论文阅读05-DFCN:Deep Fusion Clustering Network
论文信息
论文地址:[DFCN][2012.09600] Deep Fusion Clustering Network (arxiv.org)
论文代码:WxTu/DFCN: AAAI 2021-Deep Fusion Clustering Network (github.com)
1.存在问题
- 研究方向
通过自动编码器AE和图神经网络GCN以利用结构信息来提高聚类性能
- 存在问题
- 缺乏动态融合机制来选择性地整合和细化图结构和节点属性的信息以进行共识表示学习;
- 难以从两个方面提取信息以生成稳健的目标分布:(即“groundtruth”软标签)
2. DFCN 解决问题
- 如何解决
创新点:提出了一种基于互相依赖学习的结构和属性信息融合(SAIF)模块,用于显式地合并由自编码器和图自编码器学习到的表示以进行共识表示学习。此外,还设计了可靠的目标分布生成度量和三元自监督策略,以促进跨模态信息利用。
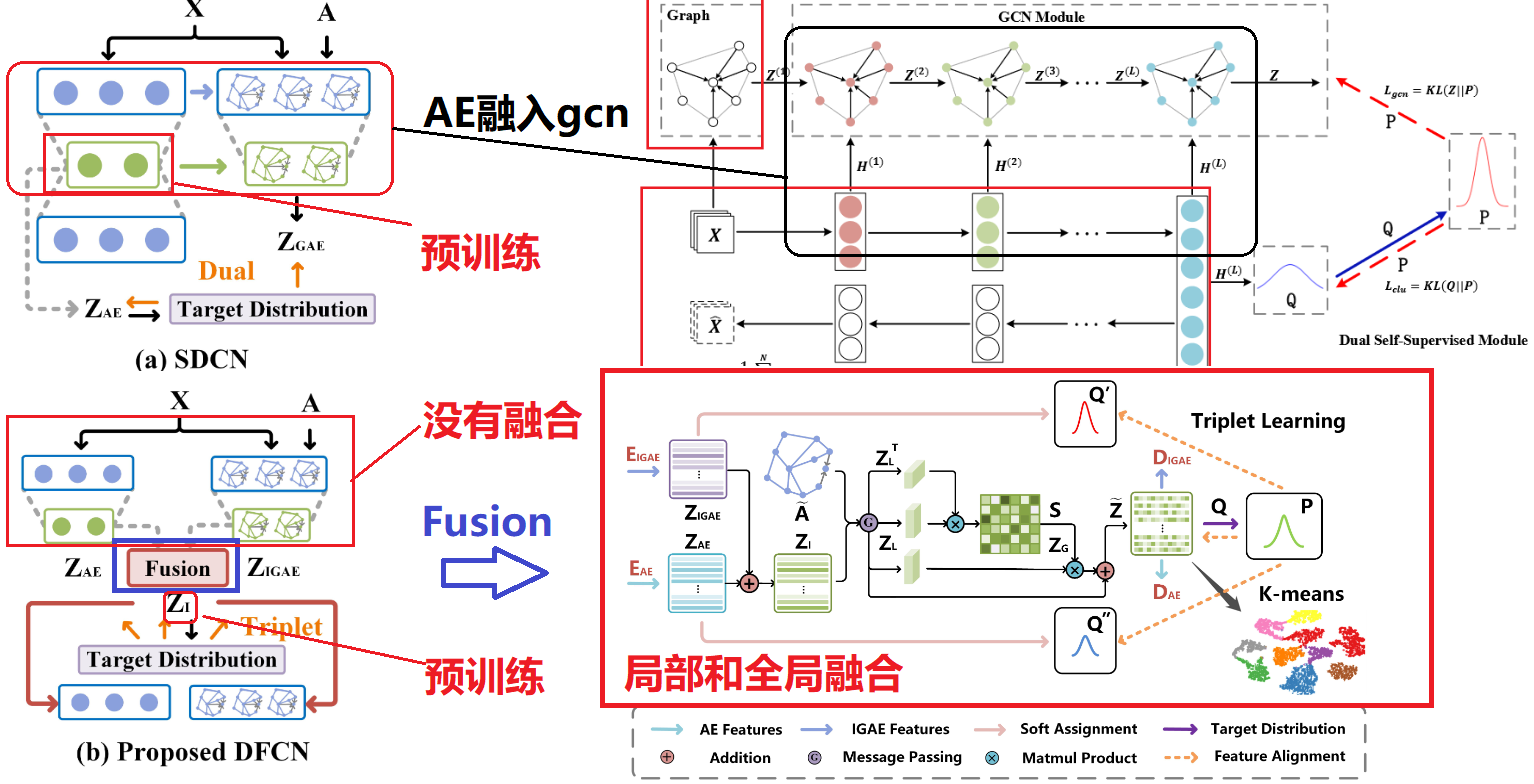
- SDCN 和DFCN 结构比较
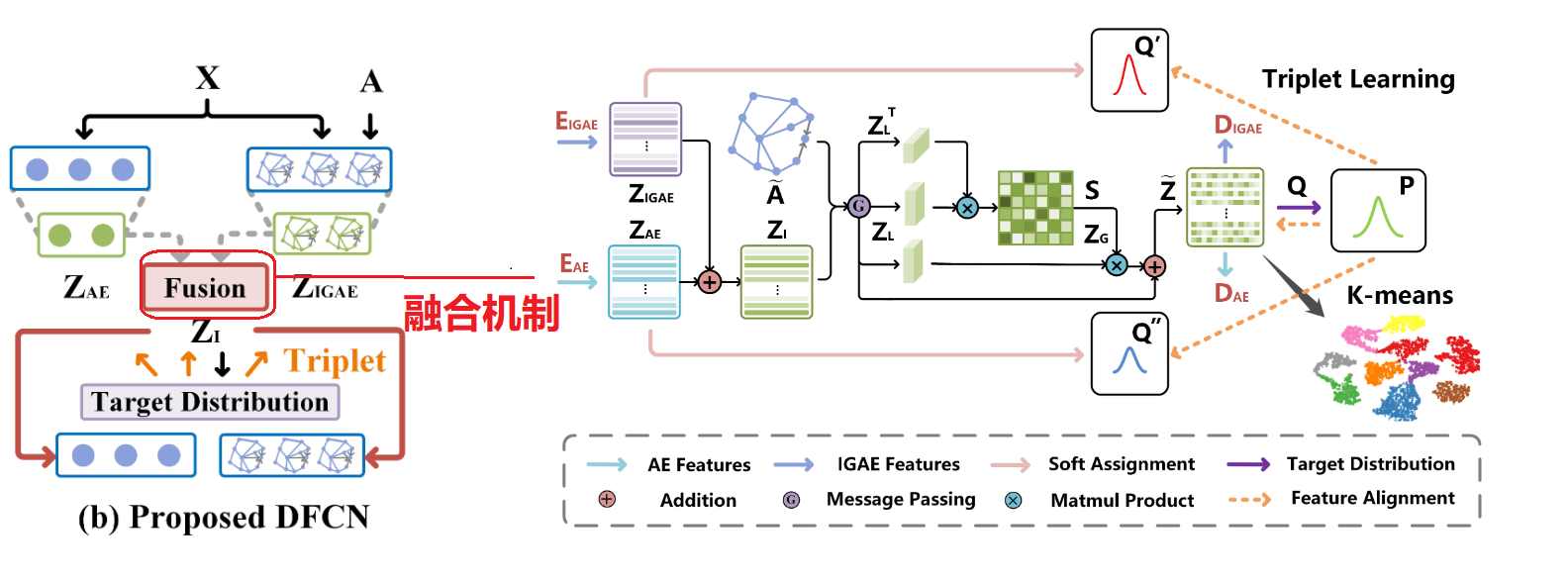
与现有的结构和属性信息融合网络(如 SDCN)不同,我们提出的方法通过信息融合模块得到增强。
- AE 和 IGAE 的解码器都使用学习到的共识潜在表示来重建输入。
- 目标分布是通过AE和IGAE之间的充分协商构建的。
- 设计了一种自我监督的三元组学习策略。
3.DFCN model
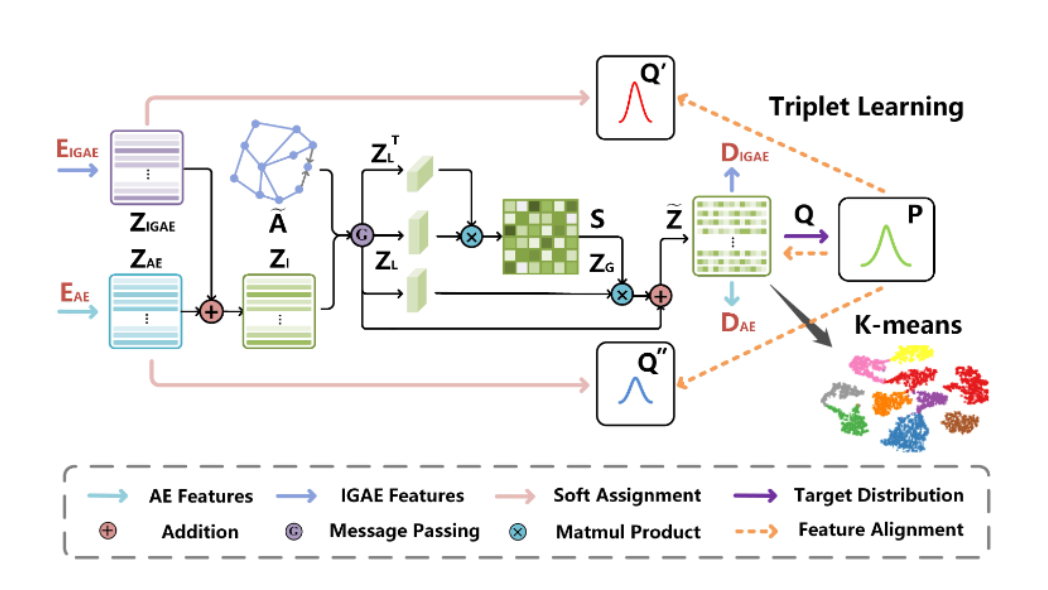
1. model structrue
DFCN:提取几何结构信息,然后将其与属性信息集成以进行表示学习:结构和属性融合.DFCN 由4个模块组成。
- 自编码器AE: 采用的全连接的神经网络.
