自注意力机制
一、输入
在学习自注意力机制之前,我们学到的神经网络的输入都是一个向量,输出可能是一个数值或者是一个类别。
1.举个例子。假设输入的向量是一排向量,而且输入的向量的数目是会改变的, 最简单的输入长度会改变的向量就是文字处理,假设我们的输入是一个句子的话。
那又是如何将句子中的一个简单的词汇表达成一个向量呢?
One-hot Encoding:我们可以找一个理想状态下的向量,这个向量的元素个数是世界上所有词汇的个数。于是就可以表示为下图的状态。

但是有一个问题就是无法通过我们制造的向量看到两个词之间有什么关系,需要假设所有的词汇彼此之间的都是没有关系的。比如上图,我们无法从独热向量之中看到两种动物cat和dog之间有什么接近的关系,cat和apple之间有什么不接近的关系。
Word Embedding:词嵌入表示法,我们给每一个词汇一个向量,这个向量是有语义的信息的,如果把词嵌入表示画出来的话,可以看到如下图,所有的动物都会聚成一团,所有的植物都会聚成一团,所有的动词也会聚成一团(词嵌入的内容会单独出一期!!!!!!)

2.再举个例子,一段声音信号其实是一排向量,我们会把一段声音讯号取一个范围,这个范围叫做窗口,这个窗口里面的内容描述成一个向量
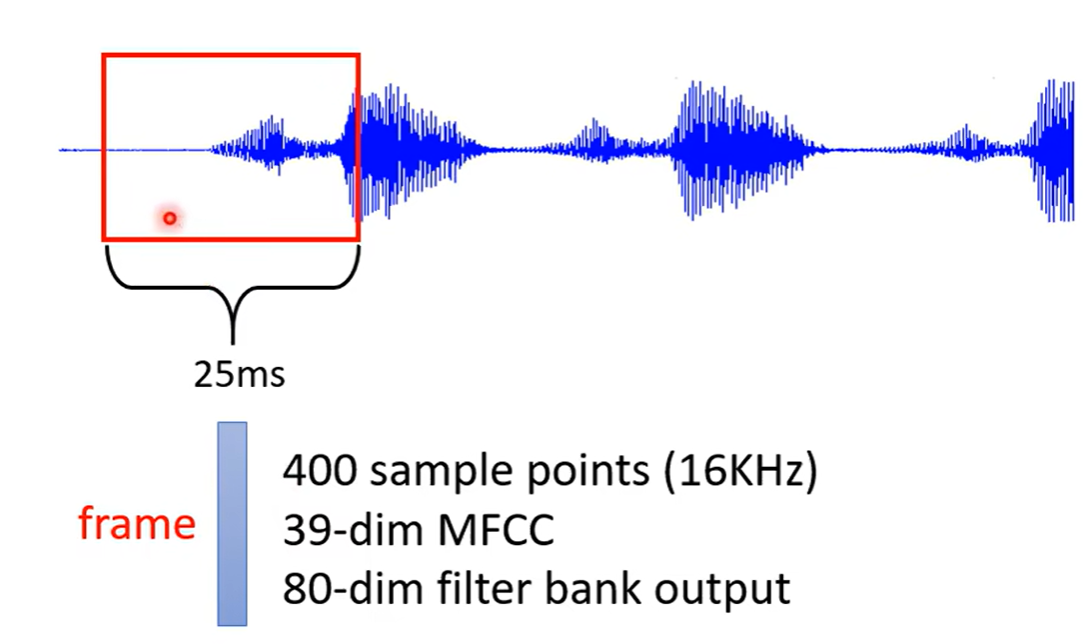
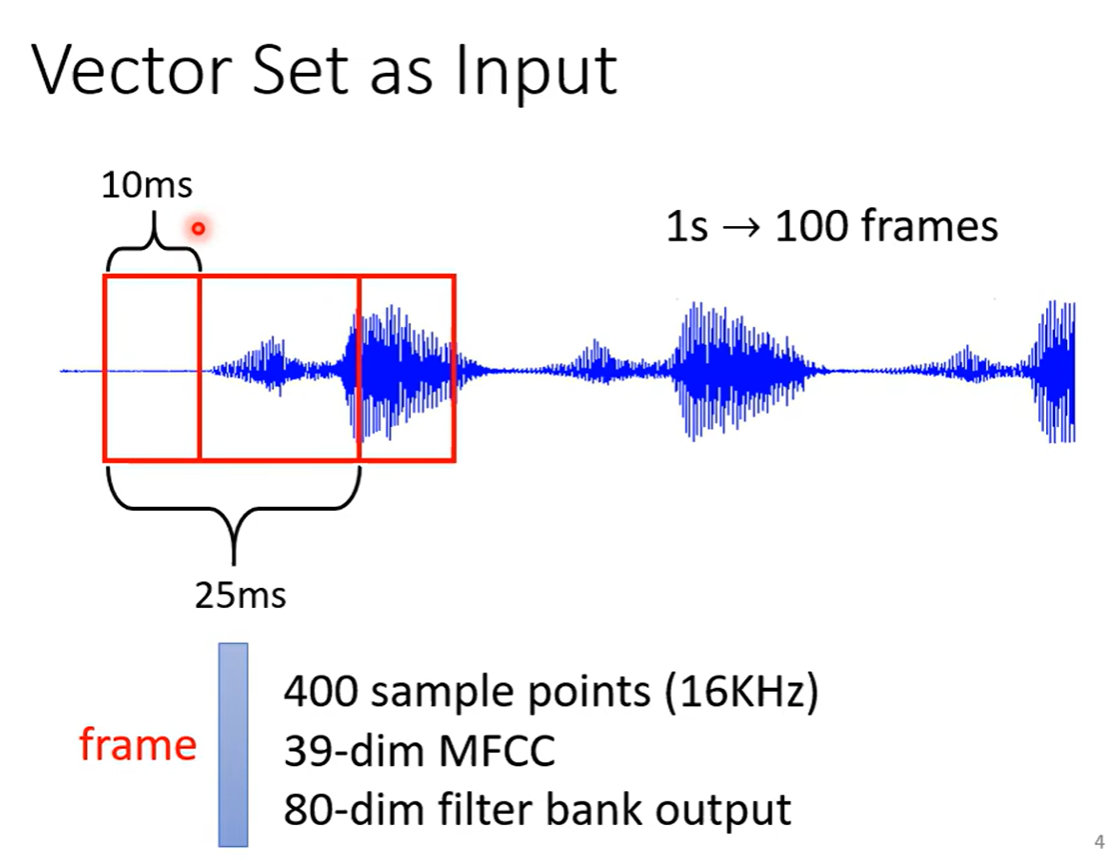
如果要描述一整段的声音讯号,我们会把窗口右移10ms的位置(一般都是25ms的窗口,移动步幅是10ms)所以一秒钟的声音讯号有100个向量
