部署在k8s中的应用日志中文乱码问题解决过程
问题:
java程序部署在k8s中,查看日志时,发现日志中的中文显示乱码。

分析:
中文乱码无非就是编码格式问题。
问题排查:
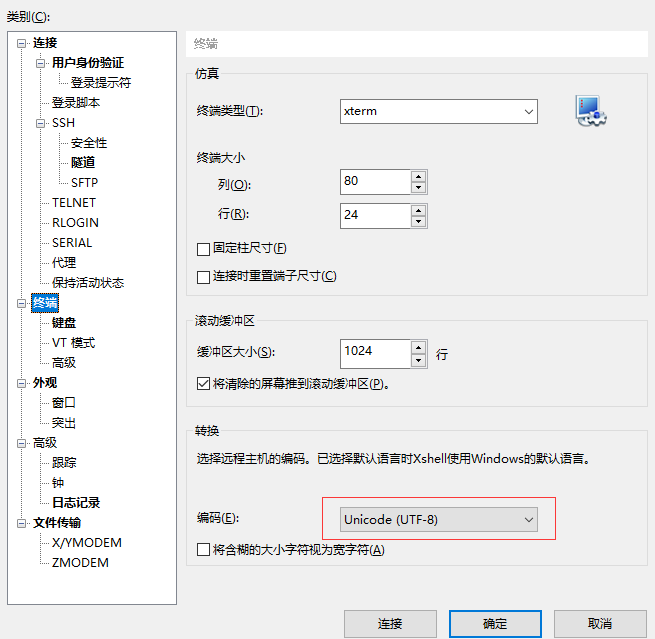
1、客户端,排查客户端编码配置,我使用的是xshell,“文件--属性--终端--编码”,查看编码是否为UTF-8。
2、程序环境,因为程序是部署在k8s中,所以应该进入容器中检查。
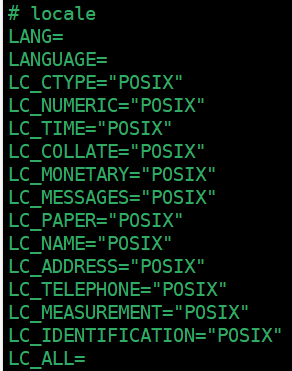
进入容器后,输入“locale”命令,查看
问题处理:
重新构建基础镜像,Dockerfile中添加以下配置重新构建,或者在每次构建服务镜像时都添加以下配置至Dockerfile中。
ENV LC_ALL=zh_CN.utf8 ENV LANG=zh_CN.utf8 ENV LANGUAGE=zh_CN.utf8 RUN localedef -c -f UTF-8 -i zh_CN zh_CN.utf8
总结:
POSIX规范并不包含中文,所以会导致乱码。
locale 是一个用于查看和设置系统本地化信息的命令。本地化信息包括地区、语言、字符编码等,它们对于不同地区和语言的用户来说可以确保正确的语言环境和字符处理。
LANG:系统的默认语言设置。LC_CTYPE:字符分类和字符集相关的设置,用于文本处理。LC_NUMERIC:数字格式相关的设置。LC_TIME:时间和日期格式相关的设置。LC_COLLATE:字符串比较和排序相关的设置。LC_MONETARY:货币格式相关的设置。LC_MESSAGES:系统消息和文本的语言设置。LC_PAPER:纸张尺寸相关的设置。LC_NAME:人名格式相关的设置。LC_ADDRESS:地址格式相关的设置。LC_TELEPHONE:电话号码格式相关的设置。LC_MEASUREMENT:测量单位相关的设置。LC_IDENTIFICATION:文档和数据的标识相关的设置。
POSIX 表示字符分类(Character Classification)和字符集(Character Set)的设置遵循POSIX标准。字符分类和字符集涉及字符的属性、编码和处理方式。POSIX字符分类和字符集是一种标准化的方式来处理字符,以确保跨不同Unix系统的一致性。