- 改进图编码器IGAE:和以往的图编码器不同的在于,采用了对称的结构,即编码器和解码器的层数相同,都是采用GCN 类似与AE。
- 融合模块: 通过融合IGAE和AE 的嵌入层,得到最终的embedding 来进行聚类。
- 优化模块: 优化聚类的效果.
2. Fusion-based Autoencoders
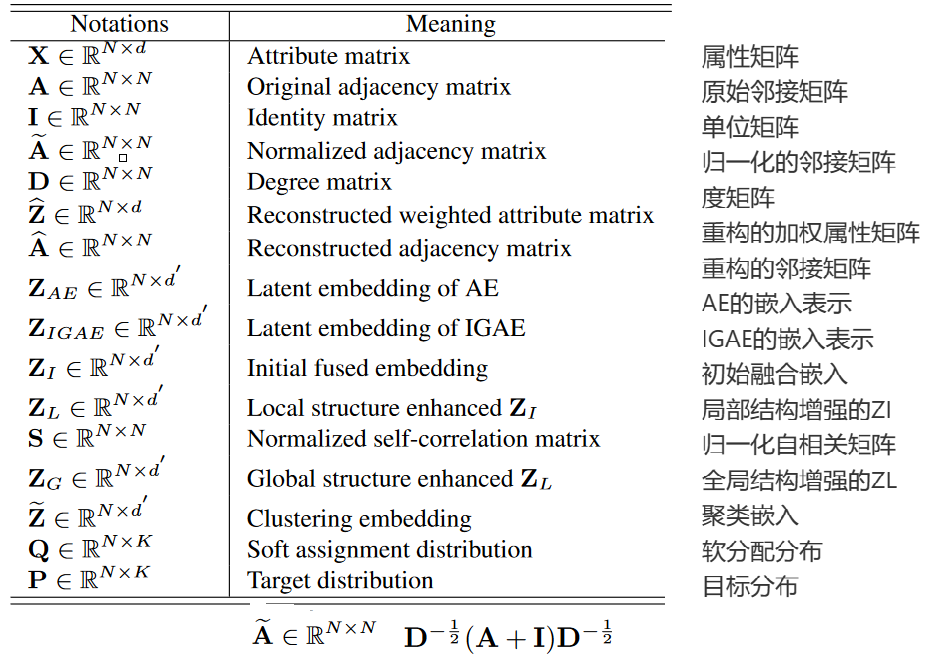
- DFCN参数表
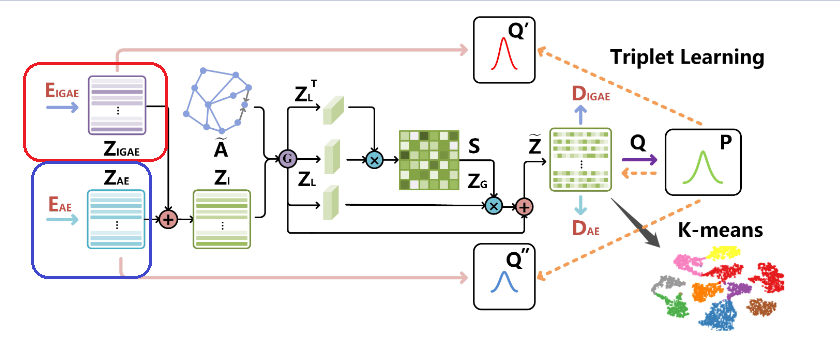
1. Input of the Decoder和Structure and Attribute Information Fusion
通过使用 AE 和 GAE 的降维表示,我们首先计算来自两个来源的信息以获得一致的潜在表示。然后将此嵌入作为输入,AE 和 GAE 的解码器都重构两个子网络的输入:意思是作为ISAF 融合模块的输入。
2.Improved Graph Autoencoder:IGAE
由于经典的自动编码器通常是对称的,然而图卷积网络通常不是对称的,图卷积网络只考虑了潜在表示来重建邻接信息,而忽略了基于结构的属性信息,为了更好地利用邻接信息和属性信息,作者设计了一个对称改进的图自动编码器(IGAE)。同时重建属性和邻接矩阵。
IGAE 编码器解码器:
需要注意的是La前面的超参数为0.1 按照我的理解邻接矩阵重构相对于Lw重建属性矩阵,重要性不大

具有多级网络表示的内积操作生成的重构矩阵A^解释,通过查看DFCN的代码:
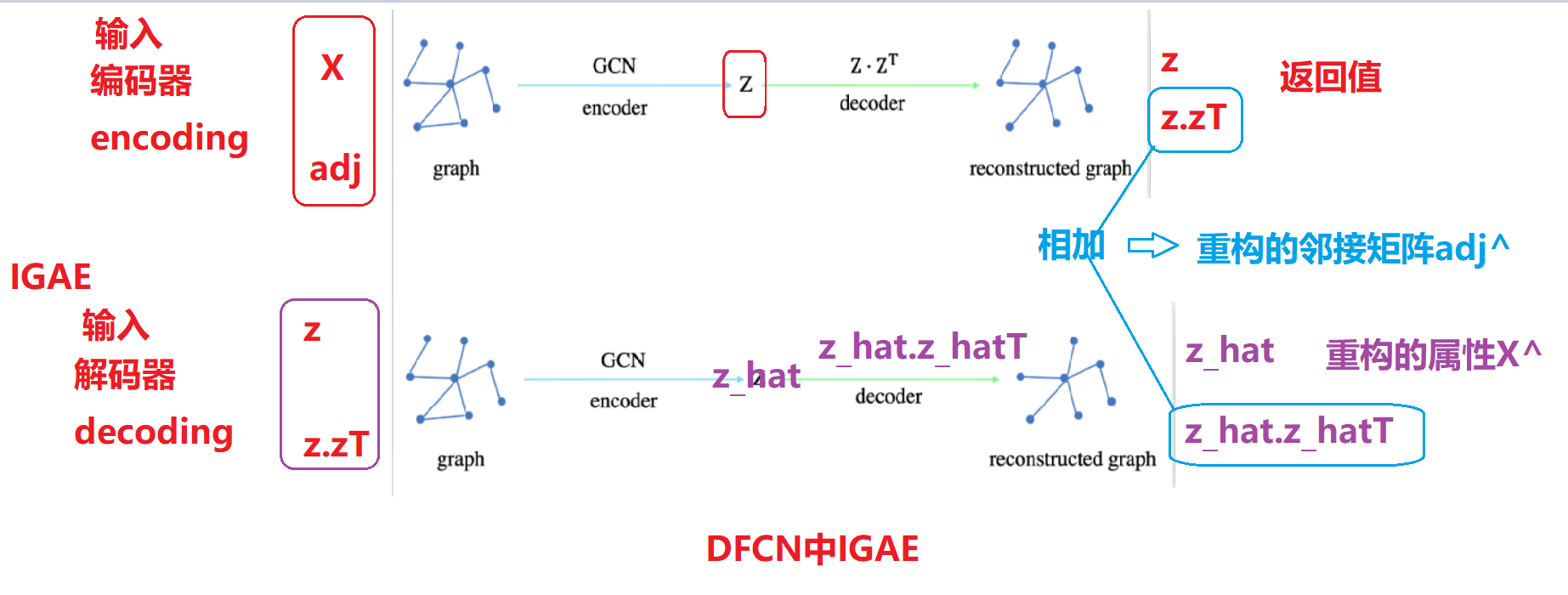
普通的GAE:
编码器: 产生嵌入向量z:相当于重构属性x
解码器: GAE通过嵌入向量z 的内积z.zT生成 重构邻接矩阵adj
IGAE:
编码器:相当于普通GAE 编码器和解码器
输入属性x,邻接矩阵adj ===》产生了上述的z 和z.zT ==adj
z可以表示重构的属性x adj表示普通的GAE产生的重构邻接矩阵adj
解码器 : 相当于又经历一次普通GAE 编码器和解码器
输入 IGAE编码器的z 和adj =》再通过和IGAE编码器一样的操作产生z_hat,
z_hat 通过内积操作产生邻接矩阵z_adj.
