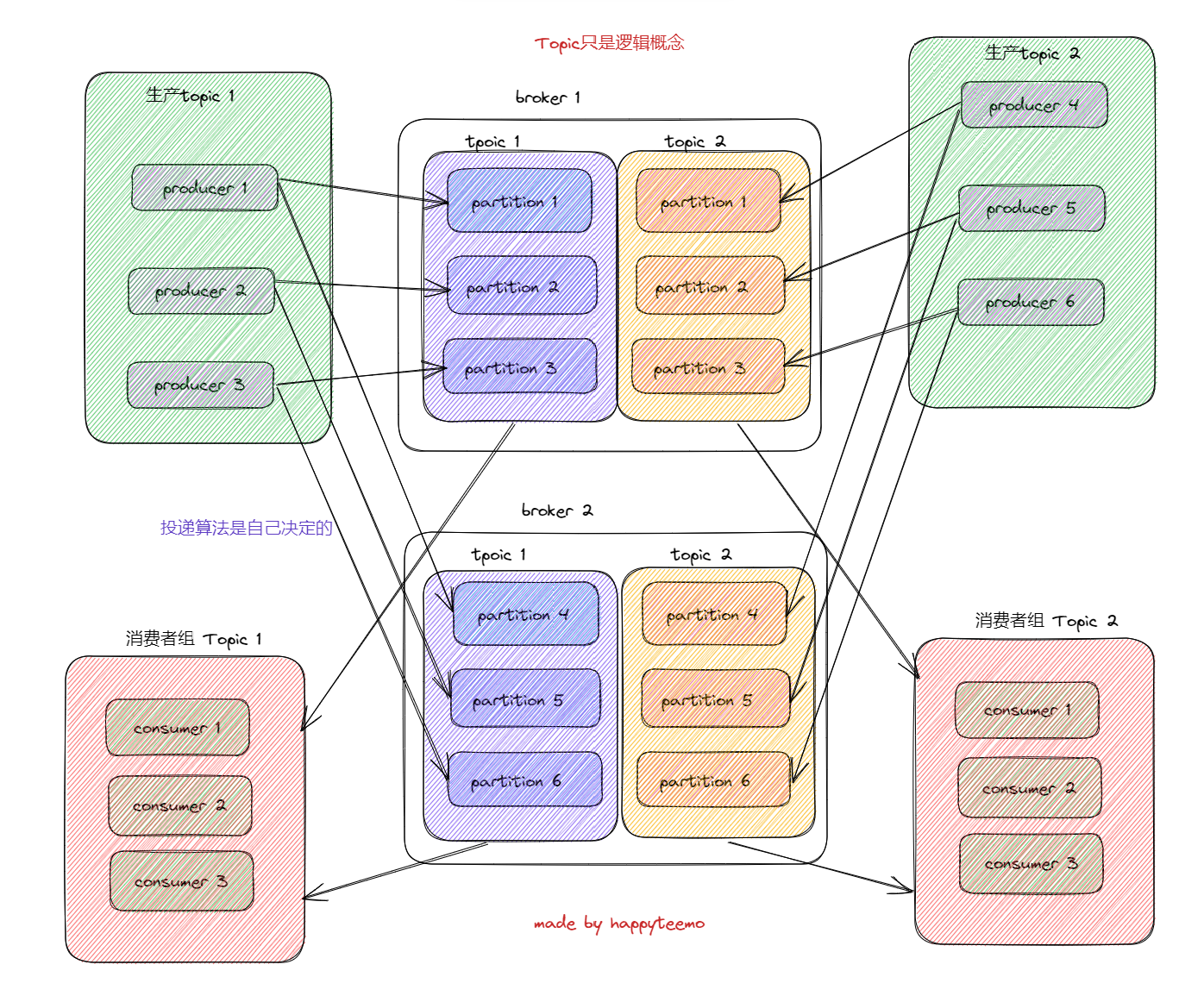
1 Broker
Kafka集群包含一个或多个服务器,服务器节点称为broker。
如图,我们有2个broker,6个partition,则会均分;如果只有1个partition,那么另一个broker会闲置。
理想情况,我们希望broker数量等于partition数量,然后每个partition对应一块硬盘,那样能保证顺序读写的吞吐量最大化。
具体的数量安排请看:https://www.cnblogs.com/HappyTeemo/p/17109381.html
2 Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
- 如果我们使用随机策略,则生产者投递到哪个partition是随机的。
- 我也可以制定生产者1的消息固定就投递到partition1中。
- kafka只保证partition内部的顺序性,如果我们要顺序执行,可以使用哈希算法,比如用userId这样的标志,将他的消息都投递到固定的partition上。
- 总之,我们可以自由控制消息的投递算法。
3 Partition
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。
partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。如果topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
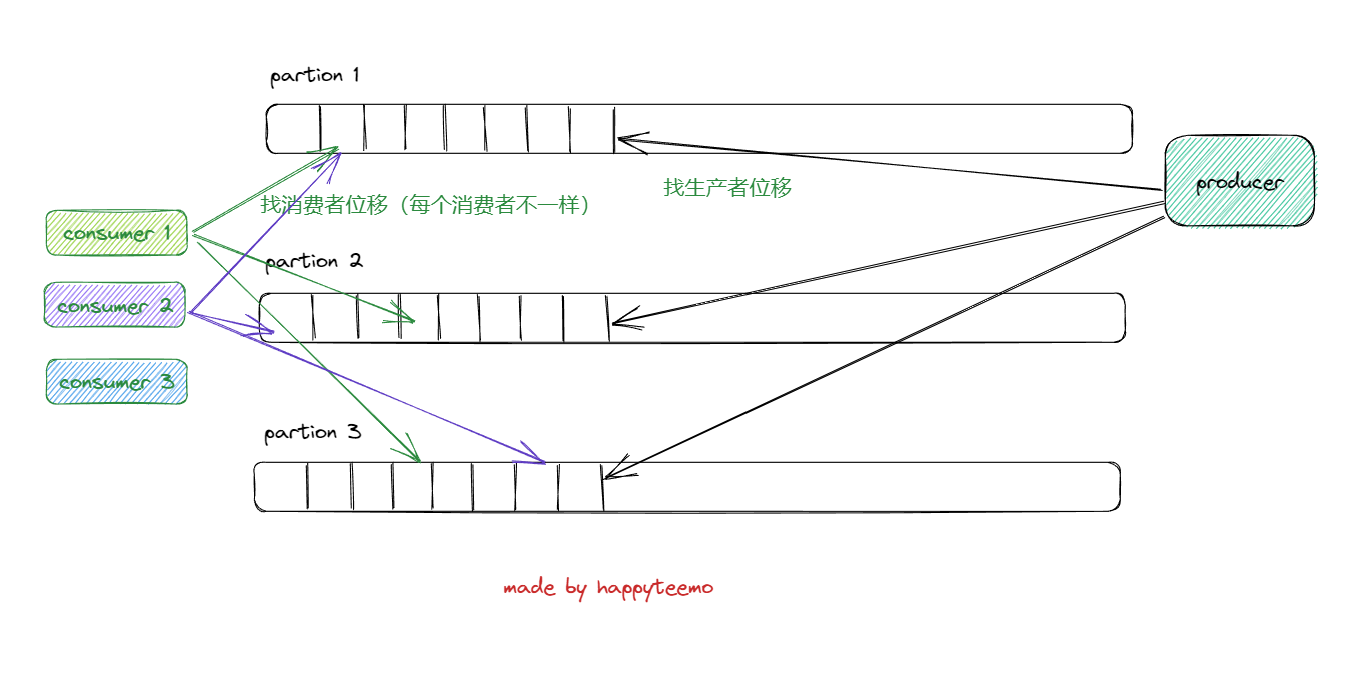
关于偏移量offest
4 Producer
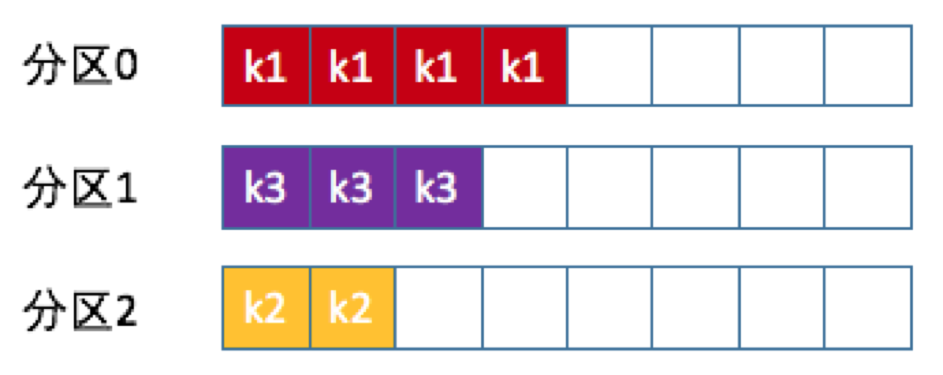
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
轮训算法
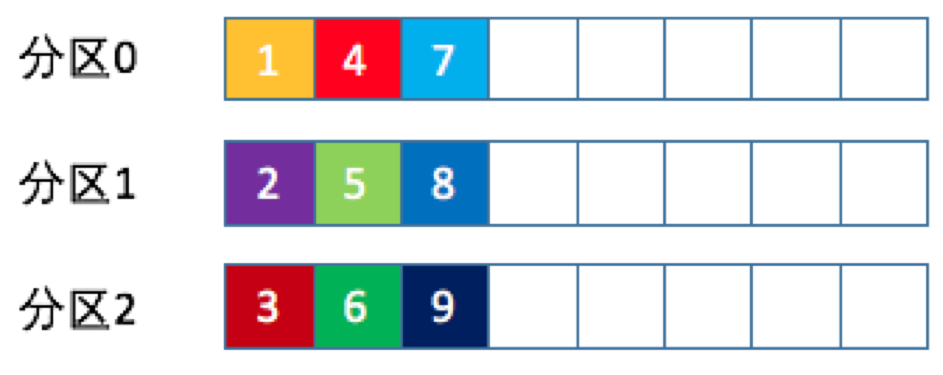
随机算法
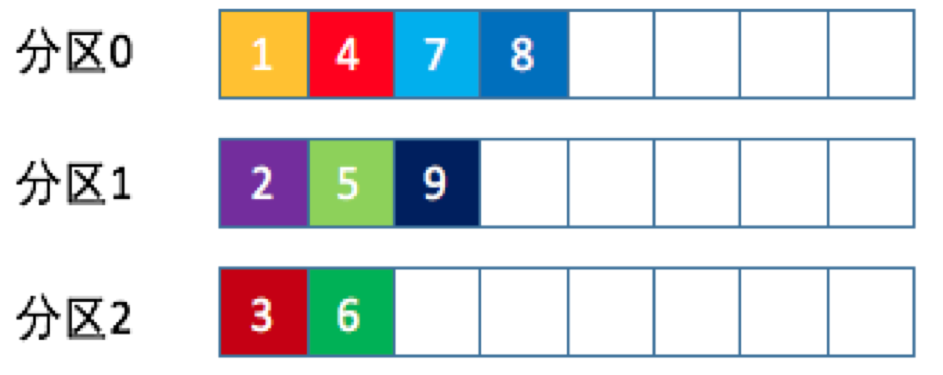
哈希算法
5 Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
6 Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group
name则属于默认的group)。
这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制给consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
7 Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
8 Follower
Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。
ISR: in-sync-replica,处于同步状态的副本集合,是指副本数据和主副本数据相差在一定返回(时间范围或数量范围)之内的副本,当然主副本肯定是一直在ISR中的。 当主副本挂了之后,新的主副本将从ISR中被选出来接替它的工作。
OSR: 和IRS相对应 out-sync-replica,其实就是指那些不在ISR中的副本。
9 Offset
kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
消息 Message
一条消息包含key和value,value是具体信息,key主要是用来指定写入分区的策略。
比如为键生成一个一致性性散列值,然后使用散列值对主题分区数进行取模,为消息选取分区。
批次
批次就是一组消息,用于减少网络开销。网络开销和CPU往往需要取平衡。