group','job','alertname','cluster'] # 报警分组
group_wait: 5s # 在组内等待所配置的时间,如果同组内,5秒内出现相同报警,在一个组内出现。
group_interval: 1m # 如果组内内容不变化,合并为一条警报信息,2m后发送。
repeat_interval: 2m # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
receiver: 'email'
routes:
- receiver: 'devops'
match:
severity: critical22
group_wait: 5s
group_interval: 5m
repeat_interval: 30m
receivers:
- name: 'email'
email_configs:
- to: 'zhdya@qq.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'devops'
email_configs:
- to: 'aaa@163.com,bbb@qq.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
inhibit_rules: # 抑制规则
- source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 servrity: 'critical'
severity: 'critical'
target_match:
severity: 'warning' # 目标标签值正则匹配,可以是正则表达式如: ".*MySQL.*"
equal: ['alertname', 'dev', 'instance'] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。
wechat.tmpl: |-
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 告警恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
email.tmpl: |-
{{ define "email.from" }}xxx.com{{ end }}
{{ define "email.to" }}xxx.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
========= 监控报警 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
========= 告警恢复 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- end }}参数说明:
global:
resolve_timeout: 5m ##超时,默认5min
smtp_smarthost: 'smtp.exmail.qq.com:25'
smtp_from: 'xxxxxxx'
smtp_auth_username: 'xxxx'
smtp_auth_password: '123'
smtp_require_tls: false
templates: ##告警模板(可定义多个)
- '/etc/alertmanager/*.tmpl'
##route:用来设置报警的分发策略。Prometheus的告警先是到达alertmanager的根路由(route),alertmanager的根路由不能包含任何匹配项,因为根路由是所有告警的入口点
##另外,根路由需要配置一个接收器(receiver),用来处理那些没有匹配到任何子路由的告警(如果没有配置子路由,则全部由根路由发送告警),即缺省
##接收器。告警进入到根route后开始遍历子route节点,如果匹配到,则将告警发送到该子route定义的receiver中,然后就停止匹配了。因为在route中
##continue默认为false,如果continue为true,则告警会继续进行后续子route匹配。如果当前告警仍匹配不到任何的子route,则该告警将从其上一级(
##匹配)route或者根route发出(按最后匹配到的规则发出邮件)。查看你的告警路由树,https://www.prometheus.io/webtools/alerting/routing-tree-editor/,
##将alertmanager.yml配置文件复制到对话框,然后点击"Draw Routing Tree"
route:
group_by: ['env','instance','type','group','job','alertname','cluster'] ##用于分组聚合,对告警通知按标签(label)进行分组,将具有相同标签或相同告警名称(alertname)的告警通知聚合在一个组,然后作为一个通知发送。如果想完全禁用聚合,可以设置为group_by: [...]
group_wait: 10s ##当一个新的告警组被创建时,需要等待'group_wait'后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送
group_interval: 2m ##当第一次告警通知发出后,在新的评估周期内又收到了该分组最新的告警,则需等待'group_interval'时间后,开始发送为该组触发的新告警,可以简单理解为,group就相当于一个通道(channel)
repeat_interval: 10m ##告警通知成功发送后,若问题一直未恢复,需再次重复发送的间隔(根据实际情况来调整)
receiver: 'email' ##配置告警消息接收者,与下面配置的对应,例如常用的 email、wechat、slack、webhook 等消息通知方式。
routes: ##子路由
- receiver: 'wechat'
match: ##通过标签去匹配这次告警是否符合这个路由节点;也可以使用match_re进行正则匹配
severity: error ##标签severity为error时满足条件使用wechat警报
continue: true ##匹配到这个路由后是否继续匹配,默认flase
receivers: ##配置报警信息接收者信息
- name: 'email' ##警报接收者名称
email_configs:
- to: 'xxxxxx' ##接收警报的email(可引用模板文件中定义的变量),可定义多个
## html: '{{ template "email.to.html" .}}' ##发送邮件的内容(调用模板文件中的)
helo: 'alertmanager.com' #alertmanager的地址
send_resolved: true #故障恢复后通知
- name: 'wechat'
wechat_configs:
- corp_id: xxxxxxxxx ##企业信息
to_user: '@all' ##发送给企业微信用户的ID,这里是所有人
agent_id: xxxxx ##企业微信AgentId
api_secret: xxxxxxxxx ##企业微信Secret
## message: '{{ template "wechat.default.message" .}}' ##发送内容(调用模板里面的微信模板)
send_resolved: true ##故障恢复后通知
inhibit_rules: ##抑制规则配置,当存在与另一组匹配的警报(源)时,抑制规则将禁用与一组匹配的警报(目标)
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']2.3 创建AlertManager部署文件 alertmanager-deploy.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitor
labels:
k8s-app: alertmanager
spec:
type: ClusterIP
ports:
- name: http
port: 9093
targetPort: 9093
selector:
k8s-app: alertmanager
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
k8s-app: alertmanager
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
template:
metadata:
labels:
k8s-app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:v0.24.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 9093
args:
## 指定容器中AlertManager配置文件存放地址 (Docker容器中的绝对位置)
- "--config.file=/etc/alertmanager/alertmanager.yml"
## 指定AlertManager管理界面地址,用于在发生的告警信息中,附加AlertManager告警信息页面地址
- "--web.external-url=https://alertmanager.ikubernetes.cloud"