z_hat 表示重构的z属性矩阵,z_hat通过内积产生邻接矩阵z_adj
IGAE:
相当于做了两次传统的GAE操作,由于每个传统的GAE 都产生了重构矩阵adj
因此 IGAE 重构的adj=IGAE编码器重构的adj+IGAE解码器重构的adj
IGAE 重构的属性z_hat 表示就是属性x的重构:
z_hat 指的是经历了编码和解码产生的,没有进行加和操作
3. Cross-modality Dynamic Fusion Mechanism:动态融合机制

具体融合过程如下图所示:
4. Triplet Self-supervised Strategy.:三重自监督

5.Joint loss and Optimization
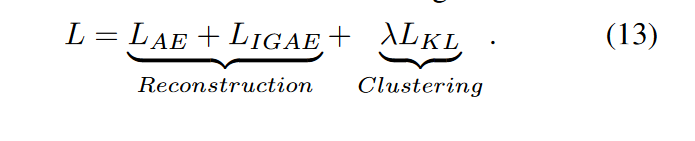
6. DFCN 算法流程图

3. result Analysis
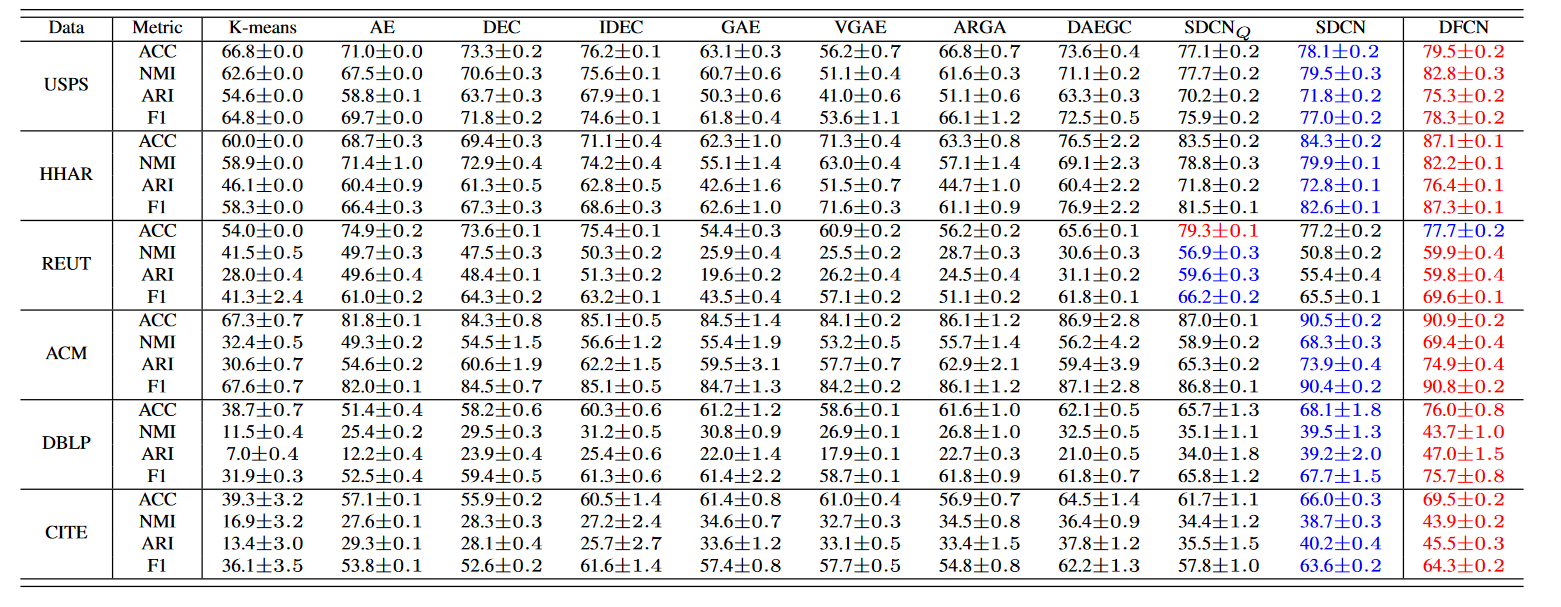
1. 数据集
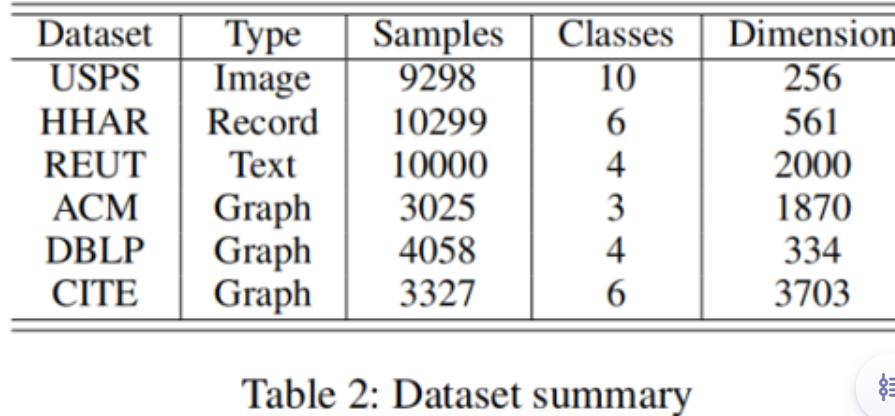
2. 实验结果
3. 实验训练过程
- 首先,我们通过最小化重建损失函数独立地对 AE 和 IGAE 进行 30 次迭代预训练。然后,将两个子网络集成到一个联合框架中,再进行 100 次迭代DFCN的预训练模型。:
- 利用不同学习中心,在三元组自监督策略的指导下,我们对整个网络进行至少 200 次迭代训练,直到收敛。
4.实验结果分析
- AE、DEC 和 IDEC 只是利用节点属性表示进行聚类。这些方法很少考虑结构信息,导致性能欠佳。DFCN通过选择性地整合图结构和节点属性的信息,成功地利用了可用数据,这与共识表示学习相辅相成,大大提高了聚类性能。
- 基于 GCN 的方法,如 GAE、VGAE、ARGA 和 DAEGC 无法与我们的相提并论,因为这些方法未充分利用数据本身的丰富信息,并且可能仅限于过度平滑现象。DFCN 将 AE 学习的基于属性的表示合并到整个聚类框架中,并通过融合模块相互探索图结构和节点属性,以实现共识表示学习。因此,所提出的 DFCN 改进了现有基于 GCN 的方法的聚类性能,并具有更好的差距。
- 与sdcn和sdcn-q相比较:这是因为 DFCN 不仅实现了图结构和节点属性之间的动态交互以揭示内在的聚类结构,而且采用三元组自监督策略来提供精确的网络训练指导。
4.Ablation Studies 消融实验
1.Effectiveness of IGAE:IGAE 编码器有效性
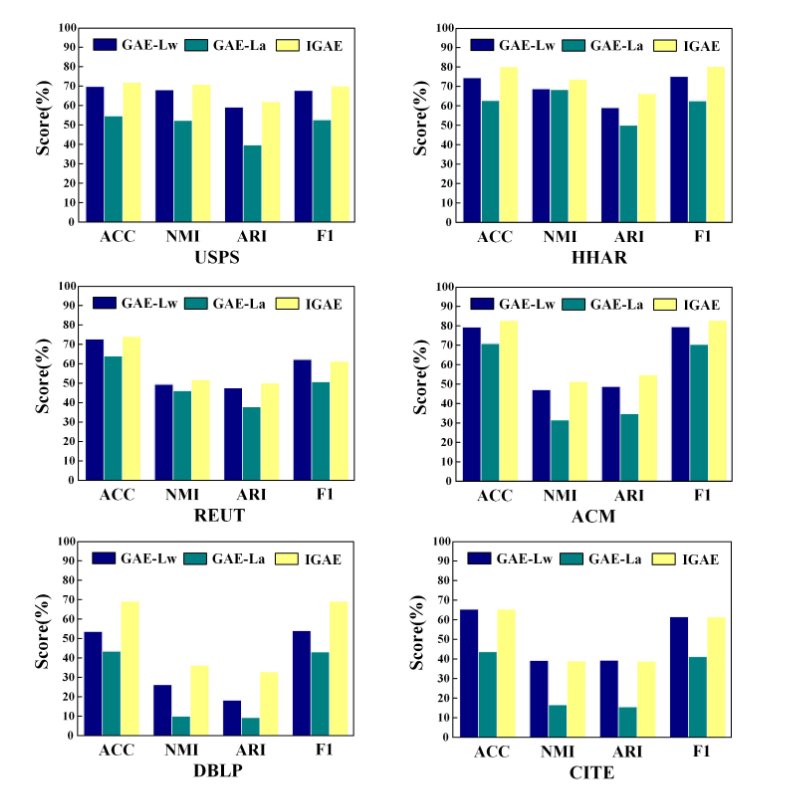
实验参数解释:
实验结果:
- GAE-Lw 在六个数据集上的表现始终优于 GAE-La。
- 与GAE-La仅构建邻接矩阵的方法相比,IGAE 明显提高了聚类性能。
实验结论:
1. 我们提出的**重建措施能够利用更全面的信息来提高深度聚类网络的泛化能力**。
1. 通过这种方式,**潜在嵌入从原始图的属性空间继承了更多属性**,**保留了生成更好聚类决策的代表性特征**
2.Analysis of the SAIF Module融合模块
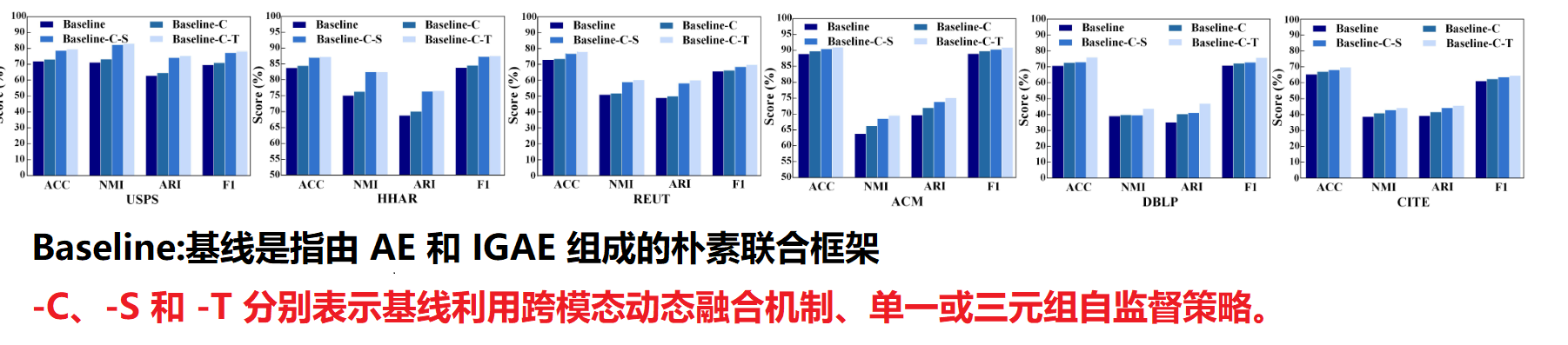
实验结果:
- 与baseline相比,Baseline-C方法有大约0.5%到5.0%的性能提升,表明从局部和全局的角度探索图结构和节点属性有助于学习共识潜在表示以实现更好的聚类;
- Baseline-C-T方法在所有数据集上的性能始终优于Baseline-C-S方法。原因是我们的三元组自监督策略成功地为 AE、IGAE 和融合部分的训练生成了更可靠的指导,使它们相互受益
3.Influence of Exploiting Both-source Information:利用双源信息的影响
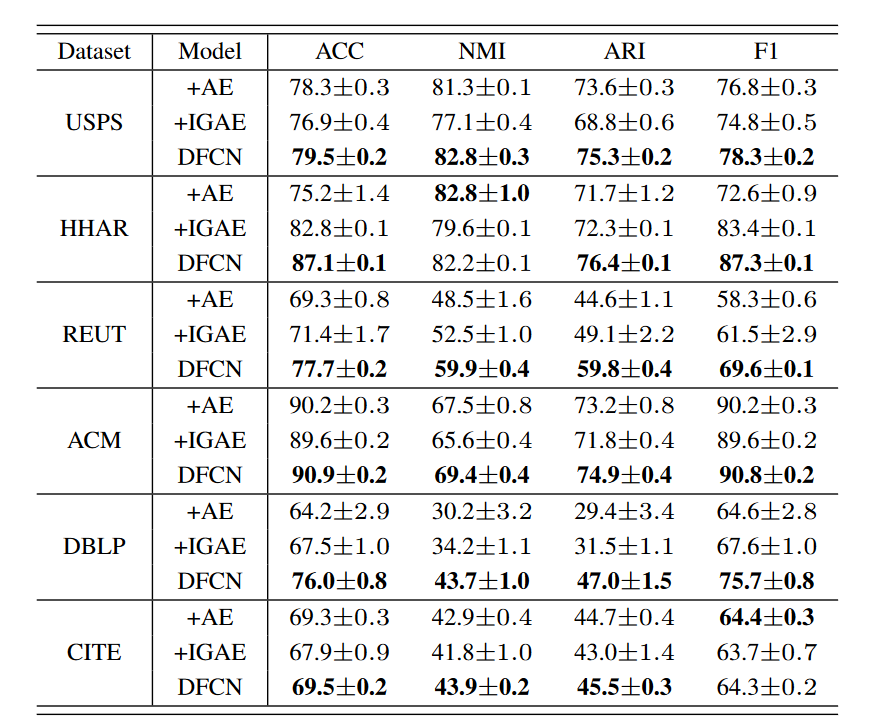
+AE:表示DFCN 只有AE +IGAE: 指DFCN 只有IGAE。
实验分析:
一方面,由于 +AE 和 +IGRE 在不同的数据集上取得了更好的性能,这表明来自 AE 或 IGAE 的信息不能始终优于其对应的信息(AE有时比IGAE好,AE有时没有IGAE好),结合双源信息可以潜在地提高混合方法的稳健性。另一方面,DFCN 对基于 DNN 和 GCN 的表示进行编码,并且始终优于单源方法。
实验结论:
1)双源信息对于DFCN的性能提升同样重要;
- DFCN 可以促进互补的双模态信息,使目标分布更加可靠和稳健,从而更好地聚类。
4.Analysis of Hyper-parameter λ:超参数
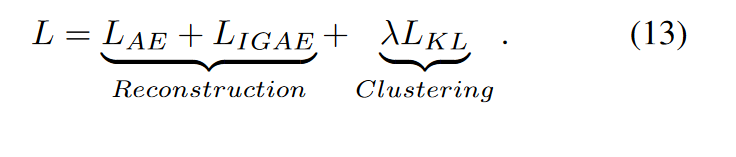
DFCN 引入了一个超参数 λ 来在重建和聚类之间进行权衡。我们进行实验以显示此参数对所有数据集的影响。
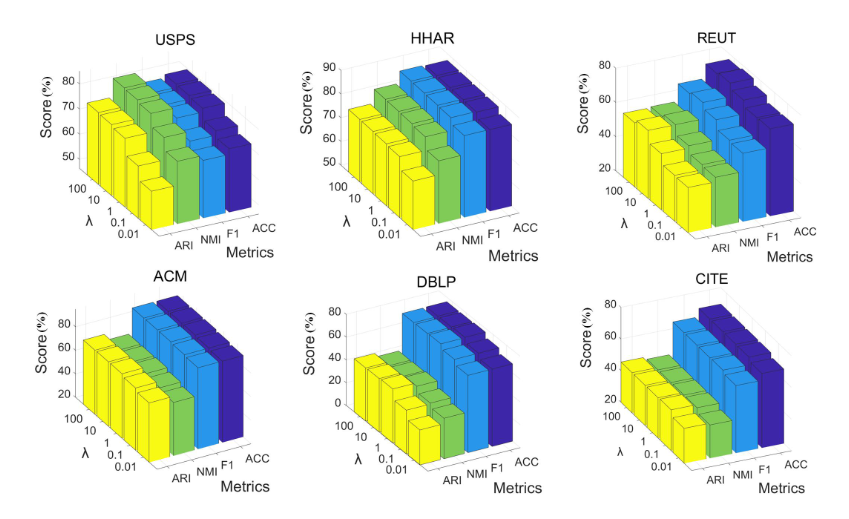
实验结果分析:
1)超参数λ有效提高聚类性能;
2)该方法在很宽的λ范围内性能稳定;
3) 通过在所有数据集中将 λ 设置为 10,DFCN 往往表现良好。
4. 预训练代码
DFCN论文代码:WxTu/DFCN: AAAI 2021-Deep Fusion Clustering Network (github.com) 不包含与训练代码。本人根据sdcn 和DAEGC 修改出 预训练代码:仅只有cite的预训练,可以参考修改其他的数据类型。
1.AE预训练代码
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torch.optim import Adam
from torch.nn import Linear
from torch.utils.data import Dataset
from sklearn.cluster import KMeans
from evaluation import eva
device = torch.device("gpu" if torch.cuda.is_available() else "cpu")
class AE_encoder(nn.Module):
def __init__(self, ae_n_enc_1, ae_n_enc_2, ae_n_enc_3, n_input, n_z):
super(AE_encoder, self).__init__()
"""
3层的AE 编码器
"""
# encoding: 编码器
self.enc_1 = Linear(n_input, ae_n_enc_1) #
self.enc_2 = Linear(ae_n_enc_1, ae_n_enc_2)
self.enc_3 = Linear(ae_n_enc_2, ae_n_enc_3)
# embedding: 嵌入层表示
self.z_layer = Linear(ae_n_enc_3, n_z)
# 激活函数
self.act = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
"""
编码器前向传播: 激活函数采用leaklyrelu
:param x: 特征矩阵
:return: 嵌入层 embedding
"""
z = self.act(self.enc_1(x))
z = self.act(self.enc_2(z))
z = self.act(self.enc_3(z))
# 激活函数:embedding
z_ae = self.z_layer(z)
return z_ae
class AE_decoder(nn.Module):
def __init__(self, ae_n_dec_1, ae_n_dec_2, ae_n_dec_3, n_input, n_z):
super(AE_decoder, self).__init__()
"""
3层的AE 解码器
"""
self.dec_1 = Linear(n_z, ae_n_dec_1)
self.dec_2 = Linear(ae_n_dec_1, ae_n_dec_2)
self.dec_3 = Linear(ae_n_dec_2, ae_n_dec_3)
# 重构数据x
self.x_bar_layer = Linear(ae_n_dec_3, n_input)
self.act = nn.LeakyReLU(0.2, inplace=True)
def forward(self, z_ae):
"""
:param z_ae: 嵌入层
:return: 重构的数据x
"""
z = self.act(self.dec_1(z_ae))
z = self.act(self.dec_2(z))
z = self.act(self.dec_3(z))
x_hat = self.x_bar_layer(z)
return x_hat
class AE(nn.Module):
def __init__(self, ae_n_enc_1, ae_n_enc_2, ae_n_enc_3, ae_n_dec_1, ae_n_dec_2, ae_n_dec_3, n_input, n_z):
super(AE, self).__init__()
# AE:编码器
self.encoder = AE_encoder(
ae_n_enc_1=ae_n_enc_1,
ae_n_enc_2=ae_n_enc_2,
ae_n_enc_3=ae_n_enc_3,
n_input=n_input,