3.再举个例子 ,一个图也会是一堆向量,比如社会网络的每一个节点是可以看作一个向量的,或者是一个化学分子的一个原子也可以看作是一个向量。同样可以使用独热向量表示一个原子
二、输出
-
每一个向量都有一个对应的label,当输入是几个向量,输出就要输出对应的几个label。例如:文字处理的词性标注,语音处理的语音辨识,社会网络中的推荐系统

-
一整个向量序列,只需要输出一个label就好。比如:nlp中的情感分析,语音识别中识别语音是来自于谁,预测分子是否有毒性或其他化学性是怎样

-
不知道输出多少个label,由机器自己决定就好,这种任务又叫seq2seq任务(后面会出一期)。比如:翻译,语音辨识等

三、Sequence Labeling
给sequence中的每一个向量都给他一个label, 虽然输入是一个sequence,但是每一个向量都分别经过一个全连接层之后,会给每一个向量输出一个结果
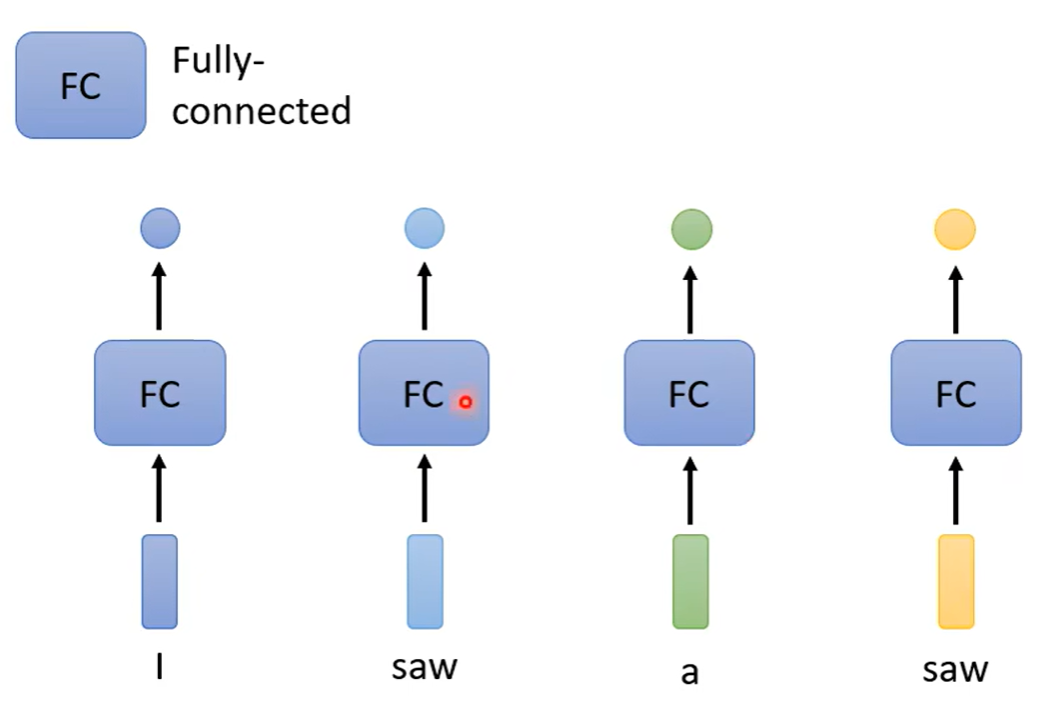
但是这样做的问题也随之体现:比如第一天做的是词性标记的问题,给定了机器上图的句子,两个saw在机器看来是一模一样的两个词,没有理由输出不一样的结果。于是将某个向量以及其前后的向量都串起来,一起丢到全连接层中 ,可以让全连接层考虑到更多的上下文的信息。

有一个任务只考虑窗口大小不能解决,需要考虑到一整个sequence才可以解决,那么应该怎么做呢(sequence的长度是可变的)?
于是便引入我们要介绍的自注意力机制(self-attention)
四、Self-Attention
自注意力机制会吃一整个sequence的信息,之后输入几个向量,便输出几个标签。可以看到下图中:输出的四个向量的特别的地方是它们都是考虑了一整个sequence之后才输出的结果,之后再将这个向量丢到全连接层之中,这样一来,这个全连接层中的输入就不是只考虑一个向量,而是间接地通过自注意力机制考虑到了一整个序列的向量。
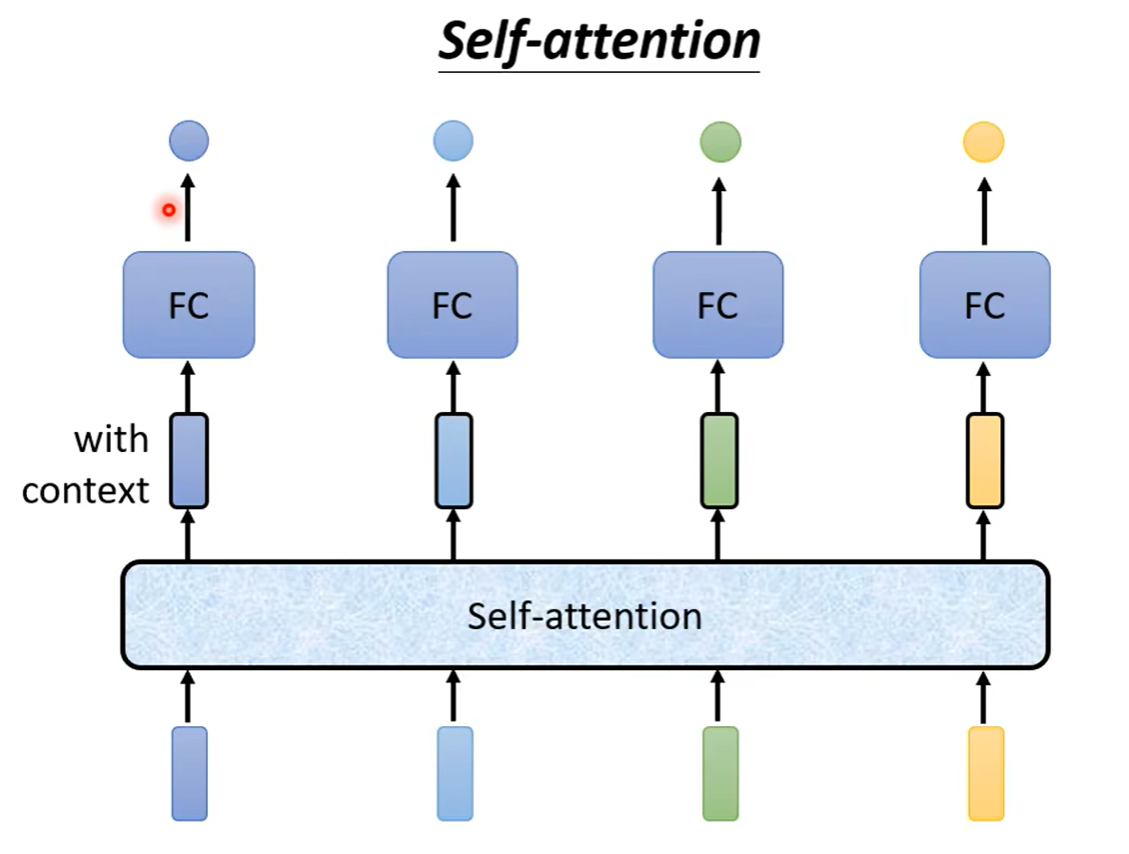
自注意力机制也不是只能用一次,我们可以多次进行使用

那么self-attention是如何运作的呢
可以看到下图中,我们发现自注意力的输出都是考虑到了所有的输入之后才产生出来
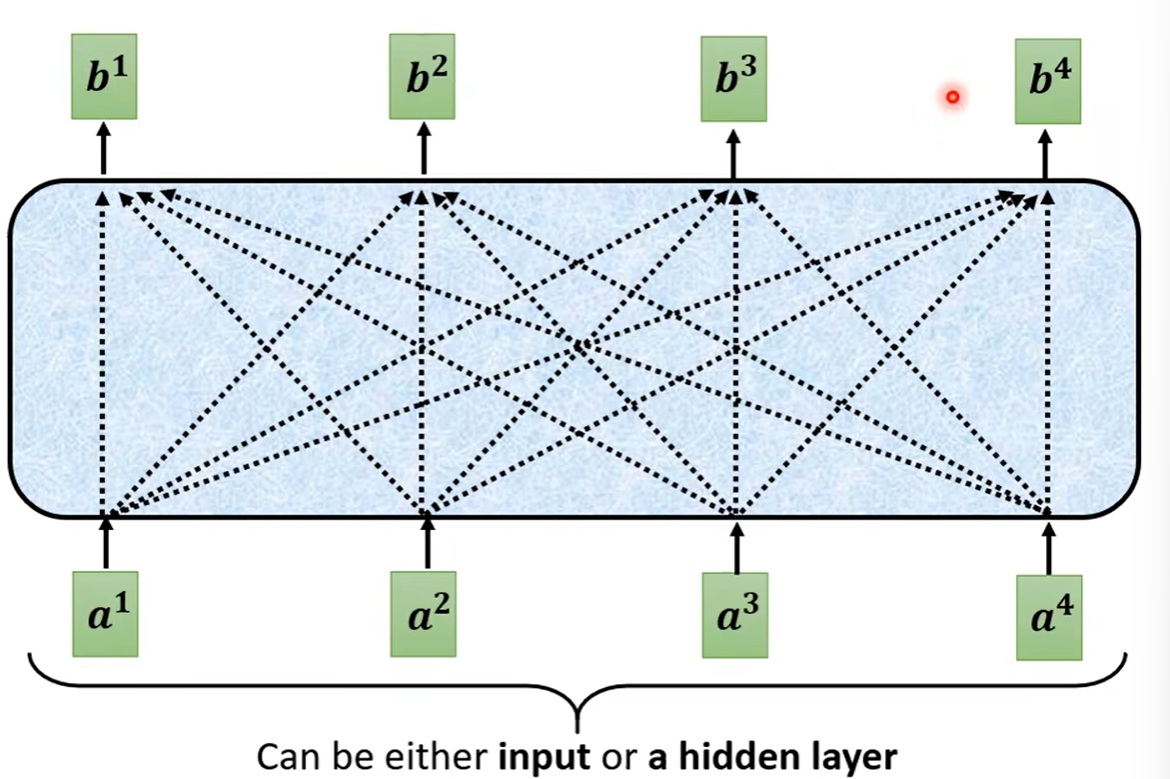
那又是如何考虑到所有的输入呢
-
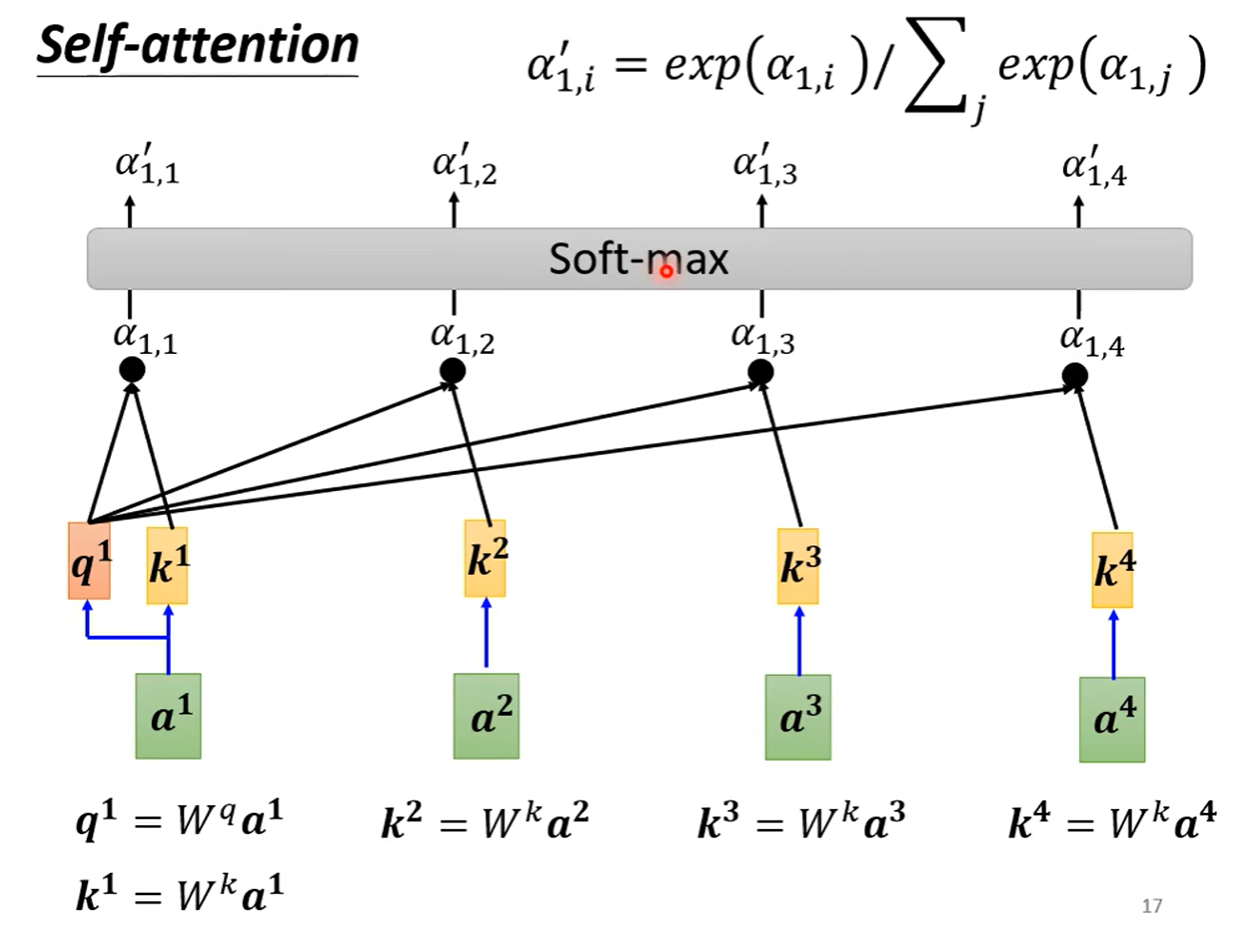
根据a1找到整个序列中与a1相关联的其他向量,每一个向量和a1的关联程度,我们用数值α来表示。自注意力机制是如何决定两个向量之间的关联性呢
-
使用到计算attention的模组,拿两个向量作为输入,直接输出α的数值,我们可以把α当作关联程度。具体的计算方法又是什么呢
-
如下图的左边,我们把输入的两个向量分别乘上两个不同的矩阵,得到两个向量,再把他们做个点乘即可。下图的右边,我们把乘了矩阵得到的两个向量串起来,经过一个激活函数再通过一次变形得到α

-
我们先将a1乘上一个矩阵得到q1(名字叫做query),再同样的方法得到k2(名字叫key,由a2乘以矩阵得到)相乘得到α(1,2)(α的名字叫做attention)
-
之后再经过的全连接层的激活函数不一定是softmax,也可以是relu函数或者其他函数
-
之后根据得到的新的α我们可以抽取到sequence中重要的东西,我们把所有的向量乘以矩阵W,得到新的向量v,再把新的向量v都去乘以attention的分数α,再进行相加。

上述的整过过程,用矩阵乘法来看待则会是:
-
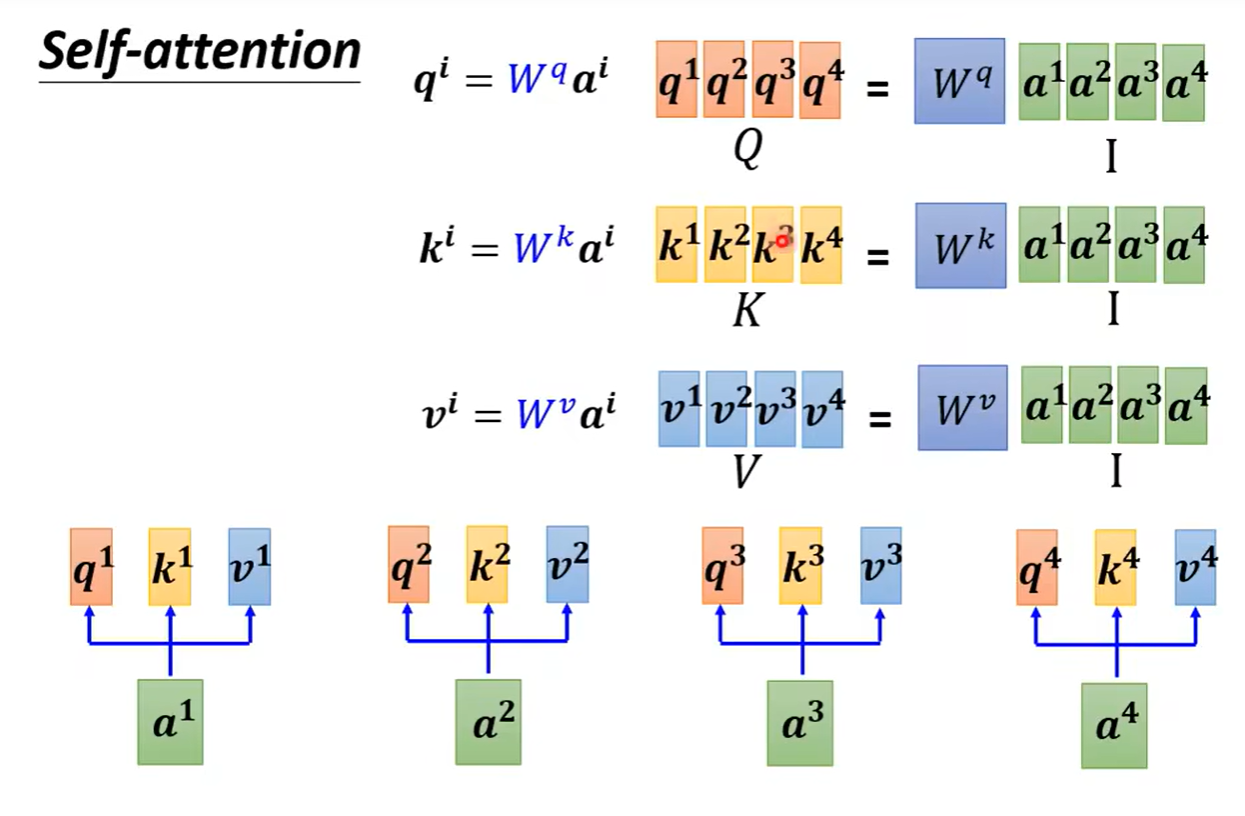
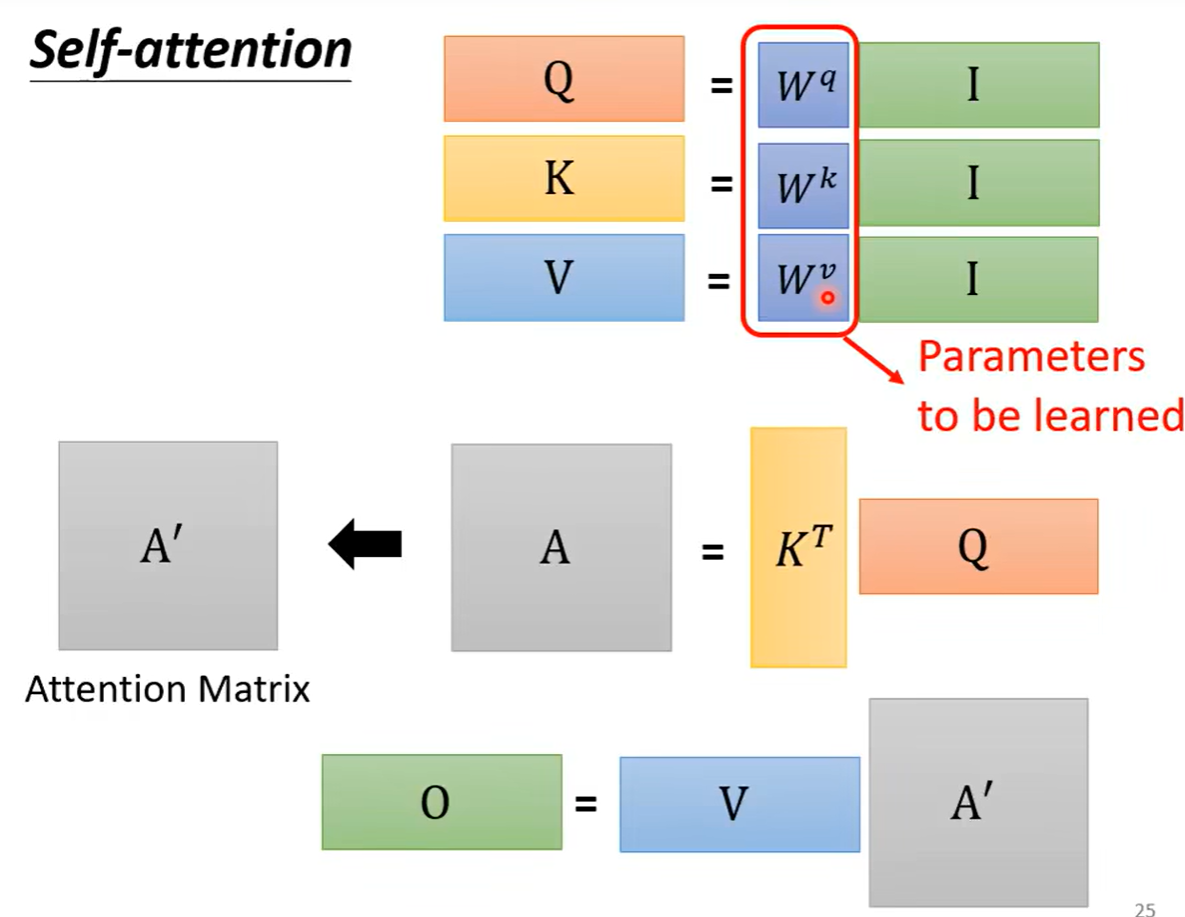
我们知道所有的输入向量都会得到三个向量q,k,v于是使用矩阵运算进行表示是每一个a都乘上Wq这个矩阵,得到四个q ,我们把四个不同的向量看作是一整个矩阵I,得到的结果(也就是q组成的矩阵Q),同理的得到三个矩阵Q,K,V
-
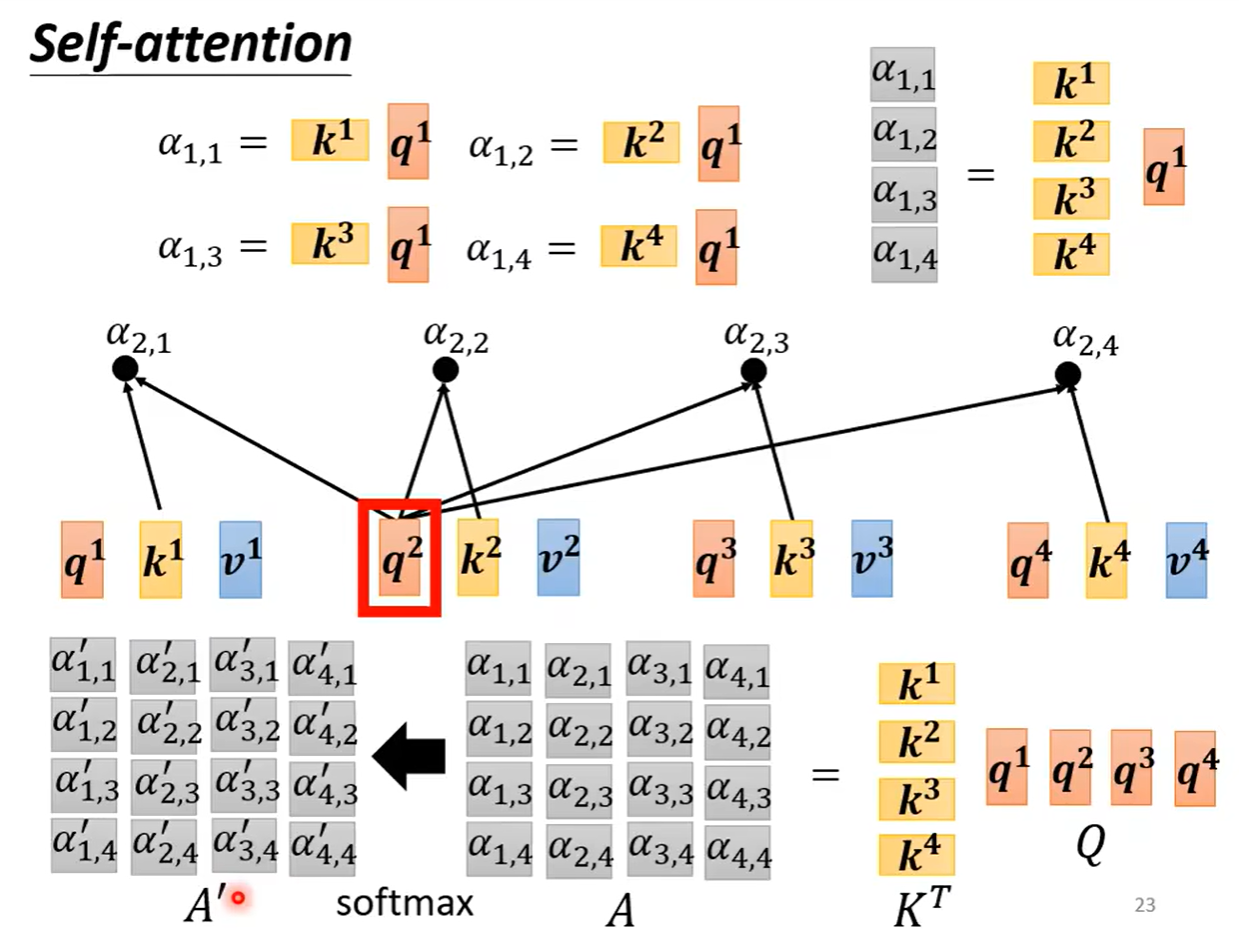
之后我们知道每一个q和k要进行点乘来计算相关系数,同样是可以进行拼接,可以看作是矩阵和向量之间进行相乘,得到一个向量,这个向量的值就是四个α的值。同样的向量q也可以进行各种拼接,于是得到了一个α的矩阵
-
之后就是对b向量的计算,b向量可看作α矩阵中的每一个列都对V拼成的矩阵进行相乘,得到的是向量b

