Linux
尚硅谷 JAVA 研究院
版本: V 1. 1
第 1 章 Linux 简介
1. 1 开源的力量
1. 1. 1 我们已经用过的开源软件
Spring
MyBatis
Tomcat
MySQL
JDK
......
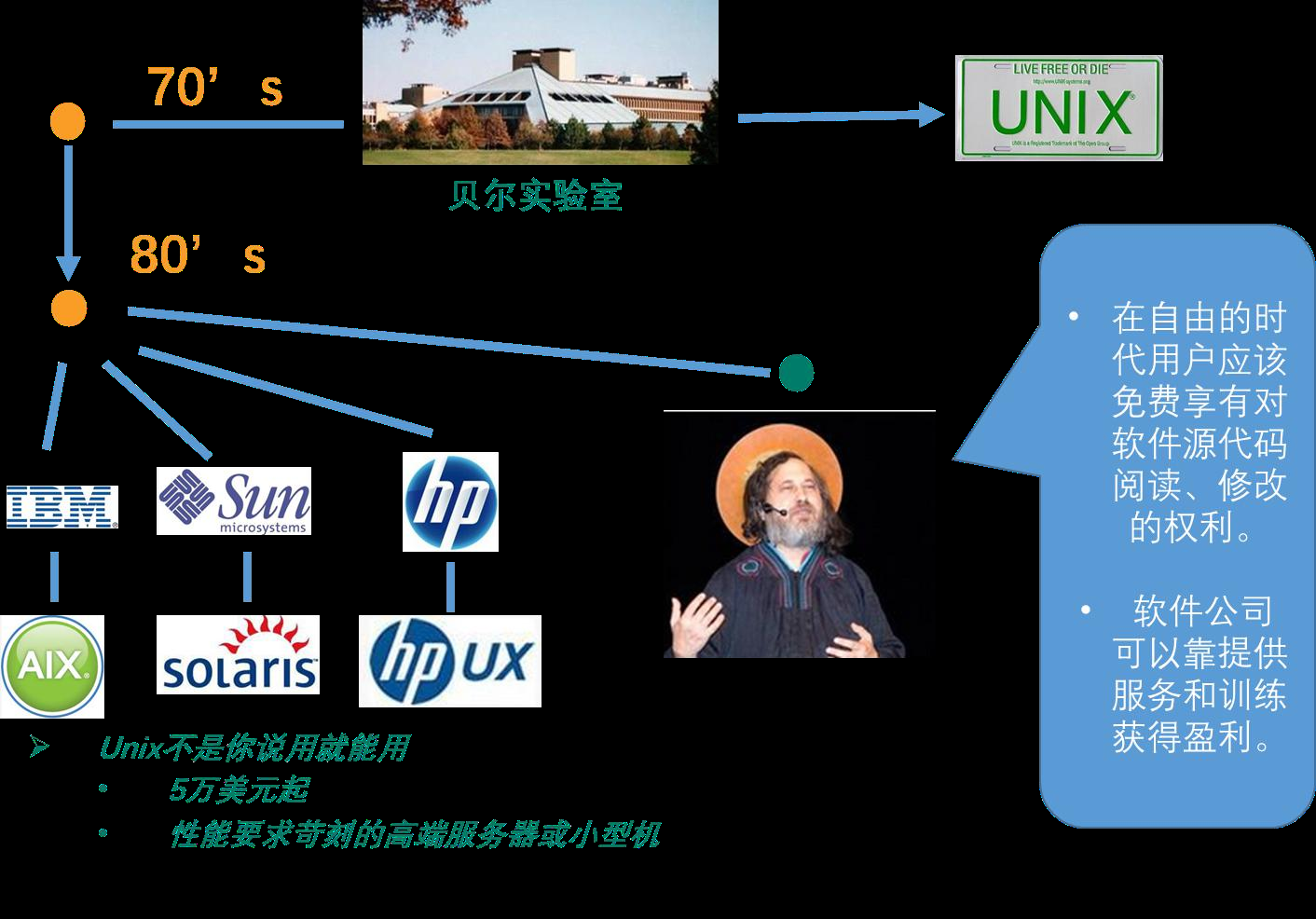
1. 1. 2 开源软件领域的旗帜: Linux
Linux是一款类Unix操作系统,它的出现离不开GNU自由软件运动中诞生的开发环境和编译器,又反过来极大
的推动了GNU自由软件运动,让崇尚自由软件精神的先驱们不必继续局限在Unix系统上进行开发。Linux出现后,
sendmail,wu-ftp,apache等团队纷纷启动了基于Linux系统的开发计划。
1. 1. 3 软件开源的好处
虚拟团队
参与开发、维护的团队成员不必身在同一个办公室,在世界任何一个角落都可以通过互联网对开源产品进
行改进。
量身定制
自由软件允许使用者对软件产品进行修改,便于使用者最大限度满足自身需要。
广泛受益
让更多的人能够享受到开源软件提供的服务。
稳定高效
由于开源软件产品吸纳了全世界所有相关领域的最顶尖程序员一起来进行维护和排错,所以开源软件漏洞
更少,效率更高。
开源不等于免费
开源指的是开放源代码,但编译得到的二进制可执行程序可能是收费的;或者产品免费,服务收费;再或
者开发定制功能收费。所以,开源项目并不影响商业运作。
1. 2 .Linux 的来历
1. 2. 1 Unix 的尴尬
硬件相关
早期的Unix系统都是针对专门的硬件系统开发的,不同厂商都是为自己的服务器开发专门的Unix操
作系统。
版权受限
出于商业等方面因素的考虑,AT&T在 1979 年发行第七版Unix系统时收回了Unix的版权。
1. 2. 2 用于教学的 Minix
在Unix收回版权的背景下,出于学院教学的需要,荷兰阿姆斯特丹的Vrije大学计算机科学系的AndrewS.
Tanenbaum教授开发了一个“类Unix”系统:Minix。之所以称为类Unix,是由于Tanenbaum教授为了避免版权
纠纷在开发过程中刻意完全不看Unix本身代码,但同时要做到在使用时让用户的操作方式和使用Unix时一样。
1. 2. 3 受到启发的 Linux
Minix最有名的学生用户是LinusTorvalds,他在芬兰的赫尔辛基大学用Minix操作平台建立了一个新的操作
系统的内核,他把它叫做Linux。
Linux是 LinusTorvalds受到Minix的影响而开发的(LinusTorvalds不喜欢他的 386 电脑上的MS-DOS操作
系统,安装了Minix,并以它为样本开发了原始的Linux内核)。

“Talk is cheap,show me the code!”
1. 3 .Linux 是什么?
1. 3. 1 Linux 是一款开源免费的操作系统。
Linux内核最初只是由芬兰人林纳斯 · 托瓦兹(LinusTorvalds)在赫尔辛基大学上学时出于个人爱好而编写的。
Linux是一套免费使用和自由传播的类Unix操作系统,是一个基于POSIX和UNIX的多用户、多任务、支持多线
程和多CPU的操作系统。Linux能运行主要的UNIX工具软件、应用程序和网络协议。它支持 32 位和 64 位硬件。Linux
继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
目前市面上较知名的发行版有:Ubuntu、RedHat、CentOS、Debain、Fedora、SuSE、OpenSUSE

1. 3. 2 Linux 的优势
Linux系统的优势主要体现在服务器端应用方面,在PC端还是Windows系统对用户操作体验和应用程序的支持
更好。具体体现是:
性能强劲,安全稳定
Linux本来就是基于Unix概念而发展出来的操作系统,当然也继承了Unix稳定高效的特点。使用Linux系统的
主机连续工作 1 年以上不死机、不重启是非常常见的。所以很多电影、动画中的特效制作这样需要强大运算能力的
工作都是运行在Linux系统之上。
可定制
如果你对Linux足够了解,完全可以使用Linux内核搭配需要的组件构成一个定制版系统,甚至你可以修改Linux
源码进行深度定制
免费或少许费用
学习Linux可以免费使用Linux的各种发行版,在商业用途中往往也只是支付很少的费用即可
硬件配置要求低
Linux内核只有几KB大小,仅运行内核的话需要的系统开销很小,以命令行方式操作Linux也一样。以图形化
界面方式运行Linux需要的资源也比Windows更少。
嵌入移动设备
由于Linux只需要很少的资源就能够驱动所有硬件设备工作,所以非常适合嵌入到手机等移动设备中,例如现
在我们使用的Android系统就是以Linux为核心的。
1. 3. 2 不同时代的不同选择
1 )一夫当关的时代,小型机单节点架构
高性能
极强的稳定性
量身定制的UNIX
应用程序结构简单
厂商提供售后服务
价格高昂
2 )烂机子组团的时代,分布式架构
可扩展的性能
风险分摊
去IOE,免费的Linux
应用程序架构复杂
运维不依赖厂商
价格好商量
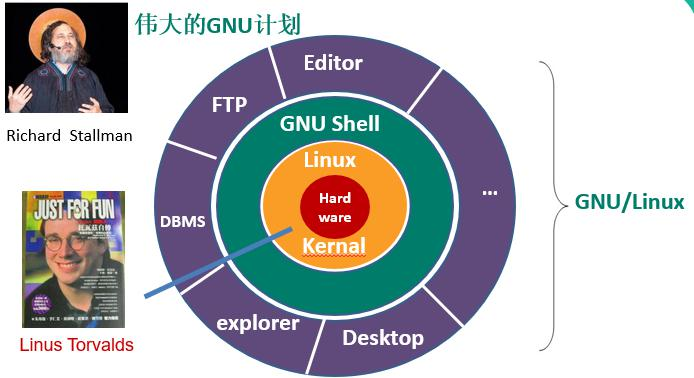
1. 4 .Linux 内核与它的各种发行版
Torvalds和他的虚拟团队的工作仅仅是开发了Linux内核以及附带的一些工具,尚不能作为一个完整的可以交给
终端用户使用的操作系统。为了方便用户使用,很多的商业公司或非营利团体,就将Linux内核(包括工具)与可
运行的软件整合起来,再加上系统的安装工具。这个『内核+软件+工具』的完全可安装的整体,我们称之为Linux
distribution,这就是Linux的发行版,港台腔叫发行套件。这是Linux这样的开放式系统和Windows、Mac等这些封
闭式系统的一个显著差别。
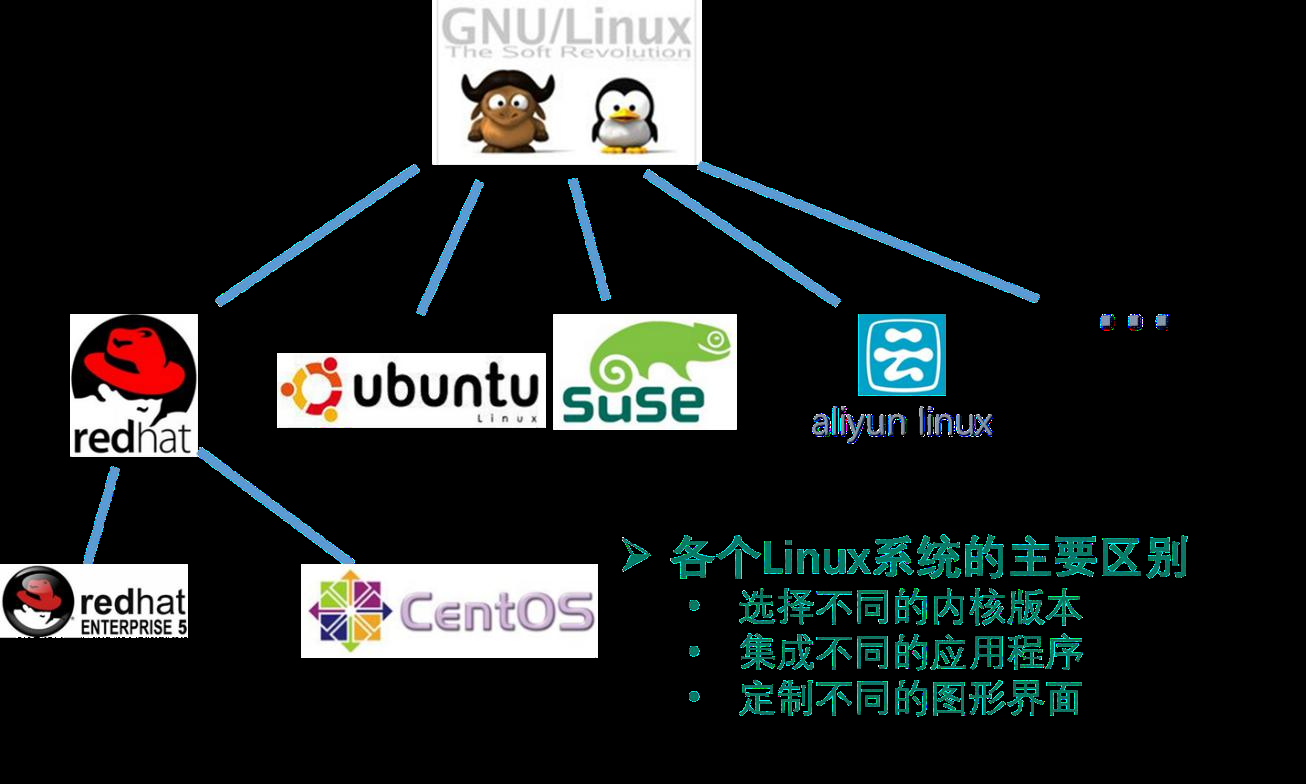
初学Linux通常会选择CentOS,这其实是RedHat收费后去掉收费功能而发布的一个免费的社区版。
主要的Linux发行版有:
● RedHat:http://www.redhat.com
●Fedora:http://fedoraproject.org/
●Debian:http://www.debian.org/
●Ubuntu:http://www.ubuntu.com/
●CentOS:http://www.centos.org/
我们可以从网易开源镜像站获取CentOS系统的镜像文件
http://mirrors. 163 .com/
第 2 章 Linux 安装
两个概念: 物理机和虚拟机。
创建虚拟机需要一台支持虚拟化的物理机、虚拟化软件(VMWare)。步骤大体分两步,第一步使用虚拟化软件
(VMWara)虚拟出一台虚拟机,然后再为这台虚拟机安装操作系统!
2. 1 查看虚拟化支持
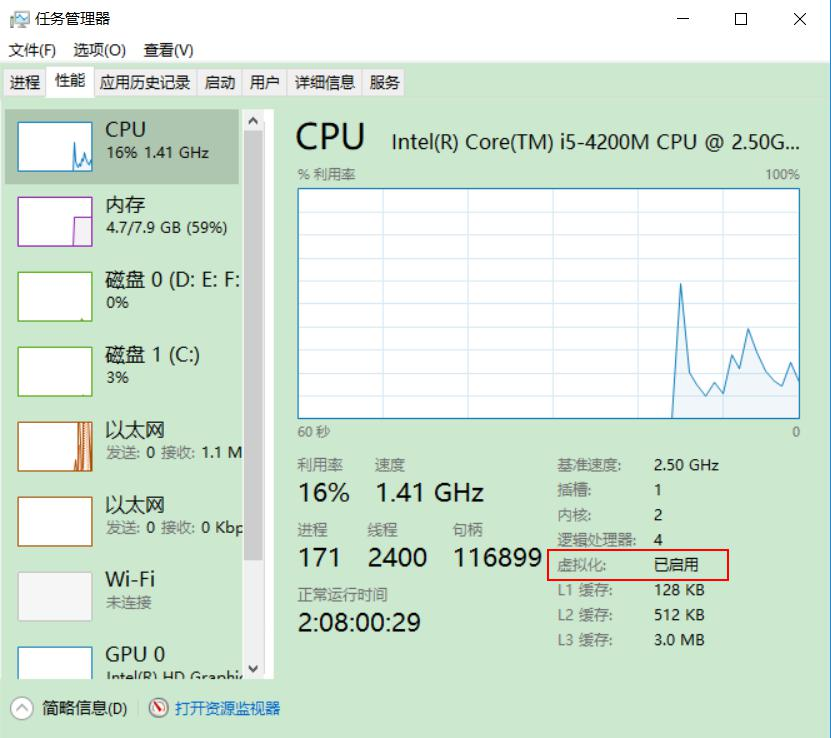
开启:
2. 2 安装 VMWare 软件
2. 3 创建虚拟机
2. 4 为虚拟机安装 Centos 操作系统
( 1 )CentOS 6 安装步骤如下:
( 2 )CentOS 7 安装步骤如下:
01 在VM上安装Ce
ntOS 7 _ 201802 V 1. 4 .docx
2. 5 安装 VMTools 工具
VMTools安装.doc
安裝成功后,需要重启虚拟机。
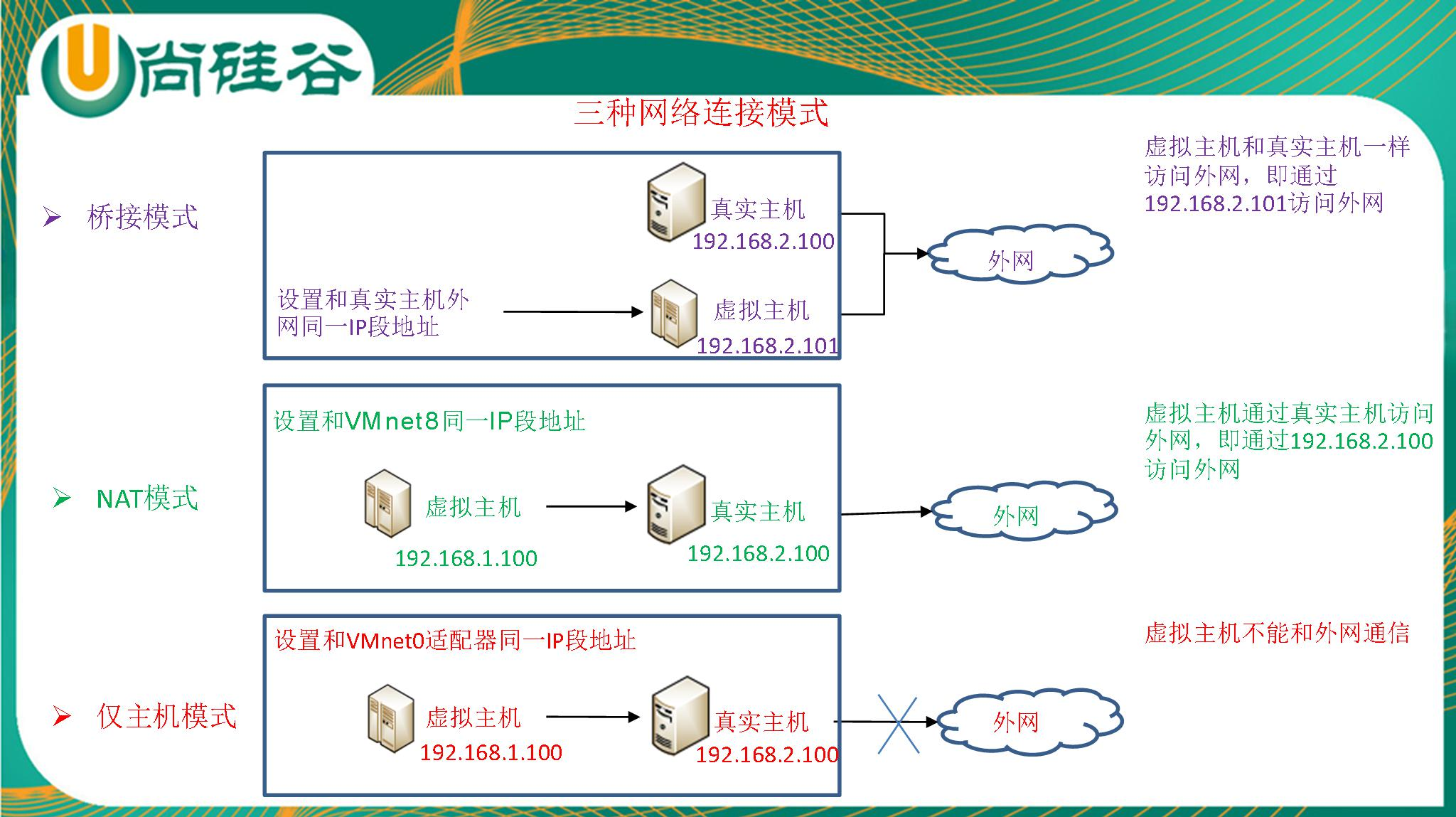
2. 6 网络配置
2. 7 远程连接
远程连接工具通常基于SSH协议,SSH(SecureShell)协议是一种基于密钥的安全性很好的协议,将发送的数
据加密。因此虚拟机需要开启SSH协议的服务,即sshd服务。

