1.算法描述
电力系统是由电力网和电力用户组成,其任务是给广大用户不间断地提供优质电能,满足各类负荷的需求。由于电能的生产、输送、分配和消费是同时完成的,难以大量储存,这就要求系统发电出力随时紧跟系统负荷的变化以达到动态平衡,否则就会影响供用电的质量,重则危及电力系统的安全与稳定。因此,电力系统负荷预测已成为电力系统中的一项重要课题,也是电力系统自动化领域中的一项重要内容。电力负荷预测就是在充分考虑一些重要的系统运行特性、增容决策、自然条件与社会影响的条件下,研究或利用一套系统地处理过去和未来负荷的数学方法,在满足一定精度要求的意义下,确定未来某特定时刻的负荷数值。对于发电公司,负荷预测是制定发电计划、机组检修计划以及报价的依据。对于供电公司,负荷预测是制定购电计划的主要依据。对于输电公司,负荷预测是进行电网规划及保证系统安全、可靠、经济运行的基础。因此,电力负荷预测精度的高低直接关乎电力企业的经济效益。电力负荷预测按时间期限通常分为长期、中期、短期和超短期负荷预测。短期负荷预测是指一年以内以月为单位的负荷预测,还指以周、天、小时为单位的负荷预测,主要用于电力系统的调度。准确的短期负荷预测结果有利于做出适当的计划电力交易量,提出恰当的运行计划和竞标策略,也有利于用电计划的管理,节煤、节油和降低发电成本,制订合理的电源建设规划,提高电力系统的经济效益和社会效益。
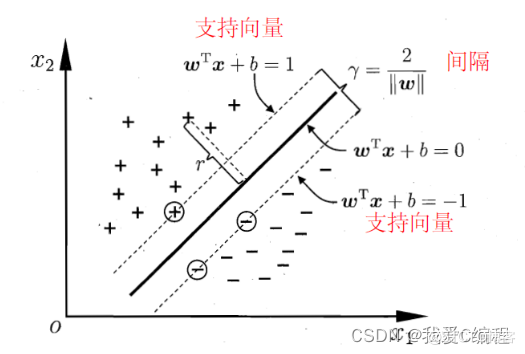
支持向量机是在统计学习理论的基础上发展起来的机器学习方法,其核心内容是vaPnik等人在1992年至1995年之间提出的。SVM实现了结构风险最小化(Structural Risk Minimization,SRM)归纳原则,在解决小样本、高维数、非线性、局部极小值等问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中.
短期负荷预测需要大量的历史负荷数据,因此,准确的预测首先要重视原始数据的收集和分析。这些数据除了受测量设备本身或者数据传输中的种种原因影响外,还有人为拉闸限电等因素的影响,使历史负荷数据中某一天的数据可能出现和包含有数据缺失、非真实的数据和异常波动数据,通常称之为不良数据或坏数据。数据预处理就是在利用历史负荷数据之前,先对其进行加工,去除不规则数据和填补缺失数据,消除不良数据或坏数据的影响,以保证负荷预测的准确性。
支持向量机(support vector machines, SVM)是二分类算法,所谓二分类即把具有多个特性(属性)的数据分为两类,目前主流机器学习算法中,神经网络等其他机器学习模型已经能很好完成二分类、多分类,学习和研究SVM,理解SVM背后丰富算法知识,对以后研究其他算法大有裨益;在实现SVM过程中,会综合利用之前介绍的一维搜索、KKT条件、惩罚函数等相关知识。本篇首先通过详解SVM原理,后介绍如何利用python从零实现SVM算法。
实例中样本明显的分为两类,黑色实心点不妨为类别一,空心圆点可命名为类别二,在实际应用中会把类别数值化,比如类别一用1表示,类别二用-1表示,称数值化后的类别为标签。每个类别分别对应于标签1、还是-1表示没有硬性规定,可以根据自己喜好即可,需要注意的是,由于SVM算法标签也会参与数学运算,这里不能把类别标签设为0。
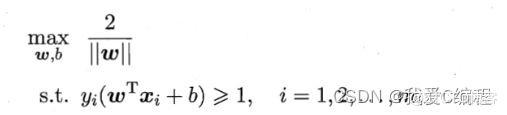
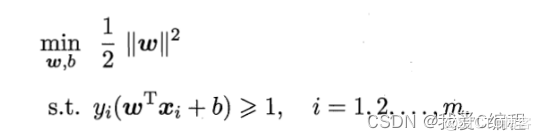
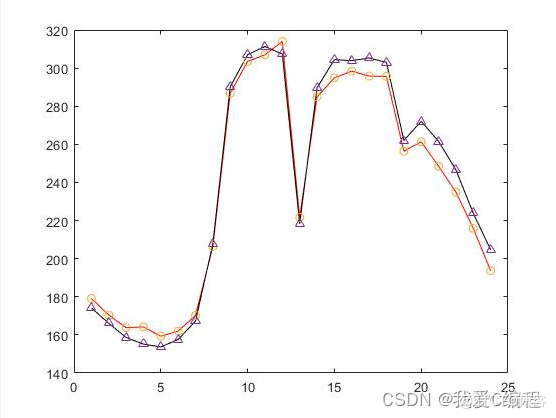
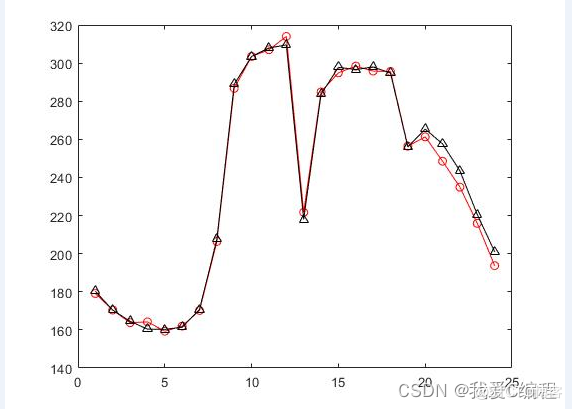
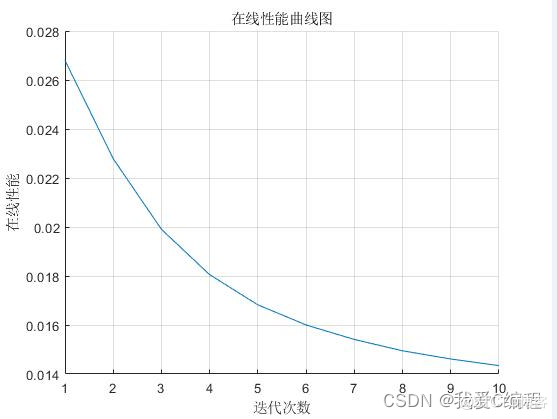
2.仿真效果预览
matlab2022a仿真结果如下:
3.MATLAB核心程序
ParticleScope=[0.1,150;
0.1,10];
ParticleSize=2;
SwarmSize=20;
LoopCount=10;
opt=zeros(LoopCount,3);
MeanAdapt=zeros(1,LoopCount);
OnLine=zeros(1,LoopCount);
OffLine=zeros(1,LoopCount);
%控制显示2维以下粒子维数的寻找最优的过程
% DrawObjGraphic(ParticleSize,ParticleScope,AdaptFunc(XX,YY));
[ParSwarm,OptSwarm]=InitSwarm(SwarmSize,ParticleSize,ParticleScope);
%开始更新算法的调用
for k=1:LoopCount
%显示迭代的次数:
disp('----------------------------------------------------------')
TempStr=sprintf('第 %g次迭代',k);
disp(TempStr);
disp('----------------------------------------------------------')
%在测试函数图形上绘制初始化群的位置
%if 2==ParticleSize
% for ParSwarmRow=1:SwarmSize
% stem3(ParSwarm(ParSwarmRow,1),ParSwarm(ParSwarmRow,2),ParSwarm(ParSwarmRow,5),'r.','markersize',8);
%end
%end
%暂停让抓图
% disp('开始迭代,按任意键:')
%pause
%调用一步迭代的算法
[ParSwarm,OptSwarm]=BaseStepPso(ParSwarm,OptSwarm,ParticleScope,0.9,0.4,LoopCount,k);
% if 2==ParticleSize
% for ParSwarmRow=1:SwarmSize
% stem3(ParSwarm(ParSwarmRow,1),ParSwarm(ParSwarmRow,2),ParSwarm(ParSwarmRow,5),'r.','markersize',8);
% end
%end
t=OptSwarm(SwarmSize+1,1);
u=OptSwarm(SwarmSize+1,2);
YResult=AdaptFunc(t,u);
str=sprintf('%g步迭代的最优目标函数值%g',k,YResult);
disp(str);
%记录每一步的平均适应度
MeanAdapt(1,k)=mean(ParSwarm(:,2*ParticleSize+1));
end
%for循环结束标志
%记录最小与最大的平均适应度
MinMaxMeanAdapt=[min(MeanAdapt),max(MeanAdapt)];
%计算离线与在线性能
for k=1:LoopCount
OnLine(1,k)=sum(MeanAdapt(1,1:k))/k;
OffLine(1,k)=max(MeanAdapt(1,1:k));
end
for k=1:LoopCount
OffLine(1,k)=sum(OffLine(1,1:k))/k;
end