总体过程总结一下如下图,并且可以看到self-attention的输入是I矩阵,输出变成了O矩阵,其中需要学习的参数只有三个W矩阵。
五、Multi-head Self-attention
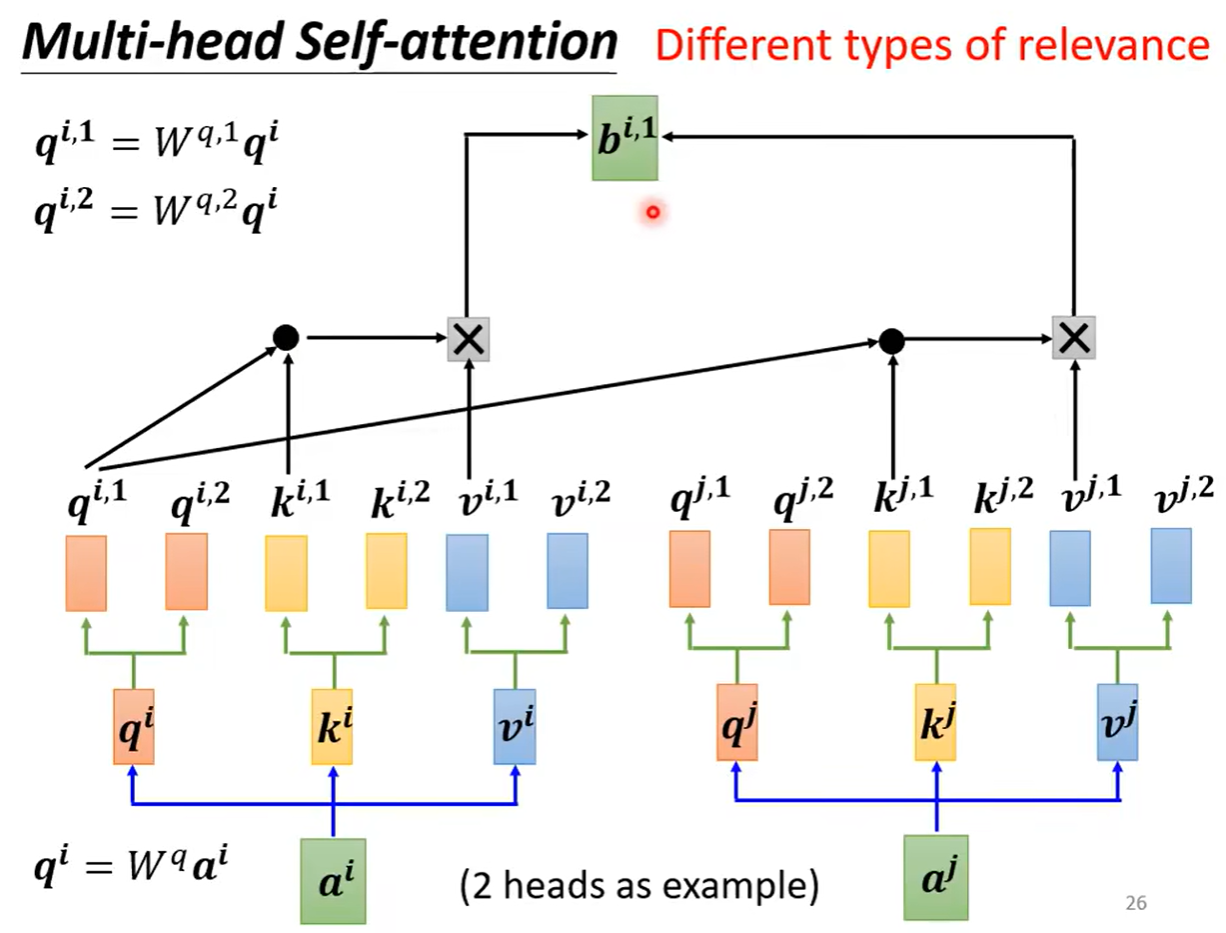
head的数量是可以根据不同的任务进行设置的,在做自注意力机制的处理的时候,我们可以认为在做的是用向量q去寻找与其相关的向量k,但是相关可以有各种类型的相关,于是可以不只有一个q可以有多个q负责不同种类的相关性。于是a可以乘上矩阵得到q,之后q可以再乘上不同矩阵得到不同版本的q。
在做self-attention时,只是和相同位置的k求相关,q1之和k1求相关系数,而不去考虑k2
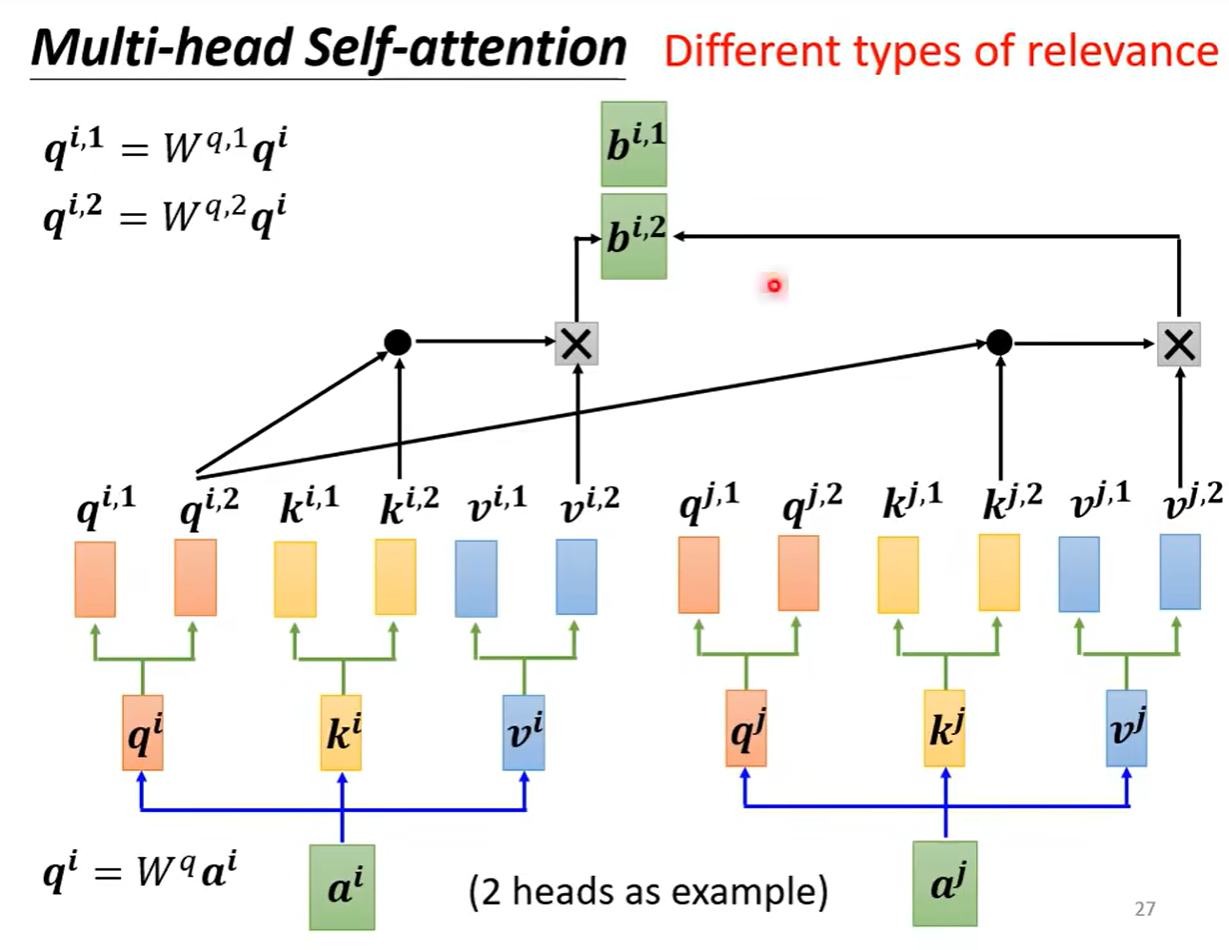
之后可以把两个b进行拼接起来,再乘以某个矩阵得到的是最后的b向量