## 指定监听的地址及端口
- '--cluster.advertise-address=0.0.0.0:9093'
## 指定数据存储位置 (Docker容器中的绝对位置)
- "--storage.path=/alertmanager"
resources:
limits:
cpu: 1000m
memory: 512Mi
requests:
cpu: 1000m
memory: 512Mi
readinessProbe:
httpGet:
path: /-/ready
port: 9093
initialDelaySeconds: 5
timeoutSeconds: 10
livenessProbe:
httpGet:
path: /-/healthy
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: data
mountPath: /alertmanager
- name: config
mountPath: /etc/alertmanager
- name: configmap-reload
image: jimmidyson/configmap-reload:v0.7.1
args:
- "--volume-dir=/etc/config"
- "--webhook-url=http://localhost:9093/-/reload"
resources:
limits:
cpu: 100m
memory: 100Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/config
readOnly: true
volumes:
- name: data
persistentVolumeClaim:
claimName: alertmanager-pvc
- name: config
configMap:
name: alertmanager-config2.4 创建AlertManager外部服务暴露 alertmanager-ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: monitor
name: alertmanager-ingress
spec:
ingressClassName: nginx
rules:
- host: alertmanager.ikubernetes.cloud
http:
paths:
- pathType: Prefix
backend:
service:
name: alertmanager
port:
number: 9093
path: /验证:
[root@master-1-230 7.6]# kubectl get ingress -n monitor
NAME CLASS HOSTS ADDRESS PORTS AGE
alertmanager-ingress nginx alertmanager.ikubernetes.cloud 192.168.1.204 80 3m25s
prometheus-ingress nginx prometheus.ikubernetes.cloud 192.168.1.204 80 14h
[root@master-1-230 7.6]# curl http://alertmanager.ikubernetes.cloud
三、告警平台部署管理(下)
3、AlertManager 的三个核心概念
3.1 分组
被触发的警报合并为一个警报进行通知,避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位。
场景:在Kubernetes集群中,运行着重量级规模的实例,即便是集群中持续很小一段时间的网络延迟或者延迟导致网络抖动,也会引发大量类似服务应用无法连接 DB 的故障。如果在警报规则中定义每一个应用实例都发送警报,那么到最后的结果就是会有大量的警报信息通过Alertmanager发送给咱们的运维及研发小伙伴。
3.2 抑制
Inhibition 是 当某条警报已经发送,停止重复发送由此警报引发的其他异常或故障的警报机制。
场景:在我们的灾备体系中,当原有集群故障宕机业务彻底无法访问的时候,会把用户流量切换到备份集群中,这样为故障集群及其提供的各个微服务状态发送警报机会失去了意义,此时, Alertmanager 的抑制特性就可以在一定程度上避免管理员收到过多无用的警报通知。
3.3 静默
