参考文献
[1] Zeighami S, Shahabi C, Sharan V. NeuroSketch: Fast and Approximate Evaluation of Range Aggregate Queries with Neural Networks[J]. Proceedings of the ACM on Management of Data, 2023, 1(1): 1-26.
Query编码方式
-
NeuroSketch支持的SQL语句格式如下:

-
在 AGG 和 Am 确定的情况下,我们对上述SQL进行编码,令 c=(c_1, ..., c_d), r=(r_1, ..., r_d), q=(c,r)
-
此时,q 即我们对某条Query的编码
解释
-
假设Query的谓词中只有一个属性,则 q=(c_1,r_1),记作 q=(c,r),表示 c <= A <= c+r(称作编码1)
-
与另一种更直观的编码方式对比,假设 q'=(low,high) 表示 low <= A <= high(称作编码2)
-
当我们使用编码2构建KD树时,我们取属性A的中位数 a,将 Q(表示q的集合)分为两部分 X、Y
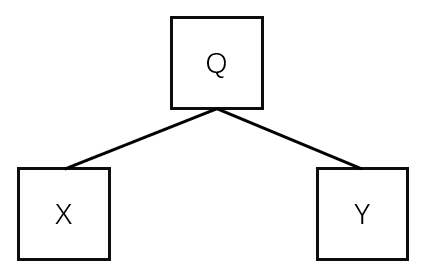
此时结点 X 表示的范围为:0 <= A <= a
结点 Y 表示的范围为:a <= A <= 1对于一条query:q'=(m,n), 若0<m<a, a<n<1,则 X、Y 任一结点都无法包含 m <= A <= n 这个范围,因为下限m落在X内,上限n落在Y内
-
我们通过改造KD数的构建过程,可以解决上述问题
首先,我们取 Q 中所有 q' 的 low 值,找到 low 的中位数 low_m;类似的方法找到 high 的中位数 high_m。
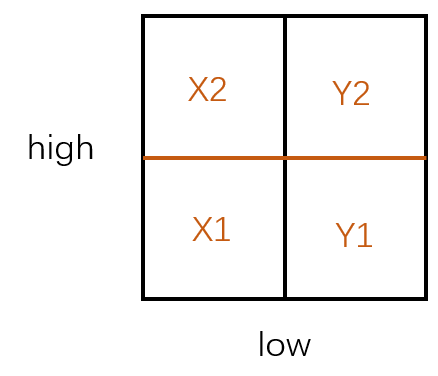
构建kd树时,首先用 low_m 将 Q 分为两部分 X、Y,再用 high_m 将X、Y分别分为两部分 X1、X2、Y1、Y2
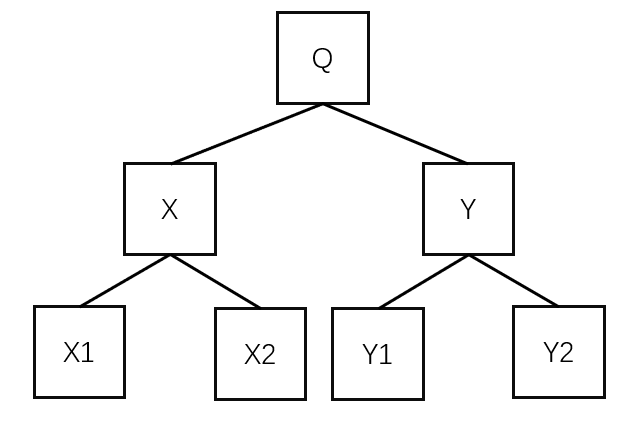
X:0 <= low <= low_m(对high不作限制)
Y:low_m <= low <= 1 (对high不作限制)
X1:0 <= low <= low_m AND 0 <= high <= high_m
X2:0 <= low <= low_m AND high_m <= high <= 1
Y1:low_m <= low <= 1 AND 0 <= high <= high_m
Y2:low_m <= low <= 1 AND high_m <= high <= 1在这个KD树中,并没有直接地把Query空间一分为二,而是第一层只限制low值,第二层只限制high值。
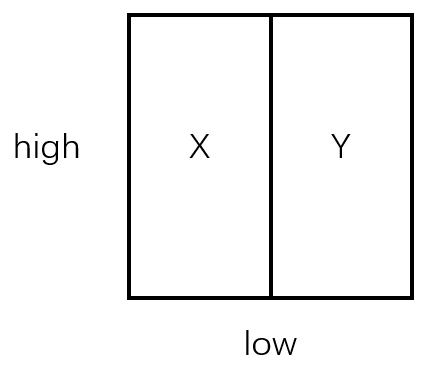
换言之,之前的构建KD树方式,是把一维空间分为两部分:
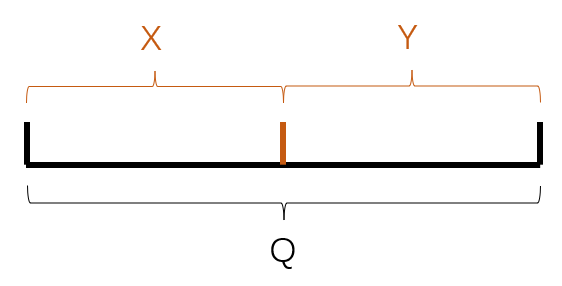
在这个空间上执行query,有可能会跨越多个子集(如下,q同时涉及了X和Y):
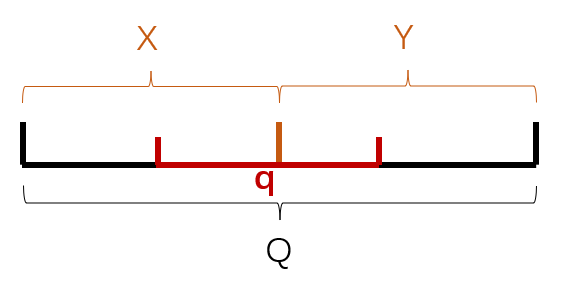
而我们第二次构建KD树时,是在二维空间上,先把low这个维度分为两部分:
再在两个子空间X、Y上,把high这个维度分为两部分:
在这个空间上执行query,其实就是在二维空间上定位一个点q=(m,n),如下所示:
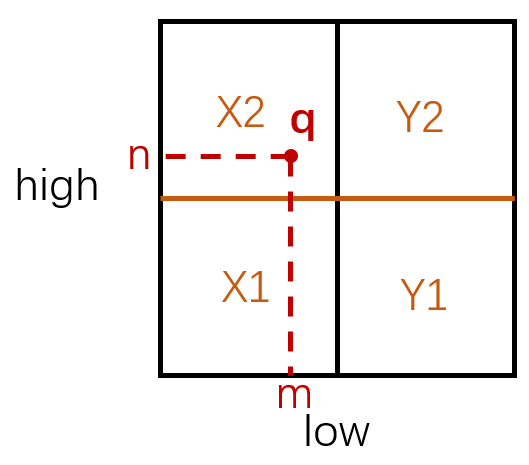
因此,对于某个q,他必然会落入某一个子空间(即某个叶结点),而不会跨越多个子空间。
-
对于编码1:q=(c,r),我们用第二次构建KD树的方式,就可以达到相同的效果。