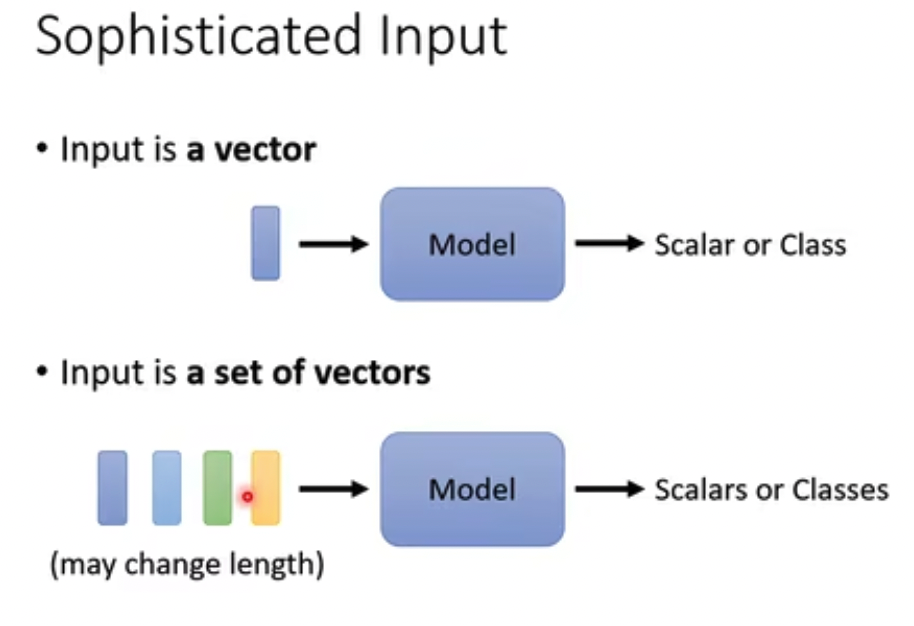
面对的问题是什么?
复杂输入,多个变长的向量
这里自然会想到RNN,后面会有比较
具体的场景,
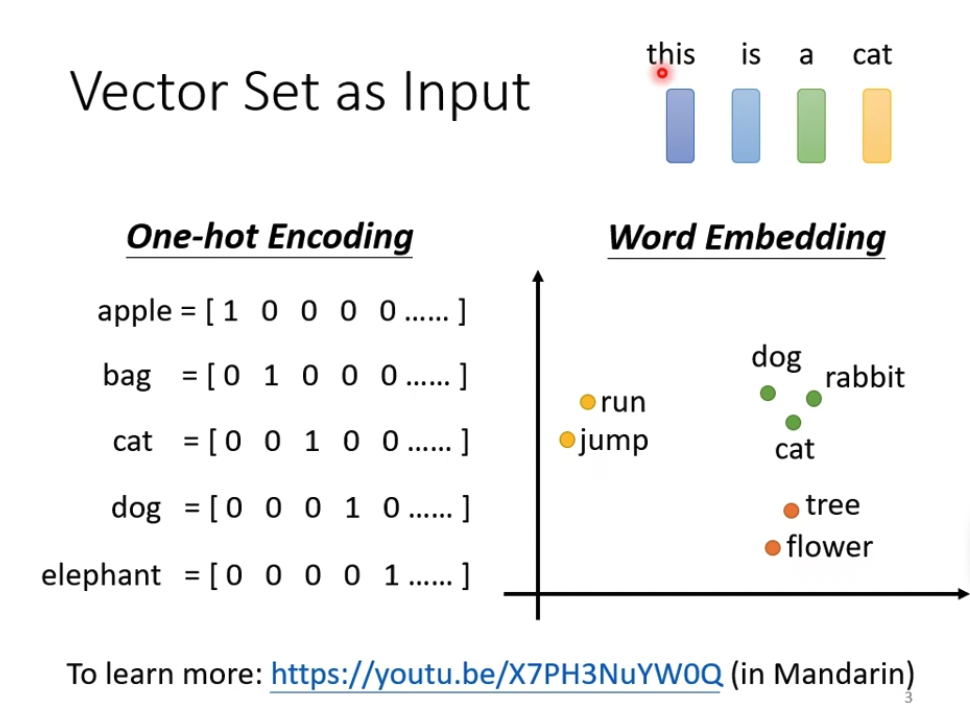
可以是一段话,每个word一个向量,可以用one hot,但大多时候是用embedding
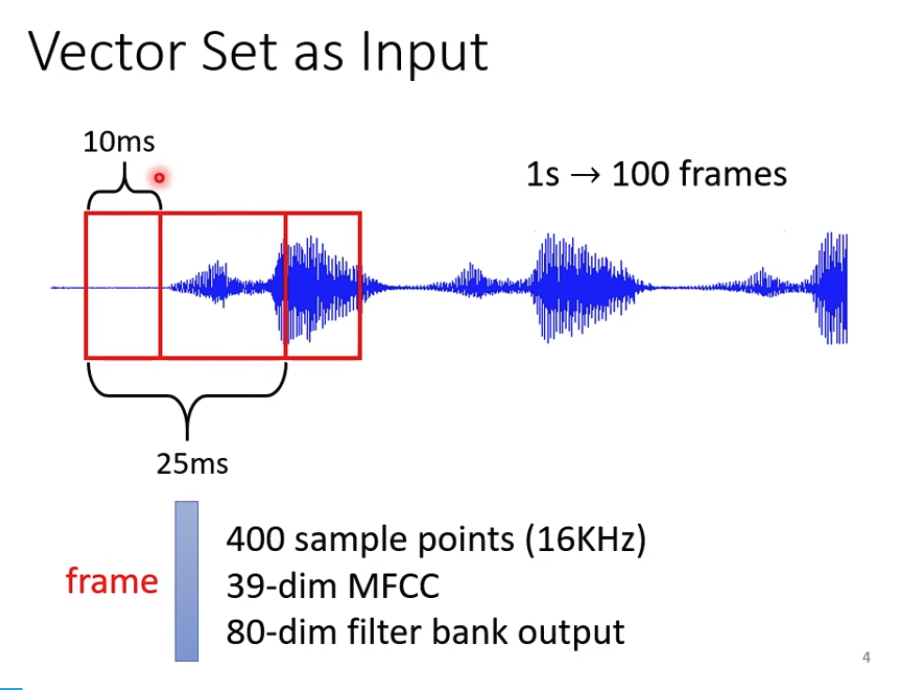
可以是一段印频,每25ms一个向量,按10ms滑动,可以看出音频的数据量是非常大的
也可以是一张图片。。。
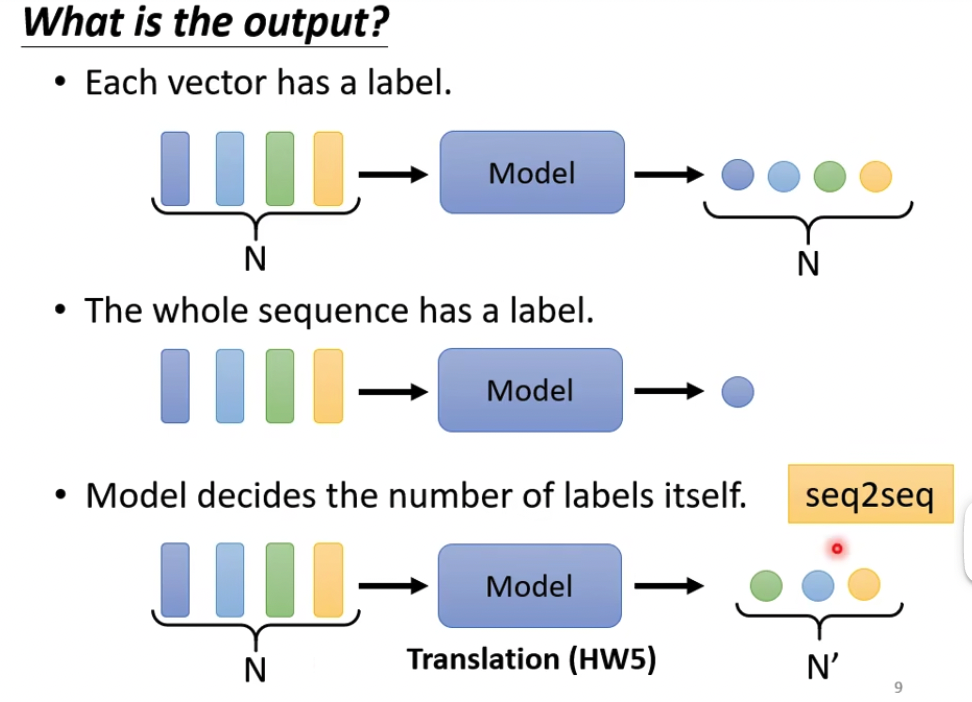
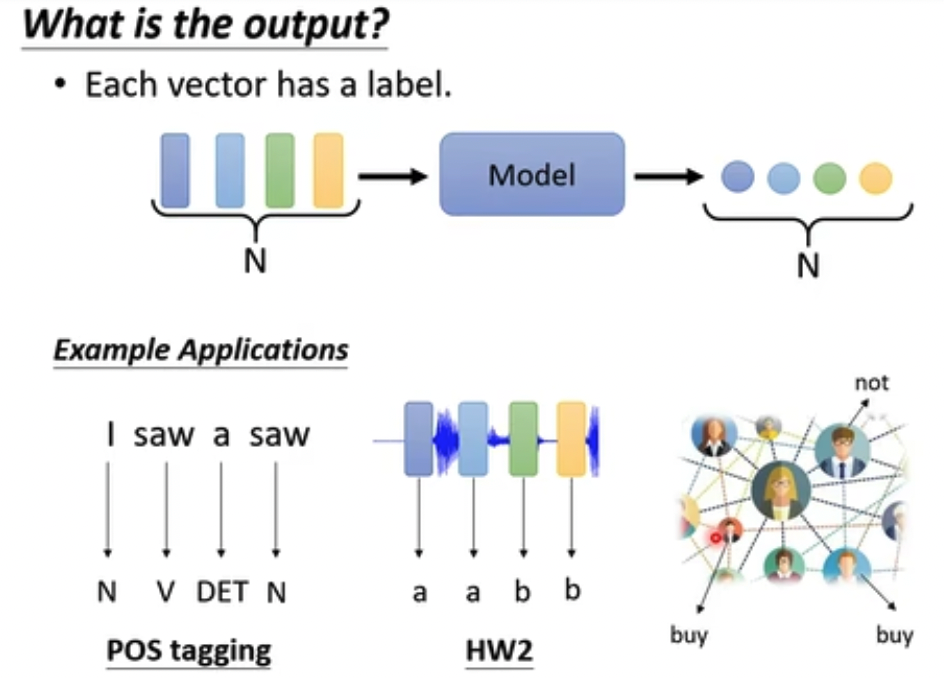
输出当然有多种形式,这个和RNN也很像
