pandas
pandas介绍
Pandas 是一个开源的数据分析和数据处理库,它是基于 Python 编程语言的。
Pandas 提供了易于使用的数据结构和数据分析工具,特别适用于处理结构化数据,如表格型数据(类似于Excel表格)。
Pandas 是数据科学和分析领域中常用的工具之一,它使得用户能够轻松地从各种数据源中导入数据,并对数据进行高效的操作和分析。
Pandas 主要引入了两种新的数据结构:DataFrame 和 Series
-
Series: 类似于一维数组或列表,是由一组数据以及与之相关的数据标签(索引)构成。Series 可以看作是 DataFrame 中的一列,也可以是单独存在的一维数据结构。
-
DataFrame: 类似于一个二维表格,它是 Pandas 中最重要的数据结构。DataFrame 可以看作是由多个 Series 按列排列构成的表格,它既有行索引也有列索引,因此可以方便地进行行列选择、过滤、合并等操作。
Pandas 提供了丰富的功能,包括:
- 数据清洗:处理缺失数据、重复数据等。
- 数据转换:改变数据的形状、结构或格式。
- 数据分析:进行统计分析、聚合、分组等。
- 数据可视化:通过整合 Matplotlib 和 Seaborn 等库,可以进行数据可视化。
pandas安装
-
安装python
官网下载/docker安装
-
安装pandas
pip install pandas验证使用:
import pandas as pd pd.__version__
pandas series
结构
- 索引: 每个 Series 都有一个索引,它可以是整数、字符串、日期等类型。如果没有显式指定索引,Pandas 会自动创建一个默认的整数索引。
- 数据类型: Series 可以容纳不同数据类型的元素,包括整数、浮点数、字符串等。
pandas.Series( data, index, dtype, name, copy)
## data:一组数据(ndarray 类型)。
## index:数据索引标签,如果不指定,默认从 0 开始。
## dtype:数据类型,默认会自己判断。
## name:设置名称。
## copy:拷贝数据,默认为 False。
实例
-
使用series
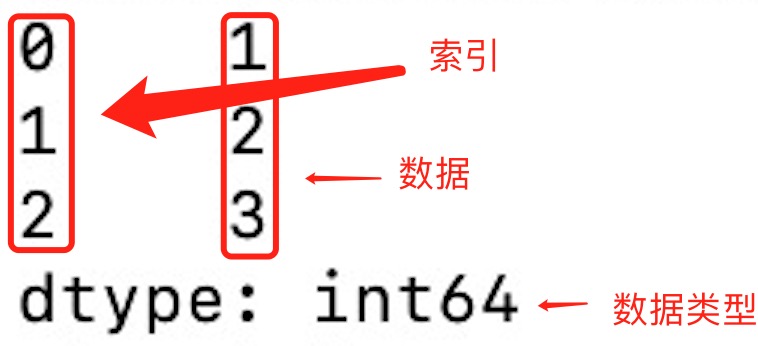
import pandas as pd a = [1, 2, 3] myvar = pd.Series(a) print(myvar) print(myvar[1])输出为:
-
使用pd.Series设置索引
import pandas as pd a = ["Google", "Runoob", "Wiki"] myvar = pd.Series(a, index = ["x", "y", "z"]) print(myvar) print(myvar["y"]) -
通过字典来创建
import pandas as pd sites = {1: "Google", 2: "Runoob", 3: "Wiki"} myvar = pd.Series(sites) print(myvar) myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" ) print(myvar) myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" ) print(myvar)
基本操作
-
基本操作
## 获取值 value = series[2] ## 获取索引为2的值 ## 获取多个值 subset = series[1:4] ## 获取索引为1到3的值 ## 使用自定义索引 value = series_with_index['b'] ## 获取索引为'b'的值 ## 索引和值的对应关系 for index, value in series_with_index.items(): print(f"Index: {index}, Value: {value}") -
基本运算
## 算术运算 result = series * 2 ## 所有元素乘以2 ## 过滤 filtered_series = series[series > 2] ## 选择大于2的元素 ## 数学函数 import numpy as np result = np.sqrt(series) ## 对每个元素取平方根 -
属性和方法
## 获取索引 index = series_with_index.index ## 获取值数组 values = series_with_index.values ## 获取描述统计信息 stats = series_with_index.describe() ## 获取最大值和最小值的索引 max_index = series_with_index.idxmax() min_index = series_with_index.idxmin() -
注意事项
- Series 中的数据是有序的。
- 可以将 Series 视为带有索引的一维数组。
- 索引可以是唯一的,但不是必须的。
- 数据可以是标量、列表、NumPy 数组等。
pandas dataframe
dataframe结构
- 列和行: DataFrame 由多个列组成,每一列都有一个名称,可以看作是一个 Series。同时,DataFrame 有一个行索引,用于标识每一行。
- 二维结构: DataFrame 是一个二维表格,具有行和列。可以将其视为多个 Series 对象组成的字典。
- 列的数据类型: 不同的列可以包含不同的数据类型,例如整数、浮点数、字符串等。
pandas.DataFrame( data, index, columns, dtype, copy)
# data:一组数据(ndarray、series, map, lists, dict 类型)。
# index:索引值,或者可以称为行标签
# columns:列标签,默认为 RangeIndex (0, 1, 2, …, n)
# dtype:数据类型,默认会自己判断。
# copy:拷贝数据,默认为 False。
dataframe实例
-
使用dataframe
import pandas as pd data = [['Google',10],['Runoob',12],['Wiki',13]] df = pd.DataFrame(data,columns=['Site','Age']) print(df) -
使用ndarrays创建
