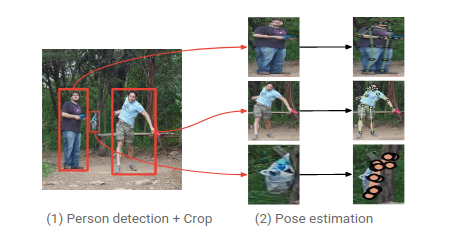
Body keypoint
人体关键点检测方法
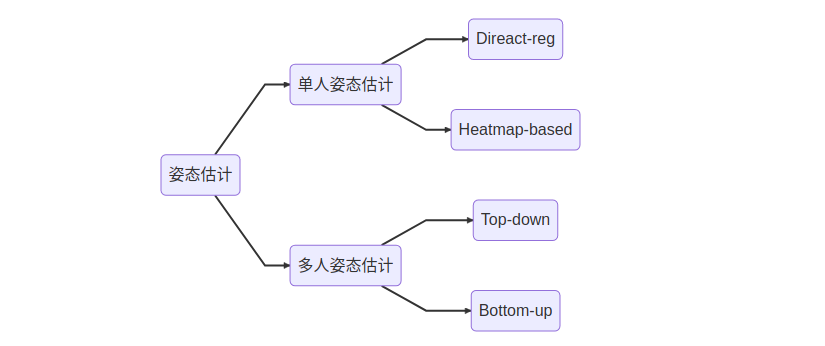
人体关键点检测, 即姿态估计可以分为两大类, 即单人姿态估计和多人姿态估计。其中单人姿态估计又可按如下划分
- 回归方法:应用端到端框架来学习从输入图像到身体关节位置或人体模型参数的映射
- 基于热图的方法:预测身体部位和关节的大致位置,这些位置由高斯分布的热图表示
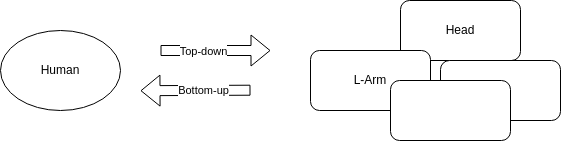
单人姿态估计算法往往会被用来做多人姿态估计。多人姿态估计的输入是一张整图,可能包含多个行人,目的是需要把图片中所有行人的关键点都能正确的做出估计。 针对这个问题,一般有两种做法,分别是top-down以及bottom-up的方法。
- 对于top-down的方法,往往先找到图片中所有行人,然后对每个行人做姿态估计,寻找每个人的关键点。单人姿态估计往往可以被直接用于这个场景。
- 对于bottom-up,思路正好相反,先是找图片中所有parts (关键点),比如所有头部,左手,膝盖等。然后把这些parts(关键点)组装成一个个行人。
所以姿态估计可划分如下:
数据集
| dataset | year | single-person/multi-person | joints | num of train | num of val | number of test | evaluation protocol | other info |
|---|---|---|---|---|---|---|---|---|
| LSP | 2010 | Single | 14 | 1k | - | 1k | PCP | Leeds Sports Pose Dataset |
| FLIC | 2013 | Single | 10 | 5k | - | 1k | PCP&PCK | Frames Labeled In Cinema |
| MPII | 2014 | Single Multiple |
16 16 |
29k 3.8k |
- | 12k 1.7k |
PCPm/PCKh mAP |
- |
| MSCOCO | 2017 | Multiple | 17 | 64k | 2.7k | 40k | AP | COCO2017 |
| PoseTrack | 2018 | Multiple | 15 | 593 | 170 | 375 | mAP | PoseTrack2018 |
| CrowdPose | 2019 | Multiple | 14 | 10k | 2k | 8k | mAP | - |
这里仅展示常见的2D pose数据集
评价指标
一般来说, 关键点检测是根据预测关键点与真实标注关键点之间的欧式距离来评判的。
PCK(Percentage of Correct Keypoints):关键点正确估计的百分比,计算检测的关键点与其对应的 groundtruth 间的归一化距离小于设定阈值的比例。该指标在2017年以前广泛使用,现在基本不再使用。公式如下
其中: i 表示关节点的编号, \(d_i\) 表示第i个关节点的预测值和 groundtruth 的欧氏距离。 d 是归一化系数,在不同的数据集里的计算方法不同。例如 MPII 中 数据集是以头部长度作为归一化参考,即 PCKh
PCP(Percentage of Correct Parts): 类似于PCK, 计算关键点与groundtruth间小于肢体长度的一部分(0.1到0.5)的比例
OKS(object keypoint similarity): oks 表示关键点的相似度,它与预测关键点和真实关键点之间的欧式距离有关,其范围值为 [0, 1]。当它们的欧式距离为 0 时,其 oks 相似度等于 1
其中:i 为关键点的编号,\(d_i\) 表示预测的关键点和 groundtruth 之间的欧式距离,S 是一个尺度因子,为人体检测框面积的平方根, \({\sigma}_i\) 是一个归一化因子,和关键点标注的难易有关,是通过对所有样本的人工标注和真实值的统计标准差。 \(v_i\) 表示当前关键点是否可见。\(\delta\)用于将可见点选出来进行计算的函数
AP(Average Precision): 这个和目标检测里的 AP 概念是一样的,只不过度量方式 iou 替换成了 oks。如果 oks 大于阈值 T,则认为该关键点被成功检测到。单人姿态估计和多人姿态估计的计算方式不同。对于单人姿态估计的AP,目标图片中只有一个人体,所以计算方式为:
对于多人姿态估计而言,由于一张图像中有 M 个目标,假设总共预测出 N 个人体,那么groundtruth和预测值之间能构成一个 MxN 的矩阵,然后将每一行的最大值作为该目标的 oks,则:
mAP, 顾名思义,AP的均值,具体计算方法就是给定不同的阈值t,计算不同阈值情况下对应的AP,然后求个均值就ok了。具体代码可参考COCO实现
应用与挑战
-
人体骨骼关键点检测是计算机视觉的基础性算法之一,在计算机视觉的其他相关领域的研究中都起到了基础性的作用,如行为识别、人物跟踪、步态识别等相关领域。具体应用主要集中在智能视频监控,病人监护系统,人机交互,虚拟现实,人体动画,智能家居,智能安防,运动员辅助训练等等。
-
由于人体具有相当的柔性,会出现各种姿态和形状,人体任何一个部位的微小变化都会产生一种新的姿态,同时其关键点的可见性受穿着、姿态、视角等影响非常大,而且还面临着遮挡、光照、雾等环境的影响,除此之外,2D人体关键点和3D人体关键点在视觉上会有明显的差异,身体不同部位都会有视觉上缩短的效果(foreshortening),使得人体骨骼关键点检测成为计算机视觉领域中一个极具挑战性的课题。
单人姿态估计
Direct regression
DeepPose
2014
DeepPose 2014 年由谷歌的研究人员提出,是最先将神经网络应用在人体姿态估计和关键点定位方面的论文。论文指出, 关键点定位中存在一些问题, 如关键点很小或者几乎看不见、被遮挡、关键点混淆等问题。DeepPose 以AlexNet为backbone, 直接回归关键点坐标,为了提高回归精度,首先基于人体 box 框对关键点坐标进行归一化:

模型结构方面如下图所示,使用 5 个卷积层和两个全连层,最后对于 k 个关键点输出 2k 个坐标值。为了获得更高的定位精度,使用多个网络进行级联,将前一阶段的网络预测输出附近图像截取出来,输入后一阶段网络获取更精细化的定位坐标值。
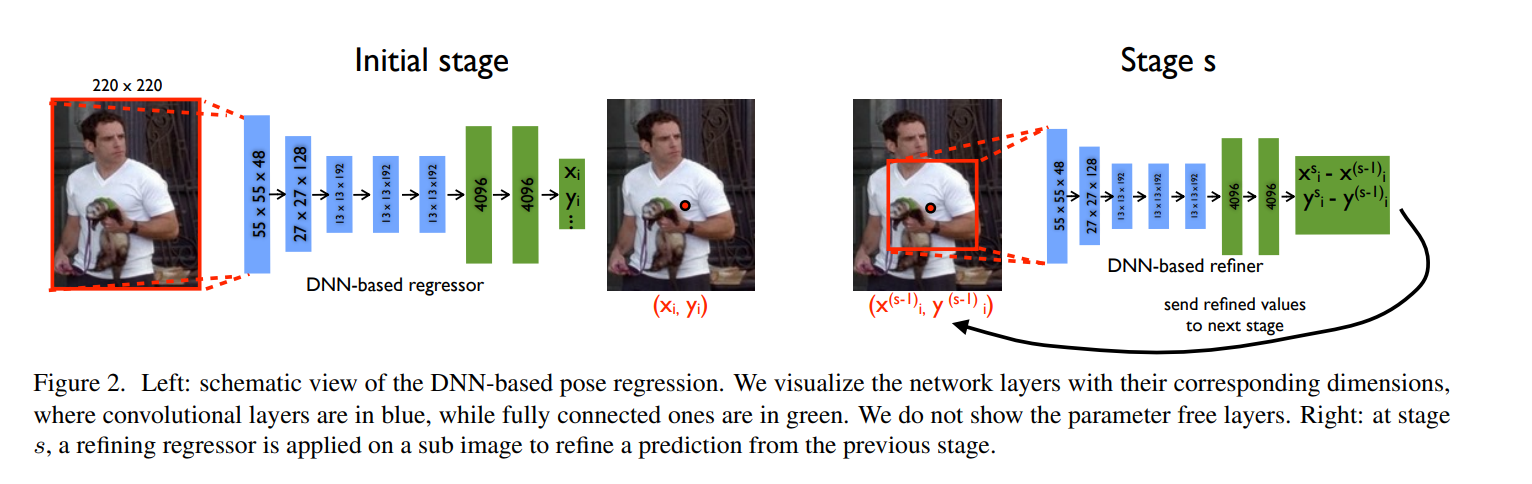
损失函数方面使用预测值和标注值之间的 L2 距离作为损失。网络在 FLIC(Frames Labeled In Cinema) 和 LSP(Leeds Sports Dataset)数据集上进行测试。
Compositional PR
2017
作者认为之前的基于回归的方法中, 姿势中的结构信息没有得到很好的利用。于是论文提出了提出了一种结构感知的回归方法。它采用使用骨骼而不是关节的重新参数化姿势表示。它利用关节连接结构来定义组合损失函数,该函数对姿势中的长程交互进行编码。它简单、有效且通用,适用于统一设置中的 2D 和 3D 姿态估计。