如果没有运行,则执行servicesshdstart,开启服务即可!
第 3 章 文件和目录结构
3. 1 文件
Linux系统中一切皆文件。
在Linux系统中任何东西都是以文件形式来存储的。这其中不仅包括我们熟知的文本文件、可执行文件等等,
还包括硬件设备、虚拟设备、网络连接等等,甚至连目录其实都是一种特殊的文件。
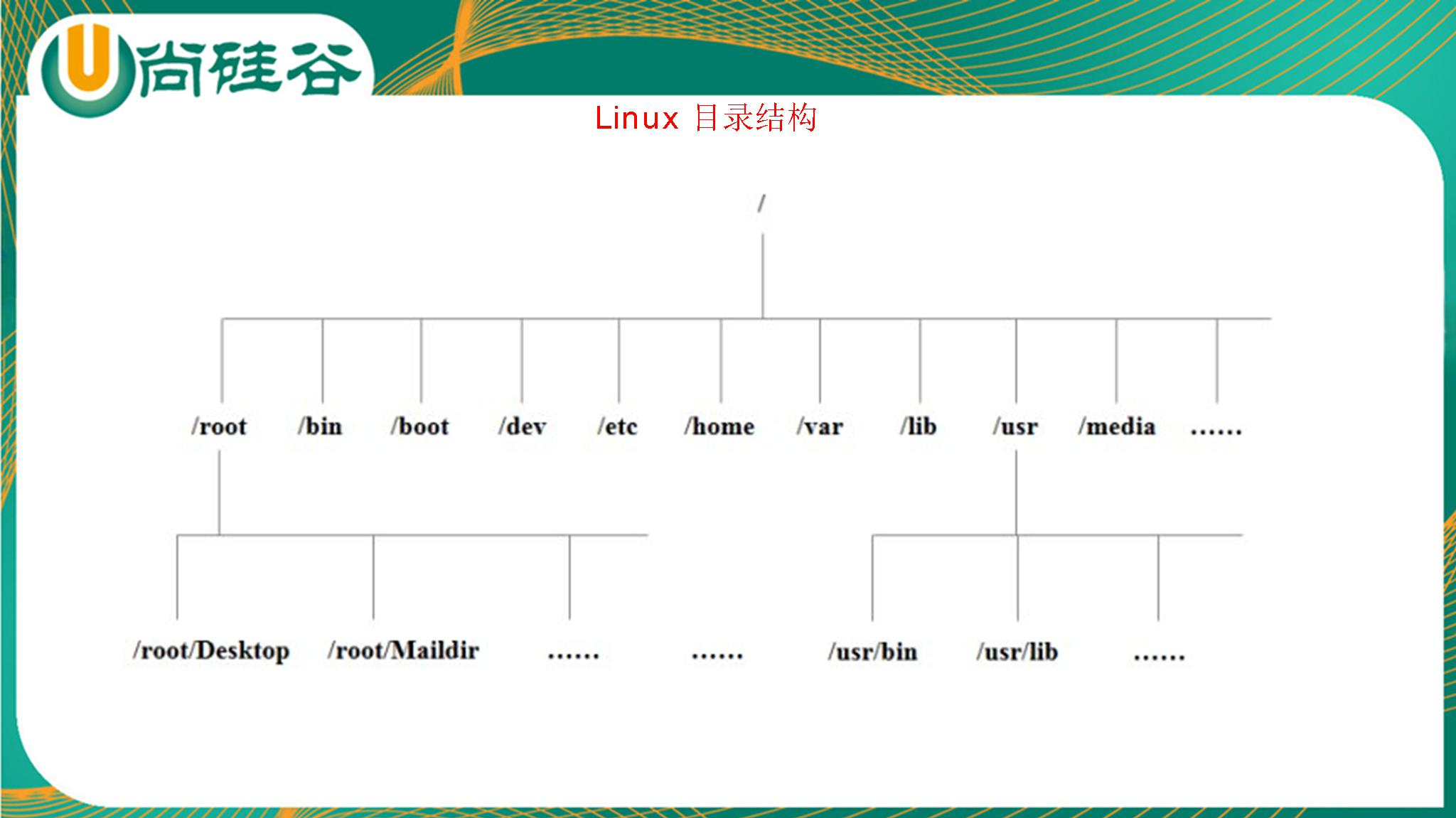
3. 2 Linux 目录结构
在Windows中,每一个盘符下是一个独立的文件系统,硬盘有多少个分区就有多少个文件系统。而在Linux系
统中不管创建了多少个硬盘分区都只有一个文件系统。整个文件系统的根目录是“/”,从“/”根目录出发理论上可
以找到Linux系统中的所有目录和文件。





