1 背景
2 硬件单元
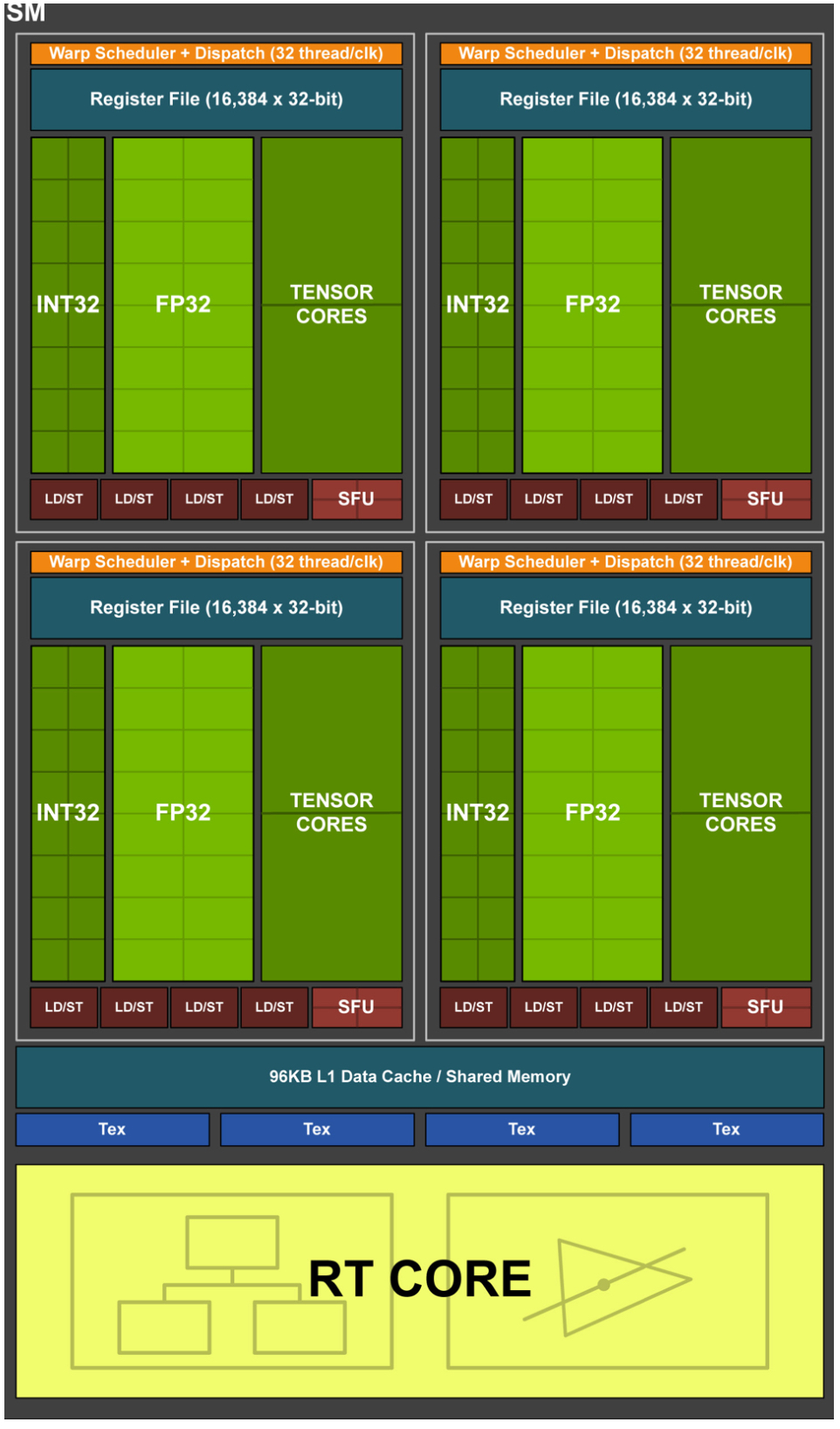
3 架构
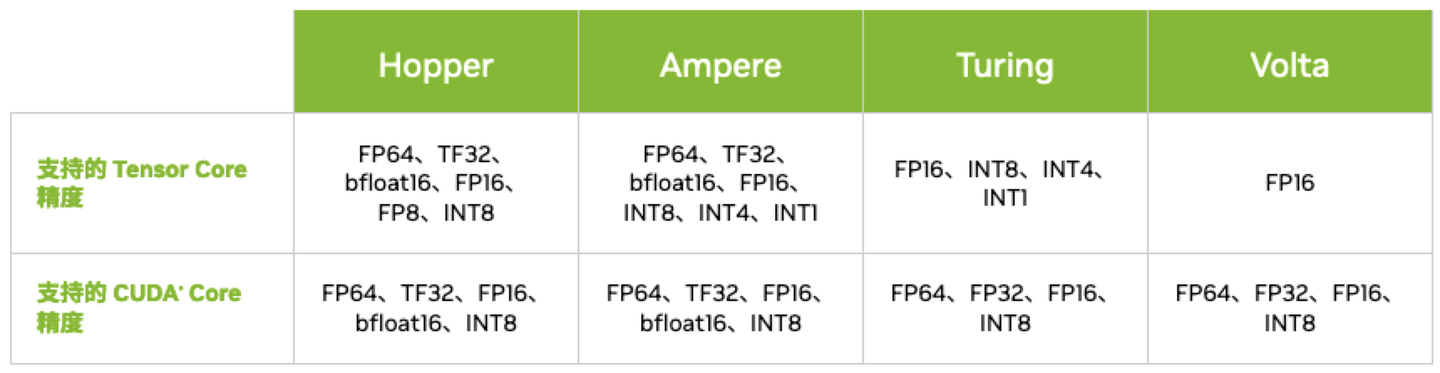
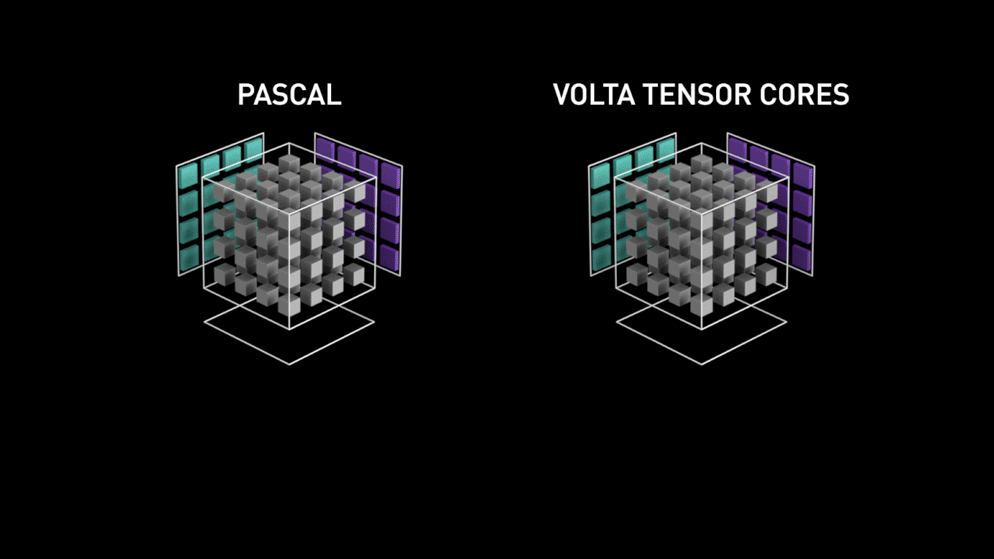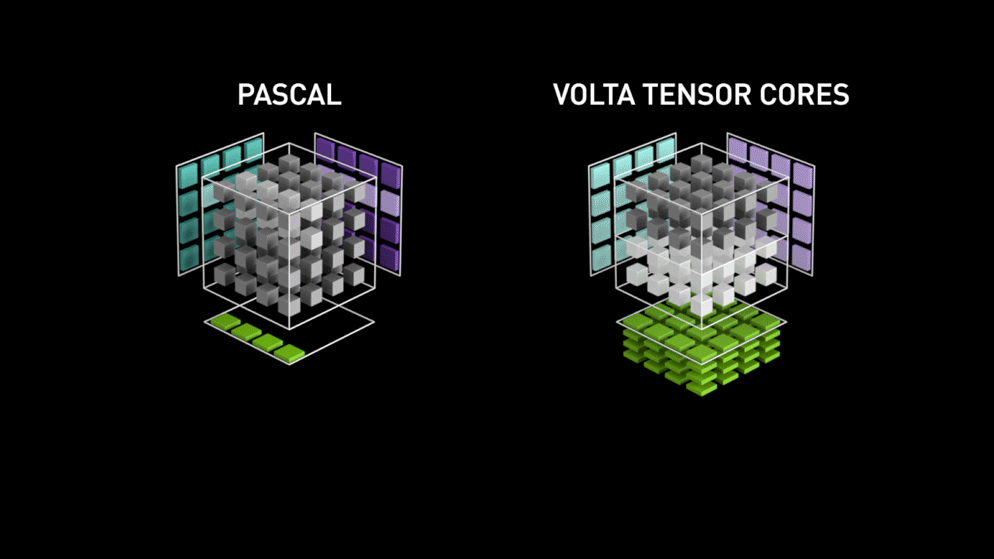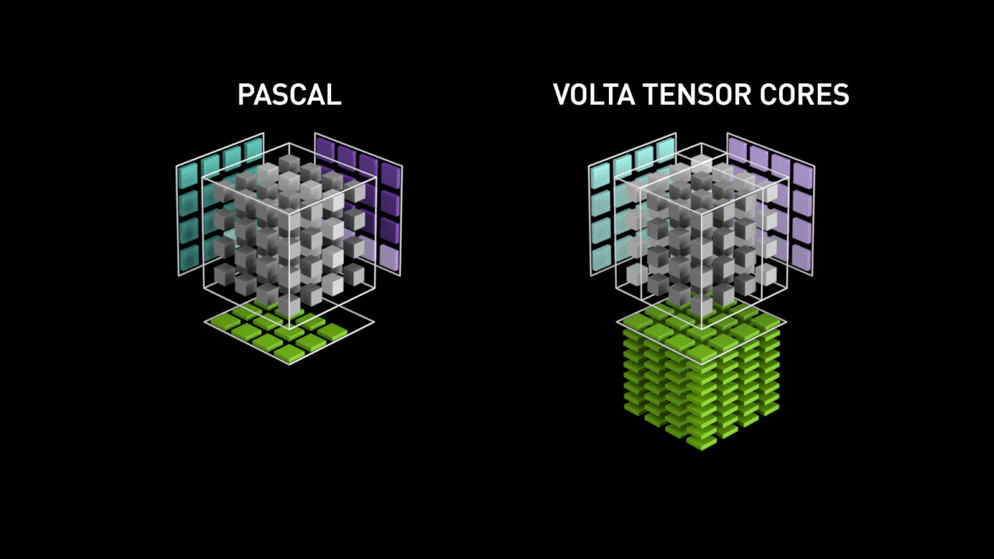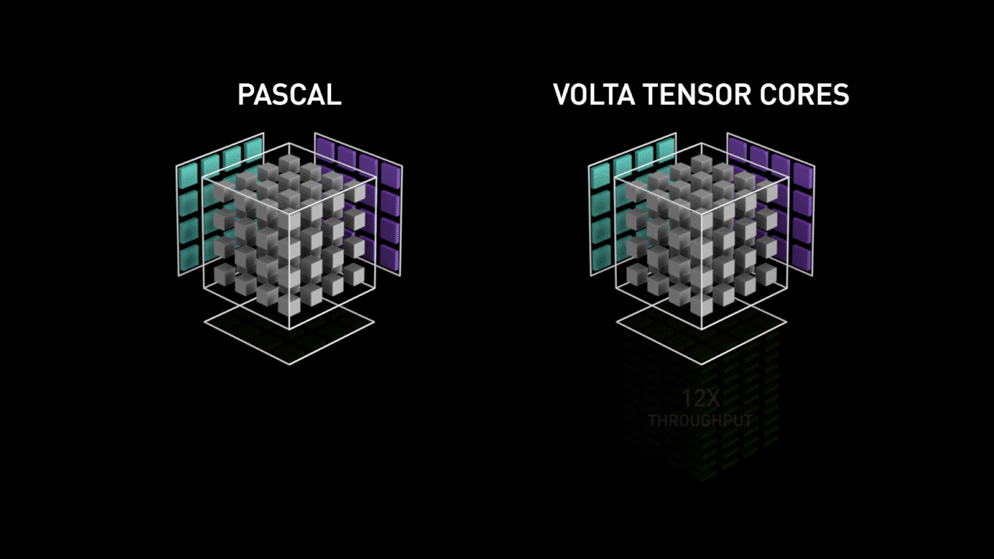
3.1 Volta Tensor Core
3.2 Turing Tensor Core
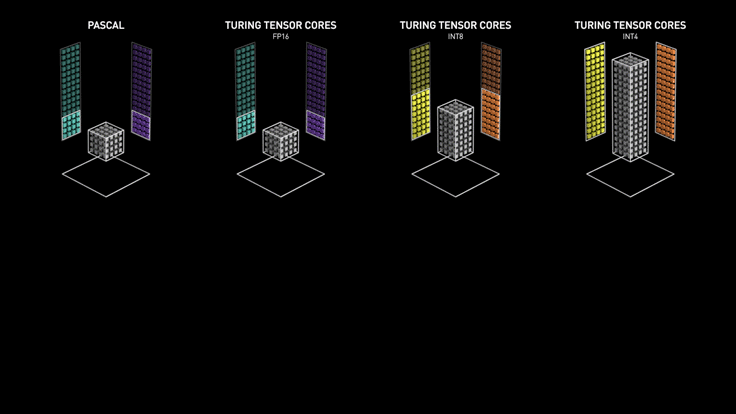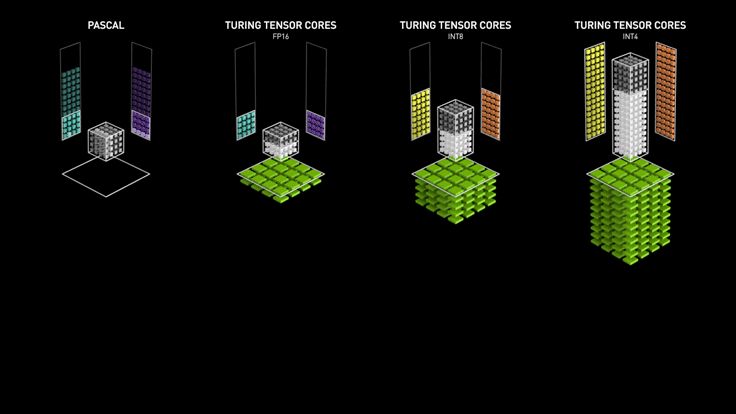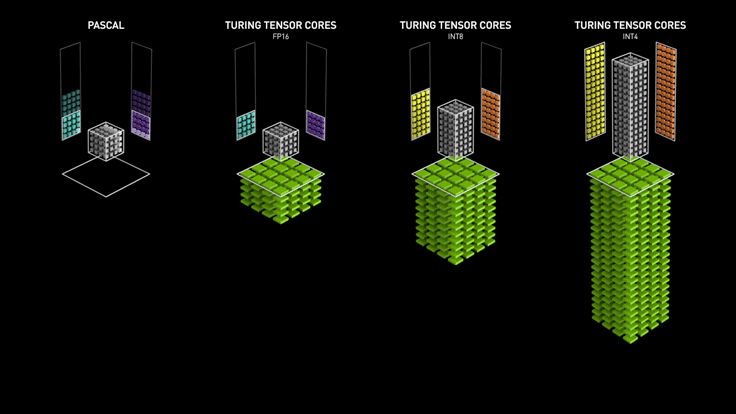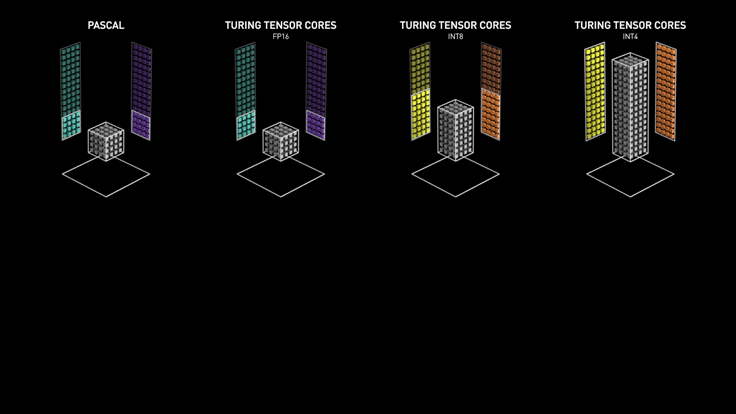
3.3 Ampere Tensor Core