PRTR
2021? Pose Recognition with Cascade Transformers
? code
该文首先设计了基于Transformer的人体姿态估计网络, 属于直接回归坐标的方法。

利用transformer进行姿势识别的结构分为两个阶段。首先,利用全图图像特征和绝对位置编码,人物检测transformer通过一组学习的人物query来检测图像中的人物。过滤背景查询后,我们用预测框裁剪原始图像。裁剪后的图像连同相对于相应边界框的位置编码一起被送入关键点检测transformer。最后,通过匈牙利算法从一组更大的关键点查询中读出 J 个关键点。关键点检测转换器以矢量化的方式处理所有预测的非背景关键点。下图中h (0) 表示假设(queries),即通过转换器解码器细化为最终预测结果 yˆ 的特征向量。
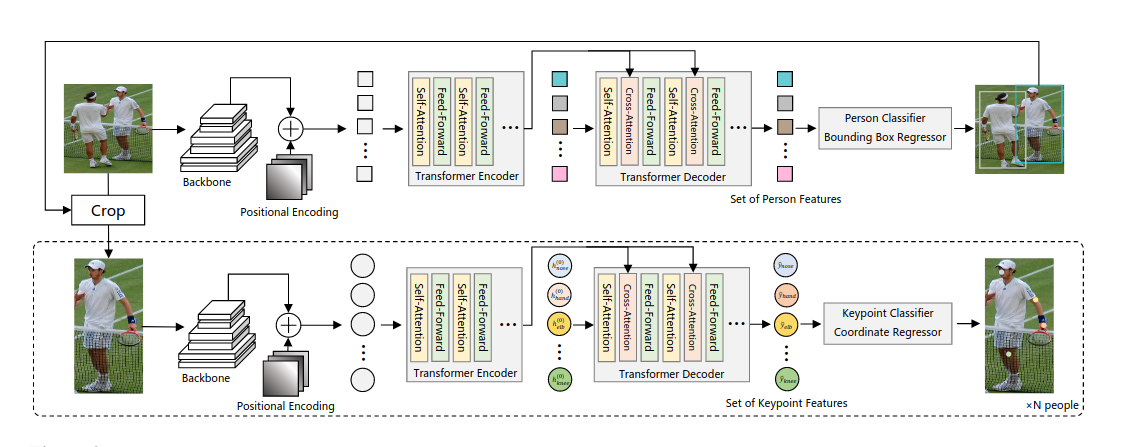
下图是PRTR端到端变体的架构。对于端到端学习,不再在 RGB 图像级别进行裁剪,而是在多层主干生成的特征上应用可微双线性采样,为关键点检测 Transformer 提供放大和多级特征。

Heatmap based
Hourglass
2016? Stacked Hourglass Networks forHuman Pose Estimation
? code
Hourglass是基于热图预测关键点的模型,也是后来各种姿态估计算法最为常用的backbone之一。
中心思想
- 提出一种新的卷积网络结构,称为堆叠式沙漏网络,用于人体姿态估计
- 融合各个尺度提取特征,重复自顶向下、自底向上的架构
- 几个关键技术:残差模块、Hourglass Module、中间监督
模型结构
Hourglass module是由单元残差模块组合而成, 将Hourglass module堆叠起来,前后增加一些简单的层, 即构成了网络架构
- 残差模块
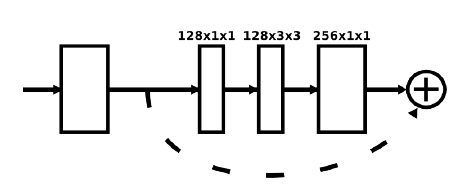
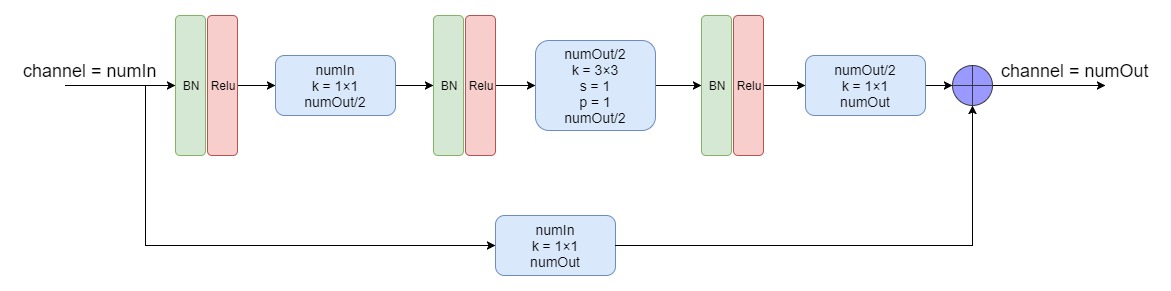
残差块结构如上图所示,详细的数据过程见下图, 主体路径是是3个卷积层,卷积核分别为:1x1、3x3和1x1,skip路径是一个卷积核为1x1的卷积层
- Hourglass Module。Hourglass Module由上面的Residual Module组成,由于它是一个递归的结构
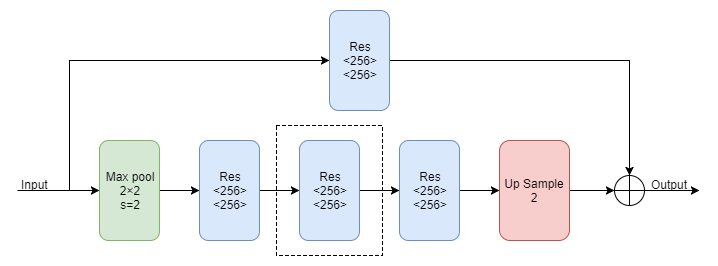
四阶的Hourglass module如下
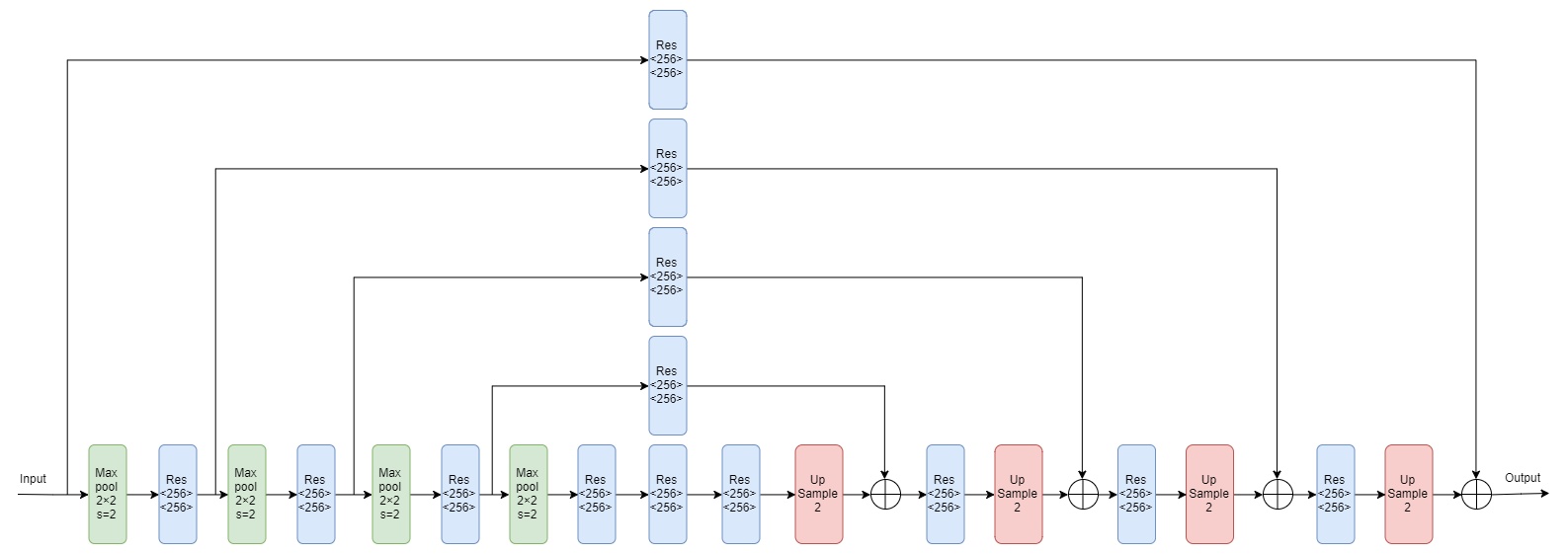
- 整体架构。网络输入的图片分辨率为256×256,然后经过一个7x7,步长为2的卷积层,之后再经过一个残差块和Maxpooling层使得分辨率降低到64,这一步骤的目的主要是降低显存。然后将尺寸为64x64的特征图输入到8个堆叠起来的(4阶Hourglass Module+Res+conv+relu+conv)中,特征输出尺寸保持不变。最后一个Hourglass Module的输出不再进行合并,直接输出heatmap。数据流如下

上面的整体网络架构图中,红色的模块为中间监督的过程,输出为16通道,针对MPII数据集,因为该数据集有16个关节点,因此输出为16通道
- 中继监督。作者在整个架构中堆叠了8个hourglass模块,提到其关键是要使用中间监督来对每一个hourglass模块进行预测,即计算每个hourglass模块输出的heatmap的损失。中间监督的位置图下图中蓝色部分所示,选取该位置的是因为, 监督的特征,需要同时包含高级别和低级别、全局和局部特征,因此选在每个hourglass模块的输出位置

作者对每个hourglass的输出的heatmap计算loss,每个loss给予不同的权重,并加和成为模型学习的总loss,进行反向传播
CPM
2016
训练阶段
网络结果和感受野示意图如下所示

网络输入彩色图像(绿色ori image)。以半身模型为例,分为四个阶段(stage)。每个阶段都能输出各个部件的响应图(蓝色score),使用时以最后一个阶段的响应图输出为准。
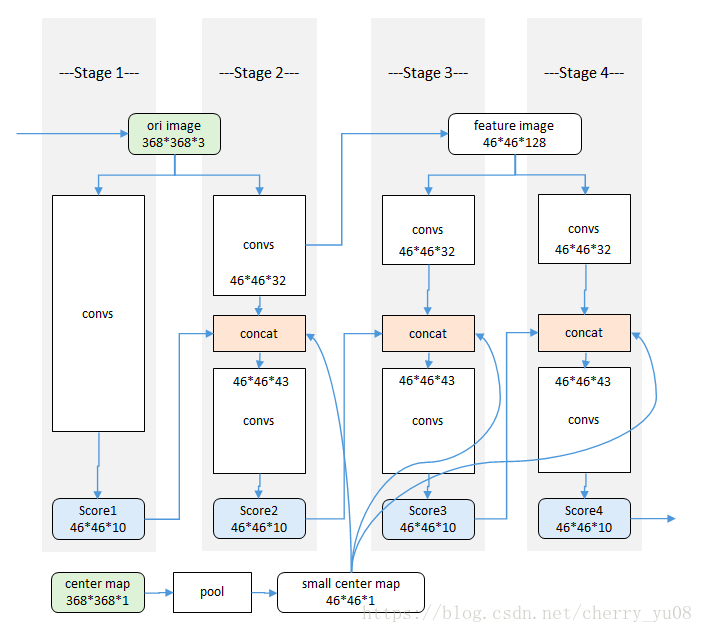
center map(绿色)是一个提前生成的高斯函数模板,用来把响应归拢到图像中心。
创新点
CPM的网络结构相当于结合了VGG(网络结构图中的X和X‘部分)和FCN(pixcel level的处理,输出不是向量而是与图片等宽等高的矩阵),在此基础之上加入三个辅助内容:
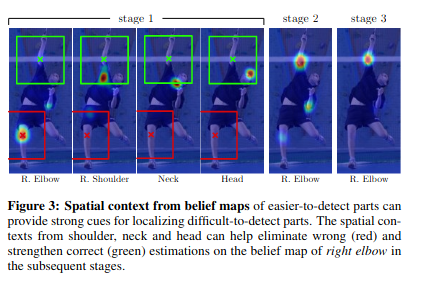
- belief map。一方面是获取每一个stage输出的heatmap,同时该belief map有助于后续stage的训练,根据论文中下图图片描述可知,belief map提供的易于检测部位的上下文信息为不易检测的部位(遮挡部位)提供了检测的线索:
- 中间监督。 在每一个stage的输出阶段计算bilief map和label的loss,最后将所有loss加和得到total loss,根据每一个stage的loss更新该阶段的参数w,这种方法实现中间监督,可以有效避免梯度消失(或者梯度爆炸)
- center map。center map是一个与图片同等大小、通道数为1的高斯模版,用于处理图片中多个人物的情况,实现多目标的姿态估计。
CPN
2018
在本文中,作者提出了一种新的网络结构,称为Cascaded Pyramid Network(CPN)级联金字塔网络,该网络可以有效缓解“hard” keypoints的检测问题,CPN网络分为两个阶段:GlobalNet和RefineNet。GlobalNet网络是一个特征金字塔网络,该网络用于定位简单的关键点,如眼睛和手等,但是对于遮挡点和不可见的点可能缺乏精确的定位;RefinNet网络该网络通过集合来自GolbalNet网络的多级别特征来明确解决“难点”的检测问题。
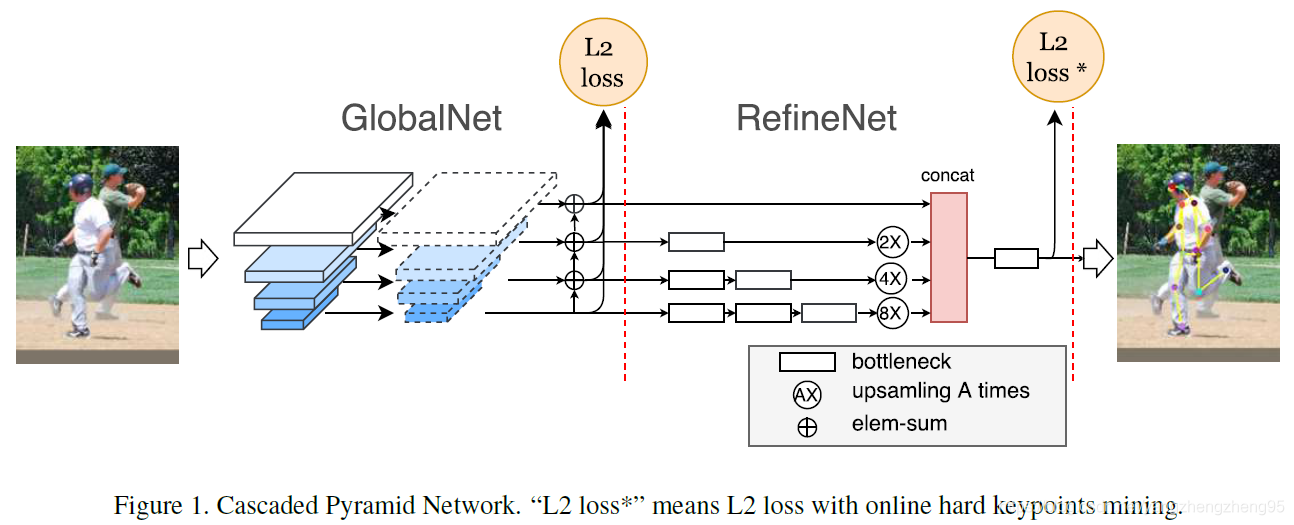
GlobalNet
backbone采用resnet网络,以resnet50为例,使用在imagenet上预训练的resnet50网络,然后使用该网络提取特征,分别使用1/4,1/8,1/16,1/32四个级别的网路特征(conv2_x, conv3_x, conv4_x, conv5_x的输出),然后在GlobalNet中分别将四层特征的通道转换为相同的通道数,此时,得到了四层通道数相同的特征图,该四层特征用两个用途:
- 对该四层网络特征做如下操作:低层特征进行上采样,与上一层特征进行相加,即不同尺度特征进行融合,最终得到融合了低层特征的四层特征,最后对该四层特征分别进行通道转换(转换为与关键点数目相同的通道数)并都上采样到1/4大小,用于计算该阶段的L2 loss)(四层输出分别和四种不同的高斯分布的label进行损失计算)。
- 在RefineNet中进行使用
RefineNet
