BFS和DFS基础
搜索简介
搜索是"暴力法"算法的具体实现,是一种吧所有可能的情况都罗列出来,然后逐一检查,从中找到答案的方法。
一般步骤
- 找到所有可能的数据,并且永数据结构表示和存储。
- 优化:尽量多的排除不符合条件的数据,以减少搜索空间。
- 用某个算法快速检索这些数据。
搜索算法的基本思路
搜索的基本算法分为两种:宽度优先搜索(BFS)、深度优先搜索(DFS)。
例子
用"老鼠走迷宫"来解释这两个算法。
- 一只老鼠(DFS):再迷宫中先按一条路一直走到头再回头看找到另一条路,重复这个操作直到走完整个迷宫。
- 一群老鼠(BFS):每条路都有一只老鼠负责走,把迷宫分为若干层每一圈为一层,每次只有当前层的老鼠都走到下一层时,位于下一层的老鼠才能继续往下走,直到有一只老鼠找到迷宫的出口为止。
BFS是"全面扩散、逐层递进";DFS是"一路到底、逐步退回"。
图示
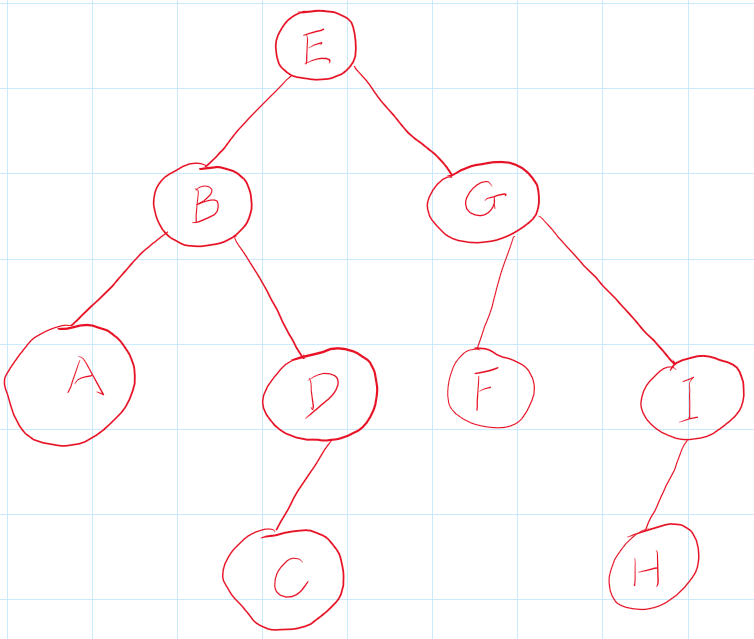
DFS的顺序是{E,B,A,D,C,G,F,I,H}访问顺序是先访问左节点再访问右节点。
BFS的顺序是{E,B,C,A,D,F,I,C,H}访问顺序是逐层访问。
BFS代码实现
BFS可描述为"BFS=队列"。
特征
- 处理完第i层后,才会处理i+1层。
- 队列中在任意时刻最多有两层节点,其中i层节点都在i+1前面。
静态二叉树
#include <bits/stdc++.h>
using namespace std;
const int N=1e5+10;
int idx=1;
struct Node{
char v;
int l,r;
}tree[N];
int newNode(int v)
{
tree[idx].v=v;
tree[idx].l=tree[idx].r=0;
return idx++;
}
void insert(int f,int c,int l_r)
{
if(!l_r)tree[f].l=c;
else tree[f].r=c;
}
int buildtree()
{
int A=newNode('A');int B=newNode('B');int C=newNode('C');
int D=newNode('D');int E=newNode('E');int F=newNode('F');
int G=newNode('G');int H=newNode('H');int I=newNode('I');
insert(E,B,0);insert(E,G,1);insert(B,A,0);insert(B,D,1);
insert(D,C,0);insert(G,F,0);insert(G,I,1);insert(I,H,0);
int root=E;
return root;
}
int main()
{
int root=buildtree();
queue<int> q;
q.push(root);
while(q.size())
{
int t=q.front();
q.pop();
cout<<tree[t].v<<" ";
if(tree[t].l!=0)q.push(tree[t].l);
if(tree[t].r!=0)q.push(tree[t].r);
}
return 0;
}
复杂度分析
- 时间复杂度:由于需要检查每条边,且只检查一次,时间复杂度为O(m),m为边的数量。
- 空间复杂度:每个点只进出队各一次,空间复杂度为O(n),n为点的数量。
Tips
BFS是逐层扩散的,非常符合在图上计算最短路径,先扩散到的节点离根节点更进。很多最短路径算法都是BFS发展出来的。
DFS的常见操作和代码框架
1.常见操作
DFS可描述为"DFS=递归"。
二叉树的各种DFS操作有:时间戳、DFS序、树的深度、子树节点数、先序输出、中序输出、后序输出。
- 时间戳:节点第一次被访问的时间戳。
- DFS序:每个节点打印两次,被这两次包围起来的是以它为父节点的一棵子树。
- 数的深度:从根节点向子树DFS,每个节点第一次被访问时,深度+1,这个节点回溯时,深度-1。
- 子树节点总数:num[i]表示i为父节点的子树上的节点总数。
- 先序输出:函数按父节点、左子节点、右子节点的顺序打印。
- 中序输出:函数按左子节点、父节点、右子节点的顺序打印。
- 后序输出:函数按左子节点、右子节点、父节点的顺序打印。
Tips
"先序+后序"不能确定一棵树。
静态二叉树
#include <bits/stdc++.h>
using namespace std;
const int N=1e5+10;
int idx=1;
struct Node{
char v;
int l,r;
}tree[N];
int newNode(char v)
{
tree[idx].v=v;
tree[idx].l=tree[idx].r=0;
return idx++;
}
void insert(int f,int c,int l_r)
{
if(l_r==0)tree[f].l=c;
else tree[f].r=c;
}
int dfn[N];//第i的时间戳
int dfn_timer=0;
void dfn_order(int father)
{
if(father!=0)
{
dfn[father]=++dfn_timer;
printf("dfn[%c]=%d;",tree[father].v,dfn[father]);
dfn_order(tree[father].l);
dfn_order(tree[father].r);
}
}
int visit_timer=0;
void visit_order(int f)
{
if(f!=0)
{
printf("visit[%c]=%d;",tree[f].v,++visit_timer);
visit_order(tree[f].l);
visit_order(tree[f].r);
printf("visit[%c]=%d;",tree[f].v,++visit_timer);
}
}
int deep[N];
int deep_timer=0;
void deep_node(int f)
{
if(f!=0)
{
printf("deep[%c]=%d;",tree[f].v,++deep_timer);
deep_node(tree[f].l);
deep_node(tree[f].r);
deep_timer--;
}
}
int num[N];
int num_node(int f)
{
if(f==0)return 0;
else{
num[f]=num_node(tree[f].l)+num_node(tree[f].r)+1;
printf("num[%c]=%d;",tree[f].v,num[f]);
return num[f];
}
}
void preorder(int f)
{
if(f!=0)
{
cout<<tree[f].v<<" ";
preorder(tree[f].l);
preorder(tree[f].r);
}
}
void inorder(int f)
{
if(f!=0)
{
inorder(tree[f].l);
cout<<tree[f].v<<" ";
inorder(tree[f].r);
}
}
void postorder(int f)
{
if(f!=0)
{
postorder(tree[f].l);
postorder(tree[f].r);
cout<<tree[f].v<<" ";
}
}
int buildtree()
{
int A=newNode('A');int B=newNode('B');int C=newNode('C');
int D=newNode('D');int E=newNode('E');int F=newNode('F');
int G=newNode('G');int H=newNode('H');int I=newNode('I');
insert(E,B,0);insert(E,G,1);insert(B,A,0);insert(B,D,1);
insert(D,C,0);insert(G,F,0);insert(G,I,1);insert(I,H,0);
int root=E;
return root;
}
int main()
{
int root=buildtree();
cout<<"dfn order:";dfn_order(root);cout<<endl;//时间戳
cout<<"visit order:";visit_order(root);cout<<endl;//DFS序
cout<<"deep order:";deep_node(root);cout<<endl;//树的深度
cout<<"num of tree:";num_node(root);cout<<endl;//子树节点总数
cout<<"in order:";inorder(root);cout<<endl;//中序
cout<<"pre order:";preorder(root);cout<<endl;//先序
cout<<"post order:";postorder(root);cout<<endl;//后序