3. 3 Linux 系统中的路径
绝对路径:从“/”根目录开始逐层查找文件和目录。
/etc/sysconfig/network-scripts
/tmp/vmware-root/vmware-db.pl. 2267
相对路径:以当前目录或上一级目录为基准逐层查找文件和目录
当前目录:“./”
当前目录的上一级目录:“../”
3. 4 用户家目录
①作用:Linux系统为每一个用户提供了一个专属的目录用来存放它自己的文件内容,在Linux中使用“~”代表用
户的家目录
②root用户:家目录是/root目录。
③普通用户:在创建后会在/home目录下创建与用户名同名的目录。例如:用户tom的家目录是/home/tom
第 4 章 VIM 编辑器
4. 1. 简介
Linux系统环境下的一款非常重要的文本编辑工具,我们在Linux环境下几乎所有的文本文件编辑工作都是靠它。
可能你还听说过VI,嗯,VIM是VI的升级版。
4. 2 .VIM 编辑器的三种工作模式
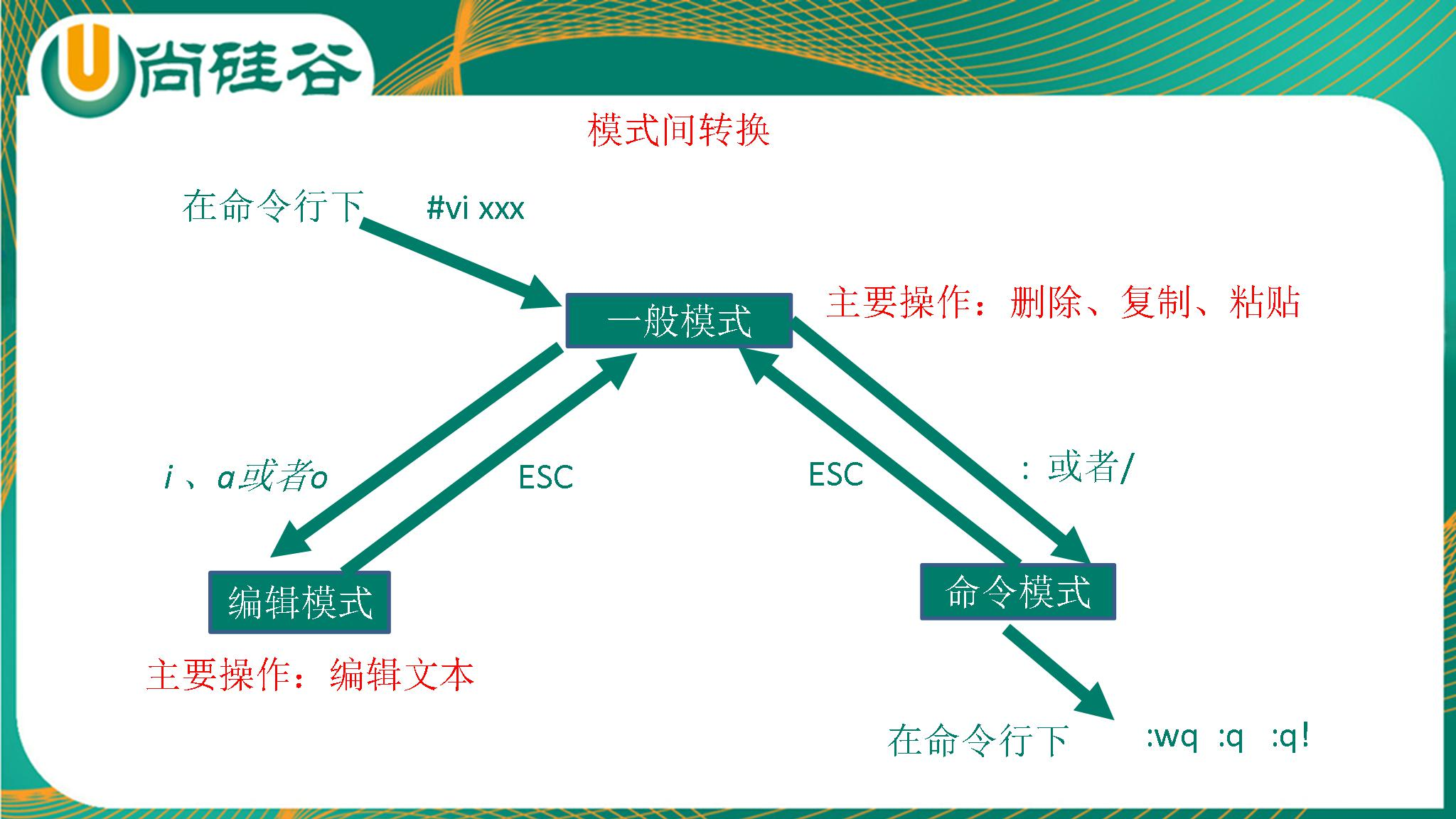
4. 3. 一般模式
以vi打开一个档案就直接进入一般模式了(这是默认的模式)。在这个模式中,你可以使用『上下左右』按键
来移动光标,你可以使用『删除字符』或『删除整行』来处理档案内容, 也可以使用『复制、贴上』来处理你的
文件数据。
按键 功能描述
yy 复制光标当前一行
y数字y 复制一段(从第几行到第几行)
p 箭头移动到目的行粘贴
u 撤销上一步
dd 删除光标当前行
d数字d 删除光标(含)后多少行
x 删除一个字母,相当于del
X 删除一个字母,相当于Backspace
yw 复制一个词
dw 删除一个词
shift+^ 移动到行头
shift+$ 移动到行尾
1 +shift+g 移动到页头,数字
shift+g 移动到页尾
数字N+shift+g 移动到目标行
4. 4. 编辑模式
在一般模式中可以进行删除、复制、粘贴等的动作,但是却无法编辑文件内容的!要等到你按下『i,I,o,O,a,A,
r,R』等任何一个字母之后才会进入编辑模式。
注意了!通常在Linux中,按下这些按键时,在画面的左下方会出现『INSERT或 REPLACE』的字样,此时才可以
进行编辑。而如果要回到一般模式时, 则必须要按下『Esc』这个按键即可退出编辑模式。
按键 功能
i 当前光标前
a 当前光标后
o 当前光标行的下一行
I 光标所在行最前
A 光标所在行最后
O 当前光标行的上一行
s 删除当前字符并进入编辑
S 删除整行并进入编辑
4. 5. 指令模式
在一般模式当中,输入『 ??』 3 个中的任何一个按钮,就可以将光标移动到最底下那一行。
在这个模式当中, 可以提供你『搜寻资料』的动作,而读取、存盘、大量取代字符、离开 vi 、显示行号等动
作是在此模式中达成的!
命令 功能
:w 保存
:q 退出
:! 强制执行
/要查找的词 n 查找下一个,N往上查找
?要查找的词 n是查找上一个,shift+n是往下查找
:setnu 显示行号
:setnonu 关闭行号
:%S/str 1 /str 2 /g 将str 1 批量替换为str 2
注意:
①其实强制保存时,还要看是否具备权限,如果没有权限加了强制也不一定能保存进去
②如果有未保存的修改则无法退出
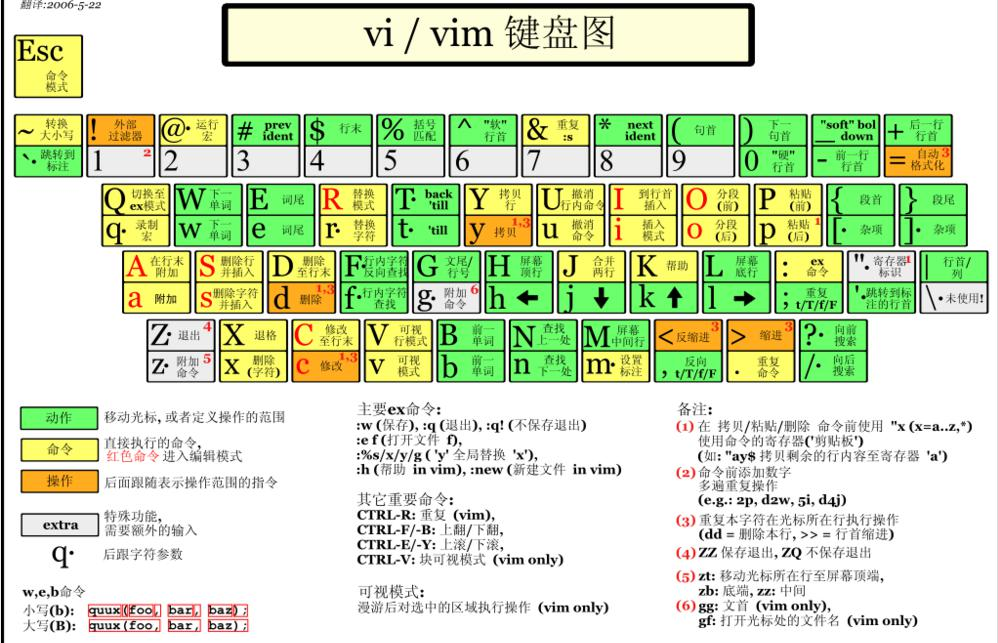
4. 6 .VIM 键盘图
第 5 章 网络配置和系统管理操作
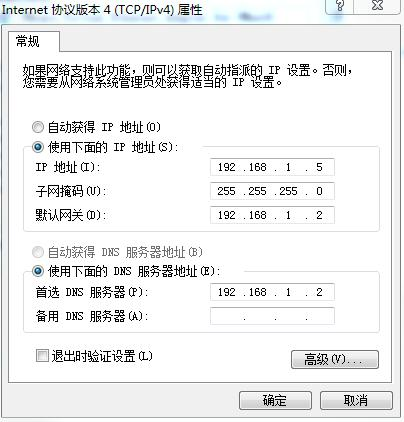
5. 1 查看网络 IP 和网关
1 )查看虚拟网络编辑器
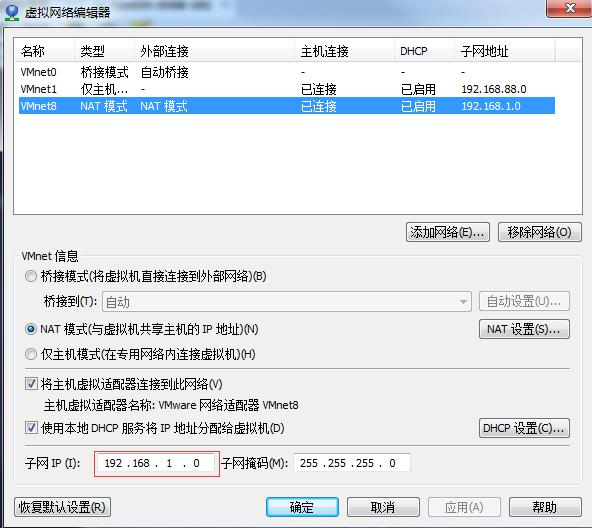
2 )修改ip地址
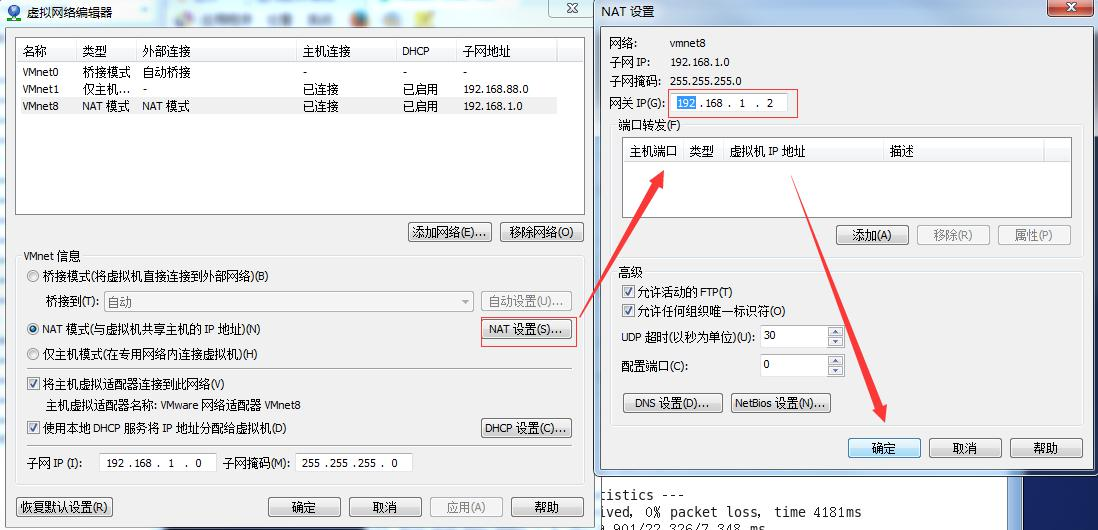
3 )查看网关
4 )查看windows环境的中VMnet 8 网络配置
5. 2 配置网络 ip 地址
5. 2. 1 ifconfig 配置网络接口
ifconfig:networkinterfacesconfiguring网络接口配置
1 )基本语法:
ifconfig (功能描述:显示所有网络接口的配置信息)
2 )案例实操:
( 1 )查看当前网络ip
[root@hadoop 100 桌面]#ifconfig
5. 2. 2 ping 测试主机之间网络连通性
1 )基本语法:
ping 目的主机 (功能描述:测试当前服务器是否可以连接目的主机)
2 )案例实操:
( 1 )测试当前服务器是否可以连接百度
[root@hadoop 100 桌面]#pingwww.baidu.com
5. 2. 3 修改 IP 地址
1 )修改IP地址
[root@hadoop 100 桌面]#vim/etc/sysconfig/network-scripts/ifcfg-eth 0
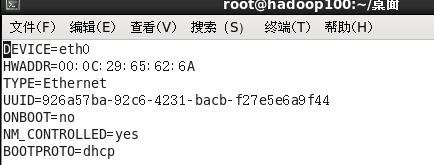
以下标红的项必须修改,有值的按照下面的值修改,没有该项的要增加。
DEVICE=eth 0 #接口名(设备,网卡)
HWADDR= 00 : 0 C: 2 x: 6 x: 0 x:xx #MAC地址
TYPE=Ethernet #网络类型(通常是Ethemet)
UUID= 926 a 57 ba- 92 c 6 - 4231 - bacb-f 27 e 5 e 6 a 9 f 44 #随机id
#系统启动的时候网络接口是否有效(yes/no)
ONBOOT=yes
#IP的配置方法[none|static|bootp|dhcp(] 引导时不使用协议|静态分配IP|BOOTP协
议|DHCP协议)
BOOTPROTO=static
#IP地址
IPADDR= 192. 168. 1. 101
#网关
GATEWAY= 192. 168. 1. 2
#域名解析器
DNS 1 = 192. 168. 1. 2
修改后
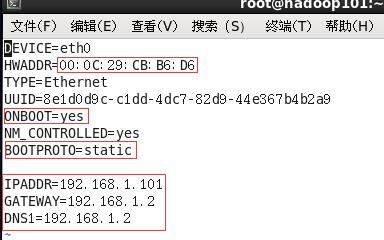
:wq 保存退出
2 )执行servicenetworkrestart

3 )如果报错,reboot,重启虚拟机
5. 3 配置主机名
5. 3. 1 hostname 显示和设置系统的主机名称
1 )基本语法:
hostname (功能描述:查看当前服务器的主机名称)
2 )案例实操:
( 1 )查看当前服务器主机名称
[root@hadoop 100 桌面]#hostname
5. 3. 2 修改主机名称
1 )修改linux的主机映射文件(hosts文件)
( 1 )进入Linux系统查看本机的主机名。通过hostname命令查看
[root@hadoop 100 桌面]#hostname
hadoop 100
( 2 )如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件
[root@hadoop 100 桌面]#vi/etc/sysconfig/network
文件中内容
NETWORKING=yes
NETWORKING_IPV 6 =no
HOSTNAME=hadoop 100
注意:主机名称不要有“_”下划线
( 3 )打开此文件后,可以看到主机名。修改此主机名为我们想要修改的主机名hadoop 100 。
( 4 )保存退出。
( 5 )打开/etc/hosts
[root@hadoop 100 桌面]#vim/etc/hosts
添加如下内容
192. 168. 1. 100 hadoop 100
192. 168. 1. 101 hadoop 101
192. 168. 1. 102 hadoop 102
192. 168. 1. 103 hadoop 103
192. 168. 1. 104 hadoop 104
192. 168. 1. 105 hadoop 105
192. 168. 1. 106 hadoop 106
192. 168. 1. 107 hadoop 107
192. 168. 1. 108 hadoop 108
( 6 )并重启设备,重启后,查看主机名,已经修改成功
2 )修改window 7 的主机映射文件(hosts文件)
( 1 )进入C:\Windows\System 32 \drivers\etc路径
( 2 )打开hosts文件并添加如下内容
192. 168. 1. 100 hadoop 100
192. 168. 1. 101 hadoop 101
192. 168. 1. 102 hadoop 102
192. 168. 1. 103 hadoop 103
192. 168. 1. 104 hadoop 104
192. 168. 1. 105 hadoop 105
192. 168. 1. 106 hadoop 106
192. 168. 1. 107 hadoop 107
192. 168. 1. 108 hadoop 108
3 )修改window 10 的主机映射文件(hosts文件)
( 1 )进入C:\Windows\System 32 \drivers\etc路径
( 2 )拷贝hosts文件到桌面
( 3 )打开桌面hosts文件并添加如下内容
192. 168. 1. 100 hadoop 100
192. 168. 1. 101 hadoop 101
192. 168. 1. 102 hadoop 102
192. 168. 1. 103 hadoop 103
192. 168. 1. 104 hadoop 104
192. 168. 1. 105 hadoop 105
192. 168. 1. 106 hadoop 106
192. 168. 1. 107 hadoop 107
192. 168. 1. 108 hadoop 108
( 4 )将桌面hosts文件覆盖C:\Windows\System 32 \drivers\etc路径hosts文件
5. 4 关闭防火墙( CentOS 6 )
5. 4. 1 service 后台服务管理
1 )基本语法:
service 服务名 start (功能描述:开启服务)
service 服务名 stop (功能描述:关闭服务)
service 服务名 restart (功能描述:重新启动服务)
service 服务名 status (功能描述:查看服务状态)
2 )经验技巧
查看服务的方法:/etc/init.d/服务名
[root@hadoop 100 init.d]#pwd
/etc/init.d
[root@hadoop 100 init.d]#ls-al
3 )案例实操
( 1 )查看网络服务的状态
[root@hadoop 100 桌面]#servicenetworkstatus
( 2 )停止网络服务
[root@hadoop 100 桌面]#servicenetworkstop
( 3 )启动网络服务
[root@hadoop 100 桌面]#servicenetworkstart
( 4 )重启网络服务
[root@hadoop 100 桌面]#servicenetworkrestart
( 5 )查看系统中所有的后台服务
[root@hadoop 100 桌面]#service--status-all
5. 4. 2 chkconfig 设置后台服务的自启配置
1 )基本语法:
chkconfig (功能描述:查看所有服务器自启配置)
chkconfig服务名off (功能描述:关掉指定服务的自动启动)
chkconfig服务名on (功能描述:开启指定服务的自动启动)
chkconfig服务名--list(功能描述:查看服务开机启动状态)
2 )案例实操
( 1 )关闭iptables服务的自动启动
[root@hadoop 100 桌面]#chkconfigiptablesoff
( 2 )开启iptables服务的自动启动
[root@hadoop 100 桌面]#chkconfigiptableson
5. 4. 3 进程运行级别