在GlobalNet中,得到了四层特征图,作者通过给每一层特征图设计了不同的数量的botleneck块,再分别经过不同倍率的上采样,然后经过concat操作后,达到了对不同尺度特征的结合,最后经过一个bottlenet块,再经过简单的变换,得到网络的最终的输出。
注意:L2 loss和L2 loss*的区别,在GlobalNet中,使用L2 loss,即GlobalNet网络的输出和label计算所有关键点的loss;在RefineNet中,使用L2 loss*,即网络输出和label计算所有关键点的loss,然后对loss进行从大到小排序,最后选择top-k个loss用于网络的反向传播。
Simple Baselines
2018? Simple Baselines for Human Pose Estimation and Tracking
? code
本文的方法对比之前的hourglass和CPN的结构都会显得十分简单,只是简单地在ResNet的最后一个卷积stage后面加了一些deconv layers。这些deconv layers默认跟着一个BN和ReLU。每一层都有256 * 4 * 4的卷积核,stride为2。最后通过一个 1*1的卷积核计算得到heatmaps \(H_k\)
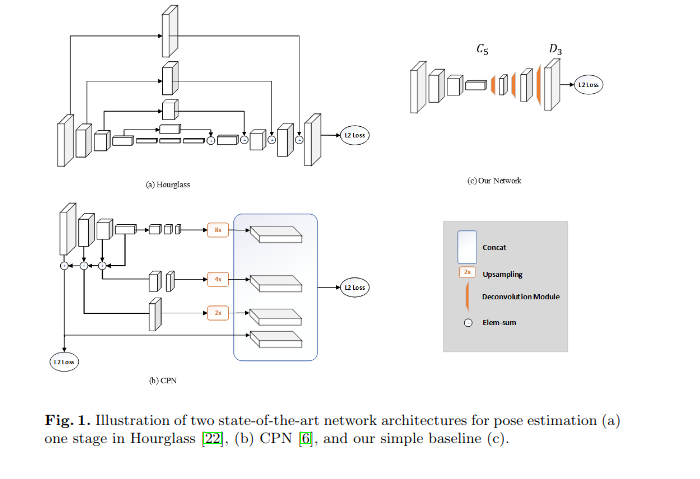
本文网络和hourglass还有CPN最大的区别就是在head 处是如何得到高分辨率的feature map的,前两个方法都是上采样得到heatmap,但是simple baseline的方法是使用deconv ,deconv相当于同时做了卷积和上采样。
SGANPose
2018? Self Adversarial Training for Human Pose Estimation
? code
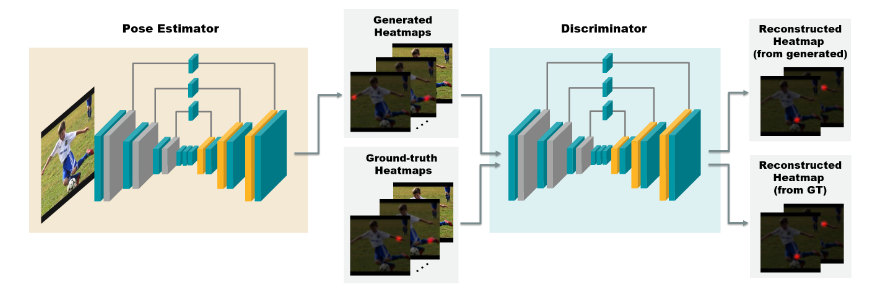
本文的模型分为两个网络,生成器和鉴别器。第一个网络生成器是一个卷积网络,生成器经过前向计算,得到一组热图,它指示每个关键点的每个位置的置信度得分。第二个网络鉴别器,具有与生成器相同的架构,但它将热图与RGB图像一起编码输入,并将其解码为一组新的热图,以便区分真实的热图和虚假的热图。本文提出的自对抗网络结果如下图所示。在最终做关键点前向推理时,会将鉴别器从整体的结果中剔除。
HRNet
2019? Deep High-Resolution Representation Learning for Human Pose Estimation
? code
HRNet在多种视觉任务中常出现。该篇论文介绍了HRNet在姿态估计中的应用。作者在设计网络的时候,一直保持high resolution representations, 在设计上采用网络并行连接从高到低的子网的方式。
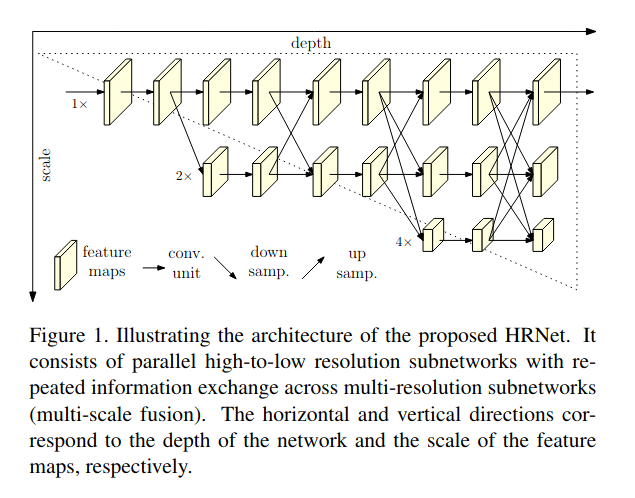
主干分支一直保持高分辨率, 为了解决高分辨率representations感受野不够大的问题, 渐进的增加高分辨率到低分辨率representations的子网的方式来获取更多全局信息。通过fusion模块把高分辨率representations信息和低分辨率信息进行交换,同时把低分辨率分支的global信息来增强高分辨率representations的学习,同时高分辨率分支的局部特征来增强低分辨率representations的学习。
fusion模块
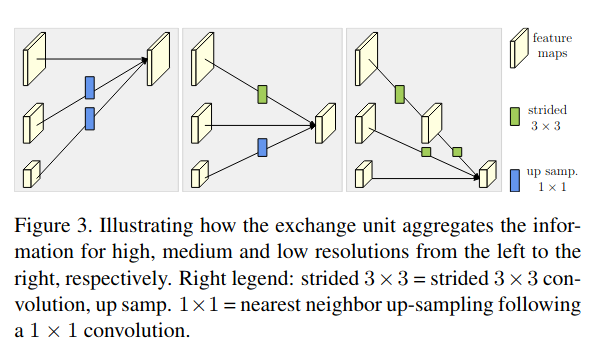
用低分辨率representations增强高分辨率representations。它是设计通过upsampling加1*1的convoluation融合到高分辨率representations 本文还设计一个模块通过strided等于2,慢慢把分辨率降到和低分辨率representations一样的情况,再进行高分辨率representations feature和低分辨率representations feature的融合。 通过这种设计高分辨率representations既得到了global的信息的一个增强,同时低分辨率representations因为得到高分辨率representations的一些细节信息而得到增强。
网络实例化

HRNet 的主干网络,包含有 4 个并行子网络的4个stages,其分辨率逐渐衰减一半,对应的网络宽度(width)(通道数)增加2倍。每个stage分成蓝色框和橙色框两部分。其中蓝色框部分是每个stage的基本结构,由多个branch组成,HRNet中stage1蓝色框使用的是BottleNeck,stage2&3&4蓝色框使用的是BasicBlock。其中橙色框部分是每个stage的过渡结构,HRNet中stage1橙色框是一个TransitionLayer(参考code),stage2&3橙色框是一个FuseLayer和一个TransitionLayer的叠加,stage4橙色框是一个FuseLayer。
解释一下为什么这么设计,FuseLayer是用来进行不同分支的信息交互的,TransitionLayer是用来生成一个下采样两倍分支的输入feature map的,stage1橙色框显然没办法做FuseLayer,因为前一个stage只有一个分支,stage4橙色框后面接neck和head了,显然也不再需要TransitionLayer了。
其它:
- stages1与resnet50第一个res2相同,包括4个bottleneck
- 从上到下,每个stages分辨率减半,通道增倍,文中提到HRNet-W32和HRNet-W48,指的是这些stage的通道数不同,但结构相同
- 从整体上看,与resnet50极为相似,但多了些过渡单元transition和并行子网络,以及exchange需要的操作
demo

整体预测函数为
def pose_predict_2d(cfg, image, model, pred_boxes):
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
)
transformer = transforms.Compose([
transforms.ToTensor(),
normalize
])
centers, scales = [], []
for box in pred_boxes:
center, scale = box_to_center_scale(box, cfg.MODEL.IMAGE_SIZE[0], cfg.MODEL.IMAGE_SIZE[1])
centers.append(center)
scales.append(scale)
rotation = 0
model_inputs = []
for center, scale in zip(centers, scales):
trans = get_affine_transform(center, scale, rotation, cfg.MODEL.IMAGE_SIZE)
model_input = cv2.warpAffine(
image,
trans,
(int(cfg.MODEL.IMAGE_SIZE[0]), int(cfg.MODEL.IMAGE_SIZE[1])),
flags=cv2.INTER_LINEAR)
# hwc -> 1chw
model_input = transformer(model_input)#.unsqueeze(0)
model_inputs.append(model_input)
model_inputs = torch.stack(model_inputs)
with torch.no_grad():
output = model(model_inputs.to(dev))
coords, _ = get_final_preds(
cfg,
output.cpu().detach().numpy(),
np.asarray(centers),
np.asarray(scales)
)
return coords
其中box_to_center_scale为
def box_to_center_scale(box, model_image_width, model_image_height):
"""convert a box to center,scale information required for pose transformation
Parameters
----------
box : list of tuple
list of length 2 with two tuples of floats representing
bottom left and top right corner of a box
model_image_width : int
model_image_height : int
Returns
-------
(numpy array, numpy array)
Two numpy arrays, coordinates for the center of the box and the scale of the box
"""
center = np.zeros((2), dtype=np.float32)
bottom_left_corner = box[0]
top_right_corner = box[1]
box_width = top_right_corner[0]-bottom_left_corner[0]
box_height = top_right_corner[1]-bottom_left_corner[1]
bottom_left_x = bottom_left_corner[0]
bottom_left_y = bottom_left_corner[1]
center[0] = bottom_left_x + box_width * 0.5
center[1] = bottom_left_y + box_height * 0.5
aspect_ratio = model_image_width * 1.0 / model_image_height
pixel_std = 200
if box_width > aspect_ratio * box_height:
box_height = box_width * 1.0 / aspect_ratio
elif box_width < aspect_ratio * box_height:
box_width = box_height * aspect_ratio
scale = np.array(
[box_width * 1.0 / pixel_std, box_height * 1.0 / pixel_std],
dtype=np.float32)
if center[0] != -1:
scale = scale * 1.25
return center, scale
后续将box的图像通过仿射变换到设定的大小,并且中心在box中心。这里最后得到的center就是box的center。在得到每个box的center和scale后,需要获取每个person的输入,这里先得到针对每个person,原图到输入的仿射变换(平移,旋转,伸缩)矩阵:
def get_affine_transform(
center, scale, rot, output_size,
shift=np.array([0, 0], dtype=np.float32), inv=0
):
if not isinstance(scale, np.ndarray) and not isinstance(scale, list):
print(scale)
scale = np.array([scale, scale])
scale_tmp = scale * 200.0
src_w = scale_tmp[0]
dst_w = output_size[0]
dst_h = output_size[1]
rot_rad = np.pi * rot / 180
src_dir = get_dir([0, src_w * -0.5], rot_rad)
dst_dir = np.array([0, dst_w * -0.5], np.float32)
src = np.zeros((3, 2), dtype=np.float32)
dst = np.zeros((3, 2), dtype=np.float32)
src[0, :] = center + scale_tmp * shift
src[1, :] = center + src_dir + scale_tmp * shift
dst[0, :] = [dst_w * 0.5, dst_h * 0.5]
dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir
src[2:, :] = get_3rd_point(src[0, :], src[1, :])
dst[2:, :] = get_3rd_point(dst[0, :], dst[1, :])
if inv:
trans = cv2.getAffineTransform(np.float32(dst), np.float32(src))
else:
trans = cv2.getAffineTransform(np.float32(src), np.float32(dst))
return trans
在这里src_w为box的w,dst_w和dst_h为规定的output size。这里get_dir函数对点[0, -0.5*src_w],然后这里首先找到的两个点对一个是刚刚提到的,另一个就是中心点,然后在根据前两个点找第三个点对,使得其于中心的连线与第一个点与中心的连线垂直。通过这三个点对获得仿射矩阵(也可以获得相应的逆变换)。在通过cv2.warpAffine得到相应的输入。最后每一个person的detection结果都能获得一个heatmap,在通过get_final_preds得到最终的coordinates:
def get_final_preds(config, batch_heatmaps, center, scale):
coords, maxvals = get_max_preds(batch_heatmaps)
heatmap_height = batch_heatmaps.shape[2]
heatmap_width = batch_heatmaps.shape[3]