return 0;
}
输出
dfn order:dfn[E]=1;dfn[B]=2;dfn[A]=3;dfn[D]=4;dfn[C]=5;dfn[G]=6;dfn[F]=7;dfn[I]=8;dfn[H]=9;
visit order:visit[E]=1;visit[B]=2;visit[A]=3;visit[A]=4;visit[D]=5;visit[C]=6;visit[C]=7;visit[D]=8;visit[B]=9;visit[G]=10;visit[F]=11;visit[F]=12;visit[I]=13;visit[H]=14;visit[H]=15;visit[I]=16;visit[G]=17;visit[E]=18;
deep order:deep[E]=1;deep[B]=2;deep[A]=3;deep[D]=3;deep[C]=4;deep[G]=2;deep[F]=3;deep[I]=3;deep[H]=4;
num of tree:num[A]=1;num[C]=1;num[D]=2;num[B]=4;num[F]=1;num[H]=1;num[I]=2;num[G]=4;num[E]=9;
in order:A B C D E F G H I
pre order:E B A D C G F I H
post order:A C D B F H I G E
复杂度分析
- 时间复杂度:由于需要检查每条边,且只检查一次,时间复杂度为O(m),m为边的数量。
- 空间复杂度:空间复杂度为O(n),因为使用了长度为n的递归栈。
Tips
DFS搜索的特征是一路深入,适合处理节点间的先后关系、连通性等,在图论中应用很广。
2.DFS代码框架
框架代码
ans;
void dfs(层数,其他参数)
{
if(出局判断)
{
更新答案;
return;
}
(剪枝)
for(枚举下一层)
if(used[i]==0)
{
used[i]=1;
dfs(层数+1);
used[i]=0;
}
returns;
}
BFS和DFS的对比
1.时间复杂度对比
大多数情况下,BFS和DFS的时间复杂度差不多,因为他们都需要搜索整个空间。
2.空间复杂度对比
BFS使用的空间往往比DFS大。
3.搜索能力对比
DFS没有BFS的空间消耗问题,但是可能搜索大量无效的节点。
Tips
总结BFS和DFS的特点,DFS更适合找一个任意可行解,BFS更适合找全局最优解。
4.扩展和优化
在BFS和DFS的基础上,发展出了剪枝、记忆化(DFS)、双向广搜(BFS)、迭代加深搜索(DFS)、A*算法(BFS)、IDA*(DFS)等技术,大大提高了搜索能力。
Tips
DFS的代码比BFS更简单,如果一道题目用BFS和DFS都可以解,一般用DFS。
BFS常用去重技巧:BFS的队列,把状态放入队列时,需要判断这个状态是否已经在队列中处理过,如果已经处理过,就不用再入队列,这就是去重。去重能大大优化复杂度。可以自己写hash去重,缺点是浪费空间。用STL set和map去重是更常见的做法。
DFS常用去重技巧:剪枝,如果某个搜索分支不符合要求,就剪去它,不在深入搜索,这样能节省大量计算。
连通性判断
连通性问题是图论中的一个基本问题:寻找一张图中连通的点和边。
判断连通性的方法:BFS、DFS、并查集。
例题
[全球变暖](全球变暖 - 蓝桥云课 (lanqiao.cn))
题目描述
你有一张某海域 NxN* 像素的照片,"."表示海洋、"#"表示陆地,如下所示:
.......
.##....
.##....
....##.
..####.
...###.
.......
其中"上下左右"四个方向上连在一起的一片陆地组成一座岛屿。例如上图就有 2 座岛屿。
由于全球变暖导致了海面上升,科学家预测未来几十年,岛屿边缘一个像素的范围会被海水淹没。具体来说如果一块陆地像素与海洋相邻(上下左右四个相邻像素中有海洋),它就会被淹没。
例如上图中的海域未来会变成如下样子:
.......
.......
.......
.......
....#..
.......
.......
请你计算:依照科学家的预测,照片中有多少岛屿会被完全淹没。
输入描述
第一行包含一个整数 (1≤N≤1000)N (1≤N≤1000)。
以下 N行 N 列代表一张海域照片。
照片保证第 1 行、第 1 列、第 N 行、第 N 列的像素都是海洋。
输出一个整数表示答案。
输入输出样例
示例
输入
7
.......
.##....
.##....
....##.
..####.
...###.
.......