Silences 提供了一个简单的机制,根据标签快速对警报进行静默处理;对传进来的警报进行匹配检查,如果接受到警报符合静默的配置,Alertmanager 则不会发送警报通知。
场景:
- 用于解决严重生产故障问题时,因所花费的时间过长,通过静默设置避免接收到过多的无用通知;
- 在已知的例行维护中,为了防止对例行维护的机器发送不必要的警报;
4、Prometheus添加告警配置
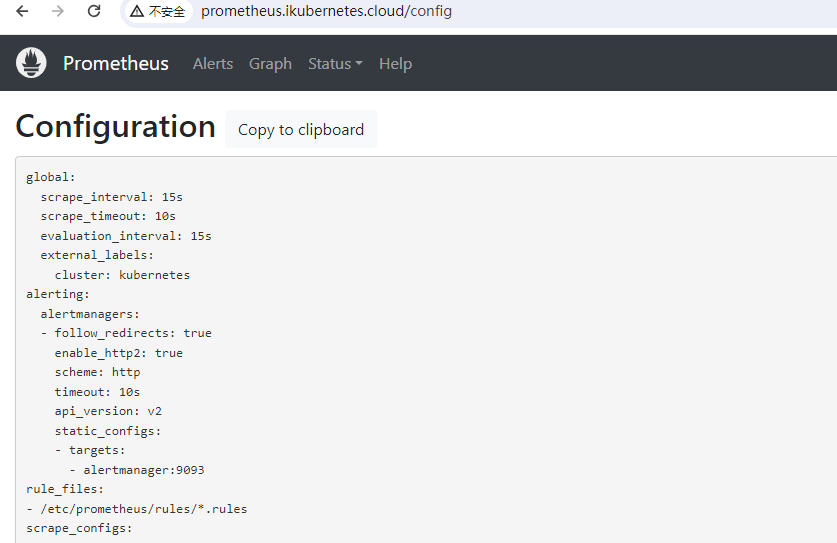
修改ConfigMap资源文件prometheus-config.yaml,改动内容如下:
-
添加AlertManager服务器地址
-
指定告警规则文件路径位置
-
添加Prometheus中触发告警的告警规则(已经简单添加了2条)
修改 prometheus-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
cluster: "kubernetes"
############ 添加配置 Aertmanager 服务器地址 ###################
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
############ 指定告警规则文件路径位置 ###################
rule_files:
- /etc/prometheus/*-rule.yml按上面方法重载 Prometheus
curl -XPOST http://prometheus.ikubernetes.cloud/-/reloadPrometheus UI查看配置和告警规则是否生效
测试告警规则:
[root@master-1-230 ~]# curl -XPOST -H 'Content-Type: application/json' http://alertmanager.ikubernetes.cloud/api/v1/alerts -d '[{"labels":{"severity":"critical22"},"annotations":{"summary":"This is a test alert"}}]'
{"status":"success"}
5、总结:
- 灵活性:Alertmanager提供了灵活的配置选项,允许用户根据自己的需求定义警报规则和接收警报的方式,同时支持多个不同层面的媒介进行告警通知。
- 可视化:Alertmanager提供了丰富的可视化功能,包括交互式控制台和Web界面,使用户可以轻松地查看警报和监控状态,以及管理警报的路由和通知。
- 多功能:通过分组,抑制,静默等多功能。这意味着这款工具可以适配更多的场景,做不同维度的功能释放。
- 与Prometheus的集成:Alertmanager是由Prometheus团队开发的,这意味着它与Prometheus监控系统紧密集成。Alertmanager可以与Prometheus进行无缝协作,从而实现更全面、更高效的监控和警报功能。
四、告警平台高级配置(上)
1、基于企业微信的报警媒介
- 实时告警通知:企业微信/钉钉等即时通信工具能够实现实时的告警通知,使得团队成员能够及时响应和解决问题。
- 通知范围更广:基于企业微信/钉钉的告警通知可以通过群组和@某人的方式,将告警通知发送给更广泛的接收者,避免出现漏报的情况。
- 告警信息更直观:企业微信/钉钉等通信工具提供了更丰富的告警信息呈现方式,例如文本消息、链接、图片、语音等,使得告警信息更加直观和易于理解。
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: monitor
data:
alertmanager.yml: |-
global:
resolve_timeout: 1m
smtp_smarthost: 'smtp.exmail.qq.com:465' # 邮箱服务器的SMTP主机配置
smtp_from: 'xxxxxx@163.com' # 发送邮件主题
smtp_auth_username: 'xxxxxx@163.com' # 登录用户名
smtp_auth_password: '123456' # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是企微邮箱,仅做测试,不需要开启此功能。
templates:
- '/etc/alertmanager/*.tmpl'
route:
group_by: ['env','instance','type','group','job','alertname','cluster']
group_wait: 10s
group_interval: 2m
repeat_interval: 10m
receiver: 'email'
routes:
- receiver: 'wechat'
match:
severity: critical
receivers:
- name: 'email'
email_configs:
- to: 'xxxxxx@163.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'wechat'
wechat_configs:
- corp_id: 'ww18xxxbaeXXXc4'
to_party: '413'
to_user: '@all'
agent_id: 1000035
api_secret: '123-4444-tc'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
wechat.tmpl: |-
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
========= 告警恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
email.tmpl: |-
{{ define "email.from" }}xxx.com{{ end }}
{{ define "email.to" }}xxx.com{{ end }}
{{ define "email.to.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{ range .Alerts }}
========= 监控报警 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{ range .Alerts }}
========= 告警恢复 =========<br>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} <br>
告警类型: {{ .Labels.alertname }} <br>
告警主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
========= = end = =========<br>
{{ end }}{{ end -}}
{{- end }}
测试验证:
[root@master-1-230 ~]# curl -XPOST -H 'Content-Type: application/json' http://alertmanager.ikubernetes.cloud/api/v1/alerts -d '[{"labels":{"severity":"critical"},"annotations":{"summary":"This is a test alert No.002"}}]'
{"status":"success"}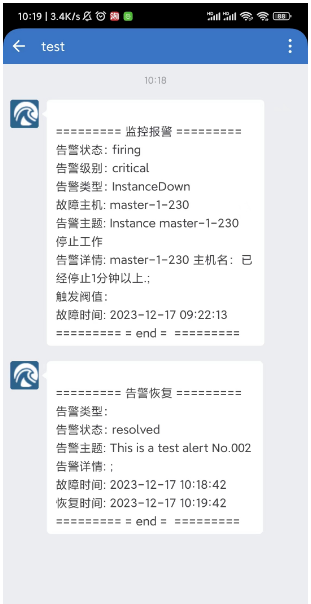
五、告警平台高级配置(下)
基于钉钉的告警媒介:参考:https://www.cnblogs.com/pythonlx/p/17804116.html
钉钉-机器人管理(复制生成webhook)
自定义机器人安全设置 - 钉钉开放平台 (dingtalk.com)
1.1 添加钉钉机器人
在钉钉APP端操作:群--> 设置 --> 智能群助手 -- > 添加机器人

2.1 dingtalk部署配置
cat << EOF > dingtalk-webhook.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: dingtalk
name: webhook-dingtalk
namespace: monitor
spec:
replicas: 1
selector:
matchLabels:
run: dingtalk
template:
metadata:
labels:
run: dingtalk
spec:
containers:
- name: dingtalk
image: timonwong/prometheus-webhook-dingtalk:v1.4.0