5. 4. 4 关闭防火墙
1 )临时关闭防火墙:
( 1 )查看防火墙状态
[root@hadoop 100 桌面]#serviceiptablesstatus
( 2 )临时关闭防火墙
[root@hadoop 100 桌面]#serviceiptablesstop
2 )开机启动时关闭防火墙
( 1 )查看防火墙开机启动状态
[root@hadoop 100 桌面]#chkconfigiptables--list
( 2 )设置开机时关闭防火墙
[root@hadoop 100 桌面]#chkconfigiptablesoff
5. 5 关闭防火墙( CentOS 7 )
5. 5. 1 systemctl 后台服务管理
1 )基本语法:
systemctlstart 服务名(xxxx.service) (功能描述:开启服务)
systemctlstop 服务名(xxxx.service) (功能描述:关闭服务)
systemctlrestart 服务名(xxxx.service) (功能描述:重新启动服务)
systemctlstatus服务名(xxxx.service) (功能描述:查看服务状态)
2 )经验技巧
查看服务的方法:/usr/lib/systemd/system/服务名
[root@cocoonsystem]#pwd
/usr/lib/systemd/system
[root@cocoonsystem]#ls-al
3 )案例实操
( 1 )查看网络服务的状态
[root@hadoop 100 桌面]#systemctlstatusnetwork.service
( 2 )停止网络服务
[root@hadoop 100 桌面]#systemctlstopnetwork.service
( 3 )启动网络服务
[root@hadoop 100 桌面]#systemctlstartnetwork.service
( 4 )重启网络服务
[root@hadoop 100 桌面]#systemctlrestartnetwork.service
5. 5. 2 systemctl 设置后台服务的自启配置
1 )基本语法:
systemctllist-unit-files (功能描述:查看所有服务自启配置)
systemctl--typeservice (功能描述:查看服务运行情况)
systemctlenable服务名 (功能描述:开启指定服务的自动启动)
systemctldisable 服务名 (功能描述:关闭指定服务的自动启动)
2 )案例实操
( 1 )关闭firewalld(防火墙)服务的自动启动
[root@hadoop 100 桌面]#systemctldisablefirewalld.service
( 2 )开启firewalld(防火墙)服务的自动启动
[root@hadoop 100 桌面]#systemctlenablefirewalld.service
5. 4. 3 进程运行级别

5. 4. 4 关闭防火墙
1 )临时关闭防火墙:
( 1 )查看防火墙状态
[root@hadoop 100 桌面]#systemctlstatusfirewalld.service
( 2 )临时关闭防火墙
[root@hadoop 100 桌面]#systemctlstopfirewalld.service
—————————————————————————————————————
30
2 )开机启动时关闭防火墙
( 1 )查看防火墙开机启动状态
[root@hadoop 100 桌面]#systemctllist-unit-files|grepfirewalld
( 2 )设置开机时关闭防火墙
[root@hadoop 100 桌面]#systemctlenablefirewalld.service
5. 6 关机重启命令
在linux领域内大多用在服务器上,很少遇到关机的操作。毕竟服务器上跑一个服务是永无止境的,除非特殊
情况下,不得已才会关机。
正确的关机流程为:sync>shutdown>reboot>halt
1 )基本语法:
( 1 )sync (功能描述:将数据由内存同步到硬盘中)
( 2 )halt (功能描述:关闭系统,等同于shutdown-hnow和 poweroff)
( 3 )reboot (功能描述:就是重启,等同于 shutdown-rnow)
( 4 )shutdown[选项] 时间
选项 功能
- h -h=halt关机
- r -r=reboot重启
参数 功能
now 立刻关机
时间 等待多久后关机(时间单位是分钟)。
2 )经验技巧:
Linux系统中为了提高磁盘的读写效率,对磁盘采取了 “预读迟写”操作方式。当用户保存文件时,Linux核心并
不一定立即将保存数据写入物理磁盘中,而是将数据保存在缓冲区中,等缓冲区满时再写入磁盘,这种方式可以极
大的提高磁盘写入数据的效率。但是,也带来了安全隐患,如果数据还未写入磁盘时,系统掉电或者其他严重问题
出现,则将导致数据丢失。使用sync指令可以立即将缓冲区的数据写入磁盘。
3 )案例实操:
( 1 )将数据由内存同步到硬盘中
[root@hadoop 100 桌面]#sync
( 2 )重启
[root@hadoop 100 桌面]#reboot
( 3 )关机
[root@hadoop 100 桌面]#halt
( 4 )计算机将在 1 分钟后关机,并且会显示在登录用户的当前屏幕中
[root@hadoop 100 桌面]#shutdown-h 1 ‘Thisserverwillshutdownafter 1 mins’
( 5 )立马关机(等同于 halt)
[root@hadoop 100 桌面]#shutdown-hnow
( 6 )系统立马重启(等同于 reboot)
[root@hadoop 100 桌面]#shutdown-rnow
5. 7 找回 root 密码
之尚找硅回谷r大oo数t密据码技.术doc
第 6 章 克隆虚拟机
6. 1 克隆虚拟机
①关闭要被克隆的虚拟机
②找到克隆选项
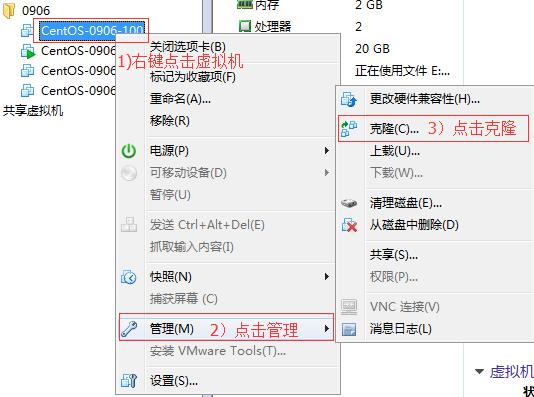
③欢迎页面点击下一步
④克隆虚拟机,克隆自虚拟机的当前状态后,点击下一步
⑤设置创建完整克隆
⑥设置克隆的虚拟机名称和存储位置
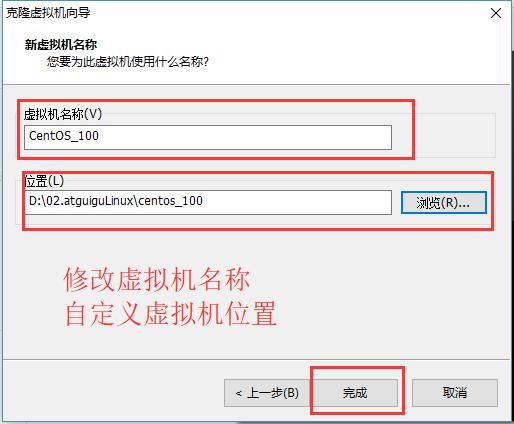
⑦等待正在克隆
⑧点击关闭,完成克隆
6. 2 克隆完成后的配置
①修改克隆后虚拟机的ip
[root@hadoop 101 /]#vim/etc/udev/rules.d/ 70 - persistent-net.rules
进入如下页面,删除eth 0 该行;将eth 1 修改为eth 0 ,同时复制物理ip地址