# post-processing
if config.TEST.POST_PROCESS:
for n in range(coords.shape[0]):
for p in range(coords.shape[1]):
hm = batch_heatmaps[n][p]
px = int(math.floor(coords[n][p][0] + 0.5))
py = int(math.floor(coords[n][p][1] + 0.5))
if 1 < px < heatmap_width-1 and 1 < py < heatmap_height-1:
diff = np.array(
[
hm[py][px+1] - hm[py][px-1],
hm[py+1][px]-hm[py-1][px]
]
)
coords[n][p] += np.sign(diff) * .25
preds = coords.copy()
# Transform back
for i in range(coords.shape[0]):
preds[i] = transform_preds(
coords[i], center[i], scale[i], [heatmap_width, heatmap_height]
)
return preds, maxvals
def get_max_preds(batch_heatmaps):
'''
get predictions from score maps
heatmaps: numpy.ndarray([batch_size, num_joints, height, width])
'''
assert isinstance(batch_heatmaps, np.ndarray), \
'batch_heatmaps should be numpy.ndarray'
assert batch_heatmaps.ndim == 4, 'batch_images should be 4-ndim'
batch_size = batch_heatmaps.shape[0]
num_joints = batch_heatmaps.shape[1]
width = batch_heatmaps.shape[3]
heatmaps_reshaped = batch_heatmaps.reshape((batch_size, num_joints, -1))
idx = np.argmax(heatmaps_reshaped, 2)
maxvals = np.amax(heatmaps_reshaped, 2)
maxvals = maxvals.reshape((batch_size, num_joints, 1))
idx = idx.reshape((batch_size, num_joints, 1))
# 复制
preds = np.tile(idx, (1, 1, 2)).astype(np.float32)
# 获取该id的坐标
preds[:, :, 0] = (preds[:, :, 0]) % width
preds[:, :, 1] = np.floor((preds[:, :, 1]) / width)
pred_mask = np.tile(np.greater(maxvals, 0.0), (1, 1, 2))
pred_mask = pred_mask.astype(np.float32)
preds *= pred_mask
return preds, maxvals
通过get_max_preds函数或者各joint在图像上的位置,这里的post_process是通过相邻像素的heatmap来对当前joint的位置做一些修正。最后通过transform_preds函数将位置坐标变换到原始图像上
def transform_preds(coords, center, scale, output_size):
target_coords = np.zeros(coords.shape)
trans = get_affine_transform(center, scale, 0, output_size, inv=1)
for p in range(coords.shape[0]):
target_coords[p, 0:2] = affine_transform(coords[p, 0:2], trans)
return target_coords
Lite-HRNet
2021? Lite-HRNet: A Lightweight High-Resolution Network
? code
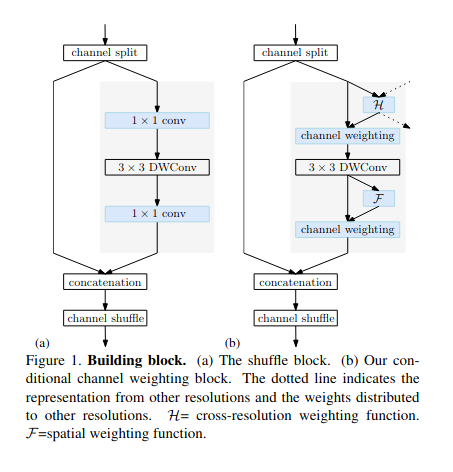
主要贡献:
- 简单地将 shuffle 块应用到 HRNet 中,形成一个轻量级网络 naive Lite-HRNet。
- 提出了一种改进的高效网络,LiteHRNet。关键点是引入了一种高效的条件通道加权单元来取代 shuffle 块中昂贵的 1 × 1 卷积,并且权重是跨通道和分辨率计算的。
- 论文指出Lite-HRNet 在 COCO 和 MPII 人体姿势估计的速度和精度权衡方面是最先进的
直接回归和热图方法对比
| 框架 | 优点 | 缺点 |
| 直接回归方法 | 快速、直接,以端到端的方式进行训练 | 难以学习映射 |
| 无需太多改动即可应用于3D场景 | 不适用于多人姿态估计 | |
| 热图方法 | 热图易于可视化 | 获取高分辨率热图需要高内存消耗 |
| 可用于复杂情况 | 难以扩展到3D场景 |
多人姿态估计
与单人姿态估计相比,多人姿态估计更加困难和具有挑战性,因为它需要弄清楚人员的数量和位置,以及如何对不同的人进行关键点分组。为了解决这些问题,多人姿态估计方法可以分为自上而下和自下而上的方法
Top-down
G-RMI
2017? Polarized self-attention: towards high-quality pixel-wise regression
? code
作者提出了新的自顶向下的多人姿态估计方法。首先使用 Faster RCNN 预测可能包含人体目标的边界框的位置和大小。然后估计每个提议边界框可能包含的关键点。使用ResNet 预测每个关键点的密度热图和偏移量。为了合并输出,作者引入了一种新的聚合过程来获得高度定位的关键点预测。作者还使用了一种新形式的基于关键点的非最大值抑制,而不是更粗糙的框级非最大抑制,以及一种新形式的基于关键点的置信度得分估计,而不是框级得分。
姿态重打分:测试时,将模型用于每个图像裁剪,而不是仅依赖人检测器置信度。考虑每个关键点置信度。最大化位置,平均化关键点产生最终实例级姿态检测分数

基于 OKS 的非最大抑制:使用目标关键点相似度来度量两个候选姿态检测是否重叠。姿态估计器输出处的更精细的OKS−NMS 更适合于确定两个候选检测是对应于 FP(同一个人的双重检测)还是TP(两个人彼此非常接近)
MSPN
2019? Rethinking on Multi-Stage Networks for Human Pose Estimation
? code
作者认为现有的多阶段网络的设计不是很合理。并从三个方面进行了分析:多阶段网络中单个stage结构设计不合理,重复升降采样导致的特征损失,多阶段只有一个损失难以优化。最终优化后的多阶段人体姿态估计(MSPN)框架图如下