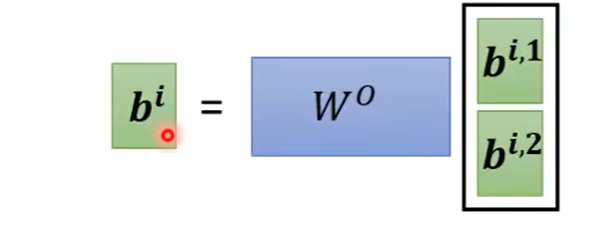
六、位置编码
到这里可以知道,此时的self-attention层缺少了位置信息,对于这一层来说,每一个输入的向量,是出现在sequence的最前面还是最后面,并不清楚。那么怎么把位置信息放入自注意力机制层呢?
Positional Encoding技术
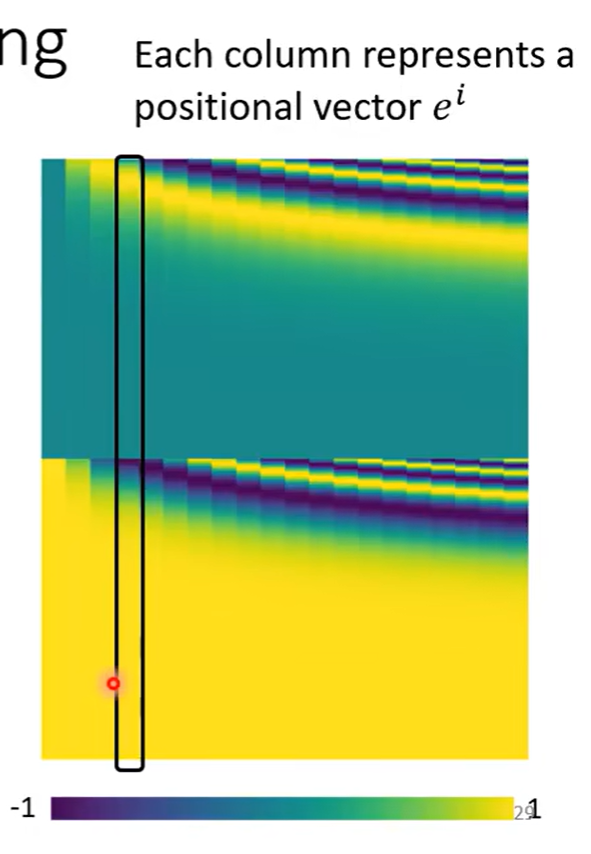
为每一个位置设定一个向量,是位置向量(positional vector)。每一个不同的位置都有不同的为位置向量,把位置向量e和上面讲的输入向量a相加即可。
那这个位置向量e是长什么样子呢?如下图中,这个图的每一个列就代表一个e。位置向量的生成方式可以有很多种
自注意力机制不是说只能应用在nlp领域,而是很多地方都可以用,比如:
-
语音识别,但是语音识别随便说一句话都会有很多向量来处理,于是产生了Truncated Self-attention,和传统的self-attention相比,它只会关注到一个小的范围就好而不是要考虑整个sequence中所有向量的相关性。
-
影像处理,可以把一张图片看作是一组向量
- attention Self 01attention self 01 self-attention self-attentive self-attention attention self self-attentive interaction attentive automatic attention smoother kernel self recommendation self-attention sequential stochastic self-attention attention self 4.1 self-attention attention笔记self self-attention representation functional attention