10 )修改IP地址
[root@hadoop 101 /]#vim/etc/sysconfig/network-scripts/ifcfg-eth 0
ifcfg-eth 0 文件说明:
DEVICE=eth 0 #接口名(设备,网卡)
BOOTPROTO=none
IP的配置方法[none|static|bootp|dhcp](引导时不使用协议|静态分配IP|BOOTP协议|DHCP协议)
BROADCAST= 192. 168. 1. 255 #广播地址
HWADDR= 00 : 0 C: 2 x: 6 x: 0 x:xx #MAC地址
IPADDR= 192. 168. 1. 23 #IP地址
NETMASK= 255. 255. 255. 0 #网络掩码
NETWORK= 192. 168. 1. 0 #网络地址
ONBOOT=yes #系统启动的时候网络接口是否有效(yes/no)
TYPE=Ethernet #网络类型(通常是Ethemet)
( 1 )把复制的物理ip地址更新
HWADDR= 00 : 0 C: 2 x: 6 x: 0 x:xx #MAC地址
( 2 )修改成你想要的ip
IPADDR= 192. 168. 1. 101 #IP地址
11 )修改主机名称
详见 5. 3 。
12 )重新启动服务器
第 7 章 常用基本命令
7. 1 帮助命令
7. 1. 1 man 获得帮助信息
1 )基本语法:
man[命令或配置文件] (功能描述:获得帮助信息)
2 )显示说明
信息 功能
NAME 命令的名称和单行描述
SYNOPSIS 怎样使用命令
DESCRIPTION 命令功能的深入讨论
EXAMPLES 怎样使用命令的例子
SEEALSO 相关主题(通常是手册页)
3 )案例实操
( 1 )查看ls命令的帮助信息
[root@hadoop 101 ~]#manls
7. 1. 2 help 获得 shell 内置命令的帮助信息
1 )基本语法:
help 命令 (功能描述:获得shell内置命令的帮助信息)
2 )案例实操:
( 1 )查看cd命令的帮助信息
[root@hadoop 101 ~]#helpcd
7. 1. 3 常用快捷键
常用快捷键 功能
ctrl+c 停止进程
ctrl+l 清屏;彻底清屏是:reset
ctrl+q 退出
善于用tab键 提示(更重要的是可以防止敲错)
上下键 查找执行过的命令
ctrl+alt linux和Windows之间切换
7. 2 文件目录类
7. 2. 1 pwd 显示当前工作目录的绝对路径
pwd:printworkingdirectory打印工作目录
1 )基本语法:
pwd (功能描述:显示当前工作目录的绝对路径)
2 )案例实操
( 1 )显示当前工作目录的绝对路径
[root@hadoop 101 ~]#pwd
/root
7. 2. 2 ls 列出目录的内容
ls:list 列出目录内容
1 )基本语法:
ls[选项][目录或是文件]
2 )选项说明:
选项 功能
- a 全部的文件,连同隐藏档(开头为 .的文件) 一起列出来(常用)
- l 长数据串列出,包含文件的属性与权限等等数据;(常用)
3 )显示说明:
每行列出的信息依次是:文件类型与权限 链接数文件属主 文件属组 文件大小用byte来表示 建立或最近修
改的时间 名字
4 )案例实操
( 1 )查看当前目录的所有内容信息
[atguigu@hadoop 101 ~]$ls-al
总用量 44
drwx------. 5 atguiguatguigu 40965 月 2715 : 15.
drwxr-xr-x. 3 root root 40965 月 2714 : 03 ..
drwxrwxrwx. 2 root root 40965 月 2714 : 14 hello - rwxrw-r--. 1 atguiguatguigu 345 月 2714 : 20 test.txt
7. 2. 3 cd 切换目录
cd:ChangeDirectory切换路径
1 )基本语法:
cd [参数]
2 )参数说明
参数 功能
cd 绝对路径 切换路径
cd相对路径 切换路径
cd~或者cd 回到自己的家目录
cd- 回到上一次所在目录
cd.. 回到当前目录的上一级目录
cd-P 跳转到实际物理路径,而非快捷方式路径
3 )案例实操
( 1 )使用绝对路径切换到root目录
[root@hadoop 101 ~]#cd/root/
( 2 )使用相对路径切换到“公共的”目录
[root@hadoop 101 ~]#cd 公共的/
( 3 )表示回到自己的家目录,亦即是 /root 这个目录
[root@hadoop 101 公共的]#cd~
( 4 )cd- 回到上一次所在目录
[root@hadoop 101 ~]#cd-
( 5 )表示回到当前目录的上一级目录,亦即是 “/root/公共的”的上一级目录的意思;
[root@hadoop 101 公共的]#cd..
7. 2. 4 mkdir 创建一个新的目录
mkdir:Makedirectory建立目录
1 )基本语法:
mkdir[选项] 要创建的目录
2 )选项说明:
选项 功能
- p 创建多层目录
3 )案例实操
( 1 )创建一个目录
[root@hadoop 101 ~]#mkdirxiyou
[root@hadoop 101 ~]#mkdirxiyou/mingjie
( 2 )创建一个多级目录
[root@hadoop 101 ~]#mkdir-pxiyou/dssz/meihouwang
7. 2. 5 rmdir 删除一个空的目录
rmdir:Removedirectory移动目录
1 )基本语法:
rmdir要删除的空目ll录
2 )案例实操
( 1 )删除一个空的文件夹
[root@hadoop 101 ~]#rmdirxiyou/dssz/meihouwang
7. 2. 6 touch 创建空文件
1 )基本语法:
touch 文件名称
2 )案例实操
[root@hadoop 101 ~]#touchxiyou/dssz/sunwukong.txt
7. 2. 7 cp 复制文件或目录
1 )基本语法:
cp[选项]sourcedest (功能描述:复制source文件到dest)
2 )选项说明
选项 功能
- r 递归复制整个文件夹
3 )参数说明
参数 功能
source 源文件
dest 目标文件
4 )经验技巧
强制覆盖不提示的方法:\cp
5 )案例实操
( 1 )复制文件
[root@hadoop 101 ~]#cpxiyou/dssz/suwukong.txtxiyou/mingjie/
( 2 )递归复制整个文件夹
[root@hadoop 101 ~]#cp-rxiyou/dssz/./
7. 2. 8 rm 移除文件或目录
1 )基本语法
rm[选项]deleteFile (功能描述:递归删除目录中所有内容)
2 )选项说明foumo
选项 功能
- r 递归删除目录中所有内容
- f 强制执行删除操作,而不提示用于进行确认。
- v 显示指令的详细执行过程
3 )案例实操
( 1 )删除目录中的内容
[root@hadoop 101 ~]#rmxiyou/mingjie/sunwukong.txt
( 1 )递归删除目录中所有内容
[root@hadoop 101 ~]#rm-rfdssz/
7. 2. 9 mv 移动文件与目录或重命名
1 )基本语法:
( 1 )mvoldNameFilenewNameFile (功能描述:重命名)
( 2 )mv/temp/movefile/targetFolder (功能描述:移动文件)
2 )案例实操:
( 1 )重命名
[root@hadoop 101 ~]#mvxiyou/dssz/suwukong.txtxiyou/dssz/houge.txt
( 2 )移动文件
[root@hadoop 101 ~]#mvxiyou/dssz/houge.txt./
7. 2. 10 cat 查看文件内容
查看文件内容,从第一行开始显示。
1 )基本语法
cat [选项]要查看的文件
2 )选项说明
选项 功能描述
- n 显示所有行的行号,包括空行。
3 )经验技巧:
一般查看比较小的文件,一屏幕能显示全的。
4 )案例实操
( 1 )查看文件内容并显示行号
[atguigu@hadoop 101 ~]$cat-nhouge.txt
7. 2. 11 more 文件内容分屏查看器
more指令是一个基于VI编辑器的文本过滤器,它以全屏幕的方式按页显示文本文件的内容。more指令中内置
了若干快捷键,详见操作说明。
1 )基本语法:
more要查看的文件
2 )操作说明
操作 功能说明
空白键(space) 代表向下翻一页;
Enter 代表向下翻『一行』;
q 代表立刻离开 more,不再显示该文件内容。
Ctrl+F 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
3 )案例实操
( 1 )采用more查看文件
[root@hadoop 101 ~]#moresmartd.conf
7. 2. 12 less 分屏显示文件内容
less指令用来分屏查看文件内容,它的功能与more指令类似,但是比more指令更加强大,支持各种显示终端。
less指令在显示文件内容时,并不是一次将整个文件加载之后才显示,而是根据显示需要加载内容,对于显示大型
文件具有较高的效率。
1 )基本语法:
less要查看的文件
2 )操作说明
操作 功能说明
空白键 向下翻动一页;
[pagedown] 向下翻动一页
[pageup] 向上翻动一页;
/字串 向下搜寻『字串』的功能;n:向下查找;N:向上查找;
?字串 向上搜寻『字串』的功能;n:向上查找;N:向下查找;
q 离开 less这个程序;
3 )经验技巧
用SecureCRT时[pagedown]和[pageup]可能会出现无法识别的问题。
4 )案例实操
( 1 )采用less查看文件
[root@hadoop 101 ~]#lesssmartd.conf
7. 2. 13 echo
1 )echo输出内容到控制台
( 1 )基本语法:
echo[选项][输出内容]
选项:
- e: 支持反斜线控制的字符转换
控制字符 作 用
\ 输出\本身
\n 换行符
\t 制表符,也就是Tab键
( 2 )案例实操
[atguigu@hadoop 101 ~]$echo"hello\tworld"
hello\tworld
[atguigu@hadoop 101 ~]$echo-e"hello\tworld"
hello world
7. 2. 14 head 显示文件头部内容
head用于显示文件的开头部分内容,默认情况下head指令显示文件的前 10 行内容。
1 )基本语法
head 文件 (功能描述:查看文件头 10 行内容)
head-n 5 文件 (功能描述:查看文件头 5 行内容, 5 可以是任意行数)
2 )选项说明
选项 功能
- n<行数> 指定显示头部内容的行数
3 )案例实操
( 1 )查看文件的头 2 行
[root@hadoop 101 ~]#head-n 2 smartd.conf
7. 2. 15 tail 输出文件尾部内容
tail用于输出文件中尾部的内容,默认情况下tail指令显示文件的前 10 行内容。
1 )基本语法tai
( 1 )tail 文件 (功能描述:查看文件头 10 行内容)
( 2 )tail -n 5 文件 (功能描述:查看文件头 5 行内容, 5 可以是任意行数)
( 3 )tail -f 文件 (功能描述:实时追踪该文档的所有更新)
2 )选项说明
选项 功能
- n<行数> 输出文件尾部n行内容
- f 显示文件最新追加的内容,监视文件变化
3 )案例实操
( 1 )查看文件头 1 行内容
[root@hadoop 101 ~]#tail-n 1 smartd.conf
( 2 )实时追踪该档的所有更新
[root@hadoop 101 ~]#tail-fhouge.txt
7. 2. 16 > 输出重定向和 >> 追加
1 )基本语法:ll
( 1 )ls-l>文件 (功能描述:列表的内容写入文件a.txt中(覆盖写))
( 2 )ls-al>>文件 (功能描述:列表的内容追加到文件aa.txt的末尾)
( 3 )cat文件 1 >文件 2 (功能描述:将文件 1 的内容覆盖到文件 2 )
( 4 )echo“内容”>>文件
2 )案例实操
( 1 )将ls查看信息写入到文件中
[root@hadoop 101 ~]#ls-l>houge.txt
( 2 )将ls查看信息追加到文件中
[root@hadoop 101 ~]#ls-l>>houge.txt
( 3 )采用echo将hello单词追加到文件中
[root@hadoop 101 ~]#echohello>>houge.txt
7. 2. 17 ln 软链接
软链接也成为符号链接,类似于windows里的快捷方式,有自己的数据块,主要存放了链接其他文件的路径。
1 )基本语法:
ln-s[原文件或目录][软链接名] (功能描述:给原文件创建一个软链接)
2 )经验技巧
删除软链接: rm-rf软链接名,而不是rm-rf软链接名/
查询:通过ll就可以查看,列表属性第 1 位是l,尾部会有位置指向。
3 )案例实操:
( 1 )创建软连接
[root@hadoop 101 ~]#mvhouge.txtxiyou/dssz/
[root@hadoop 101 ~]#ln-sxiyou/dssz/houge.txt./houzi
[root@hadoop 101 ~]#ll
lrwxrwxrwx. 1 root root 206 月 1712 : 56 houzi->xiyou/dssz/houge.txt
( 2 )删除软连接
[root@hadoop 101 ~]#rm-rfhouzi
( 3 )进入软连接实际物理路径
[root@hadoop 101 ~]#ln-sxiyou/dssz/./dssz
[root@hadoop 101 ~]#cd-Pdssz/
7. 2. 18 history 查看已经执行过历史命令
1 )基本语法:
history (功能描述:查看已经执行过历史命令)
2 )案例实操
( 1 )查看已经执行过的历史命令
[root@hadoop 101 test 1 ]#history
7. 3 时间日期类
1 )基本语法
date[OPTION]...[+FORMAT]
2 )选项说明
选项 功能
- d<时间字符串> 显示指定的“时间字符串”表示的时间,而非当前时间
- s<日期时间> 设置系统日期时间
3 )参数说明
参数 功能
<+日期时间格式> 指定显示时使用的日期时间格式
7. 3. 1 date 显示当前时间
1 )基本语法:
( 1 )date (功能描述:显示当前时间)
( 2 )date+%Y (功能描述:显示当前年份)
( 3 )date+%m (功能描述:显示当前月份)
( 4 )date+%d (功能描述:显示当前是哪一天)
( 5 )date"+%Y-%m-%d%H:%M:%S" (功能描述:显示年月日时分秒)
2 )案例实操
( 1 )显示当前时间信息
[root@hadoop 101 ~]#date
2017 年 06 月 19 日 星期一 20 : 53 : 30 CST
( 2 )显示当前时间年月日
[root@hadoop 101 ~]#date+%Y%m%d
20170619
( 3 )显示当前时间年月日时分秒
[root@hadoop 101 ~]#date"+%Y-%m-%d%H:%M:%S"
2017 - 06 - 1920 : 54 : 58
7. 3. 2 date 显示非当前时间
1 )基本语法:
( 1 )date-d' 1 daysago' (功能描述:显示前一天时间)
( 2 )date-d'- 1 daysago' (功能描述:显示明天时间)
2 )案例实操:
( 1 )显示前一天
[root@hadoop 101 ~]#date-d' 1 daysago'
2017 年 06 月 18 日 星期日 21 : 07 : 22 CST
( 2 )显示明天时间
[root@hadoop 101 ~]#date-d'- 1 daysago'
2017 年 06 月 20 日 星期日 21 : 07 : 22 CST
7. 3. 3 date 设置系统时间
1 )基本语法:
date-s字符串时间
2 )案例实操
( 1 )设置系统当前时间
[root@hadoop 101 ~]#date-s" 2017 - 06 - 1920 : 52 : 18 "
7. 3. 4 cal 查看日历
1 )基本语法:
cal[选项] (功能描述:不加选项,显示本月日历)
2 )选项说明
选项 功能
具体某一年 显示这一年的日历
3 )案例实操:
( 1 )查看当前月的日历
[root@hadoop 101 ~]#cal
( 2 )查看 2017 年的日历
[root@hadoop 101 ~]#cal 2017
7. 4 用户管理命令
7. 4. 1 useradd 添加新用户
1 )基本语法:
useradd 用户名 (功能描述:添加新用户)
useradd-g组名 用户名 (功能描述:添加新用户到某个组)
2 )案例实操:
( 1 )添加一个用户
[root@hadoop 101 ~]#useraddtangseng
[root@hadoop 101 ~]#ll/home/
7. 4. 2 passwd 设置用户密码
1 )基本语法:
passwd 用户名 (功能描述:设置用户密码)
2 )案例实操
( 1 )设置用户的密码
[root@hadoop 101 ~]#passwdtangseng
7. 4. 3 id 查看用户是否存在
1 )基本语法:
id 用户名
2 )案例实操:
( 1 )查看用户是否存在
[root@hadoop 101 ~]#idtangseng
7. 4. 4 cat /etc/passwd 查看创建了哪些用户
1 )基本语法:
[root@hadoop 101 ~]#cat /etc/passwd
7. 4. 5 su 切换用户
su:swithuser切换用户
1 )基本语法:
su 用户名称 (功能描述:切换用户,只能获得用户的执行权限,不能获得环境变量)
su-用户名称 (功能描述:切换到用户并获得该用户的环境变量及执行权限)
2 )案例实操
( 1 )切换用户
[root@hadoop 101 ~]#sutangseng
[root@hadoop 101 ~]#echo$PATH
/usr/lib 64 /qt- 3. 3 /bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
[root@hadoop 101 ~]#exit
[root@hadoop 101 ~]#su-tangseng
[root@hadoop 101 ~]#echo$PATH
/usr/lib 64 /qt- 3. 3 /bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/tangseng/bin
7. 4. 5 userdel 删除用户
1 )基本语法:
( 1 )userdel 用户名 (功能描述:删除用户但保存用户主目录)
( 2 )userdel-r用户名 (功能描述:用户和用户主目录,都删除)
2 )选项说明
选项 功能
- r 删除用户的同时,删除与用户相关的所有文件。
3 )案例实操:
( 1 )删除用户但保存用户主目录
[root@hadoop 101 ~]#userdeltangseng
[root@hadoop 101 ~]#ll/home/
( 2 )删除用户和用户主目录,都删除
[root@hadoop 101 ~]#useraddzhubajie
[root@hadoop 101 ~]#ll/home/
[root@hadoop 101 ~]#userdel-rzhubajie
[root@hadoop 101 ~]#ll/home/
7. 4. 6 who 查看登录用户信息
who:查看当前登录的主机的用户,su切换的不算。
1 )基本语法
( 1 )whoami (功能描述:显示自身用户名称)
( 2 )whoami (功能描述:显示登录用户的用户名)
2 )案例实操
( 1 )显示自身用户名称(我现在是谁)
[root@hadoop 101 opt]#whoami
( 2 )显示登录用户的用户名(我从哪来)
[root@hadoop 101 opt]#whoami
7. 4. 7 sudo 设置普通用户具有 root 权限
1 )添加atguigu用户,并对其设置密码。
[root@hadoop 101 ~]#useraddatguigu
[root@hadoop 101 ~]#passwdatguigu
2 )修改配置文件
[root@hadoop 101 ~]#vi/etc/sudoers
修改 /etc/sudoers文件,找到下面一行( 91 行),在root下面添加一行,如下所示:
Allowroottorunanycommandsanywhere
root ALL=(ALL) ALL
atguigu ALL=(ALL) ALL
或者配置成采用sudo命令时,不需要输入密码
Allowroottorunanycommandsanywhere
root ALL=(ALL) ALL
atguigu ALL=(ALL) NOPASSWD:ALL
修改完毕,现在可以用atguigu帐号登录,然后用命令sudo,即可获得root权限进行操作。
3 )案例实操
( 1 )用普通用户在/opt目录下创建一个文件夹
[atguigu@hadoop 101 opt]$sudomkdirmodule
[root@hadoop 101 opt]#chownatguigu:atguigumodule/
7. 4. 9 usermod 修改用户
1 )基本语法:
usermod-g用户组用户名
2 )选项说明
选项 功能
- g 修改用户的初始登录组,给定的组必须存在。默认组id是 1 。
3 )案例实操:
( 1 )将用户加入到用户组
[root@hadoop 101 opt]#usermod-grootzhubajie
7. 5 用户组管理命令
每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux系统对用户组的规
定有所不同,
如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
7. 5. 1 groupadd 新增组
1 )基本语法
groupadd组名
2 )案例实操:
( 1 )添加一个xitianqujing组
[root@hadoop 101 opt]#groupaddxitianqujing
7. 5. 2 groupdel 删除组
1 )基本语法:
groupdel组名
2 )案例实操
( 1 )删除xitianqujing组
[root@hadoop 101 opt]#groupdelxitianqujing
7. 5. 3 groupmod 修改组
1 )基本语法:
groupmod-n 新组名 老组名
2 )选项说明
选项 功能描述
- n<新组名> 指定工作组的新组名
3 )案例实操
( 1 )修改atguigu组名称为atguigu 1
[root@hadoop 101 ~]#groupaddxitianqujing
[root@hadoop 101 ~]#groupmod-nxitianxitianqujing
7. 5. 4 cat /etc/group 查看创建了哪些组
1 )基本操作
[root@hadoop 101 atguigu]#cat /etc/group
7. 6 文件权限类
7. 6. 1 RBAC 权限模型
Linux需要对登录用户读写执行文件、进入目录、查看增删目录内容等操作进行控制,不能任由用户随意执行
所有操作。Linux系统是一个多用户多任务的操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理
员申请一个账号,然后以这个账号的身份进入系统。
Linux的权限控制基于RBAC(RolebasedAuthenticationControl)模型
RBAC模型:基于角色的权限控制。
资源:权限控制系统要保护的对象,在linux中就是文件和目录;
权限:对资源的操作,包括读和写
角色:对用户的分组。将同一类的用户划分到同一个用户组中,让他们具备相同的权限。
用户:登录系统时使用的账号
总结:简而言之,就是根据用户的角色判断用户是否具备操作某个资源的权限。
7. 6. 2 文件属性
Linux系统是一种典型的多用户系统,不同的用户处于不同的地位,拥有不同的权限。为了保护系统的安全性,
Linux系统对不同的用户访问同一文件(包括目录文件)的权限做了不同的规定。在Linux中我们可以使用ll或者ls-l
命令来显示一个文件的属性以及文件所属的用户和组。
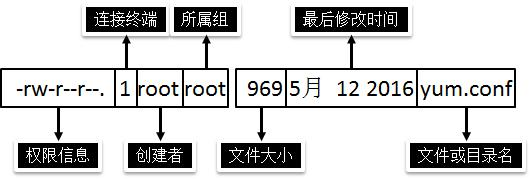
1 )权限信息从左到右的 10 个字符表示:

如果没有权限,就会出现减号[-]而已。从左至右用 0 - 9 这些数字来表示:
( 1 ) 0 首位表示类型
在Linux中第一个字符代表这个文件是目录、文件或链接文件等等
- 代表文件
d 代表目录
l 链接文档(linkfile);
( 2 )第 1 - 3 位确定属主(该文件的所有者)拥有该文件的权限。---User
( 3 )第 4 - 6 位确定属组(所有者的同组用户)拥有该文件的权限,---Group
( 4 )第 7 - 9 位确定其他用户拥有该文件的权限---Other
2 )rxw作用文件和目录的不同解释
字符 目录 文件
r(读) 可以查看目录内容,即ls 读取,查看内容
w(写) 重命名、删除目录中的内容(不是目录本身)、在
目录内创建内容。如果想删除当前目录,必须对当
前目录的父目录有写权限
修改,但是不能删除。只有对该文件的目录有写权限,
才能删除!
x(执行) 进入目录 可以被系统执行
3 )案例实操
[root@hadoop 101 ~]#ll
总用量 104
- rw-------. 1 rootroot 12481 月 817 : 36 anaconda-ks.cfg
drwxr-xr-x. 2 rootroot 40961 月 1214 : 02 dssz
lrwxrwxrwx. 1 rootroot 201 月 1214 : 32 houzi->

xiyou/dssz/houge.txt
( 1 )如果查看到是文件:链接数指的是硬链接个数。创建硬链接方法
ln[原文件][目标文件]
[root@hadoop 101 ~]#lnxiyou/dssz/houge.txt./hg.txt
( 2 )如果查看的是文件夹:链接数指的是子文件夹个数。
[root@hadoop 101 ~]#ls-alxiyou/
总用量 16
drwxr-xr-x. 4 rootroot 40961 月 1214 : 00.
dr-xr-x---. 29 rootroot 40961 月 1214 : 32 ..
drwxr-xr-x. 2 rootroot 40961 月 1214 : 30 dssz
drwxr-xr-x. 2 rootroot 40961 月 1214 : 04 mingjie
7. 6. 3 chmod 改变权限
1 )基本语法:
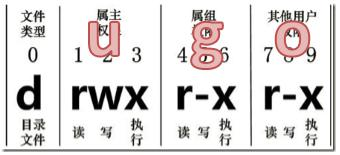
第一种方式变更权限
chmod [{ugoa}{+-=}{rwx}] 文件或目录
第二种方式变更权限
chmod [mode= 421 ] [文件或目录]
2 )经验技巧
u:所有者 g:所有组 o:其他人 a:所有人(u、g、o的总和)
r= 4 w= 2 x= 1 rwx= 4 + 2 + 1 = 7
3 )案例实操
( 1 )修改文件使其所属主用户具有执行权限
[root@hadoop 101 ~]#cpxiyou/dssz/houge.txt./
[root@hadoop 101 ~]#chmodu+xhouge.txt
( 2 )修改文件使其所属组用户具有执行权限
[root@hadoop 101 ~]#chmodg+xhouge.txt
( 3 )修改文件所属主用户执行权限,并使其他用户具有执行权限
[root@hadoop 101 ~]#chmodu-x,o+xhouge.txt
( 4 )采用数字的方式,设置文件所有者、所属组、其他用户都具有可读可写可执行权限。
[root@hadoop 101 ~]#chmod 777 houge.txt
( 5 )修改整个文件夹里面的所有文件的所有者、所属组、其他用户都具有可读可写可执行权限。
[root@hadoop 101 ~]#chmod-R 777 xiyou/
7. 6. 4 chown 改变所有者
1 )基本语法:
chown[选项][最终用户][文件或目录] (功能描述:改变文件或者目录的所有者)
2 )选项说明
选项 功能
- R 递归操作
3 )案例实操
( 1 )修改文件所有者
[root@hadoop 101 ~]#chownatguiguhouge.txt
[root@hadoop 101 ~]#ls-al - rwxrwxrwx. 1 atguiguroot 5515 月 2313 : 02 houge.txt
( 2 )递归改变文件所有者和所有组
[root@hadoop 101 xiyou]#ll
drwxrwxrwx. 2 rootroot 40969 月 321 : 20 xiyou
[root@hadoop 101 xiyou]#chown-Ratguigu:atguiguxiyou/
[root@hadoop 101 xiyou]#ll
drwxrwxrwx. 2 atguiguatguigu 40969 月 321 : 20 xiyou
7. 6. 5 chgrp 改变所属组
1 )基本语法:
chgrp[最终用户组][文件或目录](功能描述:改变文件或者目录的所属组)
2 )案例实操
( 1 )修改文件的所属组
[root@hadoop 101 ~]#chgrproothouge.txt
[root@hadoop 101 ~]#ls-al
- rwxrwxrwx. 1 atguiguroot 5515 月 2313 : 02 houge.txt
7. 7 搜索查找类
7. 7. 1 find 查找文件或者目录
find指令将从指定目录向下递归地遍历其各个子目录,将满足条件的文件显示在终端。
1 )基本语法:
find[搜索范围][选项]
2 )选项说明
选项 功能
- name<查询方式> 按照指定的文件名查找模式查找文件
- user<用户名> 查找属于指定用户名所有文件
- size<文件大小> 按照指定的文件大小查找文件。
3 )案例实操
( 1 )按文件名:根据名称查找/目录下的filename.txt文件。
[root@hadoop 101 ~]#findxiyou/-name*.txt
( 2 )按拥有者:查找/opt目录下,用户名称为-user的文件
[root@hadoop 101 ~]#findxiyou/-useratguigu
( 3 )按文件大小:在/home目录下查找大于 200 m的文件(+n 大于 -n小于 n等于)
[root@hadoop 101 ~]find/home-size+ 204800
7. 7. 2 locate 快速定位文件路径
locate指令利用事先建立的系统中所有文件名称及路径的locate数据库实现快速定位给定的文件。Locate指令
无需遍历整个文件系统,查询速度较快。为了保证查询结果的准确度,管理员必须定期更新locate时刻。
1 )基本语法
locate搜索文件
2 )经验技巧
由于locate指令基于数据库进行查询,所以第一次运行前,必须使用updatedb指令创建locate数据库。
3 )案例实操
( 1 )查询文件夹
[root@hadoop 101 ~]#updated
[root@hadoop 101 ~]#locatetmp
7. 7. 3 grep 过滤查找及 “|” 管道符
0 )管道符,“|”,表示将前一个命令的处理结果输出传递给后面的命令处理
1 )基本语法
grep选项 查找内容 源文件
2 )选项说明
选项 功能
- n 显示匹配行及行号。
3 )案例实操
( 1 )查找某文件在第几行
[root@hadoop 101 ~]#ls|grep-ntest
7. 8 压缩和解压类
7. 8. 1 gzip/gunzip 压缩
1 )基本语法:
gzip 文件 (功能描述:压缩文件,只能将文件压缩为*.gz文件)
gunzip 文件.gz (功能描述:解压缩文件命令)
2 )经验技巧:
( 1 )只能压缩文件不能压缩目录
( 2 )不保留原来的文件
3 )案例实操
( 1 )gzip压缩
[root@hadoop 101 ~]#ls
test.java
[root@hadoop 101 ~]#gziphouge.txt
[root@hadoop 101 ~]#ls
houge.txt.gz
( 2 )gunzip解压缩文件
[root@hadoop 101 ~]#gunziphouge.txt.gz
[root@hadoop 101 ~]#ls
houge.txt
7. 8. 2 zip/unzip 压缩
1 )基本语法:
zip [选项]XXX.zip 将要压缩的内容 (功能描述:压缩文件和目录的命令)
unzip[选项]XXX.zip (功能描述:解压缩文件)
2 )选项说明
zip选项 功能
- r 压缩目录
unzip选项 功能
- d<目录> 指定解压后文件的存放目录
3 )经验技巧
zip 压缩命令在window/linux都通用,可以压缩目录且保留源文件。
4 )案例实操:
( 1 )压缩 1 .txt 和 2 .txt,压缩后的名称为mypackage.zip
[root@hadoop 101 opt]#touchbailongma.txt
[root@hadoop 101 ~]#ziphouma.ziphouge.txtbailongma.txt
adding:houge.txt(stored 0 %)
adding:bailongma.txt(stored 0 %)
[root@hadoop 101 opt]#ls
houge.txtbailongma.txthouma.zip
( 2 )解压 mypackage.zip
[root@hadoop 101 ~]#unziphouma.zip
Archive: houma.zip
extracting:houge.txt
extracting:bailongma.txt
[root@hadoop 101 ~]#ls
houge.txtbailongma.txthouma.zip
( 3 )解压mypackage.zip到指定目录-d
[root@hadoop 101 ~]#unziphouma.zip-d/opt
[root@hadoop 101 ~]#ls/opt/
7. 8. 3 tar 打包
1 )基本语法:
tar [选项] XXX.tar.gz 将要打包进去的内容 (功能描述:打包目录,压缩后的文件格式.tar.gz)
2 )选项说明
选项 功能
- c 产生.tar打包文件
- v 显示详细信息
- f 指定压缩后的文件名
- z 打包同时压缩
- x 解包.tar文件
3 )案例实操
( 1 )压缩多个文件
[root@hadoop 101 opt]#tar-zcvfhouma.tar.gzhouge.txtbailongma.txt
houge.txt
bailongma.txt
[root@hadoop 101 opt]#ls
houma.tar.gzhouge.txtbailongma.txt
( 2 )压缩目录
[root@hadoop 101 ~]#tar-zcvfxiyou.tar.gzxiyou/
xiyou/
xiyou/mingjie/
xiyou/dssz/
xiyou/dssz/houge.txt
( 3 )解压到当前目录
[root@hadoop 101 ~]#tar-zxvfhouma.tar.gz
( 4 )解压到指定目录
[root@hadoop 101 ~]#tar-zxvfxiyou.tar.gz-C/opt
[root@hadoop 101 ~]#ll/opt/
7. 9 磁盘分区类
7. 9. 1 df 查看磁盘空间使用情况
df:diskfree空余硬盘
1 )基本语法:
df 选项(功能描述:列出文件系统的整体磁盘使用量,检查文件系统的磁盘空间占用情况)
2 )选项说明
选项 功能
- h 以人们较易阅读的 GBytes,MBytes,KBytes等格式自行显示;
3 )案例实操
( 1 )查看磁盘使用情况
[root@hadoop 101 ~]#df-h
Filesystem Size UsedAvailUse%Mountedon
/dev/sda 2 15 G 3. 5 G 11 G 26 %/
tmpfs 939 M 224 K 939 M 1 %/dev/shm
/dev/sda 1 190 M 39 M 142 M 22 %/boot
7. 9. 2 fdisk 查看分区
1 )基本语法:
fdisk-l (功能描述:查看磁盘分区详情)
2 )选项说明
选项 功能
- l 显示所有硬盘的分区列表
3 )经验技巧:
该命令必须在root用户下才能使用
4 )功能说明:
( 1 )Linux分区
Device:分区序列
Boot:引导
Start:从X磁柱开始
End:到Y磁柱结束
Blocks:容量
Id:分区类型ID
System:分区类型
( 2 )Win 7 分区
5 )案例实操
( 1 )查看系统分区情况
[root@hadoop 101 /]#fdisk-l
Disk/dev/sda: 21. 5 GB, 21474836480 bytes
255 heads, 63 sectors/track, 2610 cylinders
Units=cylindersof 16065 * 512 = 8225280 bytes
Sectorsize(logical/physical): 512 bytes/ 512 bytes
I/Osize(minimum/optimal): 512 bytes/ 512 bytes
Diskidentifier: 0 x 0005 e 654
DeviceBoot Start End Blocks Id System
/dev/sda 1 * 1 26 204800 83 Linux
Partition 1 doesnotendoncylinderboundary.
/dev/sda 2 26 1332 10485760 83 Linux
/dev/sda 3 1332 1593 2097152 82 Linuxswap/Solaris
7. 9. 3 mount/umount 挂载 / 卸载
对于Linux用户来讲,不论有几个分区,分别分给哪一个目录使用,它总归就是一个根目录、一个独立且唯一的
文件结构。
Linux中每个分区都是用来组成整个文件系统的一部分,它在用一种叫做“挂载”的处理方法,它整个文件系统中
包含了一整套的文件和目录,并将一个分区和一个目录联系起来,要载入的那个分区将使它的存储空间在这个目录
下获得。
0 )挂载前准备(必须要有光盘或者已经连接镜像文件)
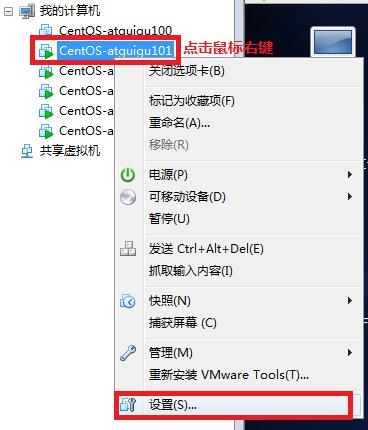
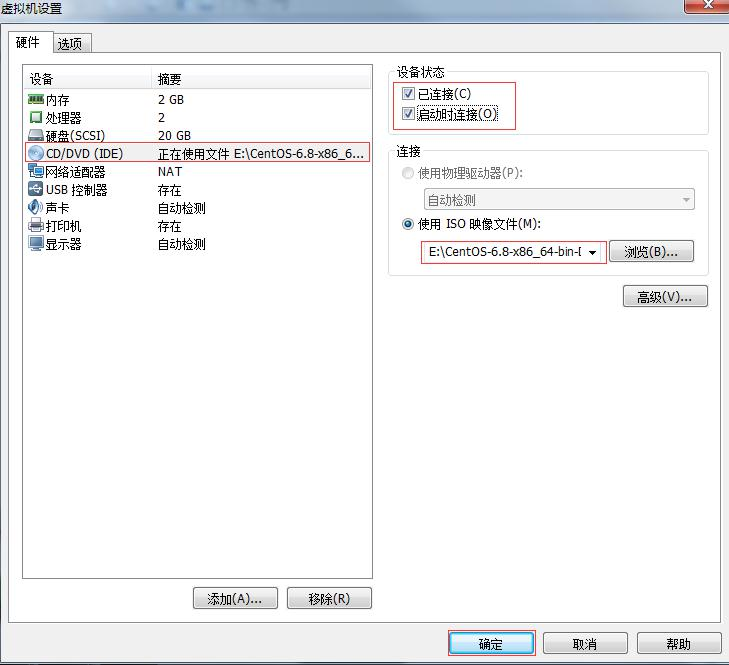
1 )基本语法:
mount[-tvfstype][-ooptions]devicedir (功能描述:挂载设备)
umount 设备文件名或挂载点 (功能描述:卸载设备)
2 )参数说明
参数 功能
- tvfstype 指定文件系统的类型,通常不必指定。mount会自动选择正确的类型。
常用类型有:
光盘或光盘镜像:iso 9660
DOSfat 16 文件系统:msdos
Windows 9 xfat 32 文件系统:vfat
WindowsNTntfs文件系统:ntfs
MountWindows文件网络共享:smbfs
UNIX(LINUX) 文件网络共享:nfs - ooptions 主要用来描述设备或档案的挂接方式。常用的参数有:
loop:用来把一个文件当成硬盘分区挂接上系统
ro:采用只读方式挂接设备
rw:采用读写方式挂接设备
iocharset:指定访问文件系统所用字符集
device 要挂接(mount)的设备
dir 设备在系统上的挂接点(mountpoint)
2 )案例实操
( 1 )挂载光盘镜像文件
[root@hadoop 101 ~]#mkdir/mnt/cdrom/ 建立挂载点
[root@hadoop 101 ~]#mount-tiso 9660 /dev/cdrom/mnt/cdrom/ 设备/dev/cdrom挂载到挂载点 :
/mnt/cdrom中
[root@hadoop 101 ~]#ll/mnt/cdrom/
( 2 )卸载光盘镜像文件
[root@hadoop 101 ~]#umount/mnt/cdrom
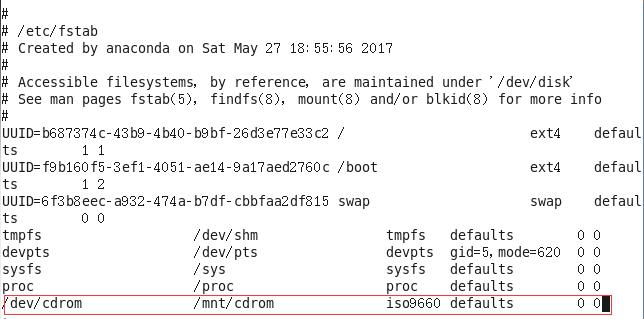
3 )设置开机自动挂载:
[root@hadoop 101 ~]#vi/etc/fstab
添加红框中内容,保存退出。
7. 10 进程线程类
进程是正在执行的一个程序或命令,每一个进程都是一个运行的实体,都有自己的地址空间,并占用一定的系
统资源。
7. 10. 1 ps 查看当前系统进程状态
ps:processstatus进程状态
1 )基本语法:
psaux|grepxxx (功能描述:查看系统中所有进程)
ps-ef|grepxxx (功能描述:可以查看子父进程之间的关系)
2 )选项说明
选项 功能
- a 选择所有进程
- u 显示所有用户的所有进程
- x 显示没有终端的进程
3 )功能说明
( 1 )psaux显示信息说明
USER:该进程是由哪个用户产生的
PID:进程的ID号
%CPU:该进程占用CPU资源的百分比,占用越高,进程越耗费资源;
%MEM:该进程占用物理内存的百分比,占用越高,进程越耗费资源;
VSZ:该进程占用虚拟内存的大小,单位KB;
RSS:该进程占用实际物理内存的大小,单位KB;
TTY:该进程是在哪个终端中运行的。其中tty 1 - tty 7 代表本地控制台终端,tty 1 - tty 6 是本地的字符界面终端,
tty 7 是图形终端。pts/ 0 - 255 代表虚拟终端。
STAT:进程状态。常见的状态有:R:运行、S:睡眠、T:停止状态、s:包含子进程、+:位于后台
START:该进程的启动时间
TIME:该进程占用CPU的运算时间,注意不是系统时间
COMMAND:产生此进程的命令名
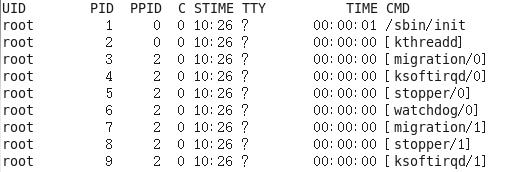
( 2 )ps-ef显示信息说明
UID:用户ID
PID:进程ID
PPID:父进程ID
C:CPU用于计算执行优先级的因子。数值越大,表明进程是CPU密集型运算,执行优先级会降低;数值
越小,表明进程是I/O密集型运算,执行优先级会提高
STIME:进程启动的时间
TTY:完整的终端名称
TIME:CPU时间
CMD:启动进程所用的命令和参数
4 )经验技巧:
如果想查看进程的CPU占用率和内存占用率,可以使用aux;
如果想查看进程的父进程ID可以使用ef;
5 )案例实操
[root@hadoop 101 datas]#psaux

