台积电3nm芯片市场与技术分析
数十家芯片厂,用上了台积电3nm?
为现代、领先的制造技术设计芯片是一项昂贵的工作。不过,根据台积电和新思科技披露的信息,已有数十家公司采用了 台积电的 N3 和 N3E(3 纳米级)制造工艺。
Synopsys IP营销和战略高级副总裁 John Koeter 表示:“用于台积电 3nm 工艺的 Synopsys IP 已被数十家领先公司采用,以加快其开发速度、快速实现芯片成功并加快上市时间。”
自 2022 年底以来,台积电一直使用其最新的 N3(又名 N3B)制造技术(最多 25 个 EUV 层并支持 EUV 双图案化)生产芯片,并打算开始采用其简化的 N3E 制造工艺(最多 19 个 EUV层和没有 EUV 双图案)在 2023 年第四季度。
此前,台积电透露,其 N3 节点已被高性能计算 (HPC) 和智能手机 SoC的设计者采用 ,并且在其生命周期早期,采用者数量比 N5 更高。与此同时,台积电从未提及有多少家公司决定使用其 3 纳米级制造工艺。
Synopsys 是一家主要的 IP 开发商和电子设计自动化工具提供商,因此当它表示数十家公司已将其 IP 授权用于台积电的 N3 制造技术时,意义重大。但 Synopsys 并不是唯一的 IP 设计商,Cadence 等公司也向其他无晶圆厂芯片开发商提供其 N3 兼容 IP。可以肯定地说,他们的客户数量也很可观。
台积电的 N3 系列工艺技术包括基准 N3 (N3B)、宽松的 N3E(晶体管密度略有降低,但扩大了工艺窗口以提高产量)、与 N3E IP 兼容的性能增强型 N3P 将于 2024 年下半年投入生产, N3X 用于将于 2025 年推出的超高性能应用。
Synopsys 目前授权的 IP 可用于 N3、N3E 和 N3P 生产节点。
台积电官方论文,详细解读3nm
本文介绍了业界最快的3nm CMOS平台技术可行性。与传统FinFET技术相比,首次引入了具有由不同鳍配置组成的标准单元的FinFlex™,以提供关键的设计灵活性,从而实现更好的功率效率和性能优化。与我们之前的5nm CMOS工艺相比,实现了约1.6X逻辑密度的大幅扩展、18%的速度提高和34%的功率降低。这种FinFlex™平台技术提供了一流的PPAC价值,以充分满足5G和HPC应用中的产品创新。
简介
近年来,人工智能应用的激增和5G的部署一直是数据中心高性能计算以及边缘设备低功耗联网和处理能力的驱动力。随着机器学习在需要快速和准确处理大数据的广泛行业中被迅速采用,HPC正成为下一个关键的增长动力。具有最高性能和最佳功率效率的先进CMOS逻辑技术比以往任何时候都更重要,它将为我们的日常生活和社会的各个方面带来创新。