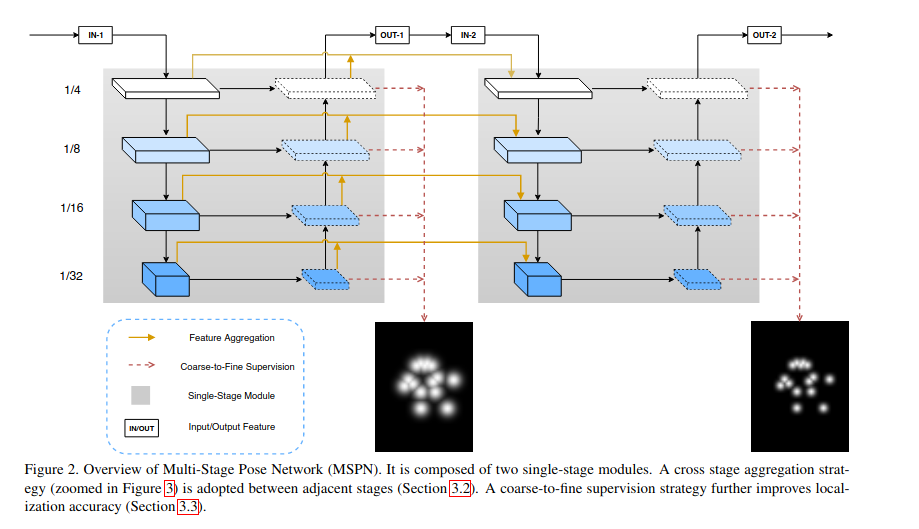
- 优化当个stage结构。作者采用CPN的网络结构来替换Hourglass中每个stage, 规避了特征因为降采样而丢失
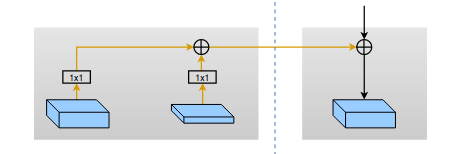
- 相邻stage特征聚合。作者将相邻阶段的特征进行聚合,以增强特征信息传播能力并降低训练难度。具体的特征聚合方法如下图所示,对于当前stage的某个降采样过程,其输入包含三个部分。分别为:上个阶段中相同size的降采样特征经过1*1卷积编码后的特征,上个阶段中相同size的升采样特征经过1*1卷积编码后的特征,以及当前stage的降采样特征。
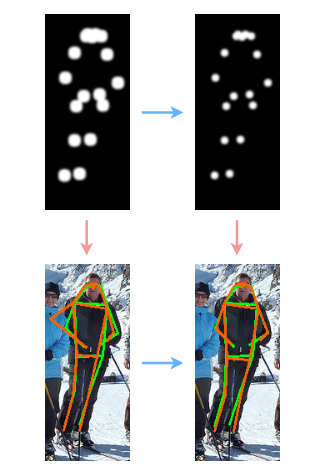
- 多stage由粗到细监督。多stage网络的特点是,每个stage的输出都能作为最终的关键点检测结果。而且随着stage的增多,关键点定位会越来越准。为了使得在前端的stage能够获得更好的知道,作者提出了由粗到细的多分支监督的方式来优化多stage的能力。如下图所示,正对于每个stage的特点,采用不同kernel-size的高斯核制作标签,越靠近输入的stagekernel-size越大。 在每个stage的监督标签中,使用不同大小的高斯核来制作GT热度图。前面的stage用大的高斯核,后面的stage用小的高斯核。
RSN
2020? Learning Delicate Local Representations for Multi-Person Pose Estimation
? code
出发点: 层内特征融合在人体姿态估计中的应用却很少。然而,它在语义分割和图像分类等其他任务中有着广泛的应用。如DenseNet使用连续的级联操作来融合层内特征。此实现保留了低级功能以提高性能。然而,随着网络的深入,网络容量急剧增加,网络中出现大量冗余信息,导致网络效率低下。
RSN使用元素级求和而不是串联来规避网络容量爆炸。此外,RSN在组成单元中的连接密度较小,这进一步提高了效率。
Proposed Method
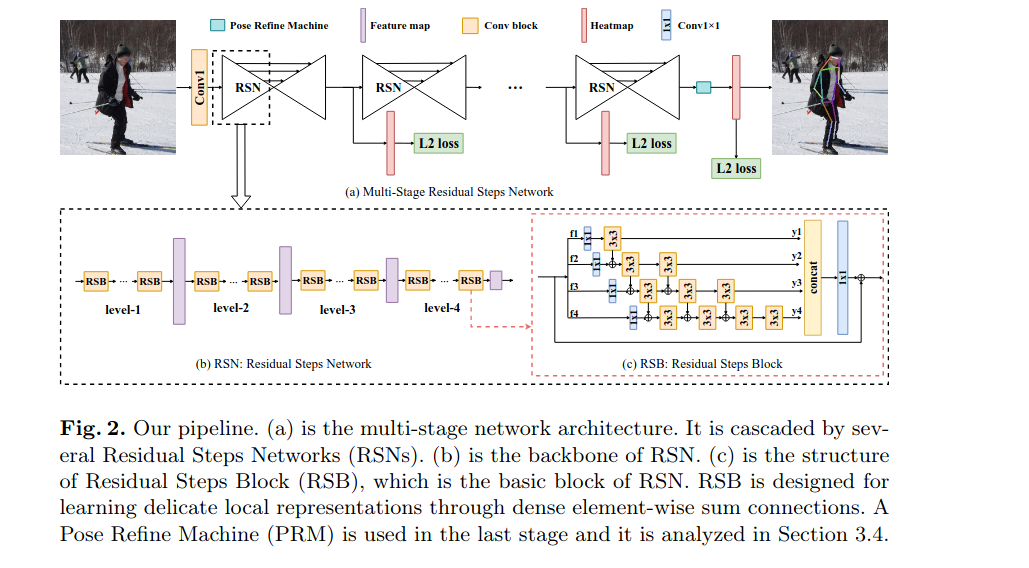
- 多级网络体系结构由几个单级模块级联而成——Residual Steps Network(RSN)
- RSN由 Residual Steps Blocks(RSB)组成。RSB是用来学习精细的局部表示,通过稠密的element-wise sum连接在一起。
- 最后一个阶段使用了姿态调整机(PRM)
- 使用中间监督
Delicate Local Representations Learning
- Residual Steps Network通过反复增强RSB内部高效的层内特征融合来学习精细的局部表示,RSB是RSN的组成单元。
- RSB首先将特征分成四个分割\(f_i\)(i=1, 2, 3, 4),然后分别执行一个1×1 conv。从conv1×1输出的每个特征都会经历3×3 conv。然后将输出特性\(y_i\)(i=1, 2, 3, 4)串联起来,在输入 1×1 conv。并使用identity连接。
- 由于conv3×3的排列看起来像steps,因此该网络被称为Residual Steps Network
- 在第i 个分支上,前i-1 conv3×3接收第i-1 个分支输出的特性。然后,第i 个conv3×3被设计用来重新融合第 i-1 个conv3×3输出的特征。
- 得益于密集的连接结构,特征的小间隙的感受野被充分融合,从而形成精细的局部表示,保留精确的空间和语义信息。
- 此外,在训练过程中,深度连接的结构提供了足够的梯度,因此可以更好地监督低层特征,这有利于关键点定位任务。
Receptive Field Analysis
- 感受野范围更广的体系结构更适合于提取与不同关节相关的特征
- 更广泛的感受野有助于学习更多的区分语义表示,这有利于关键点分类任务
- RSN通过RSB内部的small-gap感受野在特征之间建立紧密的连接。这种深度连接的体系结构有助于学习精细的局部表示
Pose Refine Machine

- GP表示global pooling,DW表示深度方向的可分离卷积。\(\alpha\) 表示权重向量。 \(\beta\)表示注意力。
- PRM的第一个组件是conv3×3,然后将特征输入到三个路径中。
- 顶部路径是identity连接。
- 中间路径,通过一个全局池,两个conv1×1和一个sigmoid激活来得到一个权重向量\(\alpha\)
- 底部路径经过conv1×1、深度可分离conv9×9和sigmoid激活,得到一个注意力地图\(\beta\)
- 在三条路径之间进行元素加和以及乘运算,得到输出特征
- 将PRM的输入特性定义为\(f_{in}\),将输出特性定义为 \(f_{out}\),将第一个conv3×3定义为 K(*),将元素乘法定义为\(\bigodot\) 。PRM可以表示为如下公式
\[f_{\text {out }}=K\left(f_{\text {in }}\right) \bigodot(1+\beta \bigodot \alpha) \] - 对于RSN的输出,将层内和层间聚合后的特征混合在一起,既包含低层次的精确空间信息,又包含高层的判别语义信息
- 空间信息有利于关键点定位,而语义信息有利于关键点分类。这些特征对最终预测的贡献各不相同。因此,为了解决这一不平衡问题,PRM旨在在RSN的输出特征中在局部和全局表示之间进行权衡
- PRM中的top identity mapping有助于保留本地特征,有利于精确定位关键点。中间路径被设计为在通道方向上重新加权特征,而底部路径被设计为用于空间注意力
UDP-Pose
2020? The Devil is in the Details: Delving into Unbiased Data Processing for Human Pose Estimation
? code
关键点检测大部分论文是从优化模型的角度出发, 该篇论文另辟蹊径, 优化数据处理, 提出的UDP方法也被后来的许多关键点检测方法所借鉴。
作者分析, 对于之前关键点检测中state-of-the-art方法,会存在两方面的问题:
- 一个是在测试过程中,如果使用flip ensemble时,由翻转图像得到的结果和原图得到的结果并不对齐
- 一个是使用的编码解码(encoding-decoding)方法存在较大的统计误差
- 这两个问题耦合在一起,产生的影响包括:估计的结果不准确、复现指标困难、有较大可能使得实验的结果结论不可靠。
用于人体姿态估计的无偏的数据处理方法(UDP)。UDP 包含两个主要的思想:一个是在数据处理的时候,使用单位长度去度量图像的大小,而非像素的多少,以解决第一个问题。另外,引入一种在理想情况下无统计误差的编码解码方法。

DARK
2020? Distribution Aware Coordinate Representation for Human Pose Estimation
? code
主要贡献:
- 提出了Distribution-Aware coordinate Representation of Keypoints (DARK)插件 ,主要包括两部分
- 基于泰勒展开的坐标解码
- 无偏sub-pixel中心坐标编码
- 在COCO和MPII上实现了最佳单模型精度
- 通过DARK,可以使用更小的输入图像分辨率,在小幅度性能下降的情况下,大幅提高模型推理效率,因此可根据嵌入式AI场景的要求,方便低延迟和low-energy应用
PSA
2021? Polarized self-attention: towards high-quality pixel-wise regression
? code
本文针对Pixel-wise regression的任务,提出了一种更加精细的双重注意力机制——极化自注意力(Polarized Self-Attention)。作为一个即插即用的模块,在人体姿态估计和语义分割任务上,作者将它用在了以前的SOTA模型上,并达到了新的SOTA性能
作者提出了Polarized Self-Attention (PSA)机制,同上面的思想一样,作者也是现在一个方向上对特征进行压缩,然后对损失的强度范围进行提升,具体可分为两个结构:
1)滤波(Filtering):使得一个维度的特征(比如通道维度)完全坍塌,同时让正交方向的维度(比如空间维度)保持高分辨率。
2)High Dynamic Range(HDR):首先在attention模块中最小的tensor上用Softmax函数来增加注意力的范围,然后再用Sigmoid函数进行动态的映射。
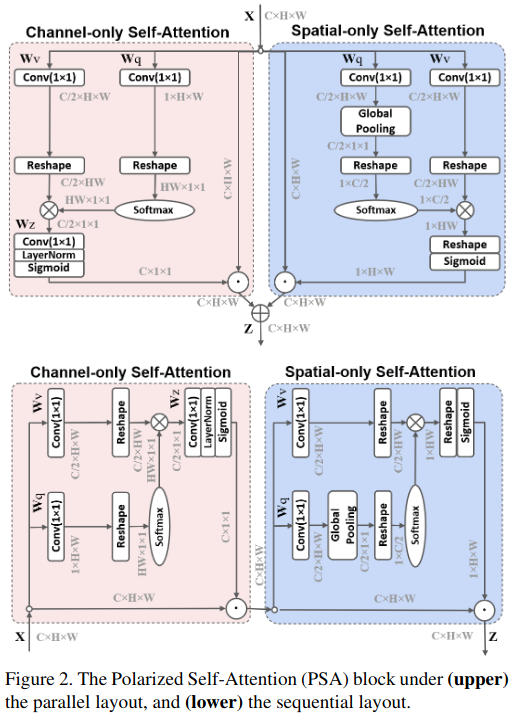
Channel-only branch
作者先用了1x1的卷积将输入的特征X转换成了Q和V,其中Q的通道被完全压缩,而V的通道维度依旧保持在一个比较高的水平(也就是C/2)。因为Q的通道维度被压缩,如上面所说的那样,就需要通过HDR进行信息的增强,因此作者用Softmax对Q的信息进行了增强。然后将Q和K进行矩阵乘法,并在后面接上1x1卷积、LN将通道上C/2的维度升为C。最后用Sigmoid函数使得所有的参数都保持在0-1之间。
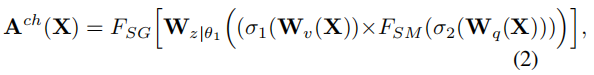
class Channel_only_branch(nn.Module):
def __init__(self, channel=64):
super().__init__()
self.ch_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.ch_wq=nn.Conv2d(channel,1,kernel_size=(1,1))
self.softmax=nn.Softmax(1)
self.ch_wz=nn.Conv2d(channel//2,channel,kernel_size=(1,1))
self.ln=nn.LayerNorm(channel)
self.sigmoid=nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.size()
#Channel-only Self-Attention
channel_wv=self.ch_wv(x) #bs,c//2,h,w
channel_wq=self.ch_wq(x) #bs,1,h,w
channel_wv=channel_wv.reshape(b,c//2,-1) #bs,c//2,h*w
channel_wq=channel_wq.reshape(b,-1,1) #bs,h*w,1
channel_wq=self.softmax(channel_wq)
channel_wz=torch.matmul(channel_wv,channel_wq).unsqueeze(-1) #bs,c//2,1,1
channel_weight=self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b,c,1).permute(0,2,1))).permute(0,2,1).reshape(b,c,1,1) #bs,c,1,1
channel_out=channel_weight*x
return channel_out
Spatial-only branch
与Channel-only branch相似,作者先用了1x1的卷积将输入的特征转换为了Q和V,其中,对于Q特征,作者还用了GlobalPooling对空间维度压缩,转换成了1x1的大小;而V特征的空间维度则保持在一个比较大的水平(HxW)。由于Q的空间维度被压缩了,所以作者就用了Softmax对Q的信息进行增强。然后将Q和K进行矩阵乘法,然后接上reshape和Sigmoid使得所有的参数都保持在0-1之间
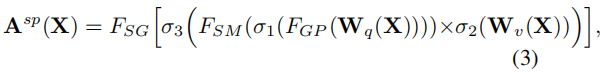
class Spatial_only_branch(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sigmoid=nn.Sigmoid()
self.sp_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.sp_wq=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.agp=nn.AdaptiveAvgPool2d((1,1))
def forward(self, x):
b, c, h, w = x.size()
#Spatial-only Self-Attention
spatial_wv=self.sp_wv(x) #bs,c//2,h,w
spatial_wq=self.sp_wq(x) #bs,c//2,h,w
spatial_wq=self.agp(spatial_wq) #bs,c//2,1,1
spatial_wv=spatial_wv.reshape(b,c//2,-1) #bs,c//2,h*w
spatial_wq=spatial_wq.permute(0,2,3,1).reshape(b,1,c//2) #bs,1,c//2
spatial_wz=torch.matmul(spatial_wq,spatial_wv) #bs,1,h*w
spatial_weight=self.sigmoid(spatial_wz.reshape(b,1,h,w)) #bs,1,h,w
spatial_out=spatial_weight*x
return out
Bottom-up
OpenPose
2017? Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
? code
自顶向下的单人pose估计,当人的检测器失败后,无法做下一步了,另外时间复杂度会随着人数的增加而增加。因此自底向上的方法能够解耦这样问题
首先由主干网络VGG19提取图片的特征,然后进入到stage模块,stage是一些串行的模块,每个模块的结构和功能都是一样的。分成两个branch,一个branch生成pcm,一个branch生成paf。并且每个stage的pcm和paf都会进行loss求解。最后总的loss是所有loss的和
