结论:
Text File,Parquet ,ORC Files结合使用,优先使用前两种,对存储及查询性能有极高要求时使用ORC。
|
存储格式
|
使用场景
|
|---|---|
| Text File | 数据直观,便于查看和编辑,数据量较小的维表可以使用. |
| Parquet |
支持深度嵌套,可用于多种数据处理框架(Hive/Spark/Flink/MapReduce/Impala/Presto等),Flink1.9版本已经支持此数据结构(已验证),能解决Hive行分隔符(默认\n)不能替换问题。 适用于字段数较多的宽表。 |
| ORC Files | 存储及查询效率最好,Flink1.11版本之后才有支持,目前只能自己实现ORC Writer。 |
压缩格式一般使用snappy或lzo,使用压缩节省磁盘并检索IO占用情况,但会增加CPU消耗(性能情况需要实际数据情况验证),前期数据量不多时可以先不开启。
File Formats
Hive supports several file formats:
- Text File
- SequenceFile
- RCFile
- Avro Files
- ORC Files
- Parquet
- Custom INPUTFORMAT and OUTPUTFORMAT
|
格式
|
描述
|
|---|---|
| Text File | 每一行都是一条记录,每行都以换行符(\ n)结尾。数据不做压缩,磁盘开销大,数据解析开销大。 |
| SequenceFile | 是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。支持三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩。 |
| RCFile | 是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。 |
| Avro Files | 为Hadoop提供数据序列化和数据交换服务。您可以在Hadoop生态系统和以任何编程语言编写的程序之间交换数据。 |
| ORC Files | ORC文件代表了优化排柱状的文件格式。ORC文件格式提供了一种将数据存储在Hive表中的高效方法。这个文件系统实际上是为了克服其他Hive文件格式的限制而设计的。Hive从大型表读取,写入和处理数据时,使用ORC文件可以提高性能。 |
| Parquet | Parquet是一个面向列的二进制文件格式。Parquet对于大型查询的类型是高效的。对于扫描特定表格中的特定列的查询,Parquet特别有用。Parquet桌子使用压缩Snappy,gzip;目前Snappy默认。 |
| Custom INPUTFORMAT and OUTPUTFORMAT | 暂不调研 |
|
格式
|
存储方式
|
业内使用情况
|
优缺点及使用场景
|
|---|---|---|---|
| Text File | 行存储 | 常用 | 数据直观,便于查看和编辑,数据量较小的维表可以使用。 |
| SequenceFile | 行存储 | 几乎不用 | k-v格式,比源文本格式占用磁盘更多,对于Hadoop生态系统之外的工具不适用,需要通过text文件转化加载。 |
| RCFile | 行列混合存储 | 较少 | 加载时性能消耗较大,需要通过text文件转化加载;读取全量数据性能低。 |
| Avro Files | - | 较少 | 数据传输交换时使用较多。 |
| ORC Files | 列存储 | 常用 | 优化后的rcfile,列式存储,有多种文件压缩方式,并且有着很高的压缩比,适用于Hive中大型的存储、查询。Flink1.11版本之后才有支持,目前只能自己实现ORC Writer。 |
| Parquet | 列存储 | 常用 |
高效的压缩和编码,支持深度嵌套,不与任何数据处理技术绑定,可用于多种数据处理框架(Hive/Spark/Flink/MapReduce/Impala/Presto等),适用于字段数较多的宽表进行部分列的查询。解决Hive行分隔符(默认\n)不能替换问题。 |
| Custom INPUTFORMAT and OUTPUTFORMAT | - | 几乎不用 |
注意: 一般来说Hive的默认行分隔符都是换行符,如果非要自定义行分隔符的话,可以通过自定义Inputformat和outputformat类来指定特定行分隔符和列分隔符。
行式存储和列式存储
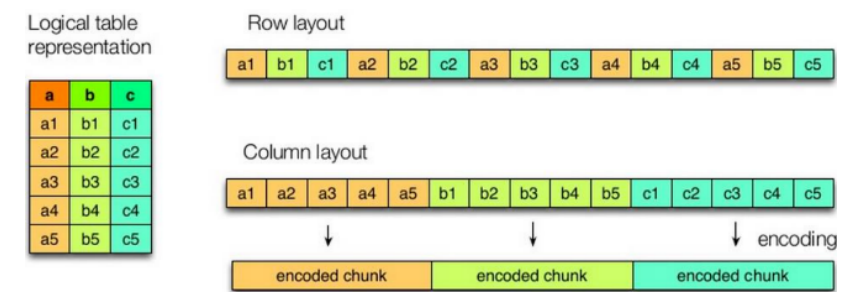
行存储
列存储
|
存储方式
|
压缩比较
|
查询比较
|
|---|---|---|
| 行式存储 | 按照行压缩,由于一行中有多个字段,而且字段类型有可能不一样,所有压缩性能差 | 查询一张表中的某几个字段,由于是行式存储而进行全表扫描,查询慢。 |
| 列式存储 | 每一列对应的相同的数据格式,所以压缩性能好 | 查询一张表中的某几个字段,由于是列式存储不需要全表扫描查询快,但如果是select * from table 这种反之慢,因为列式存储查询出结果还要组装数据。 |
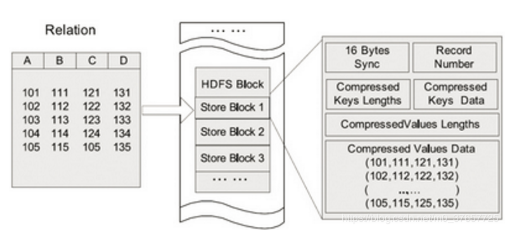
RCFile存储结构
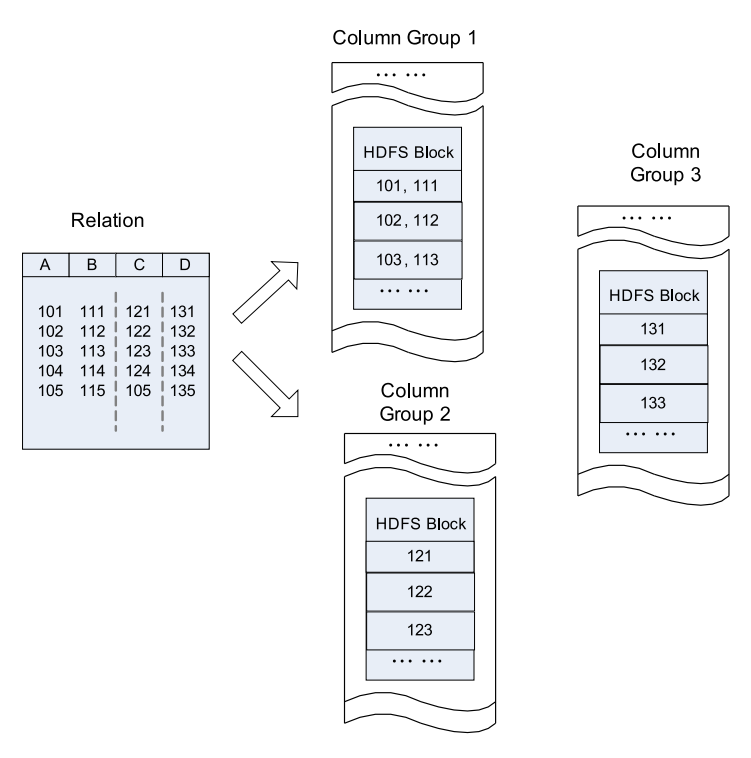
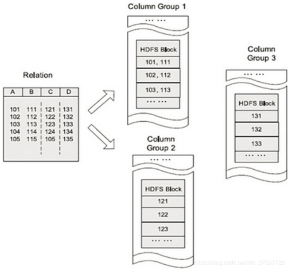
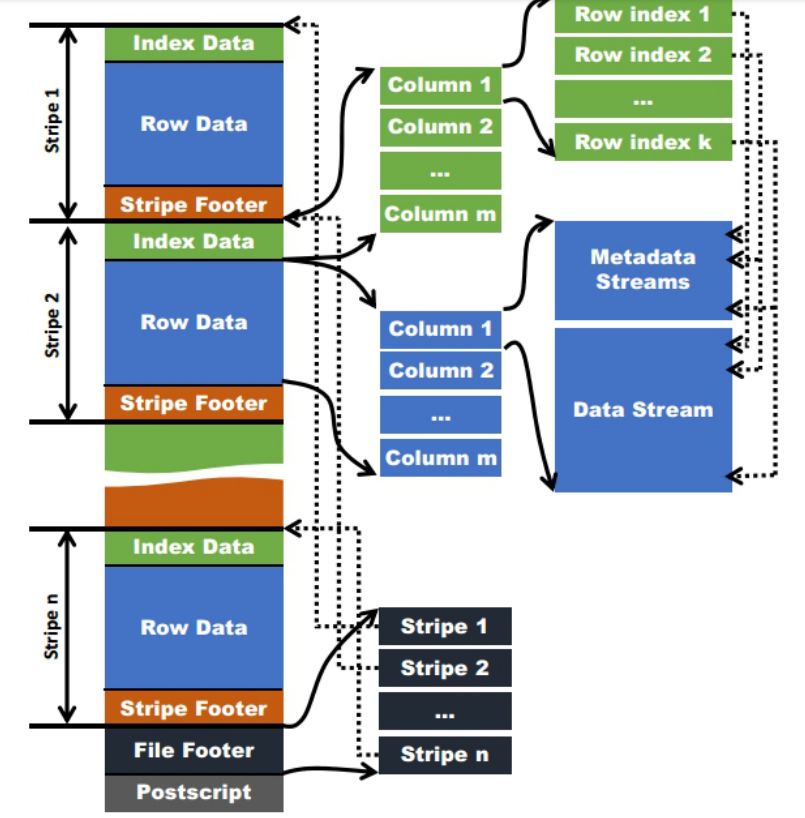
ORC存储结构
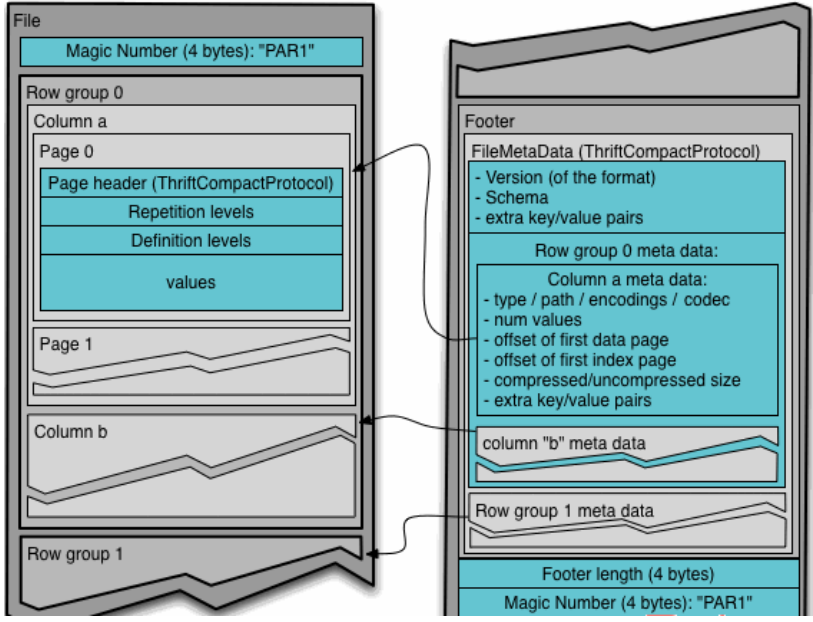
Parquet存储结构
性能测试
以下是网上搜集的性能测试结果,可供参考。
1.
测试数据大小:100G
测试Sql: select visitdate,count(*) as pv from 表名 where action = '1' and domain = 'static.scms.sztv.com.cn' group by visitdate order by pv;
测试环境:
|
存储格式
|
ORC
|
Sequencefile
|
Parquet
|
RCfile
|
Avro
|
|---|---|---|---|---|---|
| 压缩后大小 | 1.8G | 67.0G | 11G | 63.8G | 66.7G |
| 存储耗费时间 | 535.7s | 625.8s | 537.3s | 543.48s | 544.3s |
| SQL查询响应速度 | 19.63s | 184.07s | 24.22s | 88.5s | 281.65s |
2.
|
存储格式
|
Parquet
|
ORC
|
Text
|
|---|---|---|---|
| 数据大小 | 709M | 275M | 1G |
| 查询速度 | 36.451 | 26.133 | 42.574 |
参考:
https://cwiki.apache.org/confluence/display/Hive/FileFormats
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
https://zhuanlan.zhihu.com/p/141908285
https://www.cnblogs.com/panpanwelcome/p/10248990.html
orcfile : https://www.cnblogs.com/ITtangtang/p/7677912.html