本文介绍了最先进的3nm平台技术,该技术具有目标器件性能、标准单元设计和关键基本规则的扩展创新。除了成功地将批量FinFET扩展到3nm节点之外,FinFlex™标准单元创新还提供了多单元架构所需的更大设计灵活性。该技术与跨越200mV的6 Vt产品相结合,提供了前所未有的设计灵活性,以最具竞争力的逻辑密度满足广泛的功率效率SoC需求和HPC应用的高性能需求。这一过程已在由高密度和高电流SRAM宏和逻辑测试芯片组成的开发测试车上得到验证。
设计灵活性–FinFlex™和多Vt
FinFlex™是一种具有不同散热片配置的创新标准单元架构,首次在这项3nm技术中引入。伴随着关键层的传统间距缩放,它实现了全节点的逻辑密度增加。为了进一步减少FinFET的面积,业界采用的典型方法是翅片间距缩放和翅片数量减少。随着翅片间距已经低于30nm,翅片数量减少到单个翅片,工艺变化和设备驱动能力不足成为进一步扩大规模的主要障碍。FinFlex™提供了如图1所示的几种配置,以解决缩放和性能之间的权衡问题。2-1鳍配置实现了面积减少,而不牺牲功率敏感应用的性能。二鳍器件可用于关键路径以利用其更高的电流,而单个鳍用于减少漏电流,它是迄今为止密度最高功耗最低的标准单元。类似地,3-2鳍配置,配备3鳍以获得更高的驱动电流,非常适合性能要求高的应用。在需要性能、功率和密度之间的良好平衡的情况下,可以应用常规的2-2鳍配置。与常规标准单元中仅具有晶体管级电容减少的简单鳍片切割不同,FinFlex™通过共同优化BEOL位置和路径,提供单元级面积缩放以及芯片级电容减少。此外,在该技术中有6种不同的Vt产品,设计者可以为单个N/PMOS选择不同的鳍数和Vt组合,以满足同一芯片上的宽范围速度和泄漏要求。图2显示了与我们的5nm节点相比,此3nm FinFlex™技术的ARM Cortex-72 CPU性能和面积改进。功率效率高的2-1cell在0.64X区域显示出30%的功率降低和11%的速度增益;高性能3-2配置,在0.85X面积下速度增益33%,功率降低12%;并且在0.72X区域,平衡的2-2单元23%的速度增益和22%的功率降低。这一创新是成功延长FinFET架构寿命的关键组件之一,适用于另一个全技术节点。
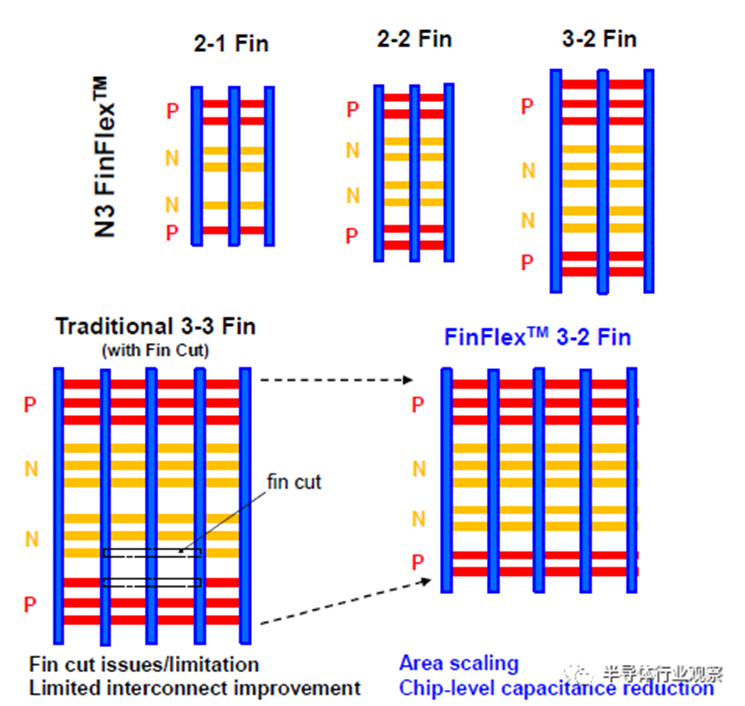
图1 FinFlex™示意图以及与传统方案的比较。与传统FinFET设计相比,面积减少和芯片级电容显著减少是该创新的主要优势。
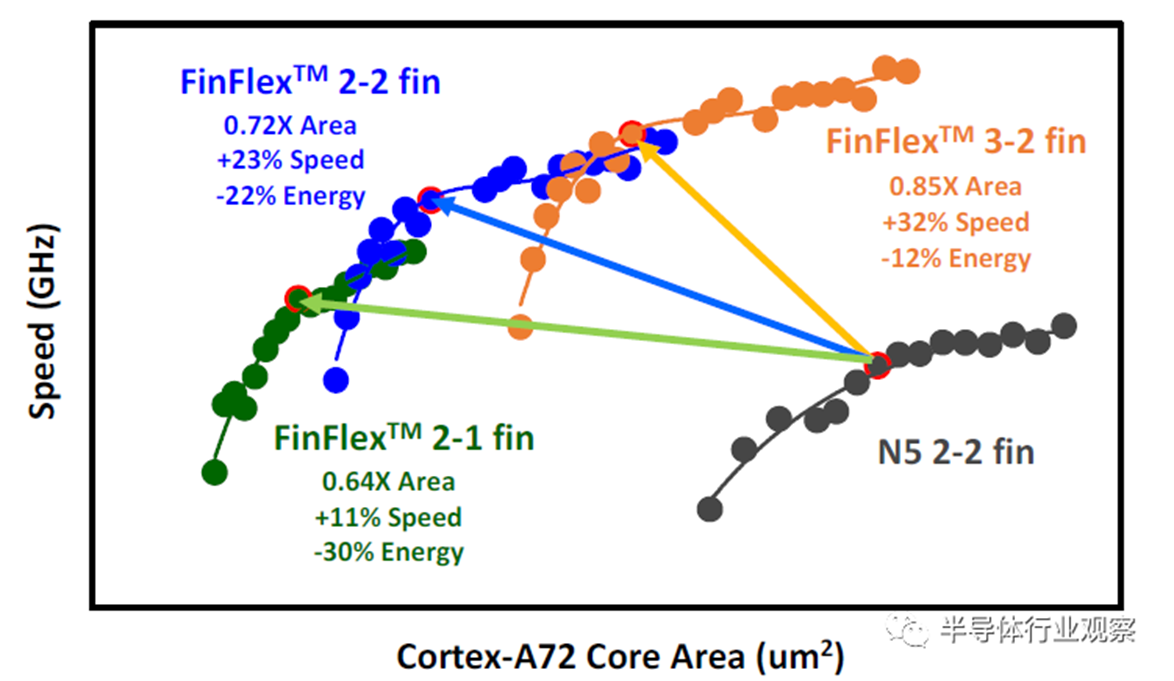
图2 ARM Cortex-A72中的FinFlex™改进。FinFlex™ 2-1鳍配置的目标是超功率效率、2-2鳍高效功率和3-2鳍超高性能。每种配置都显示了N5技术的不同面积、速度和能效改进。
工艺架构
