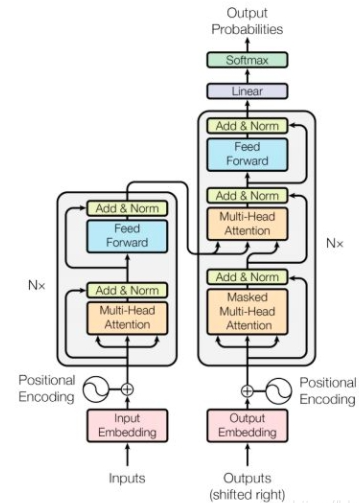
1.Transformer
1.1Transformer结构
Transformer分为输入,输出,Encoderbolck和Decoder bolck四个部分
1.2Transformer的输入
Transformer的输入是序列输入,inputs embedding输入的词向量要添加位置编码,这是因为 Transformer基于自注意力机制,而自注意力机制无法获取词语的位置信息。下面是位置编码的公式
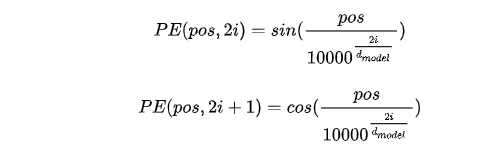
位置编码用两个不同频率的正弦余弦函数生成,再用对应位置词向量加上位置编码。
1.3Transformer的Encoder
Transformer的Encoder由Multi-Head Attention 和全连接神经网络Feed Forward Network构成,Multi-Head Attention 是基于self-attention,对于输入的embedding矩阵得到多组的Query,Keys,Values,然后每组分别计算得到一个Z矩阵,最后将得到的多个Z矩阵进行拼接。
1.4Transformer的Decoder
Transformer的Decoder由Masked Multi-Head Attention,Multi-Head Attention 和全连接神经网络FNN构成,与Encoder不同的是Decoder有两个Multi-Head Attention,一个是记录之前输出的信息,另一个是通过输入信息预测输出信息。
1.5Transformer的输出
Transformer的输出是把Decoderd的输出线性变换,再经过Softmax输出概率分布,概率最大对应词就为预测输出
2.FCN
FCN(Fully Convolutional Networks,全卷积网络)
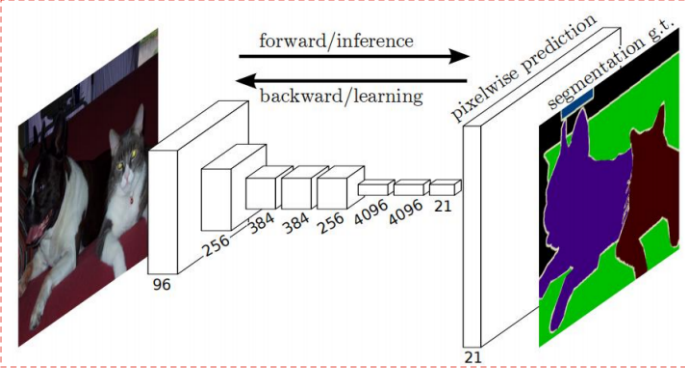
FCN对图像进行像素级的分类,该网络结构是在CNN的基础上,把CNN的所有全连接层都换成卷积层,再进行上采样, 恢复到输入图像相同的尺寸, 最后在上采样的特征图上使用softmax进行逐像素分类。
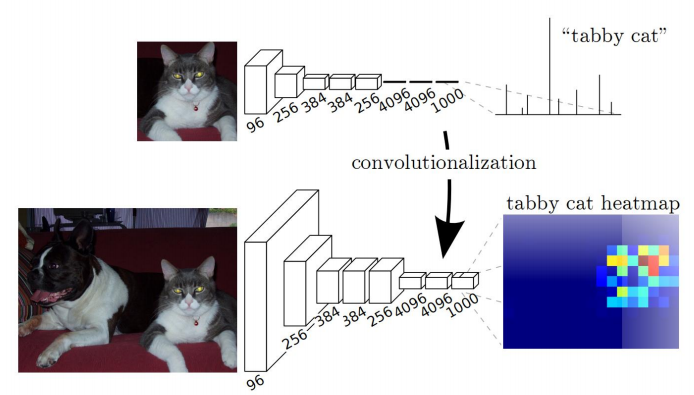