n_z=n_z)
# AE: 解码器
self.decoder = AE_decoder(
ae_n_dec_1=ae_n_dec_1,
ae_n_dec_2=ae_n_dec_2,
ae_n_dec_3=ae_n_dec_3,
n_input=n_input,
n_z=n_z)
def forward(self, x):
"""
:param x: 输入x
:return: 重构x 嵌入层z
"""
# 编码器
z_ae = self.encoder(x)
# 解码器
x_hat = self.decoder(z_ae)
return x_hat, z_ae
def adjust_learning_rate(optimizer, epoch):
lr = 0.001 * (0.1 ** (epoch // 20))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def pretrain_ae(model, dataset, y):
#通过torch DataLoader 加载数据集
train_loader = DataLoader(dataset, batch_size=256, shuffle=True)
print(model)
optimizer = Adam(model.parameters(), lr=1e-3)
for epoch in range(100):
model.train()
#adjust_learning_rate(optimizer, epoch)没有用
for batch_idx, (x, _) in enumerate(train_loader):
print(batch_idx,":batch_idx",(x,_))
x = x.to(device)
x_bar, _ = model(x)
loss = F.mse_loss(x_bar, x)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
x = torch.Tensor(dataset.x).to(device).float()
x_bar, z = model(x)
loss = F.mse_loss(x_bar, x)
print('{} loss: {}'.format(epoch, loss))
kmeans = KMeans(n_clusters=6, n_init=20).fit(z.data.cpu().numpy())
acc, f1, nmi, ari=eva(y, kmeans.labels_, epoch)
acc=round(acc,4)
torch.save(model.state_dict(), "./pre_model/ae/"+"cite"+str(epoch)+'.pkl')
class LoadDataset(Dataset):
def __init__(self, data):
self.x = data
def __len__(self):
return self.x.shape[0]
def __getitem__(self, idx):
return torch.from_numpy(np.array(self.x[idx])).float(), \
torch.from_numpy(np.array(idx))
def plot_pca_scatter(name, n_clusters, X_pca, y):
if name == "usps":
colors = ['black', 'blue', 'purple', 'yellow', 'pink', 'red', 'lime', 'cyan', 'orange', 'gray'] # usps:10
elif name == "acm":
colors = ['yellow', 'pink', 'red'] # acm:3
elif name == "dblp":
colors = ['yellow', 'pink', 'red', 'orange'] # dblp:4
elif name == "cite":
colors = ['yellow', 'pink', 'red', 'lime', 'cyan', 'orange'] # cite:6
elif name == "hhar":
colors = ['green', 'blue', 'red', 'pink', 'yellow', 'purple'] # hhar:6
elif name == "reut":
colors = ['green', 'blue', 'red', 'pink'] # reut:4
else:
print("Loading Error!")
