作业1:
·要求:
·熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
·使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
·候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
·输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
·Gitee文件夹链接:https://gitee.com/lian111111/crawl_project/tree/master/数据采集与融合技术第四次作业/作业4.1
代码如下:
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException, NoSuchElementException
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from sqlalchemy import create_engine
import mysql.connector
import time
# MySQL连接配置
config = {
'host': 'localhost',
'user': 'root',
'password': 'xck030312',
'database': 'stock'
}
# 创建或更新数据表
def setup_database(engine):
with engine.connect() as conn:
conn.execute(
"""CREATE TABLE IF NOT EXISTS stock3s (
id INT AUTO_INCREMENT PRIMARY KEY,
serial_number INT,
code VARCHAR(10),
name VARCHAR(255),
latest_price DECIMAL(10, 2),
change_percentage VARCHAR(10),
change_amount DECIMAL(10, 2),
trade_volume VARCHAR(20),
trade_value VARCHAR(20),
amplitude VARCHAR(10),
highest_price DECIMAL(10, 2),
lowest_price DECIMAL(10, 2),
opening_price DECIMAL(10, 2),
closing_price DECIMAL(10, 2),
volume_ratio DECIMAL(10, 2),
turnover_rate VARCHAR(10),
pe_ratio DECIMAL(10, 2),
pb_ratio DECIMAL(10, 2)
)"""
)
# 清理并转换数值
# 省略clean_value函数,与原始代码相同
# 爬取并存储数据
def scrape_and_store(url, page_limit=None):
# 启动Edge浏览器
driver = webdriver.Edge()
driver.get(url)
engine = create_engine(f"mysql+mysqlconnector://{config['user']}:{config['password']}@{config['host']}/{config['database']}")
setup_database(engine)
page_scraped = 0
while True:
try:
table = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'table'))
)
df = pd.read_html(table.get_attribute('outerHTML'))[0]
df = df.applymap(clean_value) # 应用清理函数
df.to_sql('stock3s', con=engine, if_exists='append', index=False)
page_scraped += 1
if page_limit is not None and page_scraped >= page_limit:
break
next_button = driver.find_element(By.CSS_SELECTOR, 'a.next.paginate_button')
if 'disabled' in next_button.get_attribute('class'):
break
next_button.click()
time.sleep(2)
except (TimeoutException, NoSuchElementException) as e:
print(f"An error occurred: {e}")
break
driver.quit()
# 爬取三个板块的数据
urls = [
'http://quote.eastmoney.com/center/gridlist.html#hs_a_board',
# ... 其他URL
]
for url in urls:
scrape_and_store(url, page_limit=100)
结果如下图:

心得体会:
翻页功能的实现主要是查找“next”按钮,并模拟点击进行刷新数据
之前的爬取json数据使用的是sqlite,这次采用了mysql,重构了代码较为顺利
作业2
·要求:
·熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
·输出信息:MYSQL数据库存储和输出格式
·Gitee文件夹链接:https://gitee.com/lian111111/crawl_project/tree/master/数据采集与融合技术第四次作业/作业4.2
代码如下:
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from scrapy.selector import Selector
import mysql.connector
from sqlalchemy import create_engine
# 数据库配置
config = {
'host': 'localhost',
'user': 'root',
'password': 'xck030312',
'database': 'stock'
}
def setup_database(engine):
# 使用SQLAlchemy引擎创建表
with engine.connect() as conn:
conn.execute(
"""CREATE TABLE IF NOT EXISTS mooc (
id INT AUTO_INCREMENT PRIMARY KEY,
course VARCHAR(255),
school VARCHAR(255),
teacher VARCHAR(255),
team VARCHAR(255),
number VARCHAR(255),
time VARCHAR(255),
jianjie TEXT