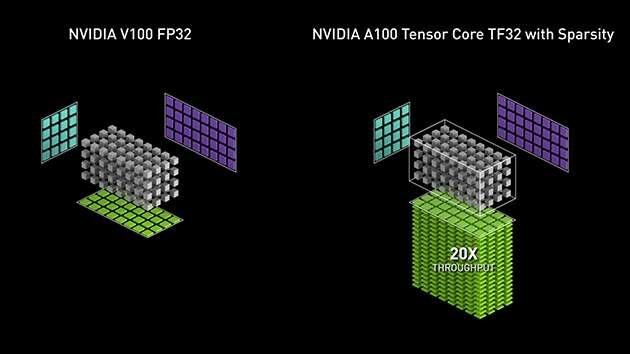
3.4 Hopper Tensor Core

4 调用
4.1 WMMA (Warp-level Matrix Multiply Accumulate) API
template<typename Use, int m, int n, int k, typename T, typename Layout=void> class fragment;
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm);
void load_matrix_sync(fragment<...> &a, const T* mptr, unsigned ldm, layout_t layout);
void store_matrix_sync(T* mptr, const fragment<...> &a, unsigned ldm, layout_t layout);
void fill_fragment(fragment<...> &a, const T& v);
void mma_sync(fragment<...> &d, const fragment<...> &a, const fragment<...> &b, const fragment<...> &c, bool satf=false);
-
fragment:Tensor Core数据存储类,支持matrix_a、matrix_b和accumulator
-
load_matrix_sync:Tensor Core数据加载API,支持将矩阵数据从global memory或shared memory加载到fragment
-
store_matrix_sync:Tensor Core结果存储API,支持将计算结果从fragment存储到global memory或shared memory
-
fill_fragment:fragment填充API,支持常数值填充
-
mma_sync:Tensor Core矩阵乘计算API,支持D = AB + C或者C = AB + C
4.2 WMMA PTX (Parallel Thread Execution)
wmma.load.a.sync.aligned.layout.shape{.ss}.atype r, [p] {, stride};
wmma.load.b.sync.aligned.layout.shape{.ss}.btype r, [p] {, stride};
wmma.load.c.sync.aligned.layout.shape{.ss}.ctype r, [p] {, stride};
wmma.store.d.sync.aligned.layout.shape{.ss}.type [p], r {, stride};
wmma.mma.sync.aligned.alayout.blayout.shape.dtype.ctype d, a, b, c;
-
wmma.load:Tensor Core数据加载指令,支持将矩阵数据从global memory或shared memory加载到Tensor Core寄存器
-
wmma.store:Tensor Core结果存储指令,支持将计算结果从Tensor Core寄存器存储到global memory或shared memory
-
wmma.mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C
4.3 MMA (Matrix Multiply Accumulate) PTX
ldmatrix.sync.aligned.shape.num{.trans}{.ss}.type r, [p];
mma.sync.aligned.m8n8k4.alayout.blayout.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k8.row.col.dtype.f16.f16.ctype d, a, b, c;
mma.sync.aligned.m16n8k16.row.col.dtype.f16.f16.ctype d, a, b, c;
-
ldmatrix:Tensor Core数据加载指令,支持将矩阵数据从shared memory加载到Tensor Core寄存器
-
mma:Tensor Core矩阵乘计算指令,支持D = AB + C或者C = AB + C