作业①:
1)、要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
题目1链接:题目1
代码如下:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
# self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
运行结果如下:
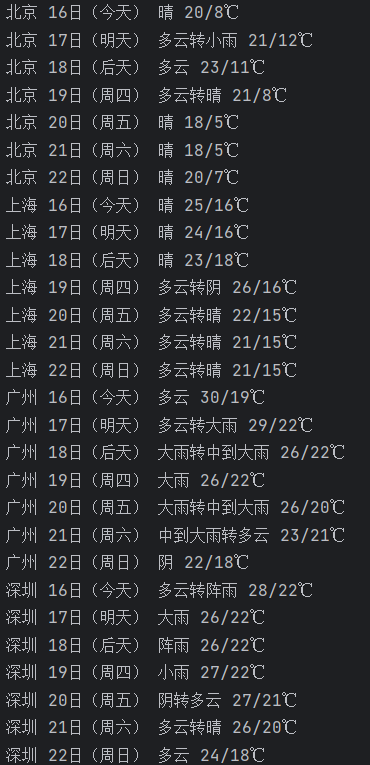
2)、心得体会
通过本题我进一步熟悉了如何爬取天气信息,并且将爬取到的数据保存到数据库当中。
作业②
1)、要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
题目2链接:题目2
代码如下:
import re
import requests
import sqlite3
class Database:
def create_table(self):
self.conn = sqlite3.connect("stock.db")
self.cursor = self.conn.cursor()
try:
self.cursor.execute('''
CREATE TABLE stock (
num TEXT,
s1 TEXT,
s2 TEXT,
s3 TEXT,
s4 TEXT,
s5 TEXT,
s6 TEXT,
s7 TEXT,
s8 TEXT,
s9 TEXT,
s10 TEXT,
s11 TEXT,
s12 TEXT
);
''')
except:
self.cursor.execute("delete from stock")
def insert_data(self, num,s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12):
self.cursor.execute("insert into stock (num,s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",
(num,s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12))
def show(self):
self.cursor.execute("select * from stock")
rows = self.cursor.fetchall()
print("{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}".format("序号", "股票代码", "名称","最新报价","涨跌幅","跌涨额","成交量","成交额","振幅","最高","最低","今开","昨收"))
for row in rows:
print("{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}\t{:^5}".format(row[0],row[1],row[2],row[3],row[4],row[5],row[6],row[7],row[8],row[9],row[10],row[11],row[12]))
def close(self):
self.conn.commit()
self.conn.close()
def get_stock(page):