输出
1
运行限制
- 最大运行时间:1s
- 最大运行内存: 256M
思路
- 计算步骤:遍历一个连通块(找到这个连通块的所有#,并标记已经搜过,不用再搜);再遍历下一个连通块,统计有多少个连通块
- 计算复杂度:因为每个像素点只搜索一次且必须至少搜一次,一共有 N2个点,复杂度为O(N2),不可能更好了。
代码模板1(DFS)
#include <bits/stdc++.h>
using namespace std;
const int N=1010;
char mp[N][N];
int st[N][N];
int ji=0,ans;
int d[4][2]={{1,0},{-1,0},{0,-1},{0,1}};
void dfs(int x,int y)
{
st[x][y]=1;
if(mp[x+1][y]=='#'&&mp[x-1][y]=='#'&&mp[x][y+1]=='#'&&mp[x][y-1]=='#')
ji=1;
for(int i=0;i<4;i++)
{
int tx=x+d[i][0],ty=y+d[i][1];
if(st[tx][ty]==0&&mp[tx][ty]=='#')
{
dfs(tx,ty);
}
}
}
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)cin>>mp[i]+1;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
{
if(mp[i][j]=='#'&&st[i][j]==0)
{
dfs(i,j);
if(ji==0)ans++;
ji=0;
}
}
cout<<ans;
return 0;
}
Tips
st[tx][ty]==0,如果没有这个条件,那么很多点会重复进行DFS,导致超时。这一种剪枝技术,叫做"记忆化搜索"。
代码模板2(BFS)
#include <bits/stdc++.h>
using namespace std;
const int N=1010;
char mp[N][N];
int st[N][N];
int ji=0,ans;
int d[4][2]={{1,0},{-1,0},{0,-1},{0,1}};
void bfs(int x,int y)
{
queue<pair<int,int>>q;
q.push({x,y});
while(q.size())
{
auto t=q.front();
q.pop();
int tx=t.first,ty=t.second;
if(mp[tx+1][ty]=='#'&&mp[tx-1][ty]=='#'&&mp[tx][ty+1]=='#'&&mp[tx][ty-1]=='#')
ji=1;
for(int i=0;i<4;i++)
{
int dx=tx+d[i][0],dy=ty+d[i][1];
if(st[dx][dy]==0&&mp[dx][dy]=='#')
{
st[dx][dy]=1;
q.push({dx,dy});
}
}
}
}
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++)cin>>mp[i]+1;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
{
if(mp[i][j]=='#'&&st[i][j]==0)
{
bfs(i,j);
if(ji==0)ans++;
ji=0;
}
}
cout<<ans;
return 0;
}
代码模板3(并查集)
#include <bits/stdc++.h>
using namespace std;
const int N=1010,M=N*N;
char mp[N][N];
int s[M],de[M];
int n,ans;
int d[4][2]={{1,0},{-1,0},{0,-1},{0,1}};
int find(int x)
{
if(x!=s[x])s[x]=find(s[x]);
return s[x];
}
void merge(int x,int y)
{
int t=0;
int ry=find((x-1)*n+y);
for(int i=0;i<4;i++)
{
int tx=x+d[i][0],ty=y+d[i][1];
if(mp[tx][ty]=='#')
{
t++;
int rx=find((tx-1)*n+ty);
if(rx!=ry)s[rx]=ry;
}
}
if(t==4)de[ry]=1;
}
int main()
{
cin>>n;
for(int i=1;i<M;i++)s[i]=i;
for(int i=1;i<=n;i++)cin>>mp[i]+1;
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
{
if(mp[i][j]=='#')
merge(i,j);
}
for(int i=1;i<=n*n;i++)
if(mp[i/n+1][i%n]=='#'&&s[i]==i&&de[i]==0)ans++;
cout<<ans;
return 0;
}
Tips
通过并查集把每一个连通块连为一个集合,维护一个数组de[]用来存储是否当前集合所在的岛屿不会被淹没,如果不会被淹没记为1,最后遍历整个集合把那些没有标记过的累加起来就是答案。(一维区间和二维区间的转化可以自己动手算算很简单)。
习题
洛谷
DFS:P1219/P1019/P5194/P5440/P1378
BFS:P1162/P1443/P3956/P1032/P1126
poj
2488/3083/3009/1321/3278/1426/3126/3414/2251
声明
本文是《算法竞赛》的笔记,仅此而已。