但是我们这里只讨论第一种,输入n个向量,输出n个值
这种模型有多种选择,
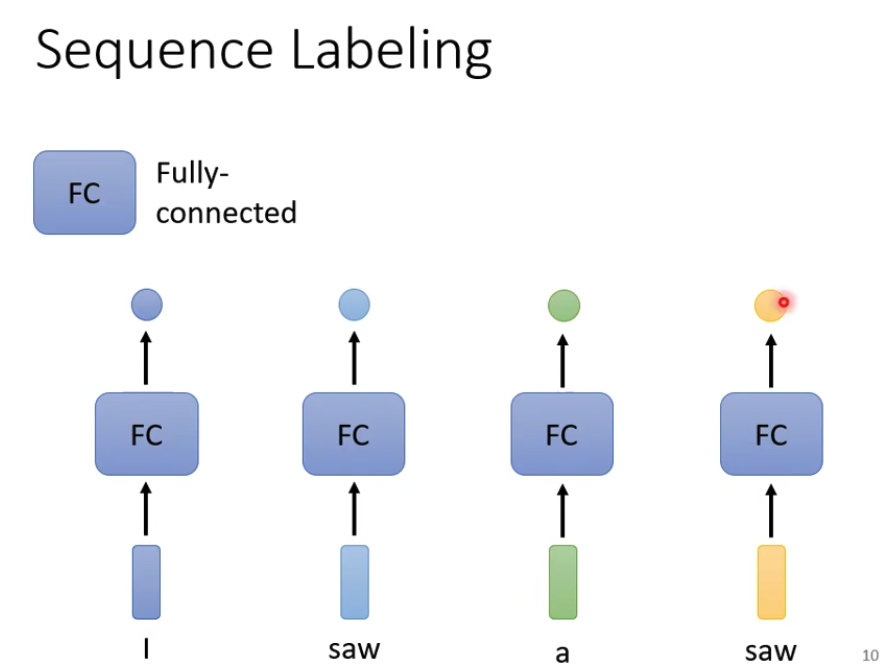
最简单的,就是每个向量经过一个FC,得到一个值就好了,问题自然是没有上下文,比如例子I saw a saw,没法区分两个saw的不同
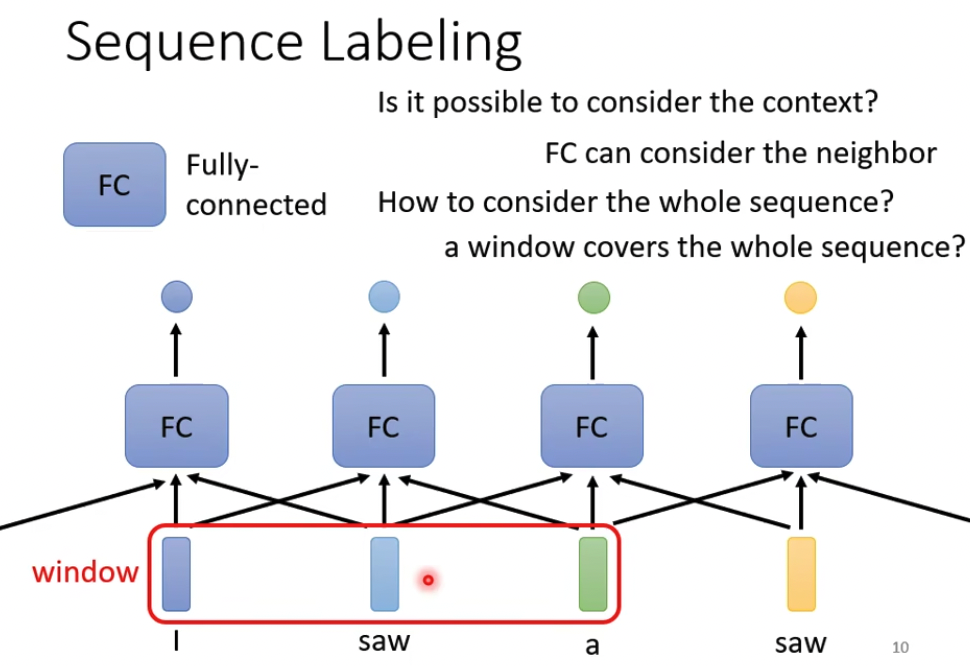
自然的改进,就是把上下文都传进FC,这里的window决定了context的大小,问题就在于window的大小如何选择
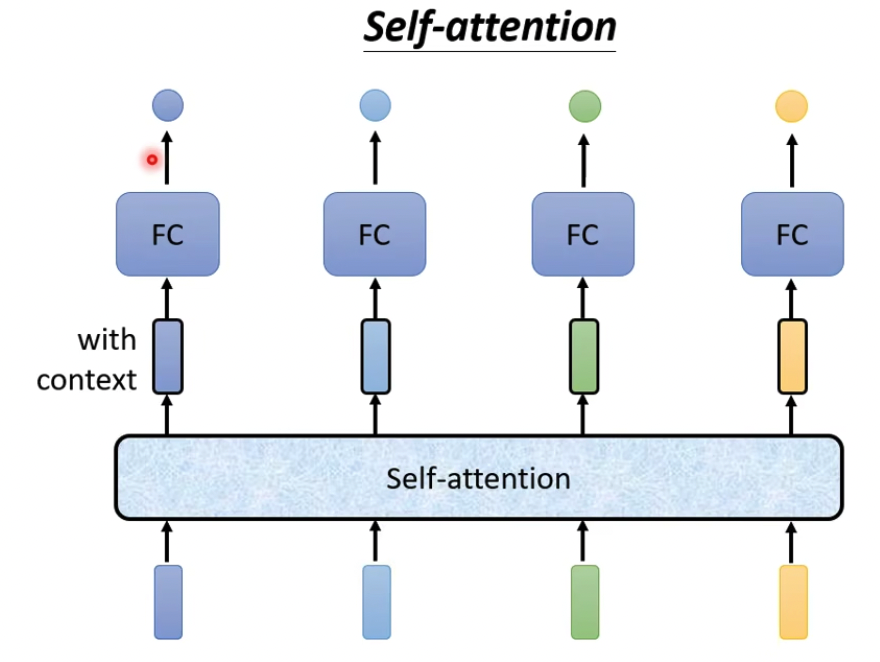
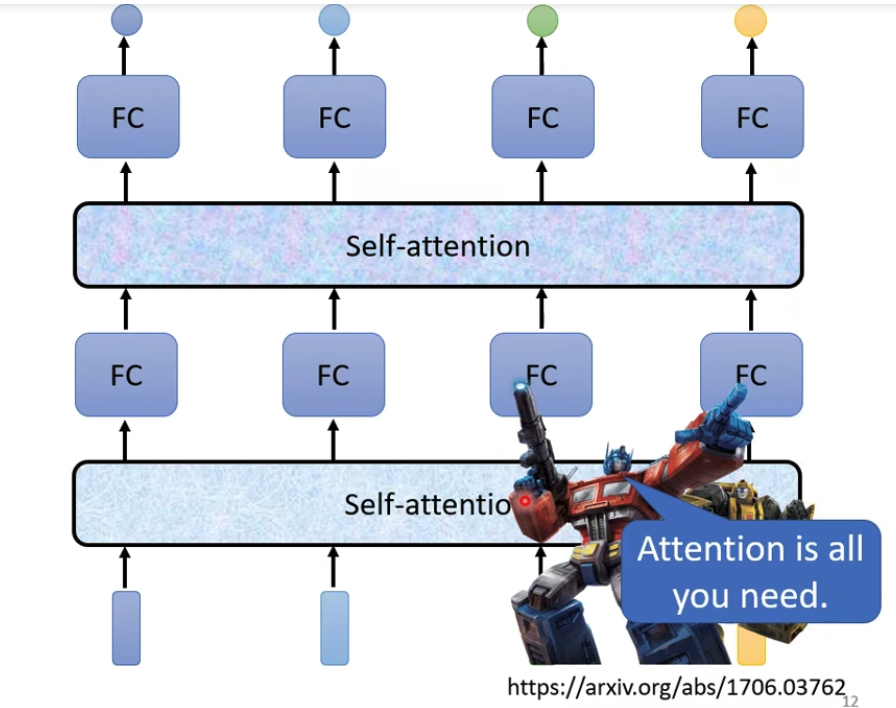
所以这里提出Self-attention模型
