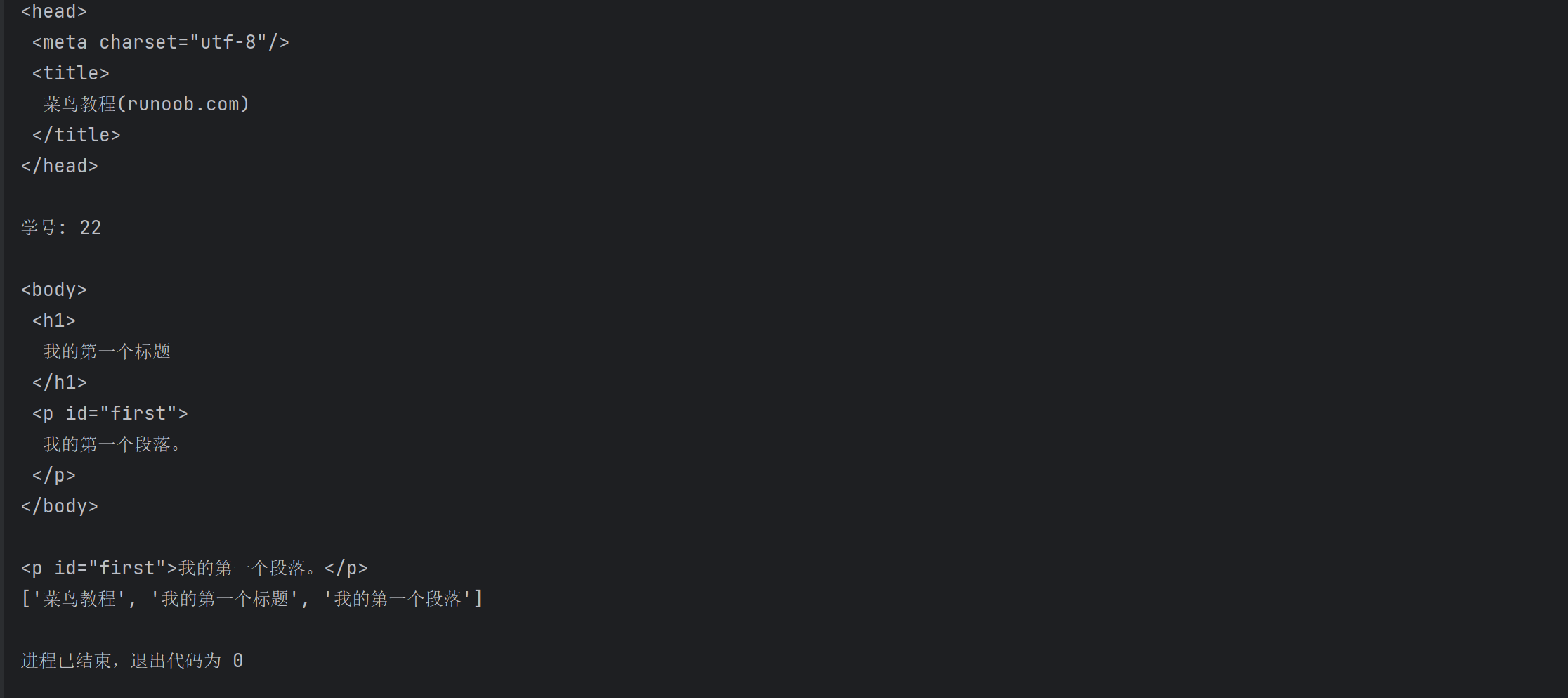
import requests url = 'https://www.baidu.com' for i in range(20): response = requests.get(url) print(f"第{i+1}次访问") print(f'Response status: {response.status_code}') print(f'Text content length: {len(response.text)}') print(f'Content length: {len(response.content)}') print(response
.text)
运行结果
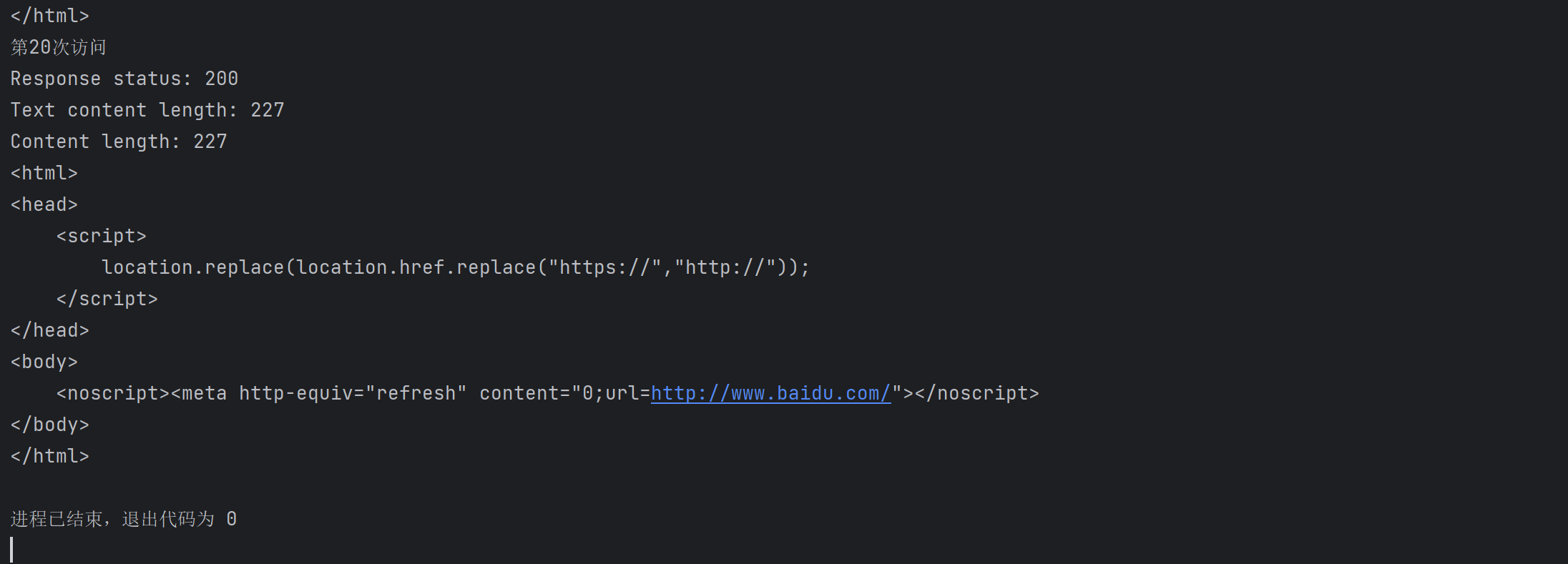
from bs4 import BeautifulSoup import re text = """ <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html> """ # 创建BeautifulSoup对象 soup = BeautifulSoup(text, features="html.parser") # 打印head标签和学号后两位 print(soup.head.prettify()) print("学号: 22\n") # 获取body标签对象 print(soup.body.prettify()) # 获取id为first的对象 first_p = soup.find(id="first") print(first_p) # 获取打印中文字符 pattern = re.compile(u'[\u4e00-\u9fff]+') chinese_chars = pattern.findall(text) print(chinese_chars)
运行结果