先是对Series来说
import numpy as np
import pandas as pd
# 两层索引对于Series对象来说,没有columns
sum_series=pd.Series([15848,13472,12073.8,7813,7446,6444,15230,8269],index=[
['河北省','河北省','河北省','河北省',
'河南省','河南省','河南省','河南省'],
['石家庄市','唐山市','邯郸市','秦皇岛市',
'郑州市','开封市','洛阳市','新乡市']])
print(sum_series)
# 多层索引
sum_series=pd.Series([15848,13472,12073.8,7813,7446,6444,15230,8269],index=[
['河北省','河北省','河北省','河北省',
'河南省','河南省','河南省','河南省'],
['石家庄市','唐山市','邯郸市','秦皇岛市',
'郑州市','开封市','洛阳市','新乡市']])
print(sum_series)
# ---------------------------下面是输出结果------------------------------
河北省 石家庄市 15848.0
唐山市 13472.0
邯郸市 12073.8
秦皇岛市 7813.0
河南省 郑州市 7446.0
开封市 6444.0
洛阳市 15230.0
新乡市 8269.0
dtype: float64
--------------------------------------------
河北省 石家庄市 15848.0
唐山市 13472.0
邯郸市 12073.8
秦皇岛市 7813.0
河南省 郑州市 7446.0
开封市 6444.0
洛阳市 15230.0
新乡市 8269.0
dtype: float64
对DataFrame来说
# 对于DataFrame对象来说(可以增加列索引)
sum_df=pd.DataFrame([15848,13472,12073.8,7813,7446,6444,15230,8269],index=[
['河北省','河北省','河北省','河北省',
'河南省','河南省','河南省','河南省'],
['石家庄市','唐山市','邯郸市','秦皇岛市',
'郑州市','开封市','洛阳市','新乡市']],
columns=["占地面积"])
print(sum_df)
# ---------------------------下面是输出结果-----------------------------
占地面积
河北省 石家庄市 15848.0
唐山市 13472.0
邯郸市 12073.8
秦皇岛市 7813.0
河南省 郑州市 7446.0
开封市 6444.0
洛阳市 15230.0
新乡市 8269.0
MultiIndex方法
from_tuples
# MultiIndex.from_tuples():将元组列表转换为MultiIndex
# MultiIndex.from_arrays():将数组列标转换为MultiIndex
# MultiIndex.from_product():从多个集合的笛卡尔乘积中创建一个MultiIndex
# 使用上面的任意一种方法,都可以返回一个MultiIndex类对象,里面有三个重要的属性,分别是levels,labels,names
# levels表示每个级别的唯一标签
# labels表示每一个索引列中每个元素在levels中对应的第几个元素
# names表示可以设置索引等级名称
# 通过from_tuples()方法创建MultiIndex对象
from pandas import MultiIndex
# 创建包含多个元组的列表
list_tuples=[('A','A1'),('A','A2'),('B','B1'),('B','B2'),('B','B3')]
# 根据元组列表创建一个MultiIndex对象(元组的第一个元素是外层索引,第二个元素是内层索引)
multi_index=MultiIndex.from_tuples(list_tuples,names=['外层索引','内层索引'])