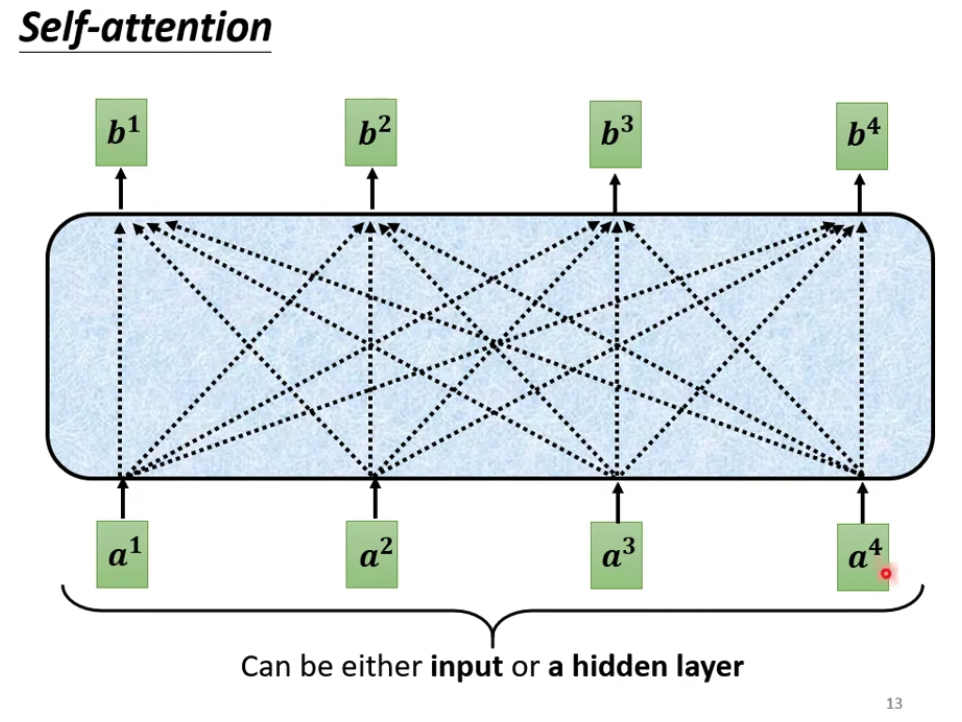
模型会对所有的向量,并给每个向量加上context,这个想法很直觉,问题是怎么做到的,参考Attention is all you need,名字霸气
注意模型是可以多层叠加的
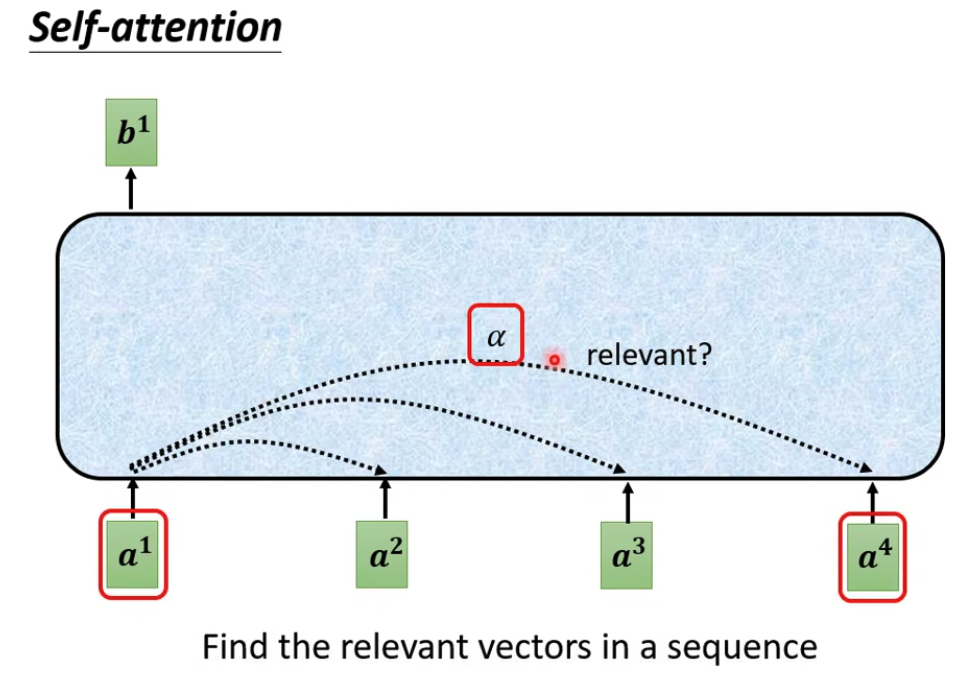
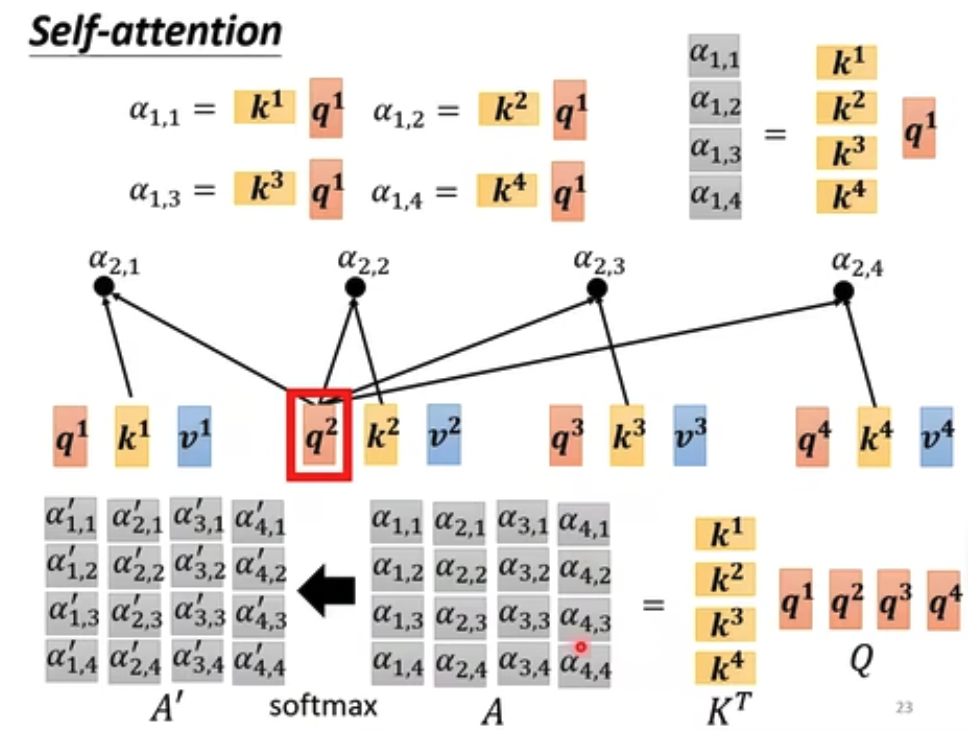
首先定义attention
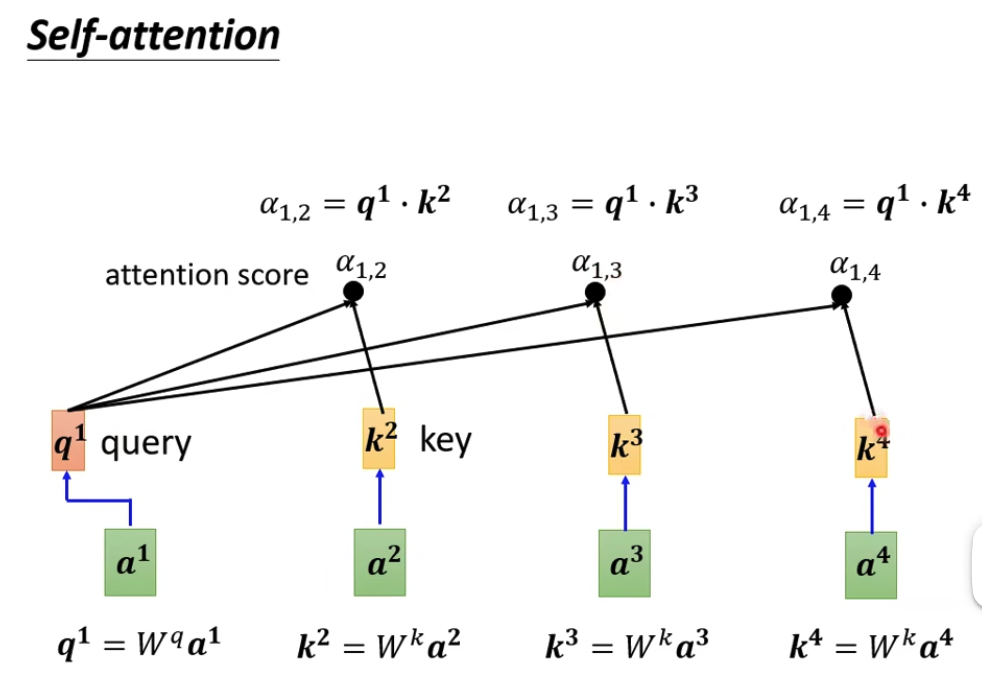
attention代表向量之间的相关性,有多种计算方法,最常用的是dot product,输入乘上参数矩阵后做点积
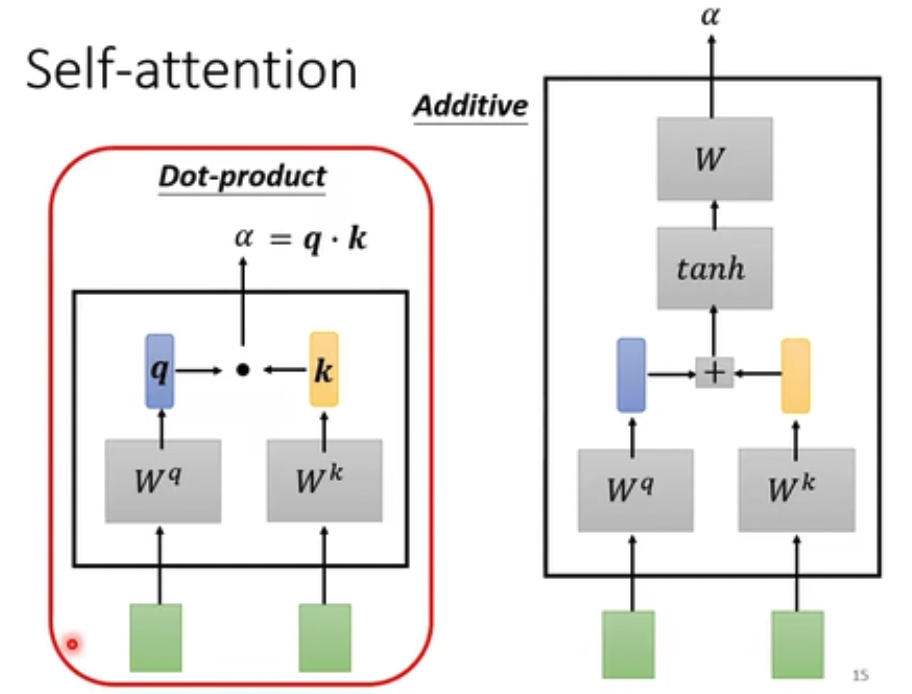