[root@hadoop 101 datas]#ps-ef
7. 10. 2 kill 终止进程
1 )基本语法:
kill [选项]进程号 (功能描述:通过进程号杀死进程)
killall 进程名称 (功能描述:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得
很慢时很有用)
2 )选项说明
选项 功能
- 9 表示强迫进程立即停止
3 )案例实操:
( 1 )杀死浏览器进程
[root@hadoop 101 桌面]#kill- 95102
( 2 )通过进程名称杀死进程
[root@hadoop 101 桌面]#killallfirefox
7. 10. 3 pstree 查看进程树
1 )基本语法:
pstree[选项]
2 )选项说明
选项 功能
- p 显示进程的PID
- u 显示进程的所属用户
3 )案例实操:
( 1 )显示进程pid
[root@hadoop 101 datas]#pstree-p
( 2 )显示进程所属用户
[root@hadoop 101 datas]#pstree-u
7. 10. 4 top 查看系统健康状态
1 )基本命令
top[选项]
2 )选项说明
选项 功能
- d 秒数 指定top命令每隔几秒更新。默认是 3 秒在top命令的交互模式当中
可以执行的命令: - i 使top不显示任何闲置或者僵死进程。
- p 通过指定监控进程ID来仅仅监控某个进程的状态。
3 )操作说明:
操作 功能
P 以CPU使用率排序,默认就是此项
M 以内存的使用率排序
N 以PID排序
q 退出top
4 )查询结果字段解释
第一行信息为任务队列信息
内容 说明
12 : 26 : 46 系统当前时间
up 1 day, 13 : 32 系统的运行时间,本机已经运行 1 天
13 小时 32 分钟
2 users 当前登录了两个用户
load average: 0. 00 , 0. 00 , 0. 00 系统在之前 1 分钟, 5 分钟, 15 分钟的平均负载。
一般认为小于 1 时,负载较小。如果大于 1 ,系
统已经超出负荷。
第二行为进程信息
Tasks: 95 total 系统中的进程总数
1 running 正在运行的进程数
94 sleeping 睡眠的进程
0 stopped 正在停止的进程
0 zombie 僵尸进程。如果不是 0 ,需要手工检查僵尸进程
第三行为CPU信息
Cpu(s): 0. 1 %us 用户模式占用的CPU百分比
0. 1 %sy 系统模式占用的CPU百分比
0. 0 %ni 改变过优先级的用户进程占用的CPU百分比
99. 7 %id 空闲CPU的CPU百分比
0. 1 %wa 等待输入/输出的进程的占用CPU百分比
0. 0 %hi 硬中断请求服务占用的CPU百分比
0. 1 %si 软中断请求服务占用的CPU百分比
0. 0 %st st(Steal time)虚拟时间百分比。就是当有虚拟
机时,虚拟CPU等待实际CPU的时间百分比。
第四行为物理内存信息
Mem: 625344 ktotal 物理内存的总量,单位KB
571504 kused 已经使用的物理内存数量
53840 kfree 空闲的物理内存数量,我们使用的是虚拟机,总
共只分配了 628 MB内存,所以只有 53 MB的空闲
内存了
65800 kbuffers 作为缓冲的内存数量
第五行为交换分区(swap)信息
Swap: 524280 ktotal 交换分区(虚拟内存)的总大小
0 kused 已经使用的交互分区的大小
524280 kfree 空闲交换分区的大小
409280 kcached 作为缓存的交互分区的大小
5 )案例实操
[root@hadoop 101 atguigu]#top-d 1
[root@hadoop 101 atguigu]#top-i
[root@hadoop 101 atguigu]#top-p 2575
执行上述命令后,可以按P、M、N对查询出的进程结果进行排序。
7. 10. 5 netstat 显示网络统计信息
1 )基本语法:
netstat-anp (功能描述:此命令用来显示整个系统目前的网络情况。例如目前的连接、数据包传递数据、
或是路由表内容)
2 )选项说明
选项 功能
- an 按一定顺序排列输出
- p 表示显示哪个进程在调用
3 )案例实操
( 1 )通过进程号查看该进程的网络信息
[root@hadoop 101 hadoop- 2. 7. 2 ]#netstat-anp|grep火狐浏览器进程号
udp 0 0192. 168. 1. 101 : 33893 192. 168. 1. 2 : 53 ESTABLISHED 4043 /firefox
udp 0 0192. 168. 1. 101 : 47416 192. 168. 1. 2 : 53 ESTABLISHED 4043 /firefox
unix 2 [ACC] STREAM LISTENING 28916 4043 /firefox
/tmp/orbit-atguigu/linc-fcb- 0 - 382 f 8 b 667 a 38 a
unix 3 [] STREAM CONNECTED 28919 4043 /firefox
/tmp/orbit-atguigu/linc-fcb- 0 - 382 f 8 b 667 a 38 a
7. 11 crond 系统定时任务
7. 11. 1 crond 服务管理
1 )重新启动crond服务
[root@hadoop 101 ~]#servicecrondrestart
7. 11. 2 crontab 定时任务设置
1 )基本语法
crontab[选项]
2 )选项说明
选项 功能
- e 编辑crontab定时任务
- l 查询crontab任务
- r 删除当前用户所有的crontab任务
3 )参数说明
[root@hadoop 101 ~]#crontab-e
( 1 )进入crontab编辑界面。会打开vim编辑你的工作。
***** 执行的任务
项目 含义 范围
第一个“” 一小时当中的第几分钟 0 - 59
第二个“” 一天当中的第几小时 0 - 23
第三个“” 一个月当中的第几天 1 - 31
第四个“” 一年当中的第几月 1 - 12
第五个“*” 一周当中的星期几 0 - 7 ( 0 和 7 都代表星期日)
( 2 )特殊符号
特殊符号 含义
* 代表任何时间。比如第一个“*”就代表一小时中每分钟都执
行一次的意思。
, 代表不连续的时间。比如“ 08 , 12 , 16 ***命令”,就代表在
每天的 8 点 0 分, 12 点 0 分, 16 点 0 分都执行一次命令
- 代表连续的时间范围。比如“ 05 * * 1 - 6 命令”,代表在
周一到周六的凌晨 5 点 0 分执行命令
/n 代表每隔多久执行一次。比如“/ 10 * * * * 命令”,
代表每隔 10 分钟就执行一遍命令
( 3 )特定时间执行命令
时间 含义
4522 ***命令 每天 22 点 45 分执行命令
017 ** 1 命令 每周 1 的 17 点 0 分执行命令
051 , 15 **命令 每月 1 号和 15 号的凌晨 5 点 0 分执行命令
404 ** 1 - 5 命令 每周一到周五的凌晨 4 点 40 分执行命令
*/ 104 ***命令 每天的凌晨 4 点,每隔 10 分钟执行一次命令
001 , 15 * 1 命令 每月 1 号和 15 号,每周 1 的 0 点 0 分都会执行命令。注意:
星期几和几号最好不要同时出现,因为他们定义的都是天。
非常容易让管理员混乱。
4 )案例实操:
( 1 )每隔 1 分钟,向/root/bailongma.txt文件中添加一个 11 的数字
*/ 1 ****/bin/echo” 11 ”>>/root/bailongma.txt
第 8 章 添加硬盘
8. 1 添加硬盘
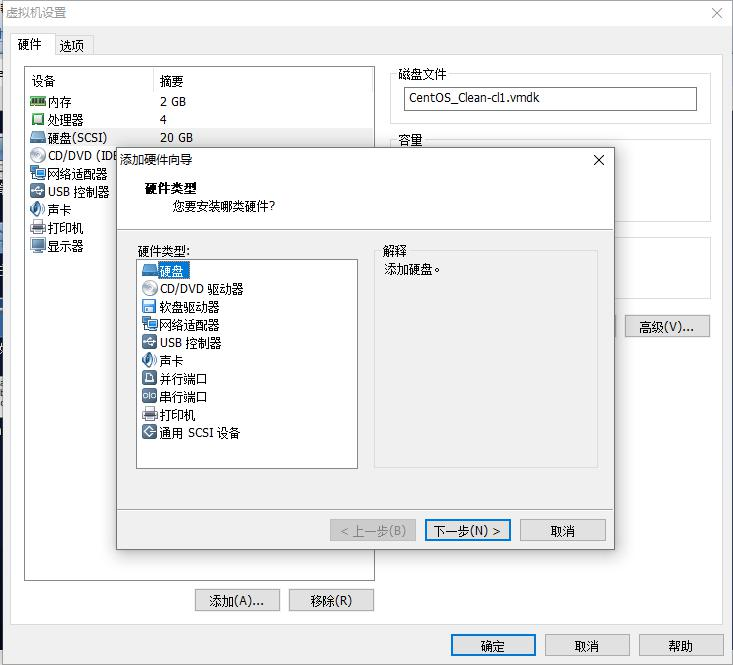
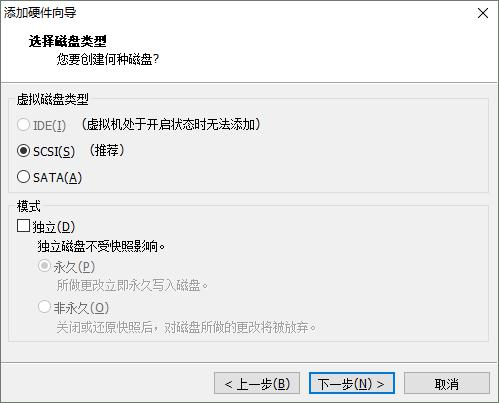
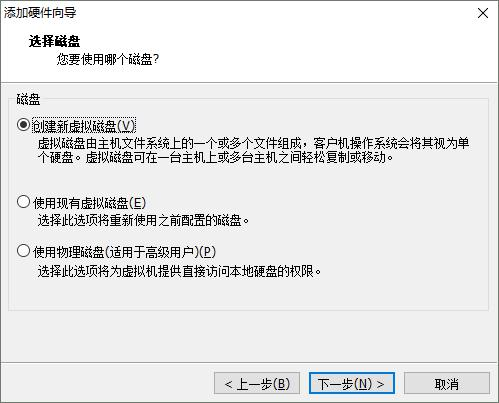
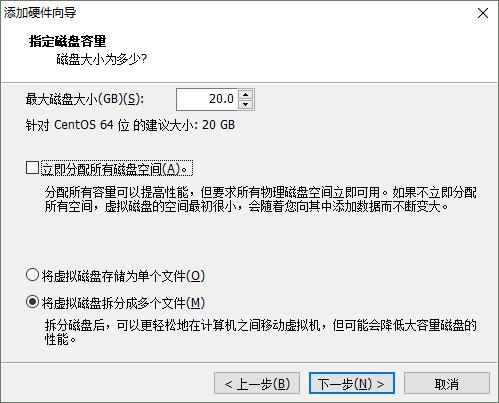
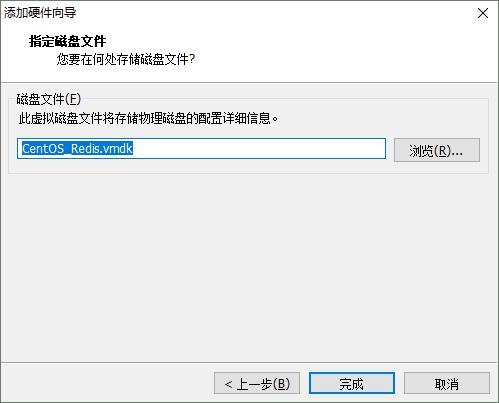

8. 2 查看磁盘状态
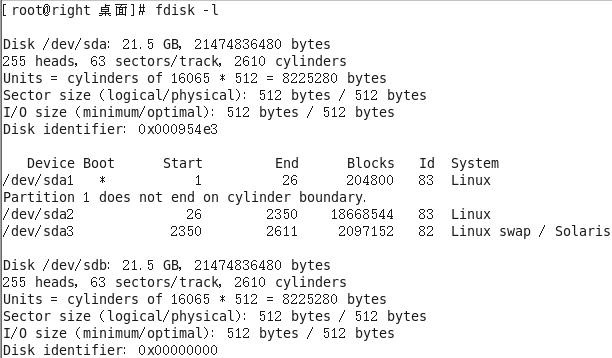
使用fdisk-l,查看磁盘状态。新添加的硬盘,需要重启后,才可以看到。
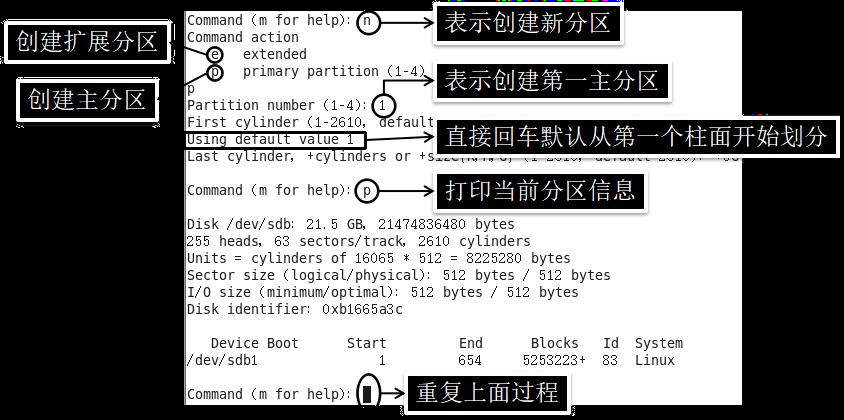
8. 3 对 /dev/sdb 进行分区
分区命令: fdisk/dev/sdb
m 显示命令列表
p 显示磁盘分区,同fdisk–l
n 新增分区
d 删除分区
w 写入并退出
步骤:执行fdisk/dev/sdb命令后,输入n,新增分区,然后选择p,分区类型为主分区。两次回车默认剩余全
部空间。最后输入w写入分区并退出,如果不保存退出就输入q。
8. 4 格式化分区
命令: mkfs–text 4 /dev/sdb 1
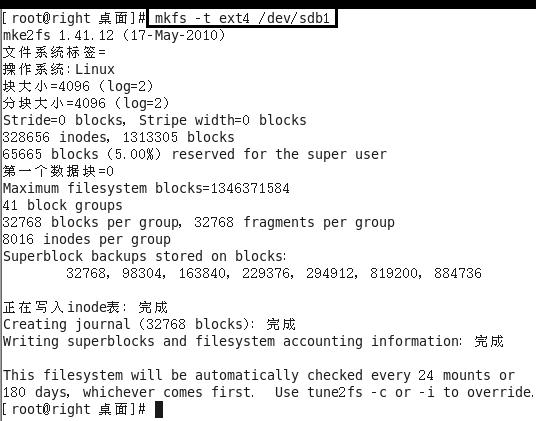
注意:扩展分区不格式化,要格式化的是逻辑分区
8. 5 创建目录用于挂载分区
查看当前分区的挂载情况: df–h

临时挂载: mount[设备名][指定目录]

系统reboot后会丢失,还需要重新挂载。
永久挂载:编辑/etc/fstab文件。

文件说明:
第一列:通过blkid命令查看UUID值

第二列:挂载目录
第三列:文件系统类型
第四列:参数
第五列:是否备份, 0 表示不备份
第六列:加载顺序,只有引导分区可以设置为 1 ,其他分区选择 0 或 2 。
编辑完成后,执行mount–a立即生效!
第 9 章 安装软件
9. 1 RPM
9. 1. 1 RPM 概述
RPM(RedHatPackageManager),Rethat软件包管理工具,类似windows里面的setup.exe
是Linux这系列操作系统里面的打包安装工具,它虽然是RedHat的标志,但理念是通用的。
RPM包的名称格式
Apache- 1. 3. 23 - 11 .i 386 .rpm
- “apache”软件名称
- “ 1. 3. 23 - 11 ”软件的版本号,主版本和此版本
- “i 386 ”是软件所运行的硬件平台
- “rpm”文件扩展名,代表RPM包
9. 1. 2 RPM 查询命令( rpm-qa )
1 )基本语法:
rpm-qa (功能描述:查询所安装的所有rpm软件包)
2 )经验技巧:
由于软件包比较多,一般都会采取过滤。rpm-qa|greprpm软件包
3 )案例实操
( 1 )查询firefox软件安装情况
[root@hadoop 101 Packages]#rpm-qa|grepfirefox
firefox- 45. 0. 1 - 1 .el 6 .centos.x 86 _ 64
9. 1. 3 RPM 卸载命令( rpm-e )
1 )基本语法:
( 1 )rpm-eRPM软件包
( 2 )rpm-e--nodeps软件包
2 )选项说明
选项 功能
- e 卸载软件包
- -nodeps 卸载软件时,不检查依赖。这样的话,那些使用该软件包的软件在
此之后可能就不能正常工作了。
3 )案例实操
( 1 )卸载firefox软件
[root@hadoop 101 Packages]#rpm-efirefox
9. 1. 4 RPM 安装命令( rpm-ivh )
1 )基本语法:
rpm-ivhRPM包全名
2 )选项说明
选项 功能
- i -i=install,安装
- v -v=verbose,显示详细信息
- h -h=hash,进度条
- -nodeps --nodeps,不检测依赖进度
3 )案例实操
( 1 )安装firefox软件
[root@hadoop 101 Packages]#pwd
/media/CentOS_ 6. 8 _Final/Packages
[root@hadoop 101 Packages]#rpm-ivhfirefox- 45. 0. 1 - 1 .el 6 .centos.x 86 _ 64 .rpm
warning:firefox- 45. 0. 1 - 1 .el 6 .centos.x 86 _ 64 .rpm:HeaderV 3 RSA/SHA 1 Signature,keyIDc 105 b 9 de:NOKEY
Preparing... ###########################################[ 100 %]
1 :firefox ###########################################[ 100 %]
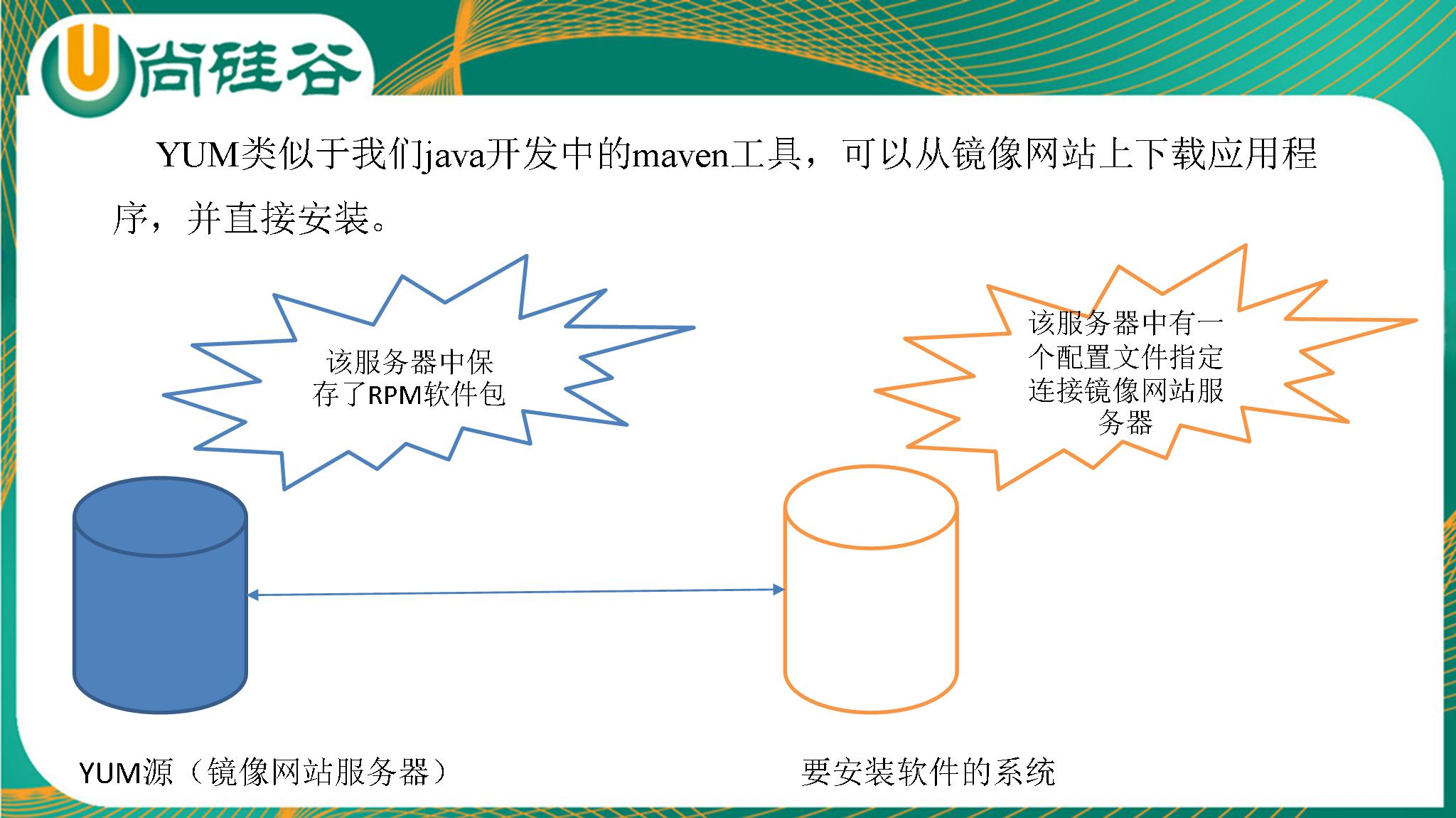
9. 2 YUM
9. 2. 1 YUM 概述
YUM(全称为YellowdogUpdater,Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理
器。基于RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装
所有依赖的软件包,无须繁琐地一次次下载、安装。
9. 2. 2 YUM 的常用命令
1 )基本语法:
yum[选项][参数]
2 )选项说明
选项 功能
- y 对所有提问都回答“yes”
3 )参数说明
参数 功能
install 安装rpm软件包
update 更新rpm软件包
—————————————————————————————————————
81
check-update 检查是否有可用的更新rpm软件包
remove 删除指定的rpm软件包
list 显示软件包信息
clean 清理yum过期的缓存
deplist 显示yum软件包的所有依赖关系
4 )案例实操实操
( 1 )采用yum方式安装tree软件
[root@hadoop 101 ~]#yum-yinstalltree
第 10 章 开发环境搭建
10. 1 安装 JDK
①上传tar包到服务器
②解压tar包到指定目录/opt
③配置环境变量vim /etc/profile
JAVA_HOME=/opt/jdk 1. 7. 0 _ 79
PATH=/opt/jdk 1. 7. 0 _ 79 /bin:$PATH
exportJAVA_HOMEPATH
④使新的配置文件生效:source/etc/profile
说明:
“:”是多个值之间的分隔符;
“$”用来引用环境变量。“:$PATH”表示把系统原有的PATH环境变量的值追加进来以免我们设置的值覆盖系
统默认值;
“export”表示发布新配置的环境变量;
10. 2 安装 Tomcat
①上传并解压缩到/opt
②启动tomcat ./startup.sh
问题:
在Windows系统中通过浏览器访问Linux系统上的Tomcat会发现无法访问。但在Linux系统内部明明是可以访
问的,原因就是Linux系统自带的防火墙没有开放 8080 端口的访问权限。
解决:
①查看防火墙配置文件:/etc/sysconfig/iptables
②开放 8080 端口:复制第 10 行,把 22 修改为 8080 ,保存退出
③重启防火墙服务:serviceiptablesrestart
或者,一劳永逸第关闭防火墙!