除了新颖的标准单元特性外,还采用了临界接地规则进行缩放,以实现比以前的5nm节点提高约1.6X的逻辑密度。在不同的鳍片布置中,鳍片宽度和外形优化在减小的栅极长度下保持所需的短沟道效应。实施低K间隔物以减少接触和栅极之间的寄生电容,而不影响产量和可靠性。具有双外延工艺的凸起源极/漏极被优化以提供沟道应变并降低源极/漏电极(S/D)电阻。第六代高K金属栅极(HK/MG)RMG工艺支持内核和I/O器件。新的接触方案和工艺解决方案在生产线的中降低了紧密CPP缩放的寄生电阻,同时保持了可观的产量和可靠性。我们还开发了先进的Cu/低k互连方案,该方案具有积极缩放的最小金属间距工艺。创新的屏障和衬垫工程以及图案化优化使BEOL金属和通孔RC保持在轨道上,而不会因缩放而影响芯片性能。
晶体管性能
基于品质因数(FOM),该3nm技术的2-1鳍配置提供了18%的等功率速度增益,或在相同速度下比我们的5nm技术降低了34%的功率,如图3所示。我们优化了鳍的宽度和轮廓,以在目标缩放Lg(图4)处获得约50mV/V的DIBL,证明FinFET在3nm节点处仍然是可行的架构。FOM性能以及NMOS和PMOS器件分别实现了该技术的目标性能,如图5和图6所示。为了充分实现FinFlex™的预期效益,消除可能降低固有翅片性能的翅片数量差异引起的负载效应至关重要。单鳍器件尤其脆弱,因为许多工艺步骤,例如蚀刻和外延,自然地与多鳍结构所经历的工艺步骤不同。图7显示,经过工艺优化后,2-1鳍配置的单鳍器件与设计一样,其二鳍对应器件的有功功率约为50%。对于高速应用,如图8所示,3-2鳍配置的速度增加了9%以上。六种电压范围>200mV的不同Vt选项(图9)可供选择,以进一步提供电源性能权衡的设计灵活性。由于器件变化在设计裕度预算中变得越来越重要,因此我们还实施了专门针对对抗变化的工艺改进,以将NMOS和PMOS的器件Vt失配(AVt)降低20%,如图10所示。对于I/O器件,图11中的LDD注入优化根据SCE控制所需的鳍轮廓将Iboff降低了2个数量级以上。

图3 FinFlex™ 2-1cell在固定功率下提供18%的SPD增益或在固定速度下降低34%的功率
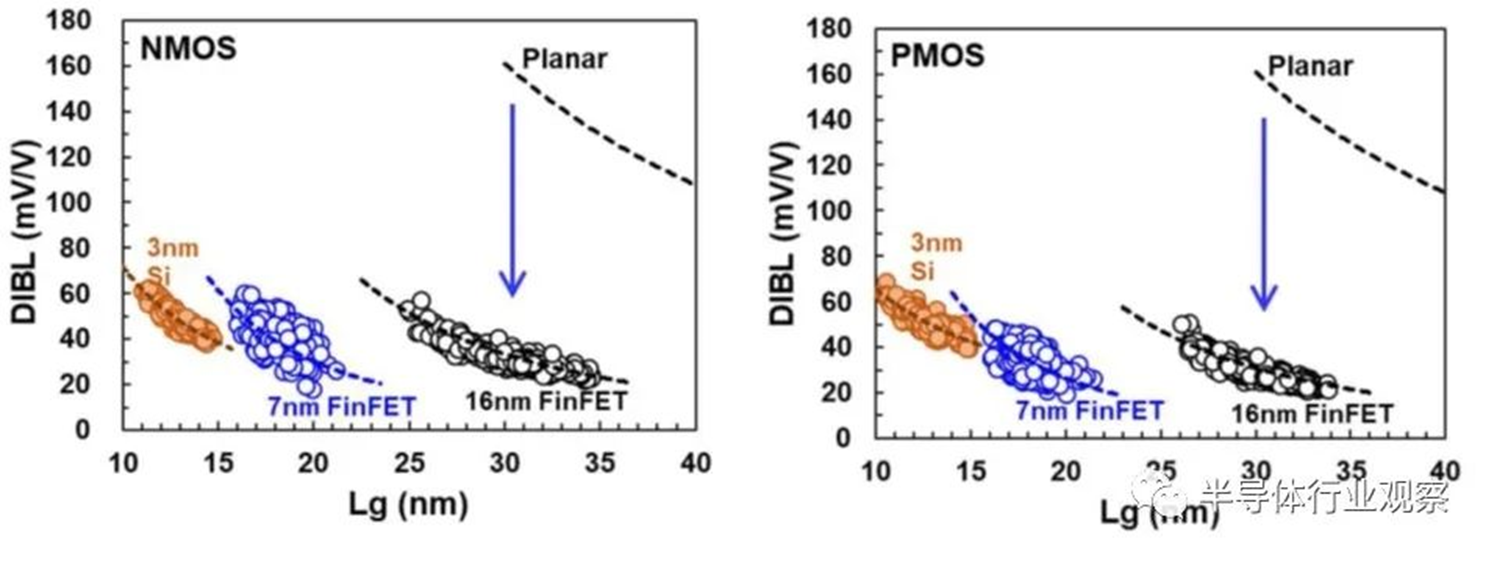
图4 FinFET SCE的改进继续支持3nm技术所需的Lg缩放。
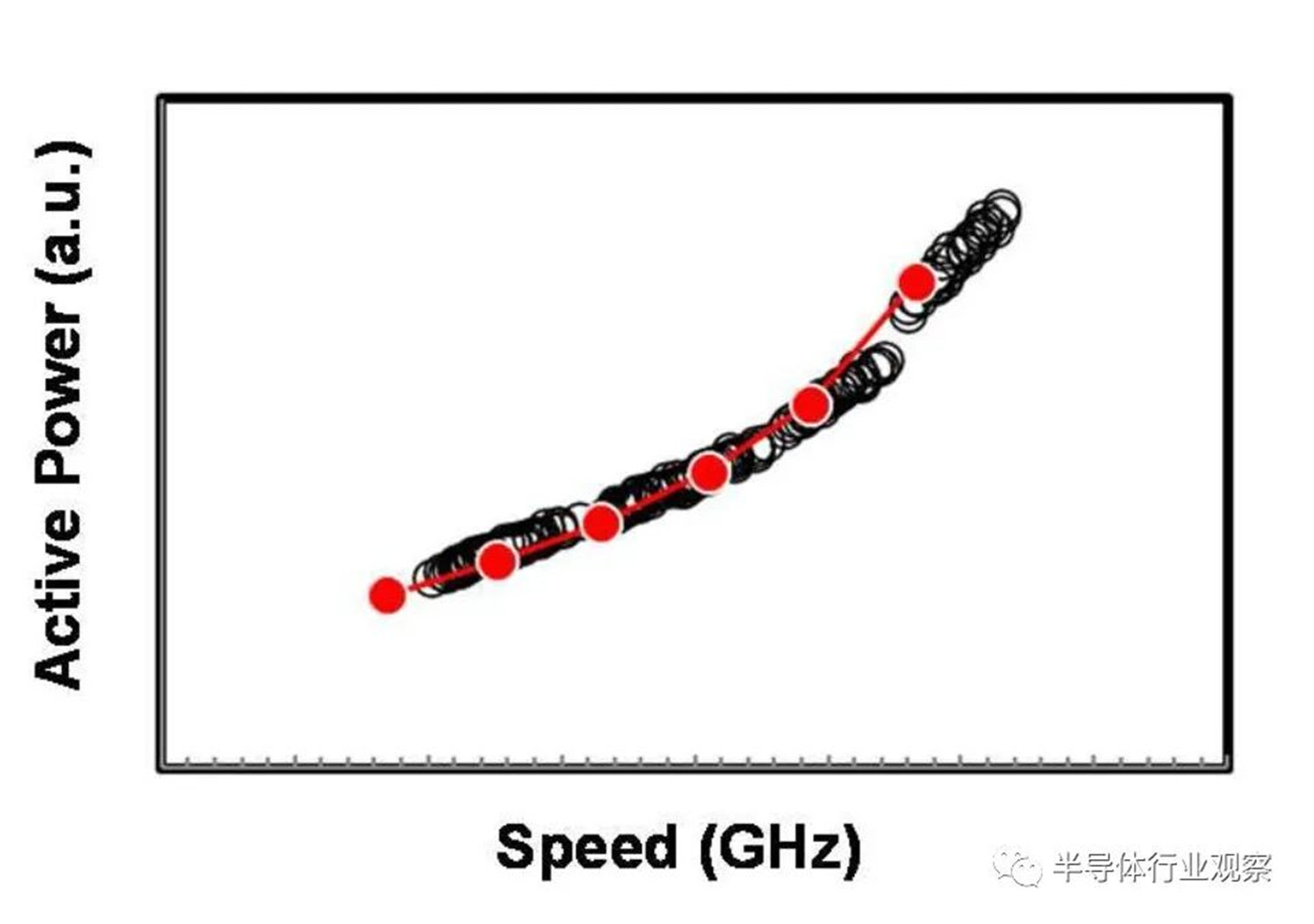
图5 品质因数(FOM)结构实现了所有Vt的目标功率速度性能。
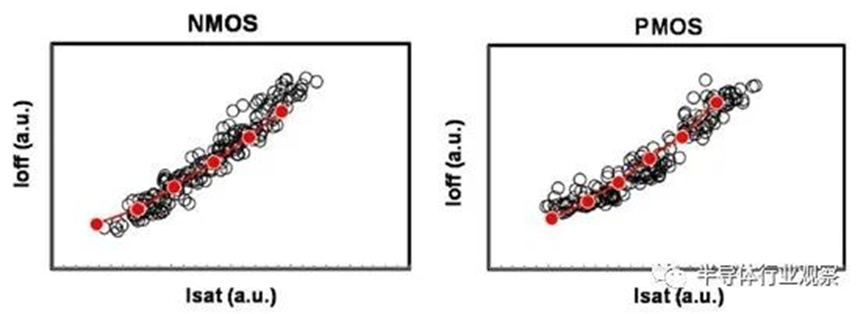
图6 NMOS和PMOS器件都显示了目标性能。
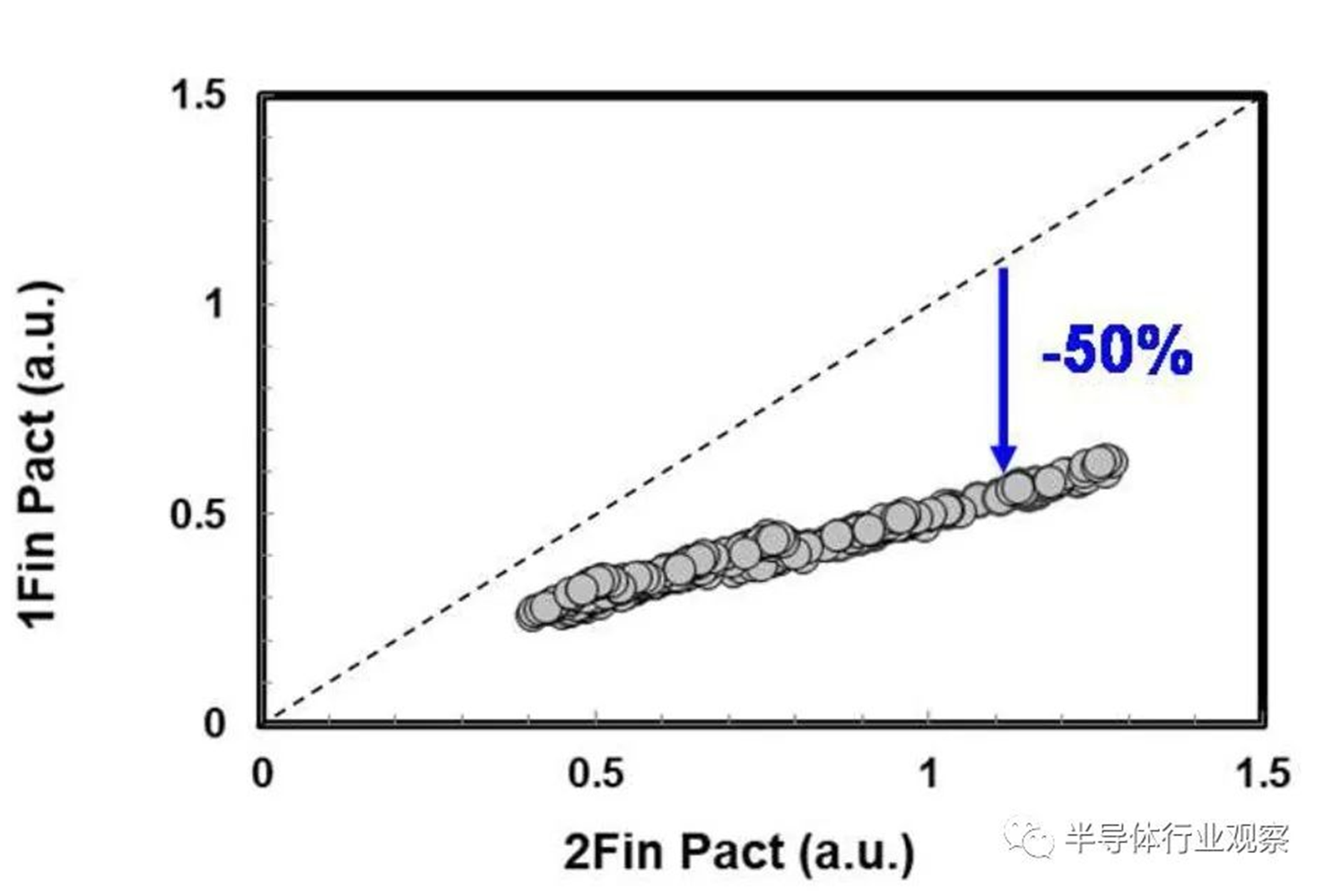
图7 1-fin器件显示出50%的有功功率降低,不存在工艺负载引起的退化。
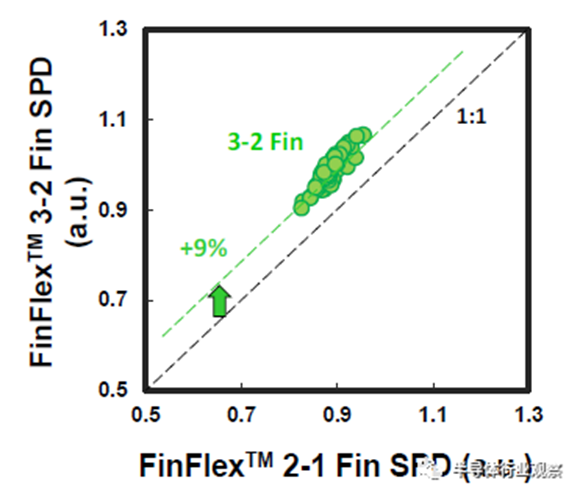
图8 FinFlex™ 3-2鳍具有额外的9% SPD增益。
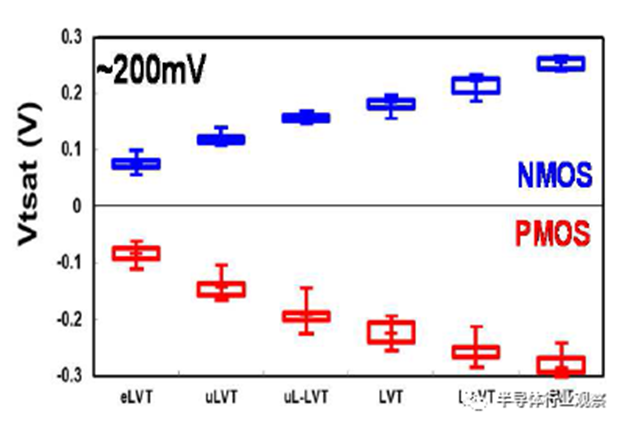
图9 六种不同的Vt选项,跨度约200mV。