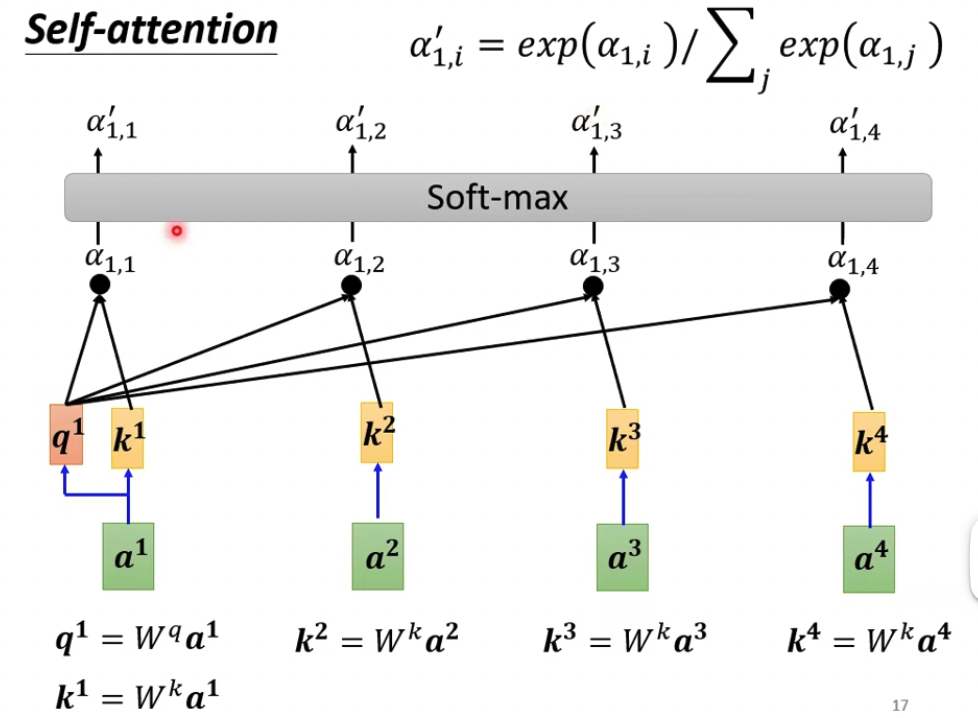
第一步,算attention score,query代表自己,key代表其他向量
第二步做归一化,soft-max是一种归一化方式,可以用其他
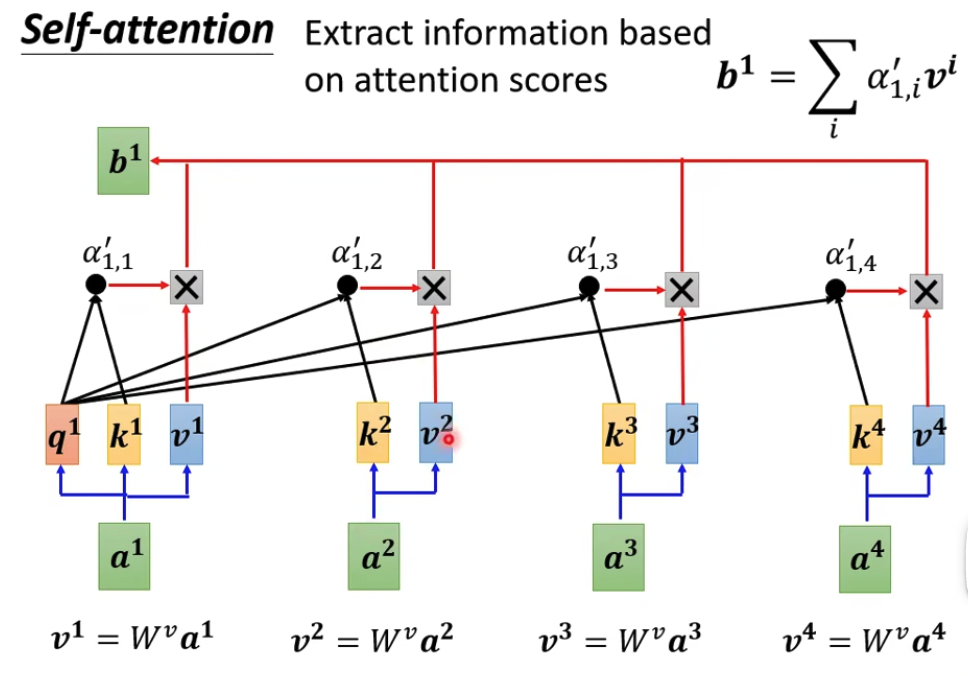
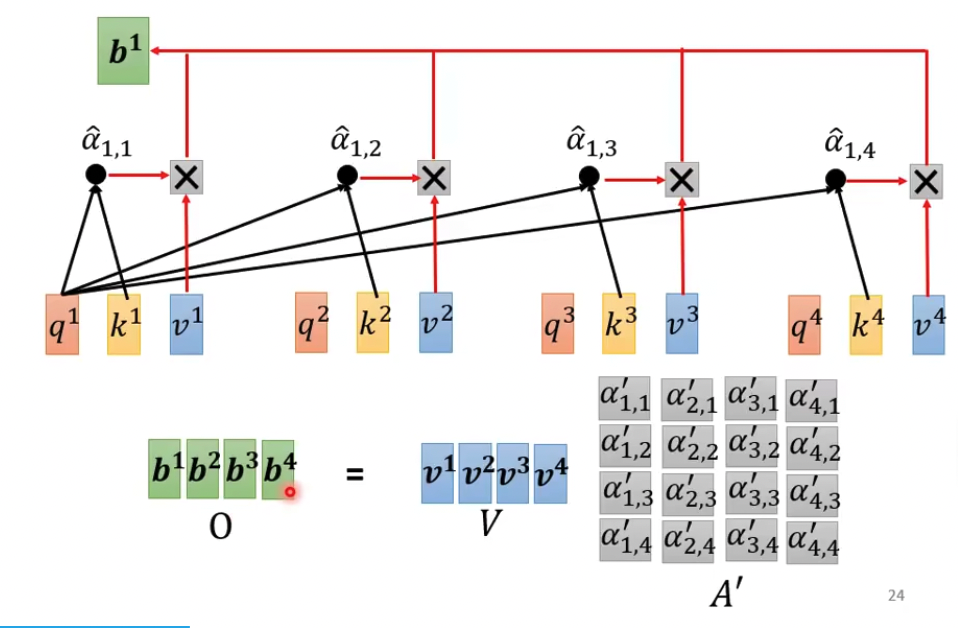
第三步根据attention值抽取各个向量信息,相关性越大attention越高,对应的向量在最终求和后的b中起的作用也越大
这样就把所有的context都融入到输入中,形成新的向量b
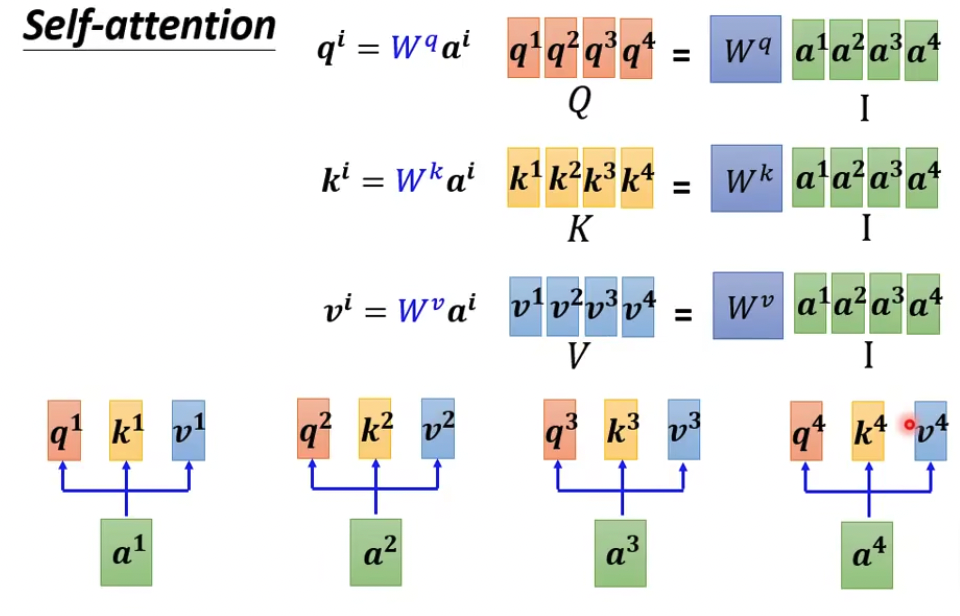
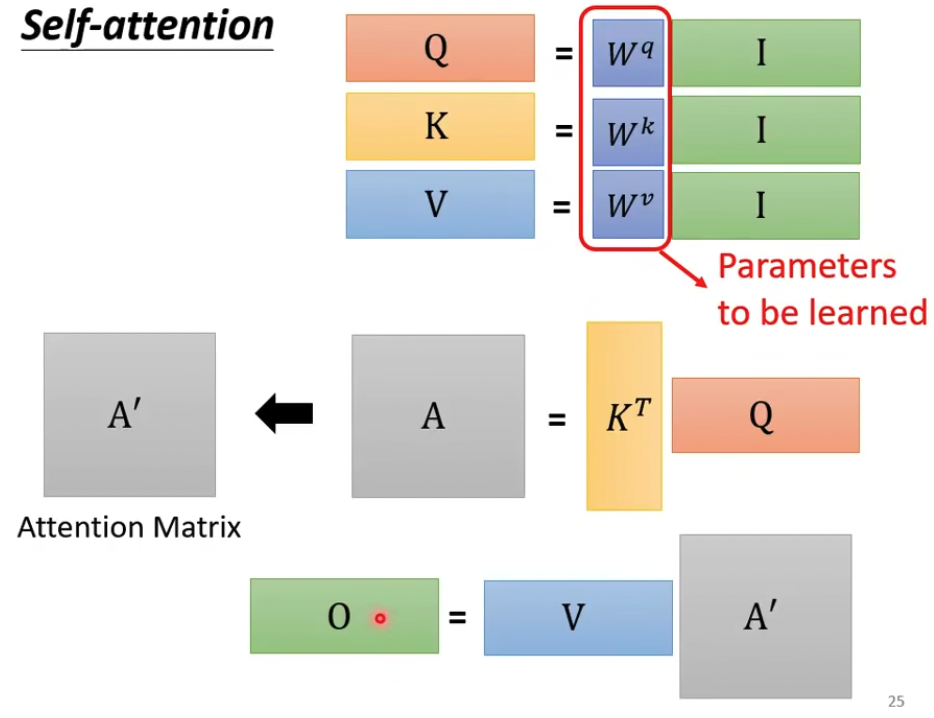
这里只是把上面的过程,变成矩阵计算