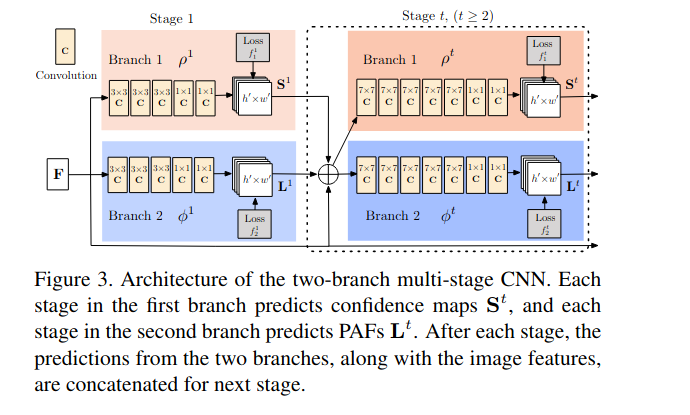
PCM, part confidence map。用来表征关键点的位置(就是热力图)。假设需要输出18个人体关键点信息,那么PCM会输出19个通道,最后一个通道作为背景。理论上不输出背景也没有什么关系,但是输出背景有两个好处,一是增加了一个监督信息,有利于网络的学习,二是背景输出继续作为下一个stage的输入,有利于下一个stage获得更好的语义信息
PAF, Part Affinity Fields for Part Association。在得到关键点的位置之后如何进行匹配是关键。PAF就是将属于同一个人的不同关键点按顺序拼接,而且是有方向的,重点是这个方向!!!手腕的点会与所有的手臂连接,但是要找到最适合属于同一个人的,就是PAF做的事
-
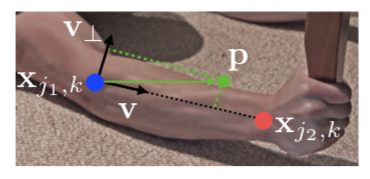
通过上图的的例子来分析这部分的内容, \(x_{j1,k}\) 和 \(x_{j1,k}\), k分别代表 K的肢体 c 两个对应的身体部位$j_{1} \(和 j_{2} 的GT位置,如果点 p 落在了肢体 c上,\) L_{c, k}^{*}({p})$ 的值为 \(j_{1}\) 指向 \(j_{2}\) 的单位向量,不在这个肢体上的点值为0;
-
为了在训练阶段评估 \(f_{L}\) 定义PAF在点p的GT值为
\(\mathbf{L}_{c,k}^*(\mathbf{p})=\left\{\begin{array}{ll}\mathbf{v}&\text{ if }\mathbf{p}\text{ on limb }c,k\\\mathbf{0}&\mathrm{~otherwise}\end{array}\right.\), 其中v= \(\left(\mathbf{x}_{j_2,k}-\mathbf{x}_{j_1,k}\right)/\left\|\mathbf{x}_{j_2,k}-\mathbf{x}_{j_1,k}\right\|_2\) 代表肢体方向的单位向量 -
在\(0\leq\mathbf{v}\cdot\left(\mathbf{p}-\mathbf{x}_{j_{1},k}\right)\leq l_{c,k}\mathrm{and}\left|\mathbf{v}_{\perp}\cdot\left(\mathbf{p}-\mathbf{x}_{j_{1},k}\right)\right|\leq\sigma_{l}\)范围内的点 p被定义为在肢体 c上, 其中 \(\sigma_{l}\)代表肢体的宽度, \(l_{c,k} = \left\|\mathbf{x}_{j_2,k}-\mathbf{x}_{j_1,k}\right\|_2\)代表肢体的长度
-
点 p的部分亲和力场GT值为所有人在此点上PAF平均值:\(\mathbf{L}_c^*\left(\mathbf{p}\right)=\frac1{n_c\left(\mathbf{p}\right)}\sum_k\mathbf{L}_{c,k}^*\left(\mathbf{p}\right)\), 其中 \(n_{c}(p)\)代表非零向量的个数
-
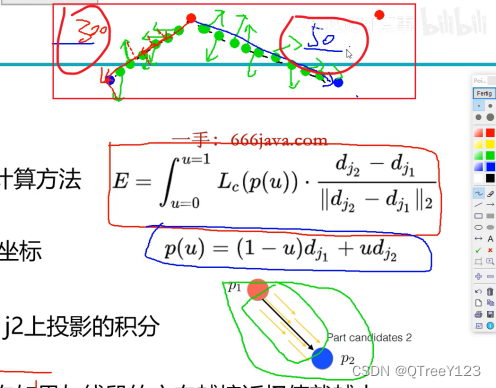
在预测阶段,对于两个候选的部位点 \(d_{j1}\)和 \(d_{j2}\),我们沿着线段采样预测得到的PAF \(L_{c}\),以测量两个部分之间的关联置信度, $ E=\int_{u=0}^{u=1} \mathbf{L}{c}(\mathbf{p}(u)) \cdot \frac{\mathbf{d}{j_{2}}-\mathbf{d}{j{1}}}{\left|\mathbf{d}{j{2}}-\mathbf{d}{j{1}}\right|{2}} du $, 其中 $ p(u)$ 代表两个身体部位之间的位置: $\mathbf{p}(u)=(1-u) \mathbf{d}{j_{1}}+u \mathbf{d}{j{2}} $,实际预测时对u区间进行均匀间隔采样求和来求解近似的积分值
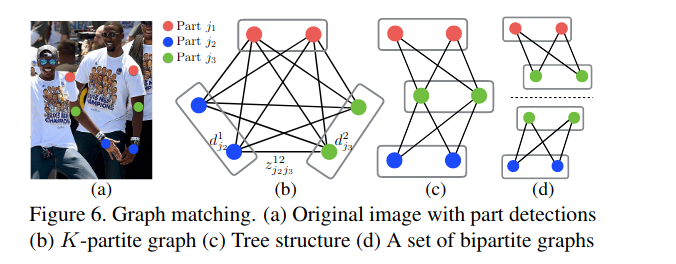
如下图所示,如何找到白色衣服肩膀上的点到所有粉色点的连接是PAF的关键

标签制作, 这个匹配与向量大小无关,仅更方向有关,所以在打标签的时候,都是做成了单位向量,它只有方向没有大小。标签定义,两条垂线是有阈值的,然后做出矩形,但凡落到矩形中的,那就是跟v是同一个方向的,只保留掉落在矩形面积中的点,其他点全部去掉。

得到PFA的标签后(包括所有人该连接处的向量),开始计算方向相同的值,下图的上方是各种打乱的方向,他们是预测值,调整预测值的方向相同的值,而右下角是标注的图,是同一个方向的。再看看下图的上方,明显右边计算出来的积分(投影的思想)更大也就是权重更大,所以选择这个方向
匈牙利匹配,

HigherHRNet
2020? HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
? code
Higher-Resolution Network
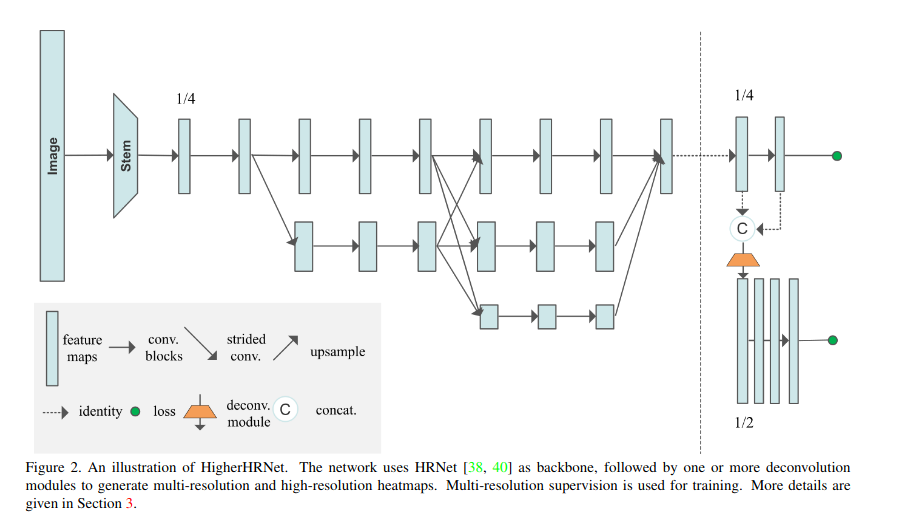
作者在HRNet中的最高分辨率特征图的基础上,添加了一个反卷积模块。反卷积模块将HRNet的特征和预测热图作为输入,生成分辨率比输入特征图高2倍的新特征图。利用反卷积模块和HRNet的特征图生成了具有两种分辨率的特征金字塔。反卷积模块还通过增加1×1卷积来预测热图
Grouping
- 使用关联嵌入associative embedding的简单方法可以高精度地解决分组问题
- 使用关联嵌入进行关键点分组。分组过程通过对tags具有较小l2距离的关键点进行分组,将无标识的关键点聚集到个体中。
Deconvolution Module
- 提出了一个简单的反卷积模块,用于生成分辨率比输入特征图高两倍的高质量特征图
- 使用4×4反卷积(转置卷积)和BatchNorm和ReLU来学习对输入特征映射进行上采样-
- HigherHRNet中添加4个剩余块
- 反卷积模块的输入是HRNet或先前的反卷积模块的特征图和预测热图的连接, 并利用各反卷积模块的输出特征图进行多尺度热图预测
Multi-Resolution Supervision
- 在 HigherHRNet 的每个预测尺度上,计算该尺度的预测热图与其相关的 ground truth 热图间的均方误差,最终热图损失是所有分辨率均方误差之和。
Heatmap Aggregation for Inference
- 使用双线性插值将所有具有不同分辨率的预测热图上采样到输入图像的分辨率,并平均所有尺度的热图进行最终预测。这种策略与先前仅使用单尺度或单阶段的热图进行预测的方法大为不同。
热图聚合能让姿态估计感知尺度。 例如,COCO关键点数据集包含了从 3 2 2 32^2 322 像素到超过 12 8 2 128^2 1282 像素的大尺度差异人体。Top-down 法通过将人的区域近似 normalizing 为同一尺度来解决此问题。但 Bottom-up 法需要感知尺度来从所有尺度中检测关键点。