- 背景
今天有同事问我一道关于数据库SQL的面试题,我刚开始随便给了一个思路,后来思索发现这个思路有漏洞,于是总结下来,仅供参考。
问题: 薪水表中是员工薪水的基本信息,包括雇员编号,和薪水,查询除去最高、最低薪水后的平均薪水。
- 一、薪水表信息
CREATE TABLE `salaries` ( `emp_no` int NOT NULL, `salary` int NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
测试数据如下:
INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (10003, 6000); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (10004, 6000); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (10001, 6000); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (10006, 6100); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (10005, 6900); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (10008, 7100); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100010, 7400); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100013, 7500); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100014, 7500); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100015, 7688); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100018, 8000); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100020, 8100); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100028, 8200); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100026, 8400); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100035, 8500); INSERT INTO `salaries`(`emp_no`, `salary`) VALUES (100038, 8500);
- 二、查询分析
思路1、最容易想到的方法,就是查询到薪水的最大值和最小值。然后从薪水中排除掉这两个,计算平均值即可。
select avg(salary) from salaries where salary not in ( (select min(salary) from salaries), (select max(salary) from salaries) ) ;
思路2、使用开窗函数Max() Over() 和 Min() Over() 求出最大值,然后排除掉这两个,再计算平均值。
select avg(salary) from ( select emp_no,salary, min(salary) over() min_sal, max(salary) over() max_sal from salaries ) x where salary not in (min_sal,max_sal) ;
思路3 、直接使用数学方法,平均值 = (求和-最大值-最小值)/ (总个数-2)
select (sum(salary)-min(salary)-max(salary))/(count(*)-2)
from salaries ;
思路4、使用一次row_number() over 窗口函数和count() over 函数,count窗口函数统计表中所有记录数,使用row_number窗口函数按照薪水升序排列,排序结果 = 1 即为最小值,排序结果 = count出的结果 即为最大值。
select avg(salary) from ( select emp_no, salary, count(*) over() num , row_number() over(order by salary asc) rn from salaries ) T where rn <> 1 and rn <> num ;
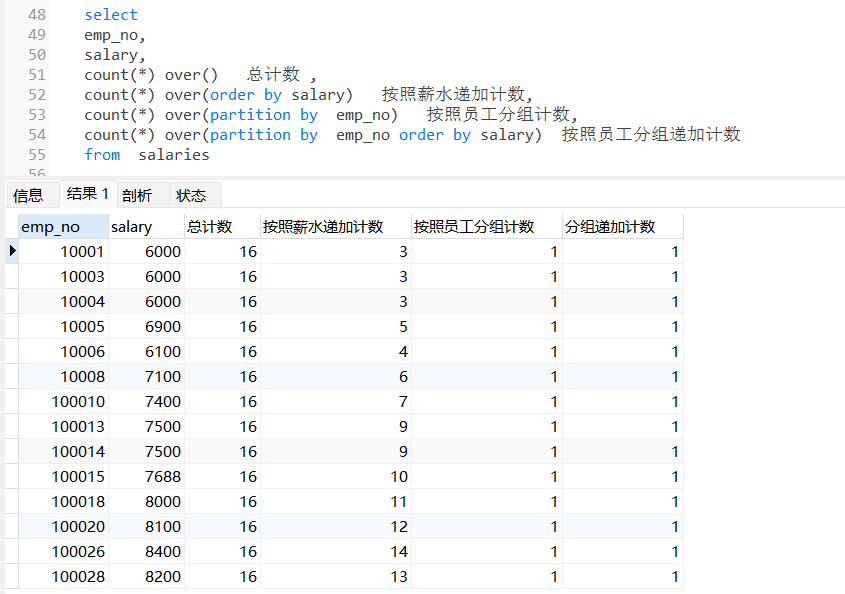
说明:
count(*)over() 求总计数, count(*)over(order by A...) 递加求计数, count(*)over(partition by A...) 分组求计数, count(*)over(partition by A...order by b...) 分组递加求计数
查询看下这四个统计结果
思路5、使用两次row_number() over 窗口函数,一个按照薪水升序,一个按照薪水降序,过滤掉第一个即去掉最大值和最小值。
select avg(salary) from ( select emp_no, salary, row_number() over(order by salary desc) rn_desc, row_number() over(order by salary asc) rn_asc from salaries ) T where rn_desc > 1 and rn_asc > 1 ;
总结: 我们在执行这5个SQL语句后,会发现统计出的平均值不一样,原因就在于:薪水表中最高薪水的人和最低薪水的人都不止一个。
前2个思路会将所有最高薪水和最低薪水全部去除,求得平均值。然而,思路3、4、5都只是去除一个最高薪水和一个最低薪水,然后求平均值。所以才导致计算出的结果不一致。