最终需要学习的参数,只有那一组W
后面看下Self-attention相关的研究
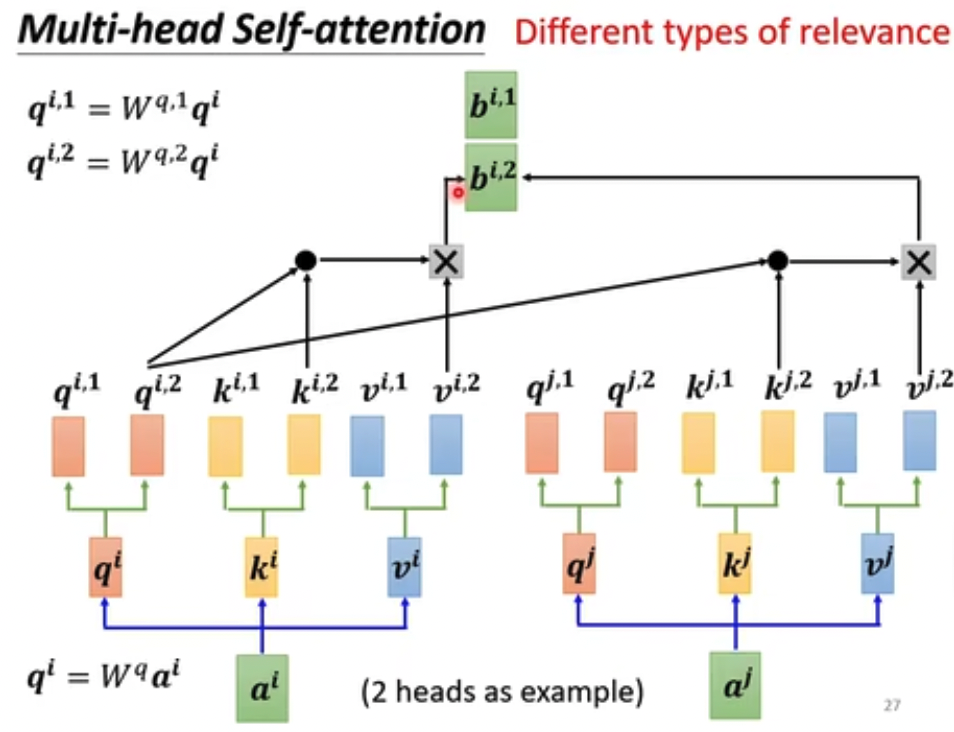
Multi-head,多头,相关性可能有多种,所以要用多头来建模不同的相关性
Self-attention是所有向量一起算的,和RNN不同,后面还会讲到,这样高效
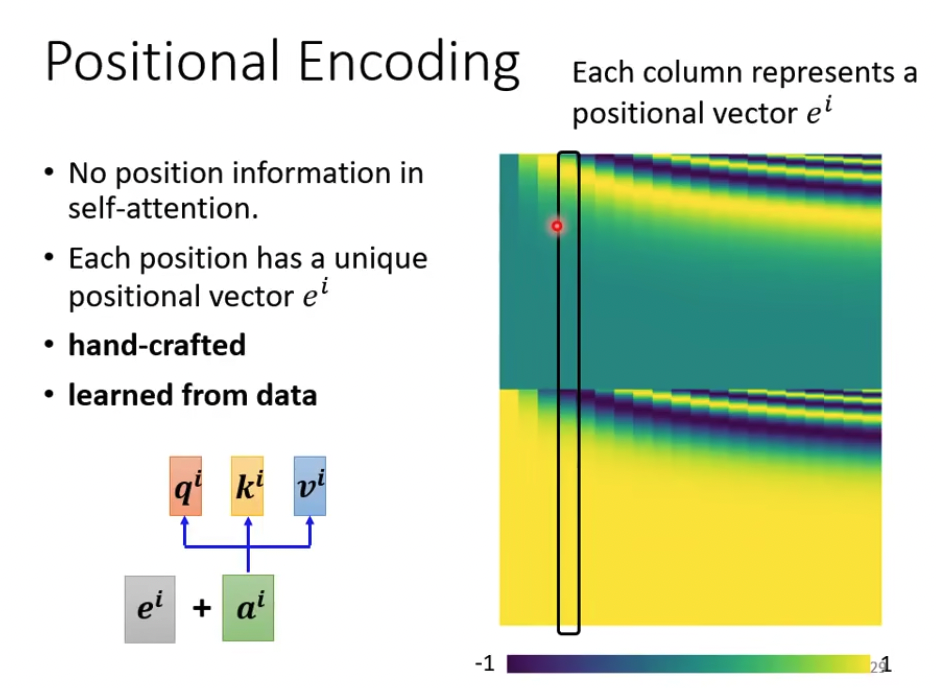
但是丢失了位置信息,所以这个研究希望加入positional encoding来建模位置信息
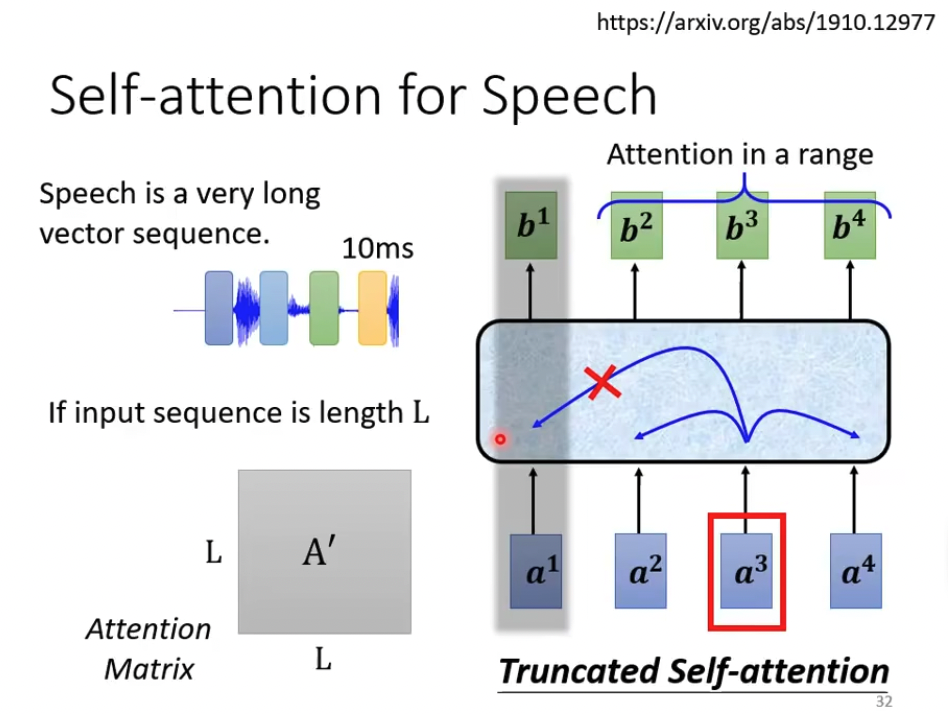
前面说了Speech,音频信息是非常大的
self-attention模型本身是计算量很大的,所以如果向量太长就有问题