for i in range(len(colors)):
px = X_pca[:, 0][y == i]
py = X_pca[:, 1][y == i]
plt.scatter(px, py, c=colors[i])
plt.legend(np.arange(n_clusters))
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.show()
if __name__ == '__main__':
model = AE(
128,256,512,512,256,128,n_input=100,n_z=20
).to(device)
x = np.loadtxt('data/cite.txt', dtype=float)
y = np.loadtxt('data/cite_label.txt', dtype=int)
# dataset = LoadDataset(x)
pca = PCA(n_components=100)
X_pca = pca.fit_transform(x)
plot_pca_scatter("cite", 6, X_pca, y)
#
dataset = LoadDataset(X_pca)
pretrain_ae(model, dataset, y)
pass
2.IGAE预训练代码
from torch.nn import Module, Parameter
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import Adam
from sklearn.decomposition import PCA
from load_data import *
from evaluation import eva
device = torch.device("gpu" if torch.cuda.is_available() else "cpu")
from torch.utils.data import DataLoader
class GNNLayer(Module):
def __init__(self, in_features, out_features):
super(GNNLayer, self).__init__()
self.in_features = in_features
self.out_features = out_features
## 测试
self.act = nn.Tanh()
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
torch.nn.init.xavier_uniform_(self.weight)
def forward(self, features, adj, active=False):
#修改的
if active:
support = self.act(torch.mm(features, self.weight))
else:
support = torch.mm(features, self.weight)
output = torch.spmm(adj, support)
return output
class IGAE_encoder(nn.Module):
def __init__(self, gae_n_enc_1, gae_n_enc_2, gae_n_enc_3, n_input):
super(IGAE_encoder, self).__init__()
self.gnn_1 = GNNLayer(n_input, gae_n_enc_1)
self.gnn_2 = GNNLayer(gae_n_enc_1, gae_n_enc_2)
self.gnn_3 = GNNLayer(gae_n_enc_2, gae_n_enc_3)
self.s = nn.Sigmoid()
def forward(self, x, adj):
z = self.gnn_1(x, adj, active=True)
z = self.gnn_2(z, adj, active=True)
z_igae = self.gnn_3(z, adj, active=False)
z_igae_adj = self.s(torch.mm(z_igae, z_igae.t()))
return z_igae, z_igae_adj
class IGAE_decoder(nn.Module):
def __init__(self, gae_n_dec_1, gae_n_dec_2, gae_n_dec_3, n_input):
super(IGAE_decoder, self).__init__()
self.gnn_4 = GNNLayer(gae_n_dec_1, gae_n_dec_2)
self.gnn_5 = GNNLayer(gae_n_dec_2, gae_n_dec_3)
self.gnn_6 = GNNLayer(gae_n_dec_3, n_input)
self.s = nn.Sigmoid()
def forward(self, z_igae, adj):
#修改
z = self.gnn_4(z_igae, adj, active= True)
z = self.gnn_5(z, adj, active= True)
z_hat = self.gnn_6(z, adj, active= True)
z_hat_adj = self.s(torch.mm(z_hat, z_hat.t()))
return z_hat, z_hat_adj
class IGAE(nn.Module):
def __init__(self, gae_n_enc_1, gae_n_enc_2, gae_n_enc_3, gae_n_dec_1, gae_n_dec_2, gae_n_dec_3, n_input):
super(IGAE, self).__init__()
self.encoder = IGAE_encoder(
gae_n_enc_1=gae_n_enc_1,
gae_n_enc_2=gae_n_enc_2,
gae_n_enc_3=gae_n_enc_3,
n_input=n_input)
self.decoder = IGAE_decoder(
gae_n_dec_1=gae_n_dec_1,
gae_n_dec_2=gae_n_dec_2,
gae_n_dec_3=gae_n_dec_3,
n_input=n_input)
def forward(self, x, adj):
z_igae, z_igae_adj = self.encoder(x, adj)
z_hat, z_hat_adj = self.decoder(z_igae, adj)
adj_hat = z_igae_adj + z_hat_adj
return z_igae, z_hat, adj_hat
def adjust_learning_rate(optimizer, epoch):
lr = 0.001 * (0.1 ** (epoch // 20))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def pretrain_gae(dataset,y):
model = IGAE(
gae_n_enc_1=128, gae_n_enc_2=256, gae_n_enc_3=20, gae_n_dec_1=20, gae_n_dec_2=256, gae_n_dec_3=128, n_input=100
).to(device)
print(model)
train_loader = DataLoader(dataset, batch_size=256, shuffle=True)
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=5e-3)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, 100)
# 需要两个数据: 属性矩阵X :data 和 邻接矩阵A:adj
data_path = 'data/cite.txt'
graph_path = 'graph/cite_graph.txt'
adj = load_graph(False,"", graph_path, data_path).to(device)
data = torch.Tensor(dataset.x).to(device)# 属性矩阵x
label = y
gamma_value=0.1
for epoch in range(200):
model.train()
z_igae, z_hat, adj_hat=model(data,adj)
loss_w = F.mse_loss(z_hat, torch.spmm(adj, data))#ax-z
loss_a = F.mse_loss(adj_hat, adj.to_dense())# a-a
loss = loss_w + gamma_value * loss_a
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
with torch.no_grad():
z_igae, z_hat, adj_hat= model(data, adj)
loss_w = F.mse_loss(z_hat, torch.spmm(adj, data)) # ax-z
loss_a = F.mse_loss(adj_hat, adj.to_dense()) # a-a
loss = loss_w + gamma_value * loss_a
print('{} loss: {}'.format(epoch, loss))
kmeans = KMeans(n_clusters=6, n_init=20).fit(z_igae.data.cpu().numpy())
acc,_,_,_=eva(label, kmeans.labels_, epoch)
torch.save(model.state_dict(), './pre_model/igae/{}{}.pkl'.format("cite",str(epoch)))
if __name__ == '__main__':
x = np.loadtxt('data/cite.txt', dtype=float)# 3327 *3703
y = np.loadtxt('data/cite_label.txt', dtype=int)# 3327
dataset = LoadDataset(x)
pca = PCA(n_components=100)
X_pca = pca.fit_transform(x)
dataset = LoadDataset(X_pca)
pretrain_gae(dataset,y)
3.DFCN 预训练代码
训练结果就是DFCN 中预训练模型加载的模型
import torch
from torch import nn
from sklearn.cluster import KMeans
from torch.nn import Parameter
import torch.nn.functional as F
from torch import nn
from torch.nn import Linear
from torch.optim import Adam
from evaluation import eva
from load_data import *
from sklearn.decomposition import PCA
device = torch.device("gpu" if torch.cuda.is_available() else "cpu")
class GNNLayer(nn.Module):
def __init__(self, in_features, out_features):
super(GNNLayer, self).__init__()
self.in_features = in_features
self.out_features = out_features
## 测试
self.act = nn.Tanh()
self.weight = Parameter(torch.FloatTensor(in_features, out_features))
torch.nn.init.xavier_uniform_(self.weight)
def forward(self, features, adj, active=False):
#修改的
if active:
support = self.act(torch.mm(features, self.weight))
else:
support = torch.mm(features, self.weight)
output = torch.spmm(adj, support)
return output
class IGAE_encoder(nn.Module):
def __init__(self, gae_n_enc_1, gae_n_enc_2, gae_n_enc_3, n_input):
super(IGAE_encoder, self).__init__()
self.gnn_1 = GNNLayer(n_input, gae_n_enc_1)