url = "http://6.push2.eastmoney.com/api/qt/clist/get?cb=jQuery11240015414280997085639_1696665041821&pn="+str(page)+"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=1696665041822"
response = requests.get(url)
text = response.text
data = re.findall(r'"diff":\[(.*?)\]', text)
data = list(eval(data[0]))
num=1
for i in data:
s1 = i["f12"]
s2 = i["f14"]
s3 = i["f2"]
s4 = i["f3"]
s5 = i["f4"]
s6 = i["f5"]
s7 = i["f6"]
s8 = i["f7"]
s9 = i["f15"]
s10 = i["f16"]
s11 = i["f17"]
s12 = i["f18"]
db.insert_data(num+(page-1)*20,s1,s2,s3,s4,s5,s6,s7,s8,s9,s10,s11,s12)
num=num+1
try:
page = eval(input("请输入想要爬取的页数:"))
db = Database()
db.create_table()
for i in range(page):
get_stock(i+1)
db.show()
db.close()
except Exception as err:
print(err)
运行结果如下:
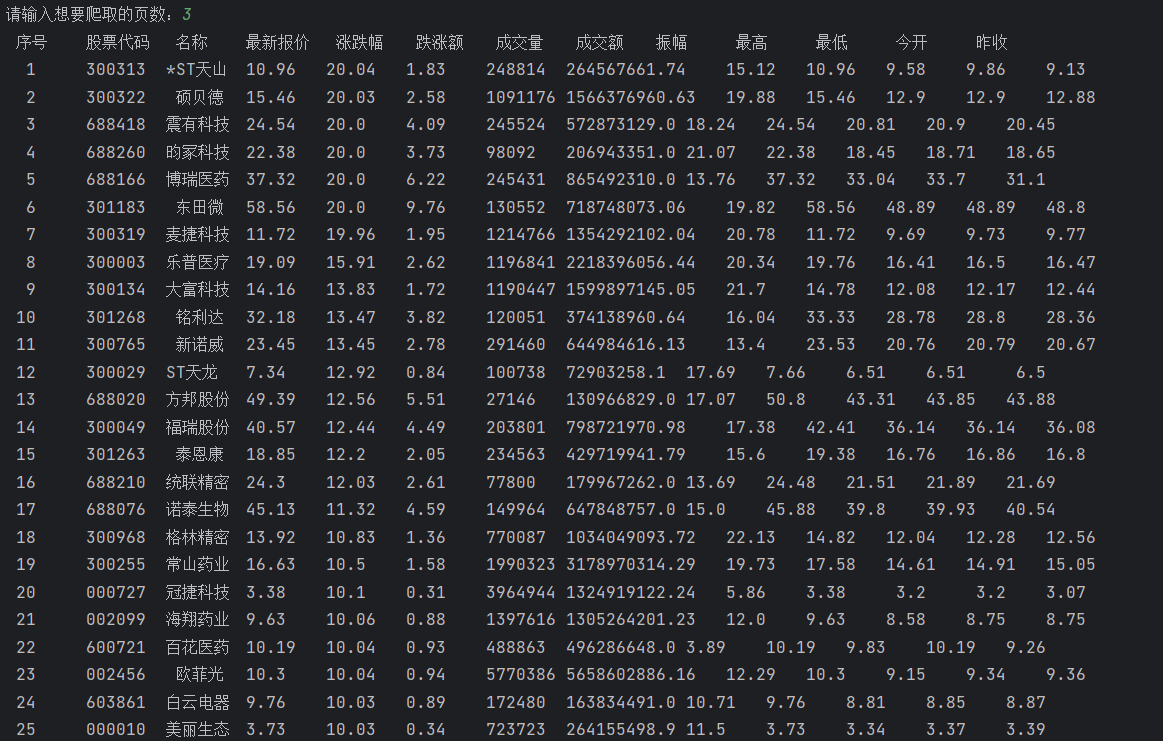
2)、心得体会
本题我们通过抓包的方式爬取数据,并且将数据保存到数据库当中。通过本道题目的实践,我对抓包的方式有了一定的了解并且能够初步使用。
作业③:
1)、要求:爬取中国大学 2021 主榜(https://www.shanghairanking.cn/rankings/bcur/2021) 所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
题目3链接:题目3
gif图如下:
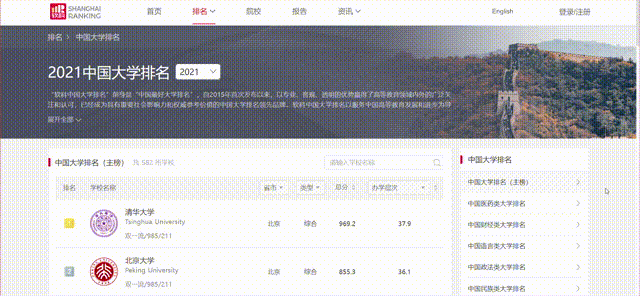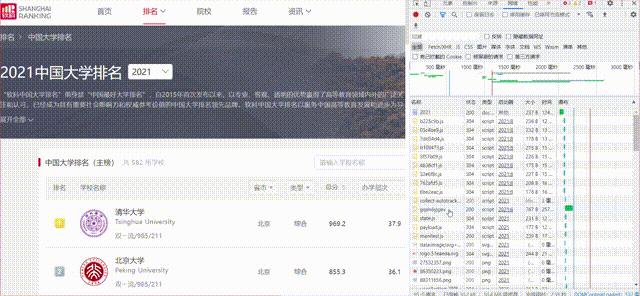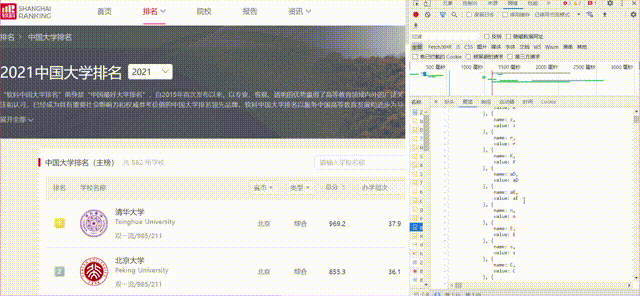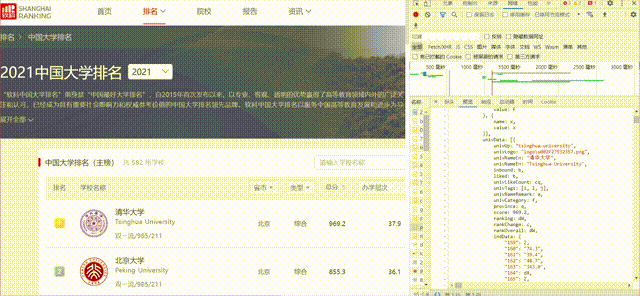
代码如下:
import re
import requests
import sqlite3
class UniversityDatabase:
def create_table(self):
self.conn = sqlite3.connect("ranking.db")
self.cursor = self.conn.cursor()
try:
self.cursor.execute('''
CREATE TABLE ranking (
ranking TEXT,
school TEXT,
province TEXT,
type TEXT,
score TEXT
);
''')
except:
self.cursor.execute("delete from ranking")
def insert_data(self, num,school_name,school_province,school_type,school_score,):