所以这里的思路就是要truncated,就是要tradeoff,那准确率换性能
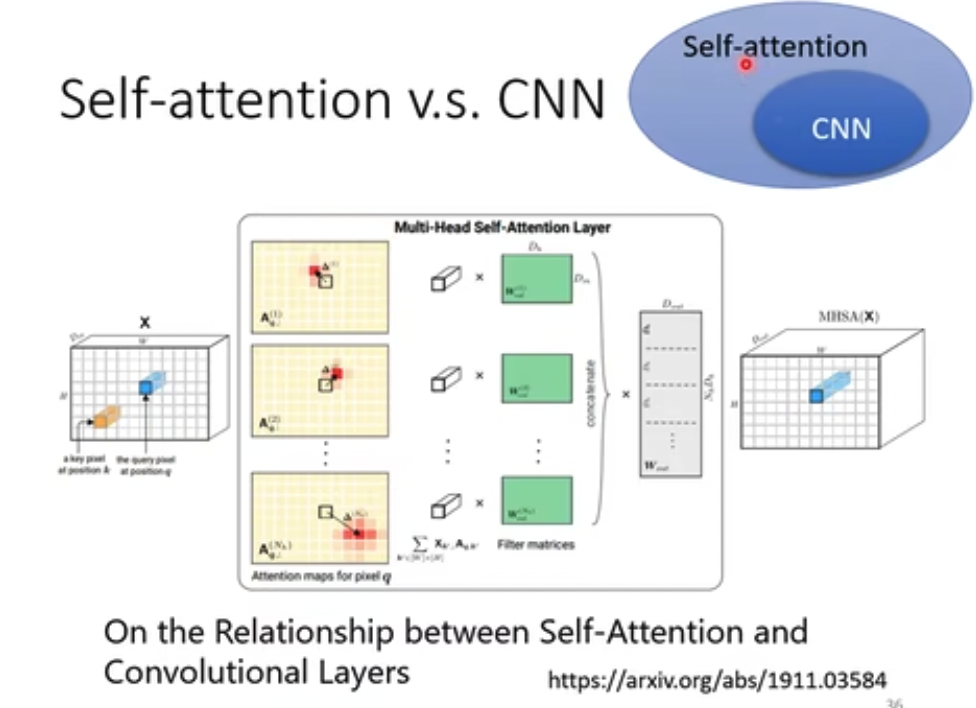
这里很有意思,和CNN比较
结论是,CNN是简化的self-attention,反之,self-attention是泛化的cnn
这个也很直觉,CNN只是考虑卷积范围内的context,而self-attention是考虑全部的context
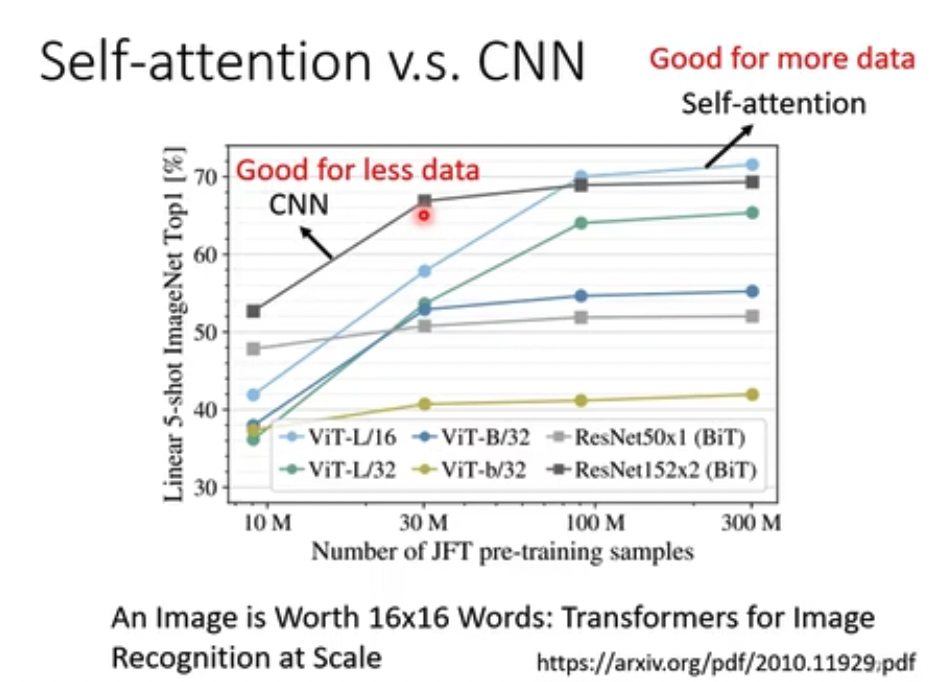
越是泛化的模型,越是需要更多的数据集,所以后面的试验也证明Self-Attention需要更多的训练集来达到效果

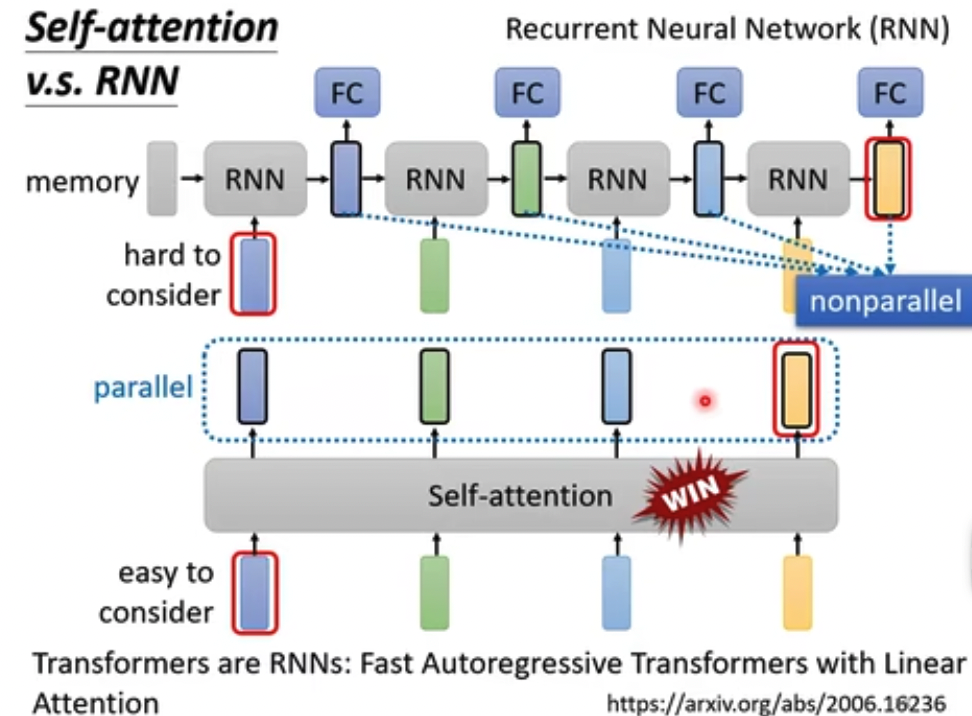