imagePullPolicy: IfNotPresent
args:
- --ding.profile=webhook1=https://oapi.dingtalk.com/robot/send?access_token=<替换成你的token>
ports:
- containerPort: 8060
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
run: dingtalk
name: webhook-dingtalk
namespace: monitor
spec:
ports:
- port: 8060
protocol: TCP
targetPort: 8060
selector:
run: dingtalk
sessionAffinity: None
EOF[root@master-1-230 7.8]# kubectl apply -f dingtalk-webhook.yaml
deployment.apps/webhook-dingtalk created
service/webhook-dingtalk created2.2 配置alertmanager 配置文件configmap
route:
group_by: ['env','instance','type','group','job','alertname','cluster']
group_wait: 10s
group_interval: 2m
repeat_interval: 10m
receiver: 'email'
routes:
- receiver: 'wechat'
match:
severity: critical
- receiver: 'webhook' ## 新增告警receiver通道
match:
severity: critical1
receivers:
- name: 'email'
email_configs:
- to: 'zhxxx@163.com'
send_resolved: true
html: '{{ template "email.to.html" . }}'
- name: 'wechat'
wechat_configs:
- corp_id: 'ww187a2xxxaececc4'
to_party: '413'
to_user: '@all'
agent_id: 1000035
api_secret: 'IVRfzG15S6lb5WRCq2-xxxoqFXSnBdY3fyocuDP-tc'
send_resolved: true
- name: 'webhook' ## 配置接收告警的媒介
webhook_configs:
- url: 'http://webhook-dingtalk.monitor.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true[root@master-1-230 7.8]# kubectl apply -f config_map.yaml
configmap/alertmanager-config configured测试验证:
[root@master-1-230 7.8]# curl -XPOST -H 'Content-Type: application/json' http://alertmanager.ikubernetes.cloud/api/v1/alerts -d '[{"labels":{"severity":"critical1"},"annotations":{"summary":"This is a test alert.no001mm"}}]'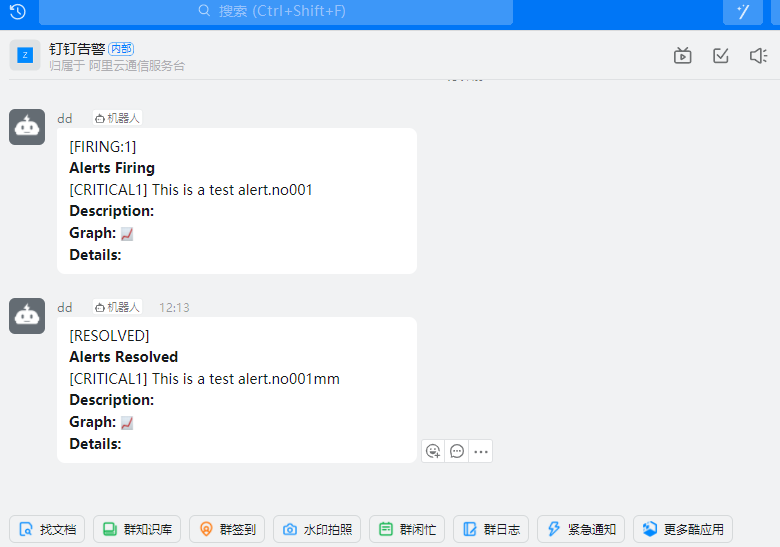
3、告警静默
3.1、什么是告警静默
静默 Silences :指让通过设置让警报在指定时间暂时不会发送警报的一种方式。
- 用于解决严重生产故障问题时,因所花费的时间过长,通过静默设置避免接收到过多的无用通知;
- 在已知的例行维护中,为了防止对例行维护的机器发送不必要的警报;
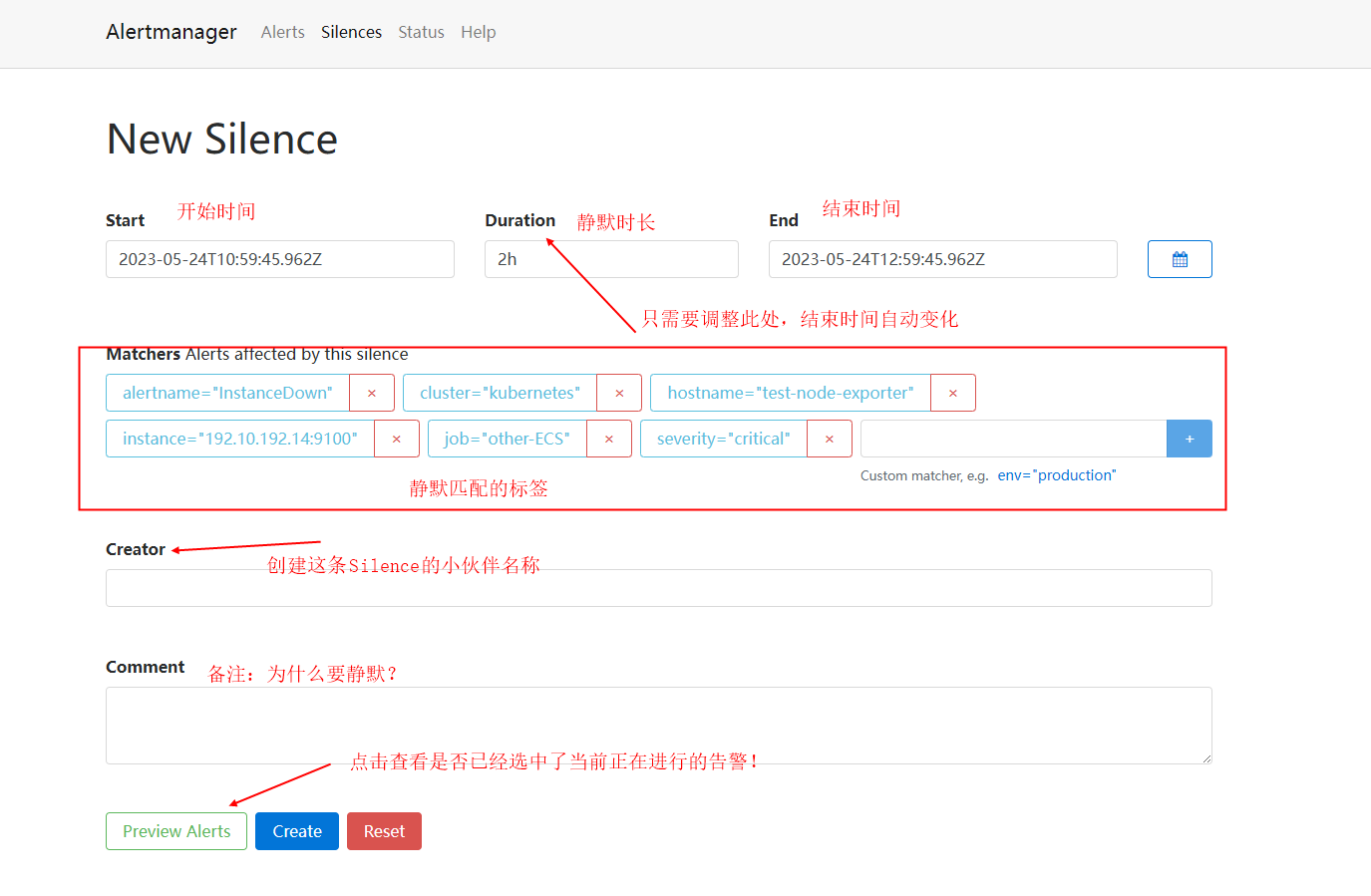
3.2 如何设置临时静默
4、总结:
- 实时告警通知:企业微信/钉钉等即时通信工具能够实现实时的告警通知,使得团队成员能够及时响应和解决问题。
- 告警抑制:对已知或排查问题的时候进行告警静默。