multi_index
# -------------------------------- 输出结果为-------------------------------
MultiIndex([('A', 'A1'),
('A', 'A2'),
('B', 'B1'),
('B', 'B2'),
('B', 'B3')],
names=['外层索引', '内层索引'])
# 接下来创建一个DataFrame对象,把刚刚的multi_index传给index
import pandas as pd
values=[[1,2,3],[5,2,3],[2,5,6],[7,8,9],[3,6,7]]
de_index=pd.DataFrame(data=values,index=multi_index)
de_index
#-------------------------------输出结果为--------------------------------
0 1 2
外层索引 内层索引
A A1 1 2 3
A2 5 2 3
B B1 2 5 6
B2 7 8 9
B3 3 6 7
from_arrays
# 通过from_arrays()创建MultiIndex对象(数组的第一列和第二列元素个数一定要相等,不然会报错)
from pandas import MultiIndex
# 根据列表去创建一个MultiIndex对象(用二维数组来进行)
multi_array=MultiIndex.from_arrays([['A','B','A','B','B'],
['A1','A2','B1','B2','B3']],
names=['外层索引','内层索引'])
multi_array
# ------------------------------------输出结果为-----------------------------------
MultiIndex([('A', 'A1'),
('B', 'A2'),
('A', 'B1'),
('B', 'B2'),
('B', 'B3')],
names=['外层索引', '内层索引'])
# 接下来创建一个DataFrane对象
import pandas as pd
# 如果外层索引是两个连续的值,那么会进行约简
df_array=pd.DataFrame([[1,2,3],[5,2,3],[2,5,6],[7,8,9],[3,6,7]],index=multi_array)
df_array
# ---------------------------------输出结果为-----------------------------------
0 1 2
外层索引 内层索引
A A1 1 2 3
B A2 5 2 3
A B1 2 5 6
B B2 7 8 9
B3 3 6 7
from_product(笛卡尔积)
# 通过MultiIndex.from_product方法创建MultiIndex对象(这是将二维数组的第一列和第二列进行笛卡尔积)
from pandas import MultiIndex
multi_product=MultiIndex.from_product([['A','B'],
['A1','A2','B2','B3']],
names=['外层索引','内层索引'])
multi_product
# -----------------------------------下面是输出结果-----------------------------------
MultiIndex([('A', 'A1'),
('A', 'A2'),
('A', 'B2'),
('A', 'B3'),
('B', 'A1'),
('B', 'A2'),
('B', 'B2'),
('B', 'B3')],
names=['外层索引', '内层索引'])
import pandas as pd
# 创建一个DataFrame对象
df_product=pd.DataFrame([[1,2,3],[5,2,3],[2,5,6],[7,8,9],[3,6,7],[3,2,4],[4,5,6],[7,3,9]],index=multi_product)
