Kernel Memory 入门系列: Embedding 简介
在 RAG模式 其实留了一个问题。
我们对于的用户问题的理解和文档的检索并没有提供合适的方法。

当然我们可以通过相对比较传统的方法。
例如对用户的问题进行关键词提取,然后通过关键词检索文档。这样的话,就需要我们提前对文档做好相关关键词的标注,同时也需要关键词能够覆盖到用户可能的提出方式以及表达方法。这样的话,就需要我们对用户的问题有一个很好的预测。用户也需要在提问的时候,能够按照我们的预期进行提问。我们和用户双向猜测,双向奔赴,如果猜对了,那么就可以得到一个比较好的结果。如果猜错了,结果难以想象。
那么有没有一种方法,能够让我们不需要对用户的问题进行预测,也不需要对文档进行关键词标注,就能够得到一个比较好的结果呢?
这个答案就是 Embedding。
Embedding 是什么
Embedding 是一种将高维数据映射到低维空间的方法。在这个低维空间中,数据的相似性和原始空间中的相似性是一致的。这样的话,我们就可以通过低维空间中的相似性来进行检索。
通俗的理解,大语言模型基于大量的文本数据进行训练,得到了一个高维的向量空间,我们可以认为这是一个语义的空间。在这个语义空间中,每一个词或者每个句子都有一个对应的空间坐标。虽然这个坐标系的维度是非常高的,起码都是上百甚至上千的维度,但是我们仍可以想象在二维或者三维空间中的点去理解这个坐标。
然后,我们就可以通过这个向量来判断两段文字是否相似。如果两段文字的向量越接近,那么这两个词的语义就越接近。例如,猫 和 狗 的向量就会比 猫 和 苹果 的向量更加接近。

这个空间坐标和模型的关系更加密切,模型越强大,对于语义的理解越深刻,那么这个空间坐标的效果就越好。所以,寻找或者训练一个好的Embedding模型对于实现一个好的检索系统是非常重要的。
使用Embedding进行匹配
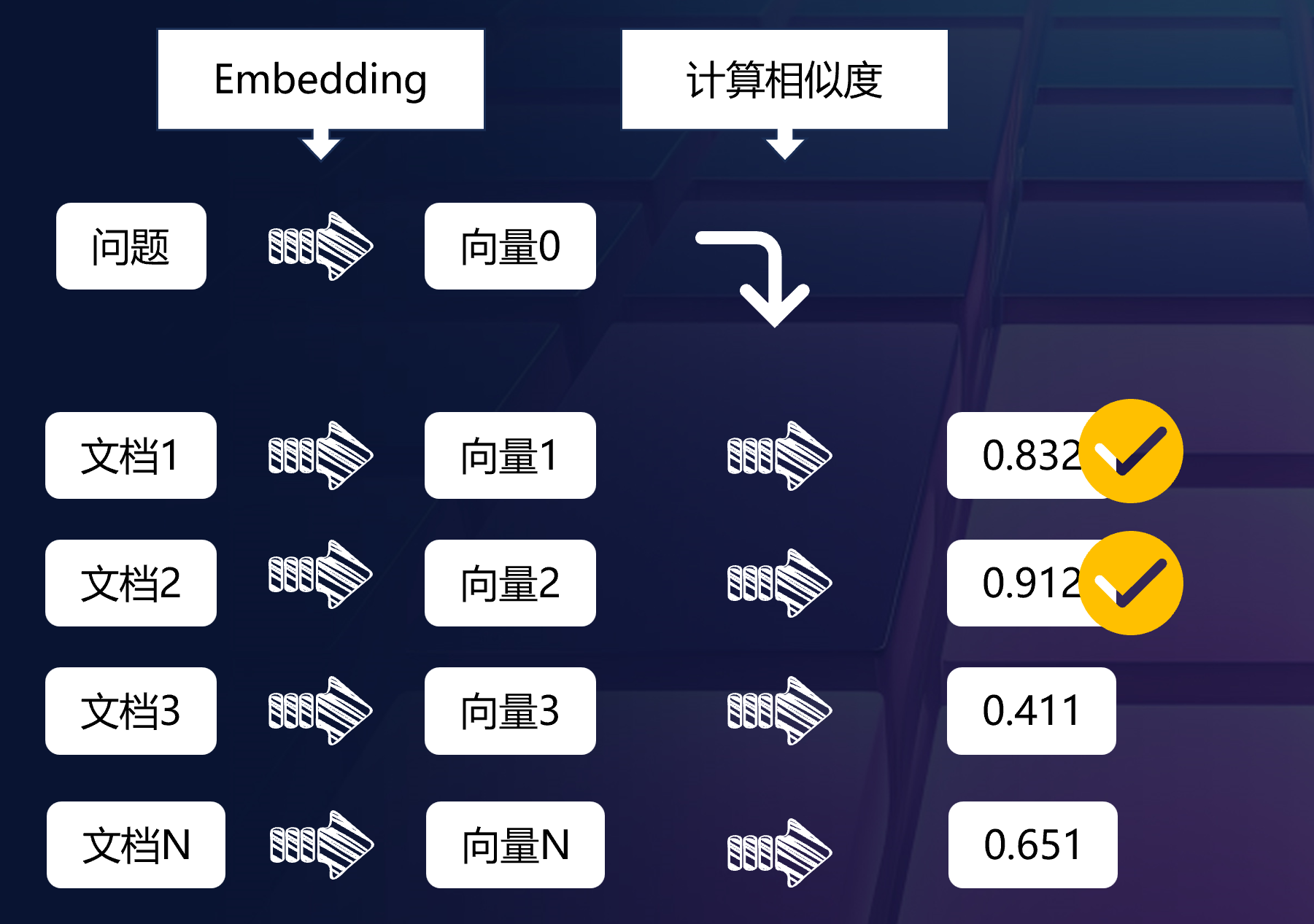
有了Embedding的结果之后,我们就可以看如何使用Embedding进行匹配了。
首先我们需要对用户的提问和我们的文本进行Embedding,得到对应的向量。
通过计算问题的向量与文本的向量的相似性,通常是余弦相似度计算,我们就可以得到一个排序的结果。这个排序的结果就是我们的检索结果。
根据实际模型的表现,选择合适的相似度阈值,然后就可以找到最为相似的内容了。