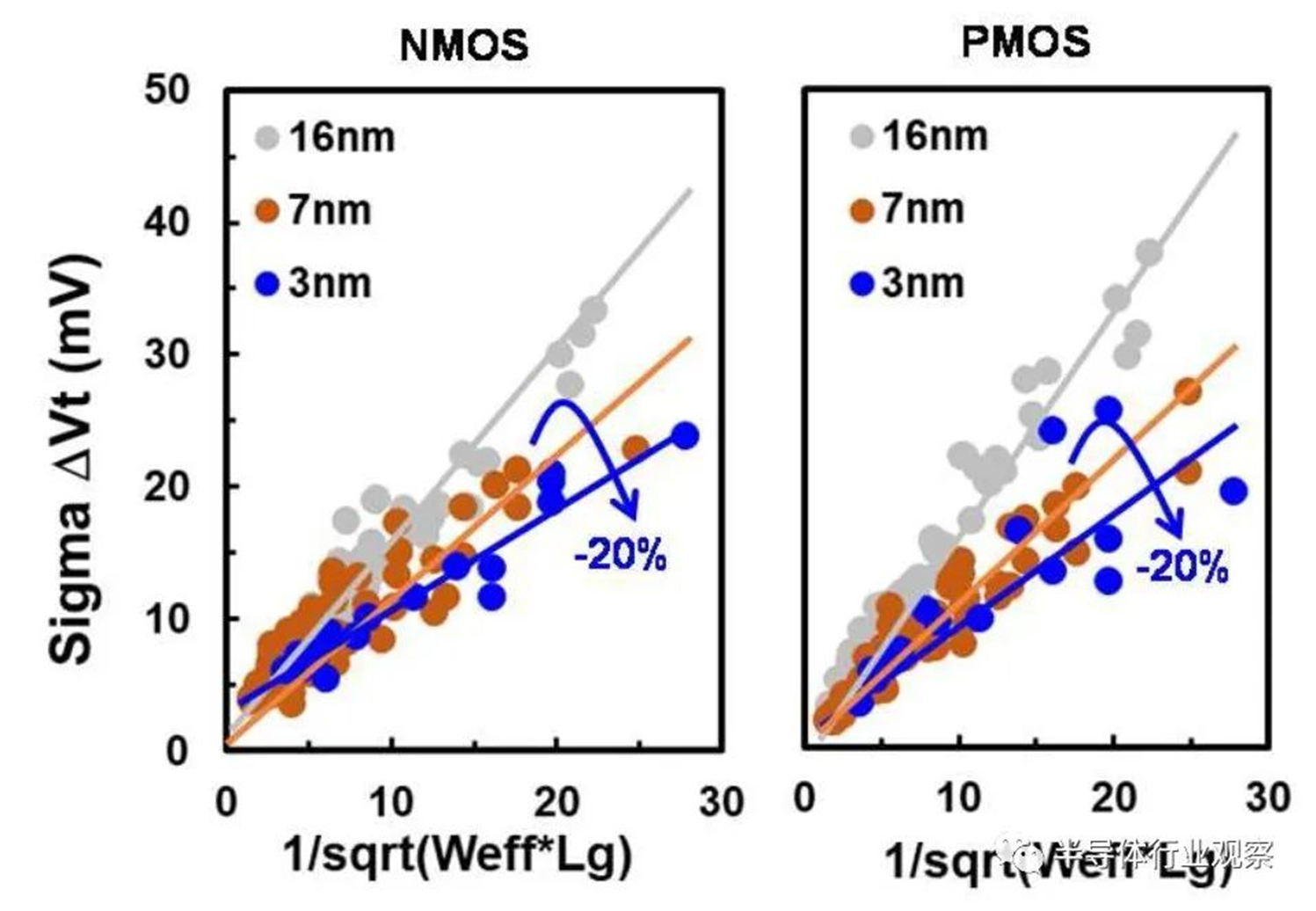
图10 展示了优异的失配性能。
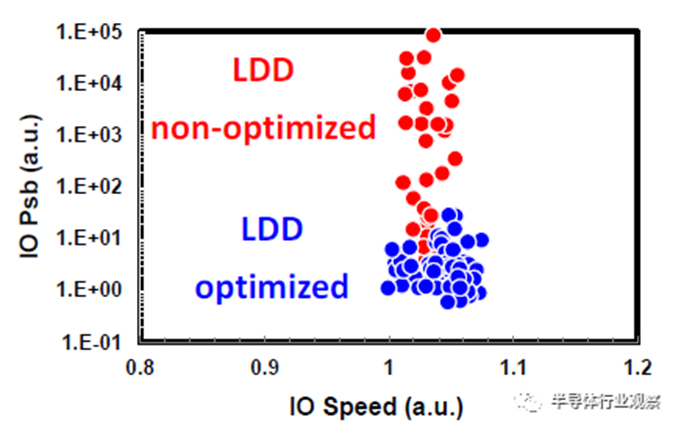
图11 I/O器件Psb与速度的关系。通过LDD优化,Iboff显著降低。
互连技术
互连工艺在决定芯片整体性能方面发挥了越来越重要的作用。对于这种3nm技术,23nm处的最小金属间距用于实现FinFlex™ 2-1鳍配置的缩放,同时提供所需的布线效率。据我们所知,这是迄今为止在高级节点中报告的最紧密的金属间距。采用了创新的Cu衬垫,以将标称金属宽度的最小间距RC降低20%,将2X金属宽度的结构RC降低30%,如图12所示。基于图13中的创新屏障工艺,过孔Rc显著降低了约60%,这是实现这种激进间距缩放的重要组成部分。通过检查M0和Mx层的A线与B线的金属电阻,图14中A线和B线之间的可比分布证明了工艺的鲁棒性。在上部松弛金属节距以及ELK电介质处减少阻挡层厚度,以最小化总体BEOL RC延迟。图15显示了15级Cu/低k金属堆叠的横截面图。对于6级和15级金属,堆叠接触到通孔链的紧密Rc分布证明了该封装的稳定性。同时还对BEOL过程集成的可靠性进行了检验。图16(a)和16(b)分别验证了最小间距金属的Vx/Mx和Vx/Mx+1的优异EM性能和互连SM稳定性。在应力500小时后,具有规则和宽金属的Kelvin Rc结构的电阻偏移百分比可忽略不计。此外,上一代中需要EUV双图案化的三个关键层被单EUV图案化所取代,这降低了工艺复杂性、固有成本和循环时间。

图12 间距23nm金属线RC的增加,由创新的铜衬垫工艺控制。
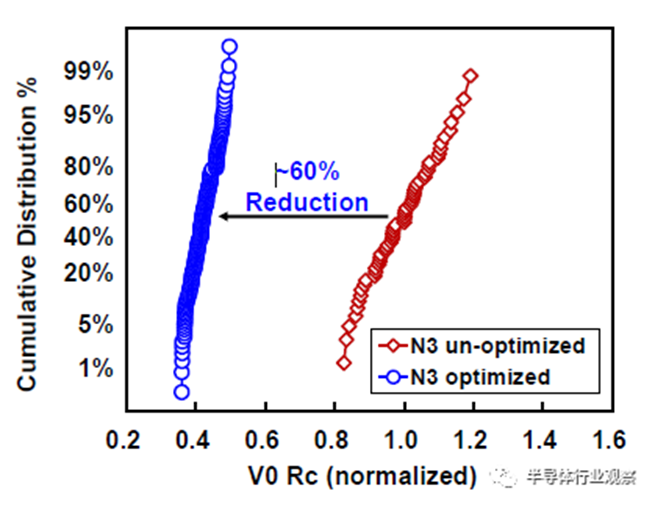
图13 通过创新的屏障工艺,在最紧密的间距处显著降低Rc。
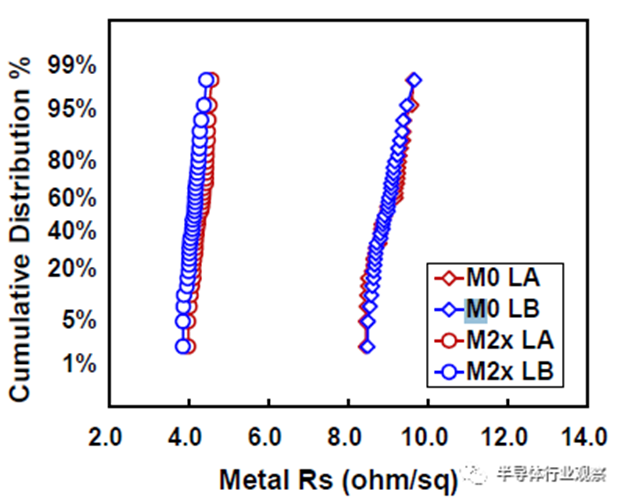
图14 A线和B线在大幅缩放间距下的M0/Mx金属电阻分布。
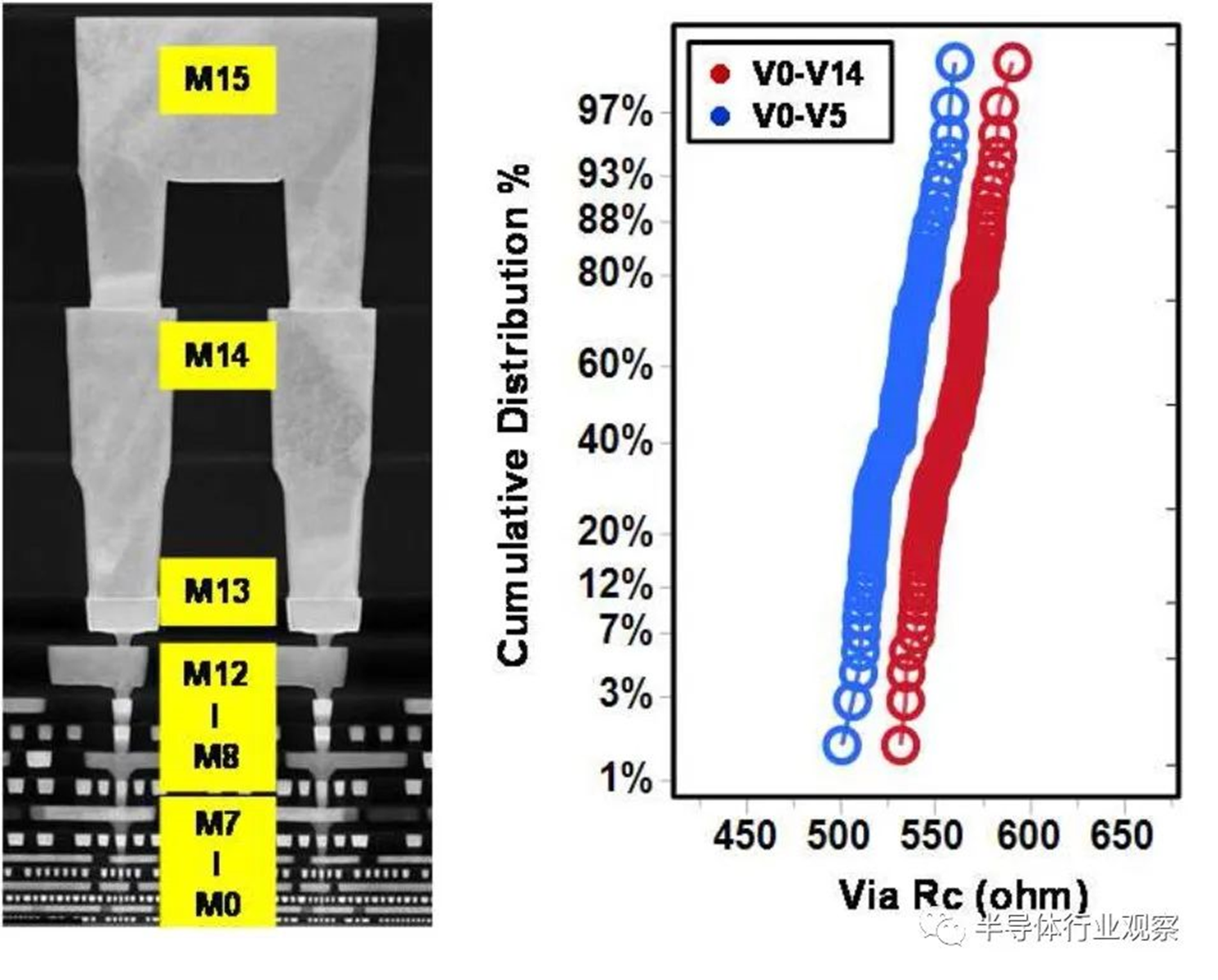
图15 15层金属叠层的TEM图像和通孔Rc叠层的紧密分布。
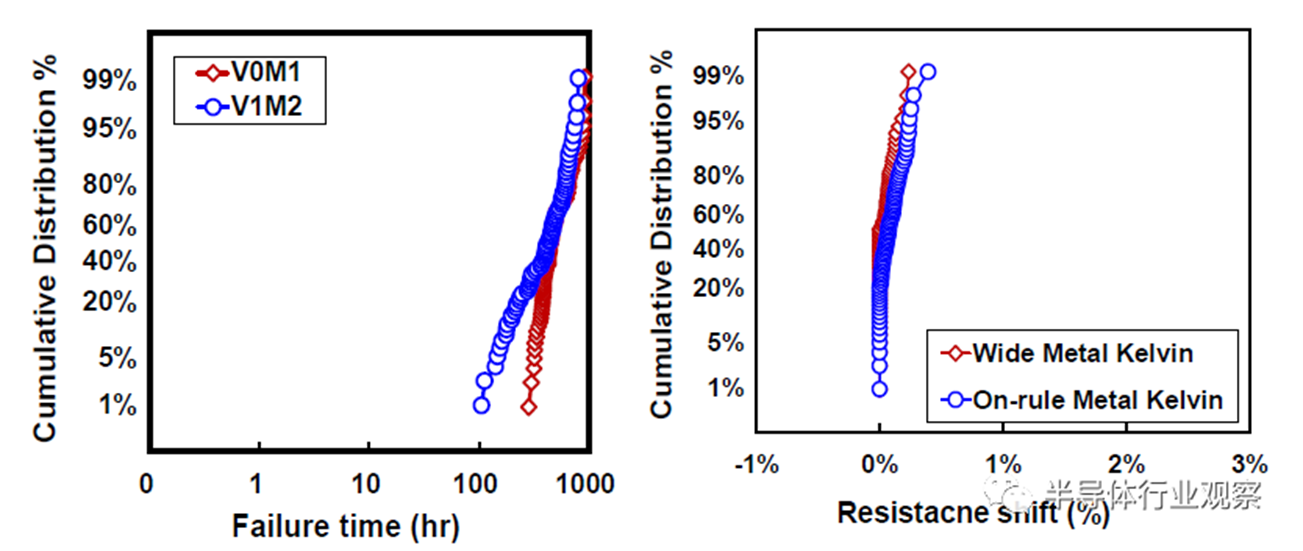
图16(a)最小螺距金属的EM性能;(b) Kelvin结构的SM。
产量和可靠性
HD和HC SRAM单元可用于低泄漏和高性能应用。由HD和HC 6-T SRAM 256Mb宏以及带有CPU/GPU/SoC块的逻辑测试芯片组成的产量学习工具可用于技术开发。0.021um2 HD SRAM单元的蝶形曲线如图17所示,其中显示了低至0.3V的单元稳定性。对于0.45V和0.6V操作,静态噪声容限(SNM)分别达到97mV和124mV。图18中256Mb HD SRAM宏的Shmoo图显示了低至0.5V的完整读写能力。256Mb HC/HD SRAM宏和类似产品的逻辑测试芯片在同一开发阶段始终显示出比我们的前几代更健康的缺陷密度。此外,两个256Mb HC/HD SRAM宏都通过了HTOL 1000小时鉴定(如图19所示),逻辑测试芯片通过了CPU的Vmin功率规格(如图20所示)。