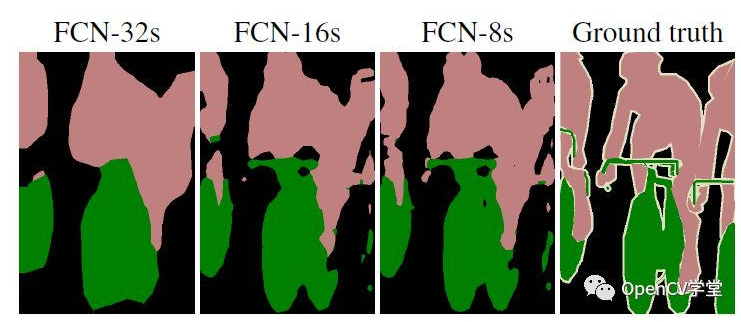
上采样次数越多,分割效果越好。
3.PSPNet
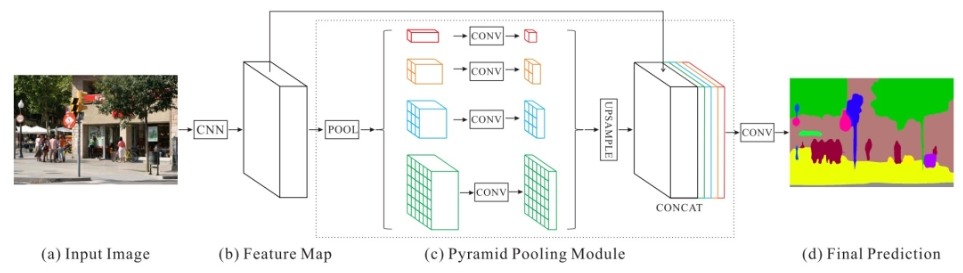
PSPNet原理:输入图像通过CNN网络获得最后一个卷积层的特征图,经过金字塔解析模块生成不同子区域,这些子区域经过上采样和连接层得到最终特征表征,将该表征送入卷积层后得到最终像素预测。

PSPNet结构的核心就是Pyramid Pooling Module。其中backbone为resnet网络,将原始图像下采样8倍成特征图,特征图输入到PPM模块,并与其输出相加,最后经过卷积和8倍双线性差值上采样得到结果
4.Deeplab-v3
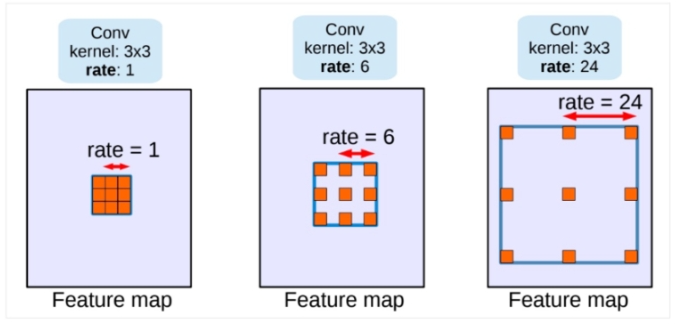
深层卷积网络在解决语义分割问题时常常会有分辨率低,空间位置不敏感等问题。Deeplab-v3通过使用不同sample rate空洞卷积以级联或平行的方式处理多尺度问题,再用ASPP使其在图像级编码全局上下文信息来生成卷积特征

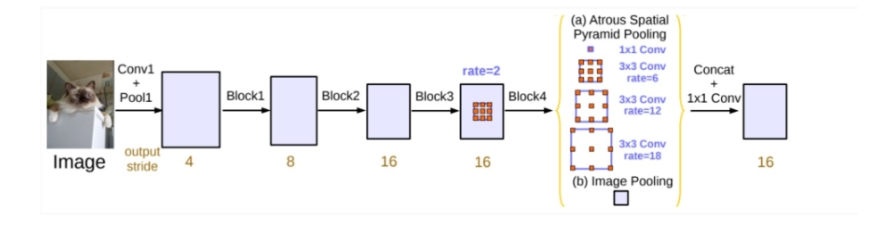
下面是二维空洞卷积的公式
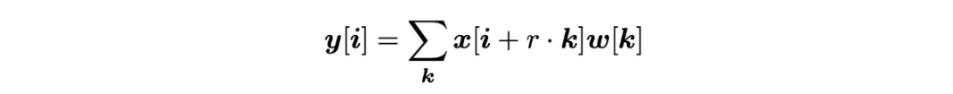
r对应样本步频的输入信号,相当于卷积输入x的filter中两个空间上相邻的weight插入r-1个0.