这里比较和RNN,结论就是大部分情况下,Self-Attention是可以替换到RNN的,技术变化的真快,现在RNN已经是昨日黄花了
原因主要是,Self-Attention更高效,并行算的,而RNN是一个个算过去
RNN保留context的机制更加复杂,而Self-Attention是自然的获得所有的context
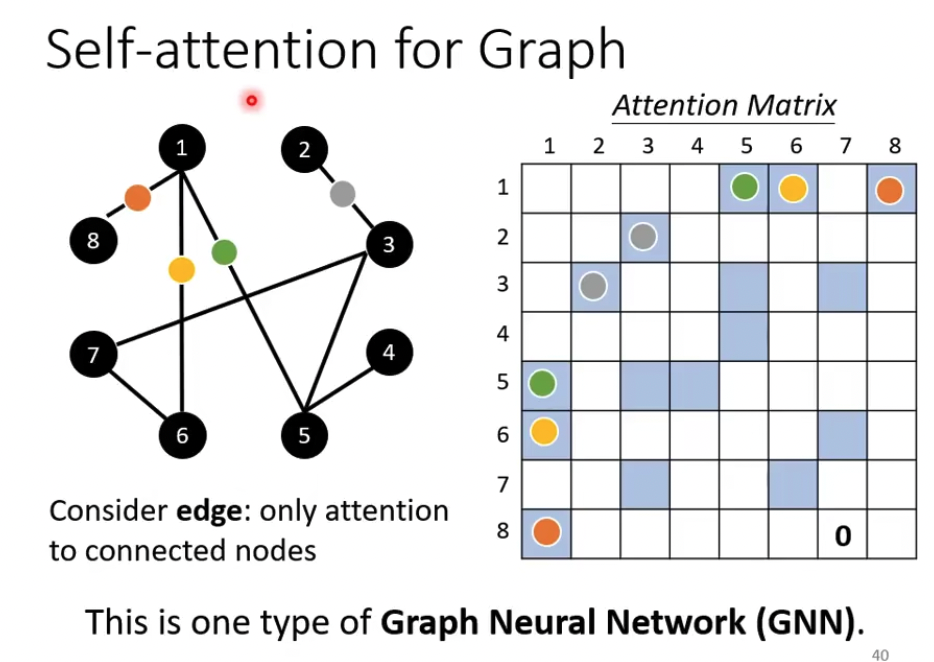
GNN,也可以用Self-Attention,这样只需要算有edge的节点间的attention,更高效
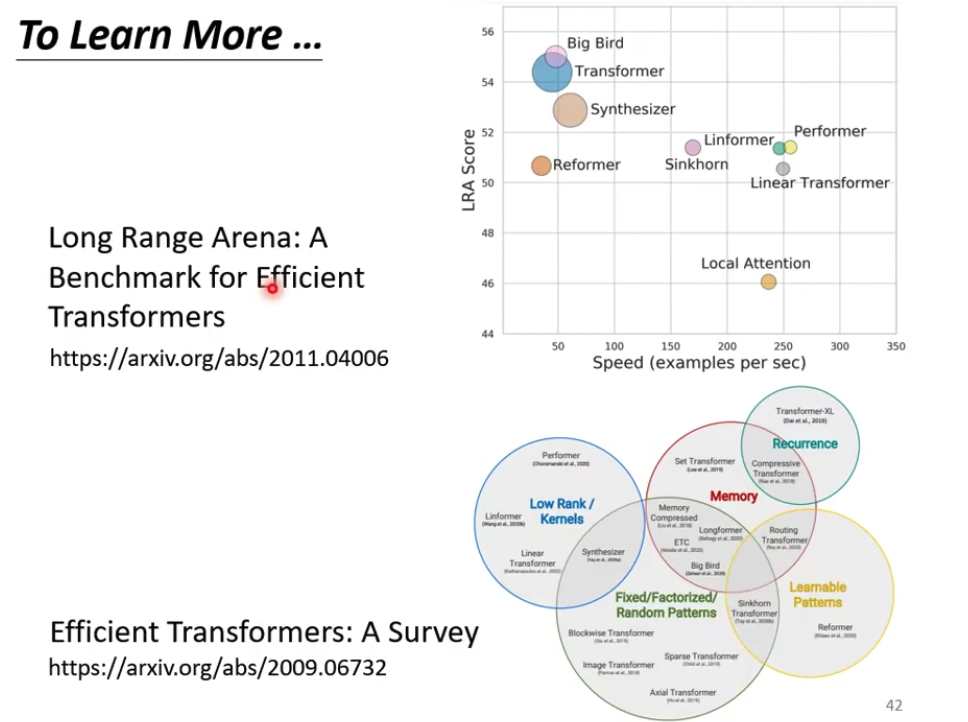
Self-Attention有很多的变种,因为它作为transformer的主要技术,变种都叫各种former
但是基本都是在准确率和计算效率之间做tradeoff
- self-attention attention 笔记 selfself-attention attention笔记self self-attention self-attentive self-attention attention self self-attentive interaction attentive automatic recommendation self-attention sequential stochastic self-attention local-global interactions transformers self-attention representation functional attention self-attention attention self 4.1 self-attention注意力attention机制