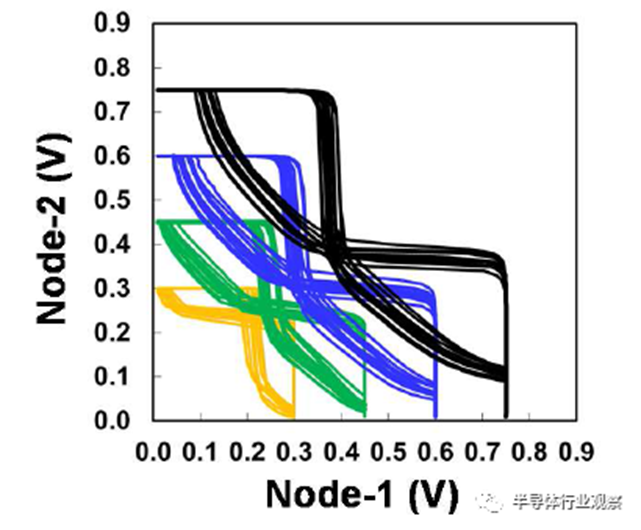
图17 0.021um²高密度6-T SRAM单元的SNM。

图18 0.021um² HD 256Mb SRAM宏的Schmoo图,具有低至0.5V的完整读/写功能。
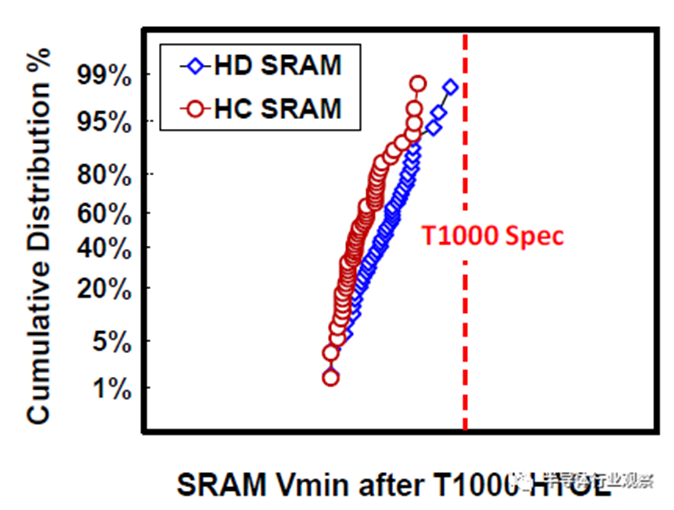
图19 HC/HD 256Mb SRAM均通过HTOL 1000小时规格。
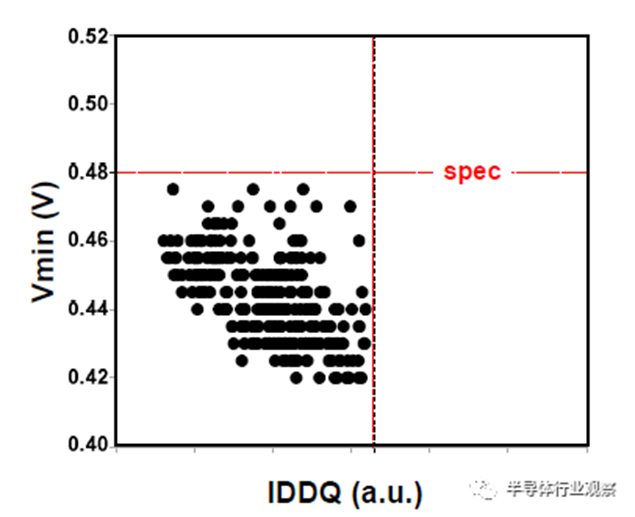
图20 Vmin对逻辑测试芯片中CPU块的IDDQ。
我们引入了业界领先的3nm FinFlex™ CMOS制造技术,该技术具有创新的设计灵活性和广泛的Vt选项。利用这一新的DTCO功能,可以将具有针对性能、功率和/或面积目标进行优化的不同功能块的产品设计集成在同一芯片上。加上关键的基本规则缩放和23nm的最小金属间距,该技术提供了迄今为止最高密度的同类最佳逻辑性能、功率效率和低Vmin SRAM。随着器件性能达到设计目标和工艺引起的变化得到适当解决,高性能HPC应用以及功率敏感SoC产品的苛刻要求都可以得到很好的满足。各种5G移动和AI/HPC应用的大规模生产技术成熟度已得到充分证明,该技术经过严格的技术鉴定,将保证稳定的产量和强大的可行性。
台积电3nm成功量产,稳了吗?
台积电在2022Q4高调宣布量产3纳米鳍式场效晶体管制程,是由原本的N3改良为N3B 制程良率较低的大约60~70%,较高的大约70~80%,表现相当亮眼,而计划在2023Q2或Q3量产的3纳米(N3E)制程良率更达80%以上, 而且价格更低更有竞争力。反观三星早在2022Q2就宣布量产3纳米环绕栅极场效晶体管(GAAFET),但是被韩国媒体爆料良率只有20%,使得台积电3纳米制程大胜三星,到底FinFET 与G AAFET有什么不同? 未来三星又会如何应对呢?
什么是集成电路(IC:Integrated Circuit)?
将电的主动元件(二极管、晶体管)与被动元件(电阻、电容、电感)缩小以后,制作在硅晶圆或砷化镓晶圆上,称为“集成电路(IC:Integrated
Circuit)”,其中”集成(Integrated)”与”电路(Circuit)”是指将许多电子元件堆积起来的意思。
将电子产品打开以后可以看到印刷电路板(PCB:Printed
Circuit Board)如图一所示,上面有许多长得很像”蜈蚣”的集成电路(IC),集成电路的尺寸有大有小,我们以处理器为例边长大约20 毫米(mm),上面一小块正方形称为“芯片(Chip)”或“晶粒(Die)”,晶片边长大约10毫米(mm), 晶片上面密密麻麻的组件称为“晶体管(Transistor)”,晶体管边长大约100纳米(nm),而晶体管上面尺寸最小的结构称为“栅极长度(Gate length)”大约10纳米(nm),这个就是我们常听到的台积电“10纳米制程”。

图一 由晶体管(Transistor)组成芯片(Chip)再封装成集成电路(IC)。资料来源:曲博科技教室。
什么是场效晶体管(FET:Field Effect Transistor)?
晶体管的种类很多,先从大家耳熟能详的”MOS”来说明。MOS的全名是”金属氧化物半导体场效晶体管(MOSFET:Metal Oxide Semiconductor Field Effect Transistor)”, 构造如图二所示,左边灰色的区域叫做”源极(Source )”,右边灰色的区域叫做”漏极(Drain)”,中间有块金属(红色)突出来叫做”栅极(Gate)”,栅极下方有一层厚度很薄的氧化物 (黄色),因为中间由上而下依序为金属(Metal)、氧化物(Oxide)、半导体(Semiconductor), 因此称为”MOS”。
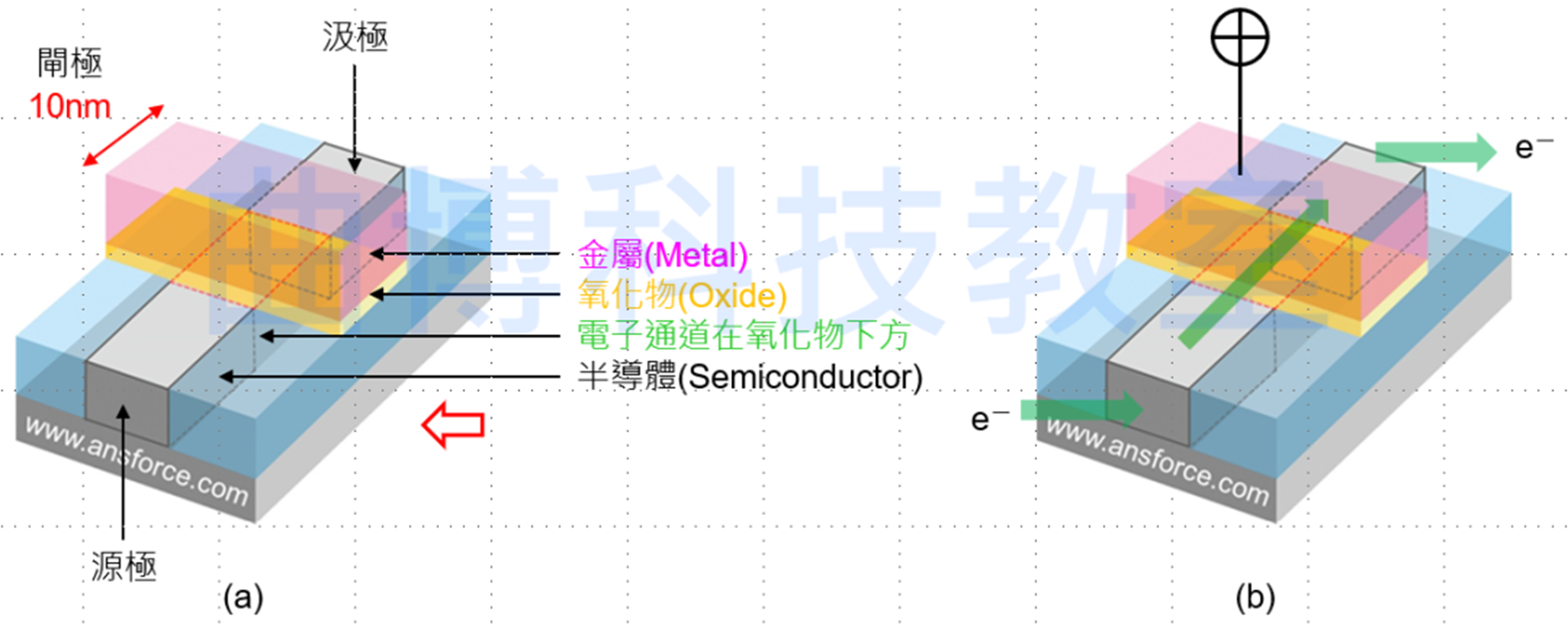
图二金属氧化物半导体场效晶体管(MOSFET)的结构与工作原理。资料来源:曲博科技教室。
MOSFET的工作原理很简单,电子由左边的源极流入,经过栅极下方的电子通道,由右边的漏极流出,中间的栅极则可以决定是否让电子由下方通过,有点像是水龙头的开关一样,因此称为”栅”; 电子是由源极流入,也就是电子的来源,因此称为”源”; 电子是由漏极流出,看看说文解字里的介绍:汲者,引水于井也,也就是由这里取出电子,因此称为”汲”。
- 当栅极不加电压,电子无法导通,代表这个组件处于”关(OFF)”的状态,我们可以想像成这个位是0,如图二(a)所示;
- 当栅极加正电压,电子可以导通,代表这个组件处于”开(ON)”的状态,我们可以想像成这个位是1,如图二(b)所示。
MOSFET是目前半导体产业最常使用的一种”晶体管(Transistor)”,科学家将它制作在硅晶圆上,是数字讯号的最小单位,我们可以想像一个 MOSFET代表一个0或一个1,就是电脑里的一个”比特(bit)”。电脑是以0与1两种数字讯号来运算,我们可以想象在硅芯片上有数十亿个MOSFET,就代表数十亿个0与1, 再用金属导线将这数十亿个MOSFET的源极、漏极、栅极连结起来,电子讯号在这数十亿个0与1之间流通就可以交互运算,最后得到我们想要的加、减、乘、除运算结果, 这就是电子计算机或电脑的基本工作原理。晶圆厂像台积电、联电,就是在硅晶圆上制作数十亿个MOSFET的工厂。
栅极长度:半导体制程进步的关键
在图二的MOSFET 中,”栅极长度(Gate length)”大约10纳米,是所有构造中最细小也最难制作的,因此我们常常以栅极长度来代表半导体制程的进步程度,这就是所谓的”制程节点(Node) “。
栅极长度会随制程技术的进步而变小,从早期的0.18、0.13微米,进步到90、65、45、22、 14纳米,到目前最新的制程10、7、5、3纳米,甚至未来的2纳米。当栅极长度愈小,则整个MOSFET就愈小,而同样含有数十亿个MOSFET的芯片就愈小,封装以后的集成电路(IC)就愈小,最后做出来的手机就愈小罗!
但是要特别留意,并不是所有的晶体管都必须便用先进制程,而是要看不同元件需要的特性来决定,目前集成电路(IC)依照特性主要分为三大类: - 数字集成电路(Digital IC):可以进行运算或储存,例如:处理器(CPU)或内存(DDR),只要承受很小的电压或电流,栅极长度愈小愈好 ,可以做到10nm(纳米)以下。
- 模拟集成电路(Analog IC):可以进行讯号放大与调变,例如:功率放大器(Power amplifier)、音频放大器(A udio amplifier),必须承受较大的电压或电流,栅极长度较大,可以做到100nm(纳米)以下。
- 功率集成电路(Power IC):可以进行电源转换,例如:功率晶体管可以将220V的交流电转换成1 10V的直流电,必须承受更大的电压或电流(功率),可以做到1μm(微米)=100 0nm(纳米)以下。
鳍式场效晶体管(FinFET):将半导体制程带入新境界
MOSFET的结构发明以来到现在已使用超过四十年,当栅极长度缩小到20纳米以下的时候遇到了许多问题,其中最麻烦的就是当栅极长度愈小,源极和漏极的距离就愈近,栅极下方的氧化物也愈薄,电子有可能偷偷溜过去产生”漏电(Leakage) “; 另外一个更麻烦的问题,原本电子是否能由源极流到漏极是由栅极电压来控制的,但是栅极长度愈小,则栅极与通道之间的接触面积愈小,如图三(a)绿色箭头所示,也就是栅极对通道的影响力愈小,要如何才能保持栅极对通道的影响力(接触面积) 呢?
因此美国加州大学伯克莱分校胡正明、Tsu-Jae King-Liu、Jeffrey Bokor等三位教授发明了”鳍式场效晶体管(FinFET:Fin Field Effect Transistor)”,把原本 2D构造的MOSFET改为3D的FinFET,如图三(b)绿色箭头所示,因为构造很像鱼鳍 ,因此称为”鳍式 (Fin)”。由图中可以看出原本的源极和漏极拉高变成立体板状结构,让源极和漏极之间的通道变成板状,则栅极与通道之间的接触面积变大了!
这样一来即使栅极长度缩小到20纳米以下,仍然保留很大的接触面积,可以控制电子是否能由源极流到漏极,因此可以更妥善的控制电流,同时降低漏电和动态功率耗损,所谓动态功率耗损就是这个FinFET由状态0变1 或由1变0时所消耗的电能,降低漏电和动态功率耗损就是可以更省电的意思啰!