)"""
)
def main():
url = 'https://www.icourse163.org/'
driver = webdriver.Edge()
driver.get(url)
login(driver)
search_for_courses(driver, "java")
content = driver.page_source
driver.quit()
data = parse_content(content)
save_to_database(data)
def login(driver):
# 省略登录代码,与原始代码相同
def search_for_courses(driver, query):
# 省略搜索代码,与原始代码相同
def parse_content(content):
# 省略解析内容代码,与原始代码相同
def save_to_database(data):
# 创建数据库连接引擎
engine = create_engine(
f"mysql+mysqlconnector://{config['user']}:{config['password']}@{config['host']}/{config['database']}")
# 设置数据库
setup_database(engine)
# 创建DataFrame对象
df = pd.DataFrame(data=data, columns=['course', 'school', 'teacher', 'team', 'number', 'time', 'jianjie'])
# 使用Pandas的to_sql方法直接保存到数据库
df.to_sql('mooc', con=engine, if_exists='append', index=False)
if __name__ == "__main__":
main()
运行结果如图所示:
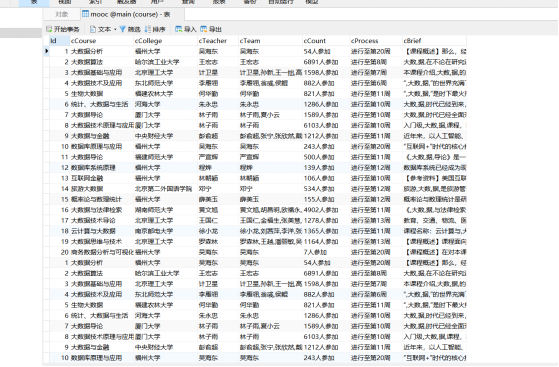
心得体会:
对Selenium有了更深的理解
作业3
·要求:
·掌握大数据相关服务,熟悉Xshell的使用
·完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
·环境搭建:开通MapReduce服务
·实时分析开发实战:
·任务一:Python脚本生成测试数据 ·任务二:配置Kafka ·任务三: 安装Flume客户端 ·任务四:配置Flume采集数据
·输出:实验关键步骤或结果截图。
过程与结果展示:
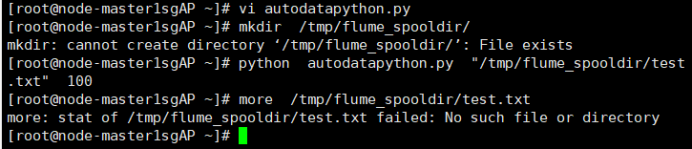
任务一:Python脚本生成测试数据

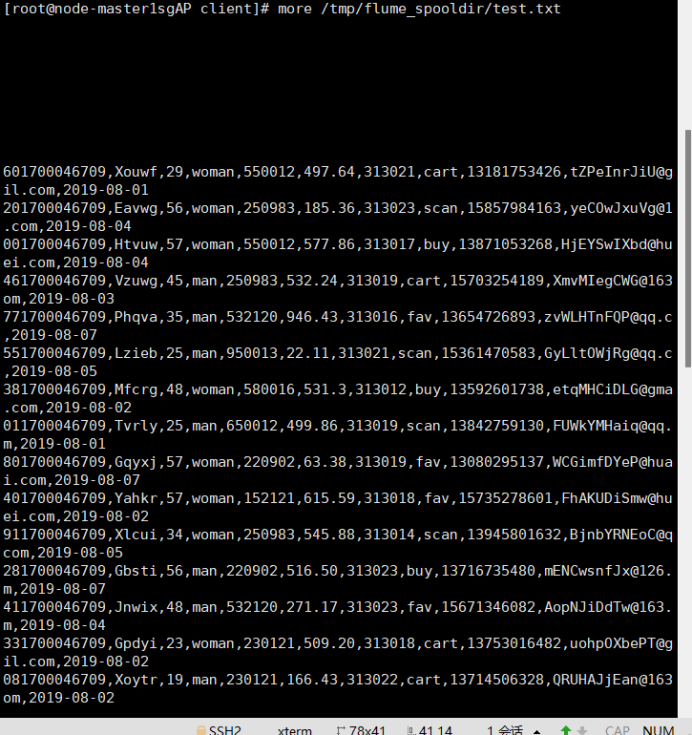
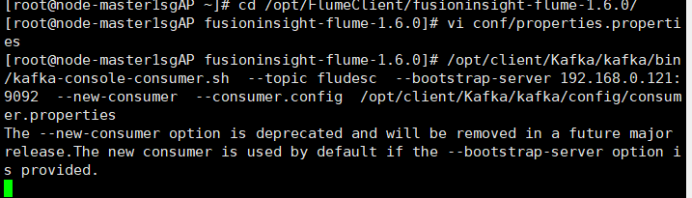
任务二:配置Kafka


任务三: 安装Flume客户端


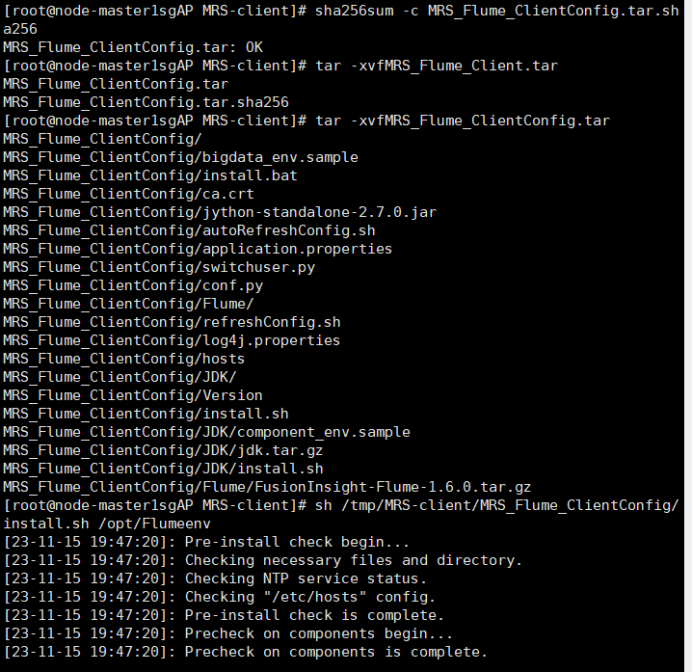
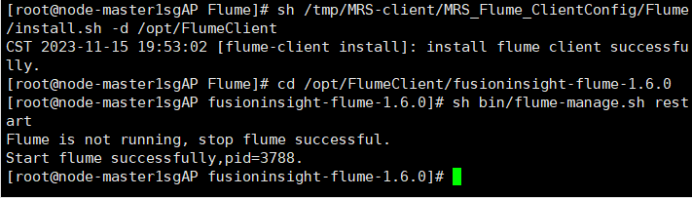
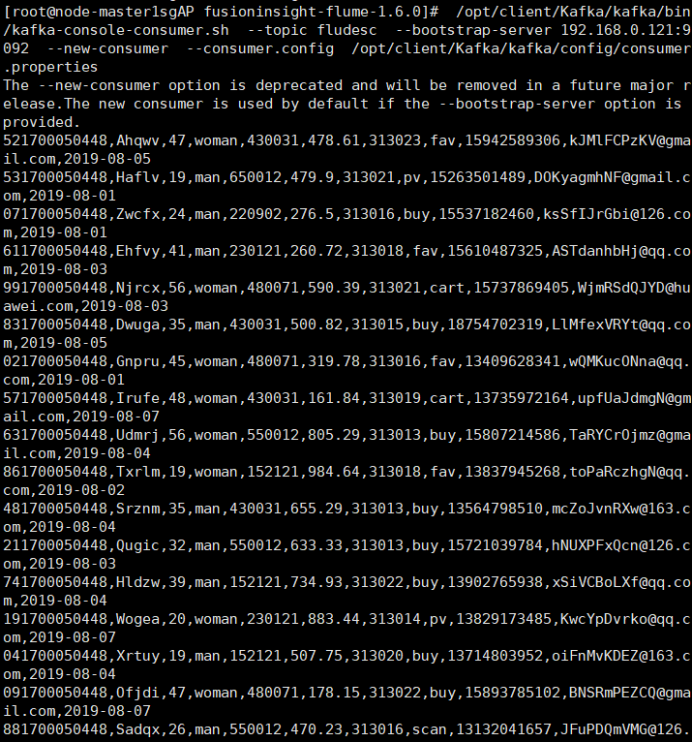
任务四:配置Flume采集数据
心得体会:
通过本次实践让我加深了对selenium爬取数据过程的知识的理解,同时紧接上次课作业对于将数据存储到数据库当中更加熟练!对华为云的相关服务有了初步认识、拓宽自己的眼界与认知!但在根据实践手册一步一步进行操作时还是有碰到些许问题,应该是自己较为粗心在配置时出现问题,今后做事应当更加注意细节。