df_product
# --------------------------------------下面是输出结果--------------------------------------
0 1 2
外层索引 内层索引
A A1 1 2 3
A2 5 2 3
B2 2 5 6
B3 7 8 9
B A1 3 6 7
A2 3 2 4
B2 4 5 6
B3 7 3 9
根据表格进行层次化索引操作
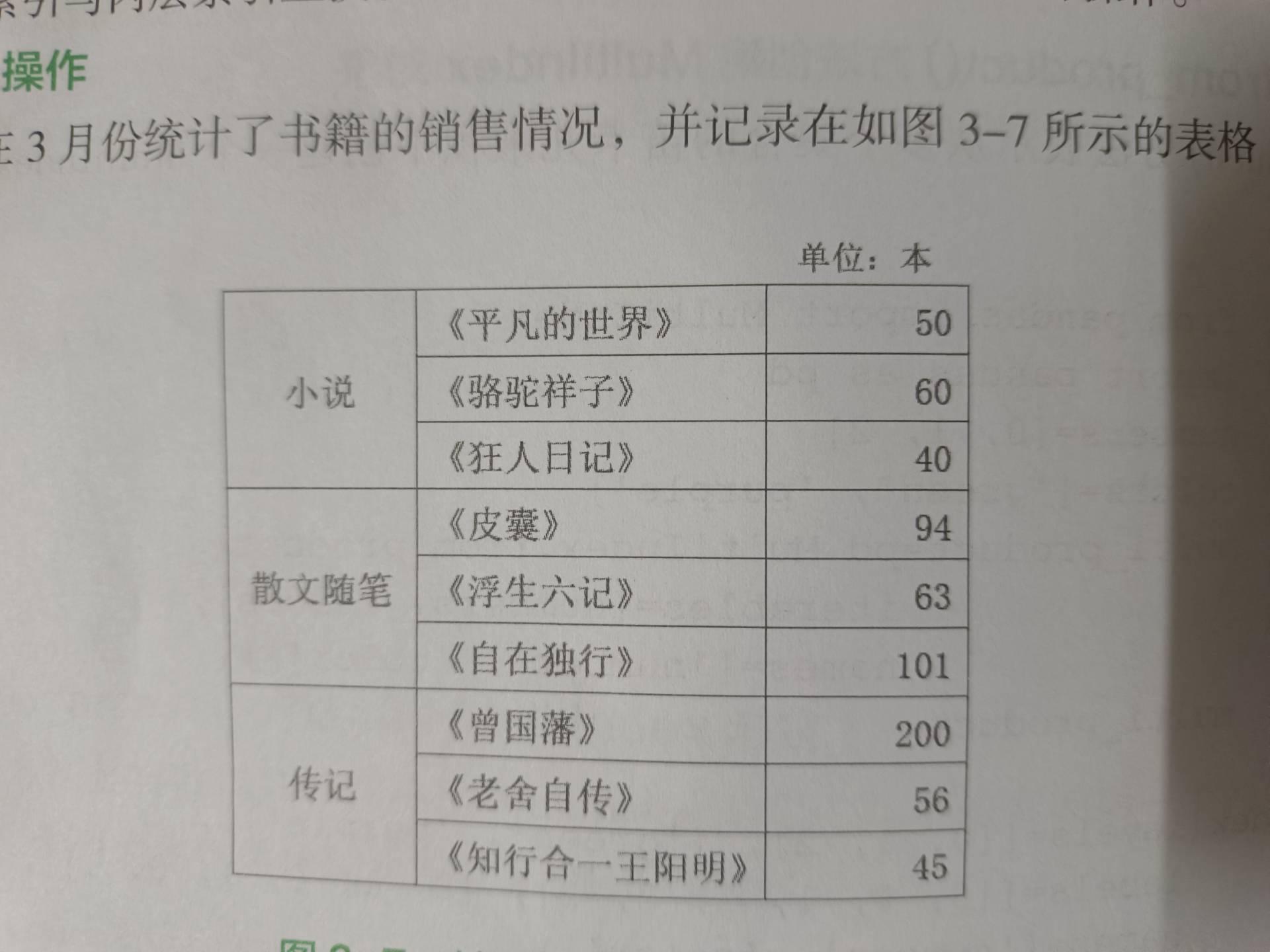
from pandas import Series
# 索引相当于是二维数组,第一列是外层索引(相同的会不显示),第二列相当于是内层索引,data就是数据
book=pd.Series([50,60,40,94,63,101,200,56,45],index=[['小说','小说','小说',
'散文随笔','散文随笔','散文随笔',
'传记','传记','传记'],
['《平凡的世界》','《骆驼祥子》','《狂人日记》',
'《皮囊》','《浮生六记》','《自在独行》',
'《曾国藩》','《老舍自传》','《知行合一王阳明》']])
print(book)
# 获取内层索引对应的子集(内层索引相当于是列名)
book[:,'《自在独行》']
#-----------------------------------下面是输出结果----------------------------------------
小说 《平凡的世界》 50
《骆驼祥子》 60
《狂人日记》 40
散文随笔 《皮囊》 94
《浮生六记》 63
《自在独行》 101
传记 《曾国藩》 200
《老舍自传》 56
《知行合一王阳明》 45
dtype: int64
------------------------------------------------
散文随笔 101
dtype: int64
# 交换分层顺序的操作可以用swaplevel()方法来进行
book.swaplevel()
#-----------------------------------下面是输出结果-----------------------------------
《平凡的世界》 小说 50
《骆驼祥子》 小说 60
《狂人日记》 小说 40
《皮囊》 散文随笔 94
《浮生六记》 散文随笔 63
《自在独行》 散文随笔 101
《曾国藩》 传记 200
《老舍自传》 传记 56
《知行合一王阳明》 传记 45
dtype: int64
分层排序
#sort_index(axis=0,level=None,ascending=True,inplace=False,kind='quicksort',na_position='last',sort_remaining=True,by=None)
from pandas import DataFrame
# 构造对象并进行实例化操作
data=pd.DataFrame({'word':['a','b','c','d','e','f','g','h','i'],'num':[1,2,3,4,5,6,7,8,9]},
index=[['A','A','A','B','B','B','C','C','C'],[1,2,3,3,2,1,2,1,3]])
print(data)
# 进行排序
print(data.sort_index())
#--------------------------------------下面是输出结果----------------------------------------
word num
A 1 a 1
2 b 2
3 c 3
B 3 d 4
2 e 5
1 f 6
C 2 g 7
1 h 8
3 i 9
word num
A 1 a 1
2 b 2
3 c 3
B 1 f 6
2 e 5
3 d 4
C 1 h 8
2 g 7
3 i 9
按num列进行降序排列,data.sort_index(by=['num'],ascending = False)