self.gnn_2 = GNNLayer(gae_n_enc_1, gae_n_enc_2)
self.gnn_3 = GNNLayer(gae_n_enc_2, gae_n_enc_3)
self.s = nn.Sigmoid()
def forward(self, x, adj):
z = self.gnn_1(x, adj, active=True)
z = self.gnn_2(z, adj, active=True)
z_igae = self.gnn_3(z, adj, active=False)
z_igae_adj = self.s(torch.mm(z_igae, z_igae.t()))
return z_igae, z_igae_adj
class IGAE_decoder(nn.Module):
def __init__(self, gae_n_dec_1, gae_n_dec_2, gae_n_dec_3, n_input):
super(IGAE_decoder, self).__init__()
self.gnn_4 = GNNLayer(gae_n_dec_1, gae_n_dec_2)
self.gnn_5 = GNNLayer(gae_n_dec_2, gae_n_dec_3)
self.gnn_6 = GNNLayer(gae_n_dec_3, n_input)
self.s = nn.Sigmoid()
def forward(self, z_igae, adj):
#修改
z = self.gnn_4(z_igae, adj, active= True)
z = self.gnn_5(z, adj, active= True)
z_hat = self.gnn_6(z, adj, active= True)
z_hat_adj = self.s(torch.mm(z_hat, z_hat.t()))
return z_hat, z_hat_adj
class IGAE(nn.Module):
def __init__(self, gae_n_enc_1, gae_n_enc_2, gae_n_enc_3, gae_n_dec_1, gae_n_dec_2, gae_n_dec_3, n_input):
super(IGAE, self).__init__()
self.encoder = IGAE_encoder(
gae_n_enc_1=gae_n_enc_1,
gae_n_enc_2=gae_n_enc_2,
gae_n_enc_3=gae_n_enc_3,
n_input=n_input)
self.decoder = IGAE_decoder(
gae_n_dec_1=gae_n_dec_1,
gae_n_dec_2=gae_n_dec_2,
gae_n_dec_3=gae_n_dec_3,
n_input=n_input)
def forward(self, x, adj):
z_igae, z_igae_adj = self.encoder(x, adj)
z_hat, z_hat_adj = self.decoder(z_igae, adj)
adj_hat = z_igae_adj + z_hat_adj
return z_igae, z_hat, adj_hat
class AE_encoder(nn.Module):
def __init__(self, ae_n_enc_1, ae_n_enc_2, ae_n_enc_3, n_input, n_z):
super(AE_encoder, self).__init__()
"""
3层的AE 编码器
"""
# encoding: 编码器
self.enc_1 = Linear(n_input, ae_n_enc_1)#
self.enc_2 = Linear(ae_n_enc_1, ae_n_enc_2)
self.enc_3 = Linear(ae_n_enc_2, ae_n_enc_3)
# embedding: 嵌入层表示
self.z_layer = Linear(ae_n_enc_3, n_z)# 512*20 转成
# 激活函数
self.act = nn.LeakyReLU(0.2, inplace=True)
def forward(self, x):
"""
编码器前向传播: 激活函数采用leaklyrelu
:param x: 特征矩阵
:return: 嵌入层 embedding
"""
z = self.act(self.enc_1(x))
z = self.act(self.enc_2(z))
z = self.act(self.enc_3(z))
# 激活函数:embedding
z_ae = self.z_layer(z)
return z_ae
class AE_decoder(nn.Module):
def __init__(self, ae_n_dec_1, ae_n_dec_2, ae_n_dec_3, n_input, n_z):
super(AE_decoder, self).__init__()
"""
3层的AE 解码器
"""
self.dec_1 = Linear(n_z, ae_n_dec_1)
self.dec_2 = Linear(ae_n_dec_1, ae_n_dec_2)
self.dec_3 = Linear(ae_n_dec_2, ae_n_dec_3)
# 重构数据x
self.x_bar_layer = Linear(ae_n_dec_3, n_input)
self.act = nn.LeakyReLU(0.2, inplace=True)
def forward(self, z_ae):
"""
:param z_ae: 嵌入层
:return: 重构的数据x
"""
z = self.act(self.dec_1(z_ae))
z = self.act(self.dec_2(z))
z = self.act(self.dec_3(z))
x_hat = self.x_bar_layer(z)
return x_hat
class AE(nn.Module):
def __init__(self, ae_n_enc_1, ae_n_enc_2, ae_n_enc_3, ae_n_dec_1, ae_n_dec_2, ae_n_dec_3, n_input, n_z):
super(AE, self).__init__()
# AE:编码器
self.encoder = AE_encoder(
ae_n_enc_1=ae_n_enc_1,
ae_n_enc_2=ae_n_enc_2,
ae_n_enc_3=ae_n_enc_3,
n_input=n_input,
n_z=n_z)
# AE: 解码器
self.decoder = AE_decoder(
ae_n_dec_1=ae_n_dec_1,
ae_n_dec_2=ae_n_dec_2,
ae_n_dec_3=ae_n_dec_3,
n_input=n_input,
n_z=n_z)
def forward(self, x):
"""
:param x: 输入x
:return: 重构x 嵌入层z
"""
#编码器
z_ae = self.encoder(x)
# 解码器
x_hat = self.decoder(z_ae)
return x_hat, z_ae
class DFCN(nn.Module):
def __init__(self, ae_n_enc_1, ae_n_enc_2, ae_n_enc_3,
ae_n_dec_1, ae_n_dec_2, ae_n_dec_3,
gae_n_enc_1, gae_n_enc_2, gae_n_enc_3,
gae_n_dec_1, gae_n_dec_2, gae_n_dec_3,
n_input,clusters=6, n_z=20, v=1.0, n_node=None, device=None):
super(DFCN, self).__init__()
self.ae = AE(
ae_n_enc_1=ae_n_enc_1,
ae_n_enc_2=ae_n_enc_2,
ae_n_enc_3=ae_n_enc_3,
ae_n_dec_1=ae_n_dec_1,
ae_n_dec_2=ae_n_dec_2,
ae_n_dec_3=ae_n_dec_3,
n_input=n_input,
n_z=n_z)
self.ae.load_state_dict(torch.load("./pre_model/ae/cite50.pkl",map_location='cpu'))
self.gae = IGAE(
gae_n_enc_1=gae_n_enc_1,
gae_n_enc_2=gae_n_enc_2,
gae_n_enc_3=gae_n_enc_3,
gae_n_dec_1=gae_n_dec_1,
gae_n_dec_2=gae_n_dec_2,
gae_n_dec_3=gae_n_dec_3,
n_input=n_input)
self.gae.load_state_dict(torch.load("./pre_model/igae/cite50.pkl",map_location="cpu"))
self.a = nn.Parameter(nn.init.constant_(torch.zeros(n_node, n_z), 0.5), requires_grad=True).to(device)
self.b = 1 - self.a
self.cluster_layer = nn.Parameter(torch.Tensor(clusters, n_z), requires_grad=True)
torch.nn.init.xavier_normal_(self.cluster_layer.data)
self.v = v
self.gamma = Parameter(torch.zeros(1))
def forward(self, x, adj):
z_ae = self.ae.encoder(x)# 表示AE 的嵌入表示向量
z_igae, z_igae_adj = self.gae.encoder(x, adj) # GAE编码器的嵌入表示向量:z_igae: 特征属性x,z_igae_adj: 邻接矩阵
# 融合SAIF
z_i = self.a * z_ae + self.b * z_igae
z_l = torch.spmm(adj, z_i)
s = torch.mm(z_l, z_l.t())
s = F.softmax(s, dim=1)
z_g = torch.mm(s, z_l)
z_tilde = self.gamma * z_g + z_l # 融合的结果Q
#
x_hat = self.ae.decoder(z_tilde)# 重构的属性x
z_hat, z_hat_adj = self.gae.decoder(z_tilde, adj) # z_hat重构属性,z_hat_adj 重构邻接矩阵
# 表示最后重构的邻接矩阵:编码器的重构的邻接矩阵和解码器重构的邻接矩阵合在一起
adj_hat = z_igae_adj + z_hat_adj# z_igae_adj 编码器的邻接矩阵 z_hat_adj: 解码器的邻接矩阵
q = 1.0 / (1.0 + torch.sum(torch.pow((z_tilde).unsqueeze(1) - self.cluster_layer, 2), 2) / self.v)
q = q.pow((self.v + 1.0) / 2.0)
q = (q.t() / torch.sum(q, 1)).t()
q1 = 1.0 / (1.0 + torch.sum(torch.pow(z_ae.unsqueeze(1) - self.cluster_layer, 2), 2) / self.v)
q1 = q1.pow((self.v + 1.0) / 2.0)
q1 = (q1.t() / torch.sum(q1, 1)).t()
q2 = 1.0 / (1.0 + torch.sum(torch.pow(z_igae.unsqueeze(1) - self.cluster_layer, 2), 2) / self.v)
q2 = q2.pow((self.v + 1.0) / 2.0)
q2 = (q2.t() / torch.sum(q2, 1)).t()
return x_hat, z_hat, adj_hat, z_ae, z_igae, q, q1, q2, z_tilde
def adjust_learning_rate(optimizer, epoch):
lr = 0.001 * (0.1 ** (epoch // 20))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def pre_dfcn(dataset,y):
model=DFCN(ae_n_enc_1=128, ae_n_enc_2=256, ae_n_enc_3=512,
ae_n_dec_1=512, ae_n_dec_2=256, ae_n_dec_3=128,
gae_n_enc_1=128, gae_n_enc_2=256, gae_n_enc_3=20,
gae_n_dec_1=20, gae_n_dec_2=256, gae_n_dec_3=128,
n_input=100, clusters=6,n_z=20, v=1.0, n_node=3327, device=device)
optimizer = Adam(model.parameters(), lr=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, 100)
gamma_value=0.1
data_path = 'data/cite.txt'
graph_path = 'graph/cite_graph.txt'
adj = load_graph(False, "", graph_path, data_path).to(device)
data = torch.Tensor(dataset.x).to(device)
label = y
for epoch in range(100):
adjust_learning_rate(optimizer,epoch)
x_hat, z_hat, adj_hat, z_ae, z_igae, q, q1, q2, z_tilde = model(data, adj)
loss_ae = F.mse_loss(x_hat, data) # data表示原始属性矩阵X
loss_w = F.mse_loss(z_hat, torch.spmm(adj, data)) # A~X-Z^
loss_a = F.mse_loss(adj_hat, adj.to_dense()) # A~-A
loss = loss_w + gamma_value * loss_a+loss_ae
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
kmeans = KMeans(n_clusters=6, n_init=20).fit(z_tilde.data.cpu().numpy())
x_hat, z_hat, adj_hat, z_ae, z_igae, q, q1, q2, z_tilde = model(data, adj)
loss_ae = F.mse_loss(x_hat, data) # data表示原始属性矩阵X
loss_w = F.mse_loss(z_hat, torch.spmm(adj, data)) # A~X-Z^
loss_a = F.mse_loss(adj_hat, adj.to_dense()) # A~-A
loss = loss_w + gamma_value * loss_a + loss_ae# 只考虑IGAE和AE的损失:参考DAEGC
print('{} loss: {}'.format(epoch, loss))
acc, nmi, ari, f1 = eva(label, kmeans.labels_, epoch)
torch.save(model.state_dict(), "./pre_model/dfcn/" + "cite" + str(epoch) + '.pkl')
pass
if __name__ == '__main__':
x = np.loadtxt('data/cite.txt', dtype=float)
y = np.loadtxt('data/cite_label.txt', dtype=int)
pca = PCA(n_components=100)
X_pca = pca.fit_transform(x)
dataset=LoadDataset(X_pca)
pre_dfcn(dataset, y)
4. 加载数据集load_data函数
import torch
import numpy as np
import scipy.sparse as sp
from torch.utils.data import Dataset
from sklearn.metrics import pairwise_distances as pair
def construct_graph(fname, features, label, method='heat', topk=1):
num = len(label)
dist = None
if method == 'heat':
dist = -0.5 * pair(features) ** 2
dist = np.exp(dist)
elif method == 'cos':
features[features > 0] = 1
dist = np.dot(features, features.T)
elif method == 'ncos':
features[features > 0] = 1
features = normalize(features, axis=1, norm='l1')
dist = np.dot(features, features.T)
inds = []
for i in range(dist.shape[0]):
ind = np.argpartition(dist[i, :], -(topk + 1))[-(topk + 1):]
inds.append(ind)
f = open(fname, 'w')
counter = 0
for i, v in enumerate(inds):
for vv in v:
if vv == i:
pass
else:
if label[vv] != label[i]:
counter += 1
f.write('{} {}\n'.format(i, vv))
f.close()
print('Error Rate: {}'.format(counter / (num * topk)))
def load_graph(k=False, graph_k_save_path="", graph_save_path="", data_path=""):
if k:
path = graph_k_save_path
else:
path = graph_save_path
save_path=path
print("Loading path:", path)
data = np.loadtxt(data_path, dtype=float)
n, _ = data.shape
idx = np.array([i for i in range(n)], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt(path, dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])), shape=(n, n), dtype=np.float32)
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
adj = adj + sp.eye(adj.shape[0])
adj = normalize(adj)
adj = sparse_mx_to_torch_sparse_tensor(adj)
return adj
def normalize(mx):
# rowsum = np.array(mx.sum(1))
#r_inv = np.power(rowsum, -1).flatten()
#r_inv[np.isinf(r_inv)] = 0.
#r_mat_inv = sp.diags(r_inv)
#mx = r_mat_inv.dot(mx)
rowsum = np.array(mx.sum(1))
r_inv = np.power(rowsum, -0.5).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
mx=mx.dot(r_mat_inv)
return mx# D^-1/2 A D^-1/2
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
class LoadDataset(Dataset):
def __init__(self, data):
self.x = data
def __len__(self):
return self.x.shape[0]
def __getitem__(self, idx):
return torch.from_numpy(np.array(self.x[idx])).float(), \
torch.from_numpy(np.array(idx))
5.评价函数evalution
import numpy as np
from munkres import Munkres
from sklearn.metrics.cluster import normalized_mutual_info_score as nmi_score
from sklearn.metrics import adjusted_rand_score as ari_score
from sklearn import metrics
def cluster_acc(y_true, y_pred):
y_true = y_true - np.min(y_true)
l1 = list(set(y_true))
numclass1 = len(l1)
l2 = list(set(y_pred))
numclass2 = len(l2)
ind = 0
if numclass1 != numclass2:
for i in l1:
if i in l2:
pass
else:
y_pred[ind] = i
ind += 1
l2 = list(set(y_pred))
numclass2 = len(l2)
if numclass1 != numclass2:
print('error')
return
cost = np.zeros((numclass1, numclass2), dtype=int)
for i, c1 in enumerate(l1):
mps = [i1 for i1, e1 in enumerate(y_true) if e1 == c1]
for j, c2 in enumerate(l2):
mps_d = [i1 for i1 in mps if y_pred[i1] == c2]
cost[i][j] = len(mps_d)
# match two clustering results by Munkres algorithm
m = Munkres()
cost = cost.__neg__().tolist()
indexes = m.compute(cost)
# get the match results
new_predict = np.zeros(len(y_pred))
for i, c in enumerate(l1):
# correponding label in l2:
c2 = l2[indexes[i][1]]
# ai is the index with label==c2 in the pred_label list
ai = [ind for ind, elm in enumerate(y_pred) if elm == c2]
new_predict[ai] = c
acc = metrics.accuracy_score(y_true, new_predict)
f1_macro = metrics.f1_score(y_true, new_predict, average='macro')
precision_macro = metrics.precision_score(y_true, new_predict, average='macro')
recall_macro = metrics.recall_score(y_true, new_predict, average='macro')
f1_micro = metrics.f1_score(y_true, new_predict, average='micro')
precision_micro = metrics.precision_score(y_true, new_predict, average='micro')
recall_micro = metrics.recall_score(y_true, new_predict, average='micro')
return acc, f1_macro
def eva(y_true, y_pred, epoch=0):
acc, f1 =cluster_acc(y_true, y_pred)
nmi = nmi_score(y_true, y_pred, average_method='arithmetic')
ari = ari_score(y_true, y_pred)
print(epoch, ':acc {:.4f}'.format(acc), ', nmi {:.4f}'.format(nmi), ', ari {:.4f}'.format(ari),
', f1 {:.4f}'.format(f1))
return acc, nmi, ari, f1
5.总结
图 编码器总结:
SDCN :GAE 的 解码器是 简单的内积。
DFCN:GAE 的解码器是 和编码器相同的GCN 类似于AE。
GATE:GAE解码器,是编码器的逆,通过存储编码器时的权重,解码器的时候使用.
DAEGC:GAE 融合了注意力机制