import pandas as pd data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]} df = pd.DataFrame(data) print (df) -
通过字典来创建
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] df = pd.DataFrame(data) print (df)没有对应的部分数据为 NaN。
-
通过loc返回指定行
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推import pandas as pd data = { "calories": [420, 380, 390], "duration": [50, 40, 45] } # 数据载入到 DataFrame 对象 df = pd.DataFrame(data) # 返回第一行 print(df.loc[0]) # 返回第二行 print(df.loc[1]) # 返回第一行和第二行 print(df.loc[[0, 1]]) # 指定索引 print(df.loc["duration"]) -
pd.DataFrame指定索引
import pandas as pd data = { "calories": [420, 380, 390], "duration": [50, 40, 45] } df = pd.DataFrame(data, index = ["day1", "day2", "day3"]) print(df)
dataframe基本操作
-
基本操作
# 获取列 name_column = df['Name'] # 获取行 first_row = df.loc[0] # 选择多列 subset = df[['Name', 'Age']] # 过滤行 filtered_rows = df[df['Age'] > 30] -
数据操作
# 添加新列 df['Salary'] = [50000, 60000, 70000] # 删除列 df.drop('City', axis=1, inplace=True) # 排序 df.sort_values(by='Age', ascending=False, inplace=True) # 重命名列 df.rename(columns={'Name': 'Full Name'}, inplace=True) -
属性和方法
# 获取列名 columns = df.columns # 获取形状(行数和列数) shape = df.shape # 获取索引 index = df.index # 获取描述统计信息 stats = df.describe() -
外部数据源创建
# 从CSV文件创建 DataFrame df_csv = pd.read_csv('example.csv') # 从Excel文件创建 DataFrame df_excel = pd.read_excel('example.xlsx') # 从字典列表创建 DataFrame data_list = [{'Name': 'Alice', 'Age': 25}, {'Name': 'Bob', 'Age': 30}] df_from_list = pd.DataFrame(data_list) -
注意事项
- DataFrame 是一种灵活的数据结构,可以容纳不同数据类型的列。
- 列名和行索引可以是字符串、整数等。
- DataFrame 可以通过多种方式进行数据选择、过滤、修改和分析。
- 通过对 DataFrame 的操作,可以进行数据清洗、转换、分析和可视化等工作。
pandas CSV
介绍
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
-
处理csv
Pandas 可以很方便的处理 CSV 文件import pandas as pd df = pd.read_csv('site.csv') print(df.to_string()) -
存储csv
可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件import pandas as pd # 三个字段 name, site, age nme = ["Google", "Runoob", "Taobao", "Wiki"] st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"] ag = [90, 40, 80, 98] # 字典 dict = {'name': nme, 'site': st, 'age': ag} df = pd.DataFrame(dict) # 保存 dataframe df.to_csv('site.csv')
数据处理
head()
head(n) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head())
print(df.head(10))
tail()
tail(n) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail())
print(df.tail(10))
info()
info() 方法返回表格的一些基本信息:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
Pandas JSON
JSON(JavaScript Object Notation,JavaScript 对象表示法),是存储和交换文本信息的语法,类似 XML。
JSON 比 XML 更小、更快,更易解析,更多 JSON 内容可以参考 JSON 教程。
Pandas 可以很方便的处理 JSON 数据
普通JSON处理
import pandas as pd
df = pd.read_json('sites.json')
print(df.to_string())
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df)
JSON 对象与 Python 字典具有相同的格式,所以我们可以直接将 Python 字典转化为 DataFrame 数据
内嵌JSON处理
使用 json_normalize() 方法将内嵌的数据完整的解析出来
