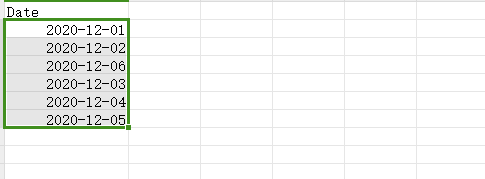
测试数据
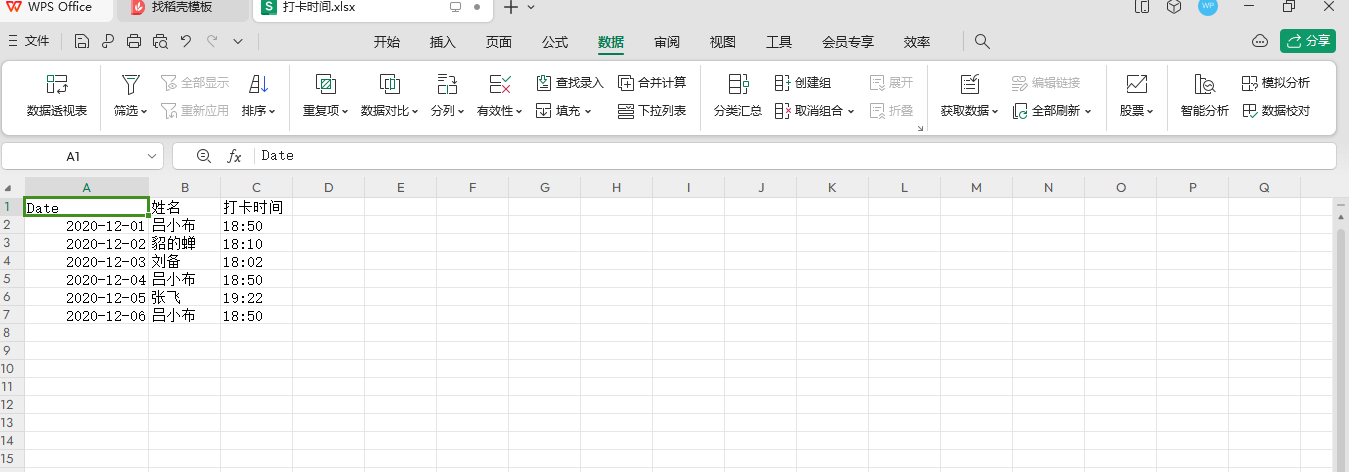
上代码:
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
def dum():
wb = load_workbook("C:/Users/admin/Desktop/打卡时间.xlsx")
sh = wb.active
##存储哪一行的重复数据
index = []
tmp = [] #没有重复的数据
for i,c in enumerate(sh['B']):
flag = c.value not in tmp
print(flag,f'===={c}========={tmp}')
if flag:
#if c not in tmp:
tmp.append(c.value)
else:
index.append(i)
fill = PatternFill('solid',fgColor='AEEEEE')
for i,r in enumerate(sh.rows):
if i in index:
for c in r:
c.fill = fill
print(f'第{i+1}条数据是重复的')
wb.save('C:/Users/admin/Desktop/重复shuju.xlsx')
if __name__ == "__main__":
dum()
实现效果:
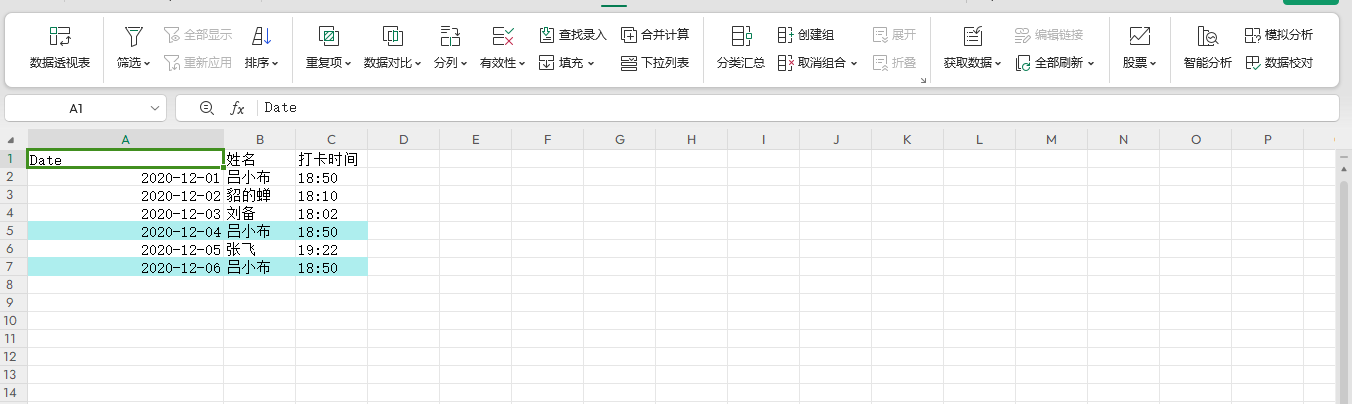
###################################删除重复值
from openpyxl import load_workbook
from openpyxl.styles import PatternFill
def dum():
wb = load_workbook("C:/Users/admin/Desktop/打卡时间.xlsx")
sh = wb.active
## 创建一个集合来存放已经遇到过的值
seen_values = set()
# 从最后一行开始向上遍历每一行
for row in range(sh.max_row, 0, -1):
for column in sh[row]:
value = str(column.value) # 将单元格内容转换为字符串类型
if value not in seen_values and value != '':
seen_values.add(value)
else:
# 移动当前行并删除该行
sh.delete_rows(row)
wb.save('C:/Users/admin/Desktop/delete.xlsx')
if __name__ == "__main__":
dum()
测试数据:

获得的结果: