产品官网:https://www.huaweicloud.com/product/hecs-light.html

今天我们采用可靠更安全、智能不卡顿、价优随心用、上手更简单、管理特省心的华为云耀云服务器L实例为例,继续Hive的部署
Hive 是建立在 Hadoop 上的一个数据仓库和查询系统。它提供了类似 SQL 的查询语言(称为 HiveQL)来查询和分析存储在 Hadoop 分布式文件系统(HDFS)中的大规模数据。Hive 的设计目标是使非技术用户能够通过类似于 SQL 的语言来查询和分析大规模数据集,而无需深入了解复杂的编程模型。
以下是 Hive 的一些主要特点和概念:
1. HiveQL语言: Hive 提供了 Hive 查询语言(HiveQL),这是一种类似于 SQL 的语言,允许用户执行查询、过滤和聚合等操作。HiveQL查询会被转化为一系列的 MapReduce 作业,从而在底层利用 Hadoop 进行分布式计算。
2. 元数据存储: Hive 使用元数据存储来存储表模式和统计信息。默认情况下,它使用嵌入式的 Derby 数据库,但也可以配置为使用其他数据库,如 MySQL 或 PostgreSQL。
3. 表和分区: Hive中的数据组织为表,表可以分为分区以提高查询性能。分区允许根据表中的某些列将数据划分为更小的部分,以便更有效地执行查询。
4. UDF(用户定义函数): Hive 支持用户定义的函数,这允许用户编写自定义的处理逻辑,并将其嵌入到 HiveQL 查询中。
5. 可扩展性: Hive 可以与 Hadoop 生态系统中的其他工具集成,包括 HBase、Spark、Tez 等,以便更灵活地处理不同类型的数据和查询。
6. 批处理: Hive 通常用于大规模批处理,适用于处理大量的静态数据。对于需要实时性能的场景,可能需要考虑其他工具,如 Apache Spark。
Hive 的使用场景主要涉及数据仓库和数据分析,特别是当数据规模很大,而且对实时性能没有过高要求时。通过使用 HiveQL,用户可以利用 SQL 风格的查询语言来分析和挖掘庞大的分布式数据集。
以下是在华为云耀云服务器L实例配置Hive的步骤。
(1) 配置 Hadoop
Hive 的运行依赖于 Hadoop ( HDFS 、 MapReduce 、 YARN 都依赖)
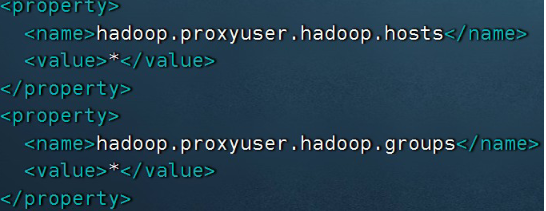
同时涉及到 HDFS 文件系统的访问,所以需要配置 Hadoop 的代理用户
即设置 hadoop 用户允许代理(模拟)其它用户
配置如下内容在 Hadoop 的 core-site.xml 中,重启 HDFS 集群
(2) 下载解压 Hive
• 切换到 hadoop 用户
su - hadoop
• 下载 Hive 安装包:
http://archive.apache.org/dist/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
• 解压到 node1 服务器的: /export/server/ 内
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
• 设置软连接
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive

(3) 提供 MySQL Driver 包
• 下载 MySQL 驱动包:
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.34/mysql-connector-java-
5.1.34.jar
• 将下载好的驱动 jar 包,放入: Hive 安装文件夹的 lib 目录内
mv mysql-connector-java-5.1.34.jar /export/server/hive/lib/

(4) 配置 Hive
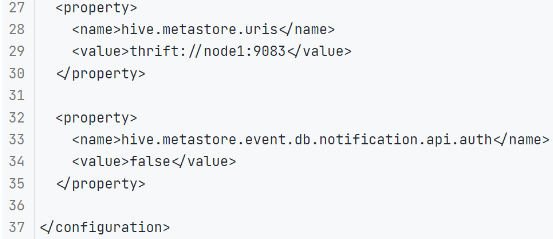
• 在 Hive 的 conf 目录内,新建 hive-site.xml 文件,填入以下内容

(5)初始化元数据库
至此, Hive 的配置已经完成,现在在启动 Hive 前,需要先初始化 Hive 所需的元数据库。
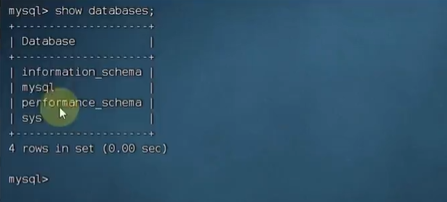
• 在 MySQL 中新建数据库: hive
CREATE DATABASE hive CHARSET UTF8;
• 执行元数据库初始化命令:
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos

(6)启动 Hive (使用 Hadoop 用户)
• 确保 Hive 文件夹所属为 hadoop 用户
• 创建一个 hive 的日志文件夹:
mkdir /export/server/hive/logs
• 启动元数据管理服务(必须启动,否则无法工作)
前台启动: bin/hive --service metastore
后台启动: nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
• 启动客户端,二选一(当前先选择 Hive Shell 方式)
Hive Shell 方式(可以直接写 SQL ): bin/hive
Hive ThriftServer 方式(不可直接写 SQL ,需要外部客户端链接使用): bin/hive --service hiveserver2
至此,我们已经成功在华为云耀云服务器L实例部署并启动了单台服务器上的hive服务。