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_list.json','r') as f:
data = json.loads(f.read())
# 展平数据
df_nested_list = pd.json_normalize(data, record_path =['students'])
print(df_nested_list)
更加复杂的数据
import pandas as pd
import json
# 使用 Python JSON 模块载入数据
with open('nested_mix.json','r') as f:
data = json.loads(f.read())
df = pd.json_normalize(
data,
record_path =['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df)
读取内嵌JSON中的一组数据
使用 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性
-
安装glom
pip3 install glom -
使用
import pandas as pd from glom import glom df = pd.read_json('nested_deep.json') data = df['students'].apply(lambda row: glom(row, 'grade.math')) print(data)
数据清洗
清洗空值
如果我们要删除包含空字段的行,可以使用 dropna() 方法,语法格式如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
# axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
# how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
# thresh:设置需要多少非空值的数据才可以保留下来的。
# subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
# inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
可以通过 isnull() 判断各个单元格是否为空。
在pandas.read_csv中可以指定na_values来指定空值
import pandas as pd
df = pd.read_csv('property-data.csv')
print(df['NUM_BEDROOMS'])
print(df['NUM_BEDROOMS'].isnull())
# 指定空数据
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
print (df['NUM_BEDROOMS'])
print (df['NUM_BEDROOMS'].isnull())
# 删除空数据
new_df = df.dropna()
print(new_df.to_string())
# 修改原DataFrame
df.dropna(inplace = True)
print(df.to_string())
# 移除指定有空值的行
df.dropna(subset=['ST_NUM'], inplace = True)
print(df.to_string())
使用fillna()替换空值
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median() 和 mode() 方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)。
import pandas as pd
df = pd.read_csv('property-data.csv')
# 使用 12345 替换空字段
df.fillna(12345, inplace = True)
print(df.to_string())
# 使用均值替换空字段
x = df["ST_NUM"].mean()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
# 使用中位数替换空字段
x = df["ST_NUM"].median()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
# 使用众数替换空字段
x = df["ST_NUM"].mode()
df["ST_NUM"].fillna(x, inplace = True)
print(df.to_string())
清洗格式错误
数据格式错误的单元格会使数据分析变得困难,甚至不可能。
我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
清洗错误数据
import pandas as pd
person = {
"name": ['Google', 'Runoob' , 'Taobao'],
"age": [50, 200, 12345]
}
df = pd.DataFrame(person)
# 直接修改数据
df.loc[2, 'age'] = 30
# 循环判断
for x in df.index:
if df.loc[x, "age"] > 120:
df.loc[x, "age"] = 120
# 删除行
for x in df.index:
if df.loc[x, "age"] > 120:
df.drop(x, inplace = True)
print(df.to_string())
清洗重复数据
如果我们要清洗重复数据,可以使用 duplicated() 和 drop_duplicates() 方法。
如果对应的数据是重复的,duplicated() 会返回 True,否则返回 False。
import pandas as pd
person = {
"name": ['Google', 'Runoob', 'Runoob', 'Taobao'],
"age": [50, 40, 40, 23]
}
df = pd.DataFrame(person)
# 查找重复数据
print(df.duplicated())
# 删除重复数据
df.drop_duplicates(inplace = True)
print(df)