self.cursor.execute("insert into ranking (ranking,school,province,type,score) values (?,?,?,?,?)",
(num, school_name,school_province,school_type,school_score,))
def show(self):
self.cursor.execute("select * from ranking")
rows = self.cursor.fetchall()
print("{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format("排名","学校","省市","类型","总分"))
for row in rows:
print("{:^10}\t{:^10}\t{:^10}\t{:^10}\t{:^10}".format(row[0], row[1], row[2],row[3],row[4]))
def close(self):
self.conn.commit()
self.conn.close()
try:
url = "https://www.shanghairanking.cn/_nuxt/static/1697106492/rankings/bcur/2021/payload.js"
response = requests.get(url)
response.encoding=response.apparent_encoding
data = response.text
key = re.findall(r'function\(([\s\S]*?)\)',data)[0].split(",")
value = re.findall(r'}\(([\s\S]*?)\)',data)[0].split(",")
a = {}
for i in range(len(key)):
a[key[i]] = value[i]
name = re.findall(r'univNameCn:"([\s\S]*?)"',data)
province = re.findall(r'province:([a-zA-Z])', data)
type = re.findall(r'univCategory:([a-zA-Z])', data)
score = re.findall(r'score:(\d+\.\d+)',data)
province1 = []
type1 = []
for i in province:
province1.append(eval(a[i]))
for i in type:
type1.append(eval(a[i]))
num = 1
db = UniversityDatabase()
db.create_table()
for i in range(100):
school_name = name[i]
school_province = province1[i]
school_type = type1[i]
school_score = score[i]
db.insert_data(num,school_name,school_province,school_type,school_score)
num = num+1
db.show()
db.close()
except Exception as err:
print(err)
运行结果如下:
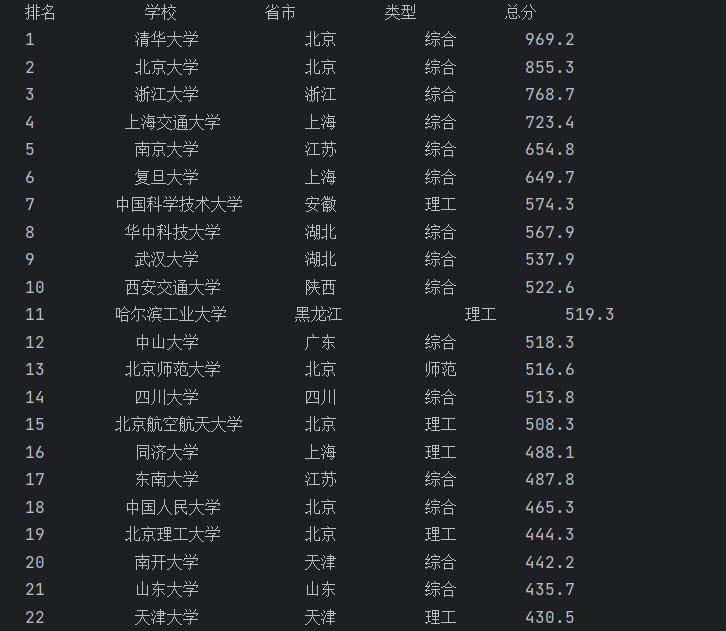
2)、心得体会
通过本题,我进一步熟悉了如何使用抓包的方式爬取数据。