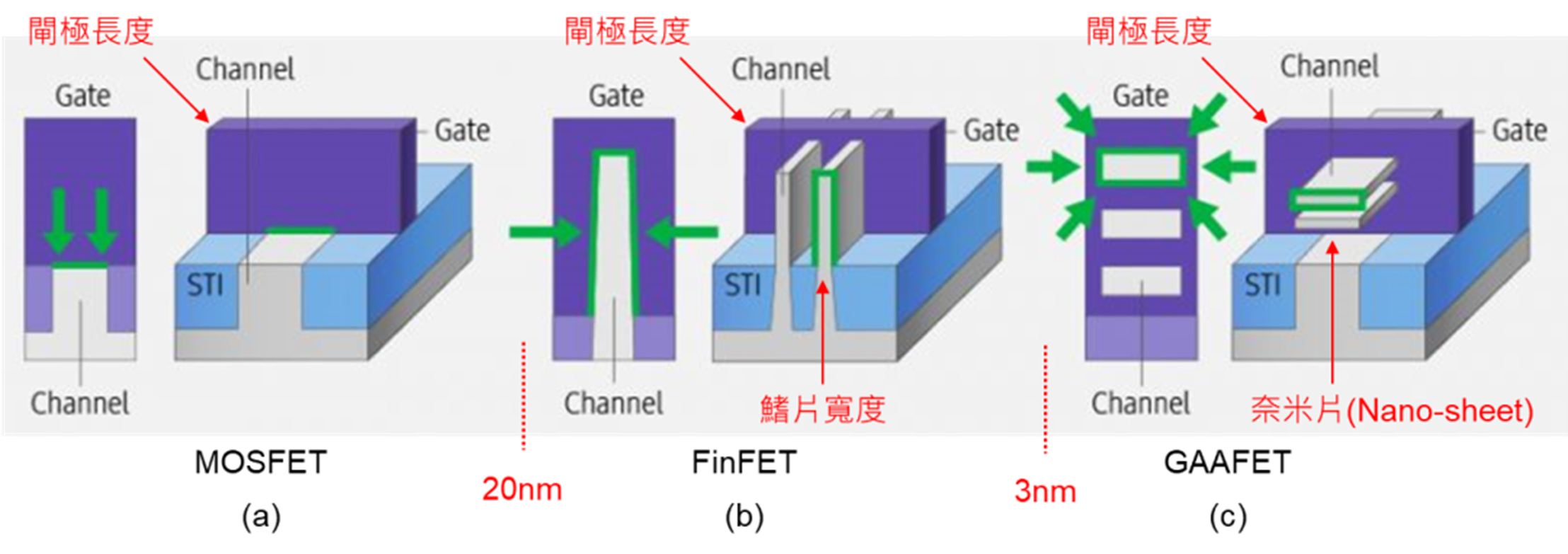
图三 晶体管的演进过程。资料来源:wccftech.com/samsung-makes-the-first-3nm-gaafet-semiconductor。
值得注意的是,在成熟制程MOSFET里”栅极长度”代表”制程节点”,但是到了先进制程FinFET上指的其实是概念上的”平均长度”,只能当作是”商品名称”,而不是真的栅极长度, 因此”几纳米”是厂商自己定义的,厂商说是几纳米它就是几纳米,而在台积电3纳米制程里比较”接近”3纳米的结构其实是图三里的”鳍片宽度”,因为这是 所有构造中最细小也最难制作的。
环绕栅极场效晶体管(GAAFET):未来先进制程的发展方向
大家猜猜,当栅极长度缩小到3纳米以下的时候,还有什么办法可以增加栅极与通道之间的接触面积? 就是栅极把电子通道完全包围起来,如图三(c)所示,称为环绕栅极场效晶体管(GAAFET:Gate All Around Field Effect Transistor),原理其实很简单,就是增加栅极与电子通道的接触面积,可以增加栅极控制效果。
由图四可以看出,台积电与三星同时在2018年量产7纳米,英特尔在2021年量产落后三年; 台积电与三星同时在2020年量产4纳米,英特尔在2022年量产落后二年; 台积电与三星同时在2022年量产3纳米,英特尔计划在2023年量产落后一年,因此英特尔并没有大家想象的落后很多,当然宣布量产是一回事,良率多高又是另一回事, 目前进度与良率都领先的只有台积电一家,这也是台积电最大的优势。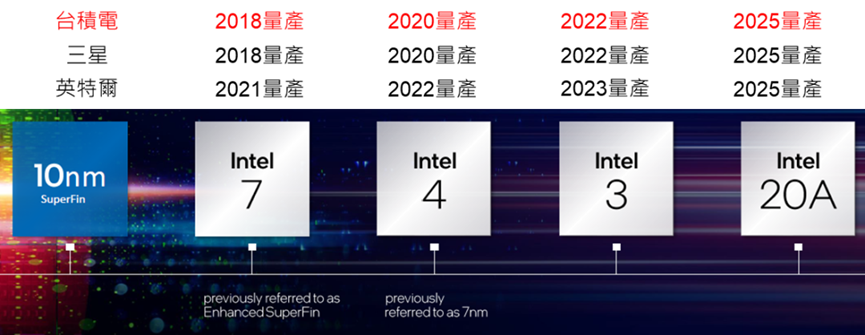
图四 台积电与竞争对手的制程节点时间表。资料来源:英特尔(Intel)。
值得注意的是,三家公司都把2纳米的日程压在2025年,而且都是使用GAAFET,里面有两个重要的含义,以前每一代制程大约只需要2年,但是先进制程困难度愈来愈高, 因此必须3年才行,这代表未来台积电进步将更困难,而竞争对手追上来相对比较容易,这是台积电未来必须面对的问题。
此外,三星在2022Q2量产3纳米使用新型的GAAFET,但是台积电到2022Q4才量产3纳米使用旧型的F inFET,乍看之下是确实是三星弯道超车,但是三家公司2纳米都必须使用GAAFET,因此三星比台积电与英特尔多了3年的量产经验,这是三星冒险在 3纳米使用GAAFET的主要原因,未来是不是有机会弯道超车?
台积电与三星仍将决战鳍式场效晶体管(FinFET)
环绕栅极场效晶体管(GAAFET)的制程非常复杂,比鳍式场效晶体管(FinFET)困难许多,因此国外媒体报道三星3纳米GAAFET制程良率仅20%, 这个其实并不令人惊讶,但是三星高层指出,三星3纳米制程良率已达”完美水平”且毫不迟疑开发第二代3纳米制程,事实如何就让我们拭目以待吧!
其实GAAFET良率根本很难提高,因此三星未来可能的做法就是回头使用FinFET制做3纳米,反正厂商说这个是几纳米它就是几纳米,因此我大胆预言:台积电与三星仍将决战FinFET。为什么GAAFET良率根本很难提高,这个用文章说不清楚,有兴趣的人可以关注我们观看视频。(三星宣布量产3纳米! 是真的超车台积电? 还是真正的苦难才刚开始? )
根据国外媒体的报道,高通(Qualcomm)与联发科(MediaTek)还不确定是否会在2023年使用台积电3纳米制程代工手机芯片,因此苹果有可能是2023年唯一采用台积电3纳米制成技术的厂商。而高通与联发科之所以犹豫是否采用台积电3纳米制程的关键在于3纳米的成本极高,台积电从10纳米制程开始,每片晶圆销售价格持续上涨,7纳米一片12寸晶圆大约10,000美元 ,到3纳米一片12寸晶圆大约20,000美元,用的还是FinFET,那么到 2025年2纳米一片12吋晶圆要不要接近30,000美元? 这么贵的东西客户接受吗?
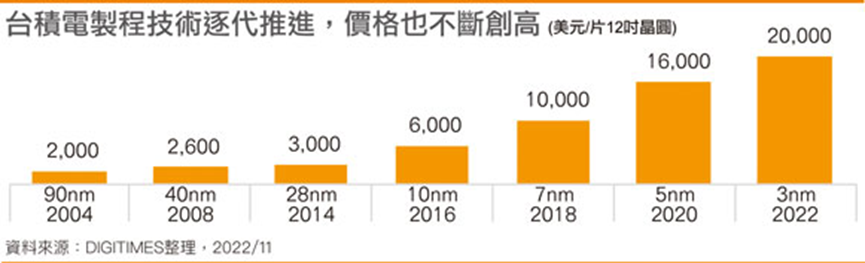
图五 台积电不同制程节点的价格预估。资料来源:Digitimes整理。
未来三年台积电3纳米制程仍然领先全球
台积电3纳米制程(N3)改良后的 N3B已经顺利在2022Q4量产,但是未来还有下面几个衍生的 制程节点,如图六所示: - N3E:牺牲尺寸成全良率、效能、功耗,2023Q2或Q3量产。
- N3P:制造工艺的性能增强版本,量产时间未定。
- N3S:缩小尺寸的密度增加版本,量产时间未定。
- N3X:超高性能的超频版本,量产时间未定。
由于GAAFET困难度高,成本更高,大家是否能顺利在2025年量产还是未知数,因此可以预期3纳米制程仍然是未来三年各家厂商竞争的主要标的,会使用很长一段时间, 台积电利用3纳米衍生的制程节点,仍然能够领先全球,比较令人忧心的还是美国补助英特尔、台积电、三星到美国设厂,大约都是在 2024或2025年量产,可能对先进制程产生供过于求的问题,这是比较有风险的地方,值得大家留意。
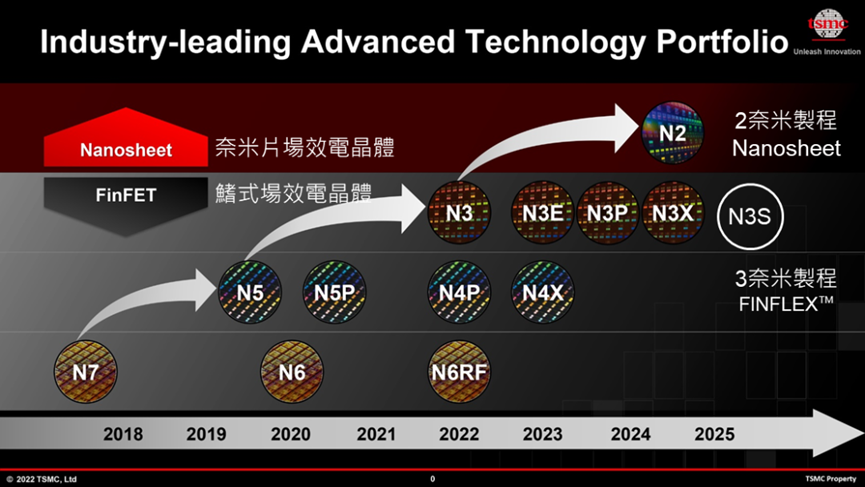
图六 台积电先进制程路线图。资料来源:台积电(TSMC)
参考文献链接
https://mp.weixin.qq.com/s/DbJbP2g4hBUh1ZxUh1lENQ
https://mp.weixin.qq.com/s/rzzsd5h5luETuT1R1EeO-A