limit优化
一个常见又非常头疼的问题就是 limit 2000000,10 ,此时需要MySQL排序前2000010 记录,仅仅返回2000000 - 2000010的记录,其他记录丢弃,查询排序的代价非常大。
优化思路: 一般分页查询时,通过创建 覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询
explain select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;但是当前版本不支持in后用limit的语法
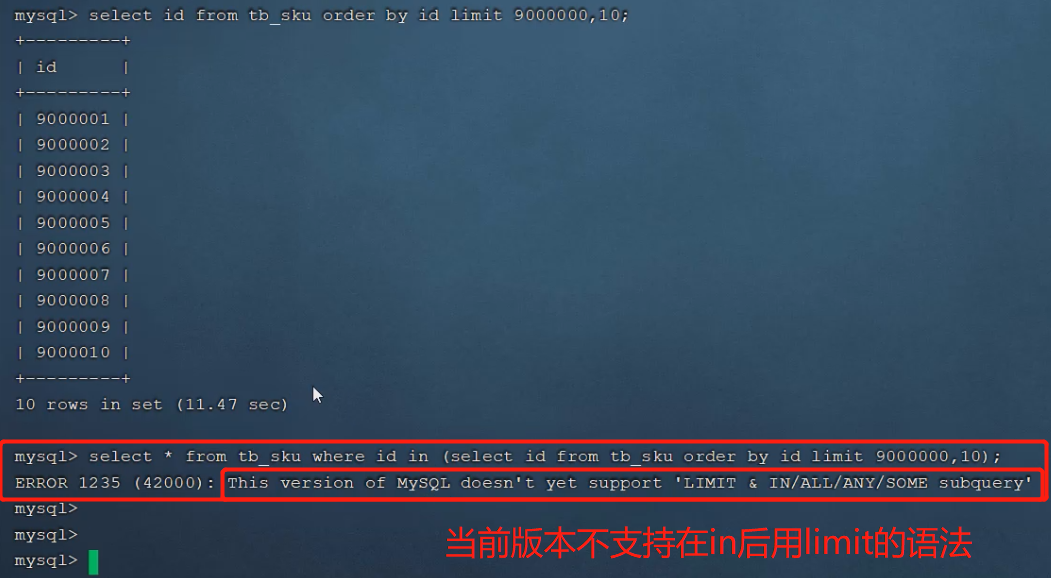
所以要用多表联查

count优化
explain select count(*) from tb_user ;MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高;
InnoDB引擎就麻烦了,它执行 count()的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
优化思路: 自己计数。
count的几种用法
count()是一个聚合函数,对于返回的结果集,一行行的判断,如果count函数的参数不是null,累计值就+1,否则不加,最后返回累计值。
用法:
count(*): InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
count(主键 id ):
InnoDB引擎会遍历整张表,把每一行的 主键id 值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)。count (字段)
count(字段):
没有not nul 约束:InnoDB 引会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为nul,不为null,计数累加
有not null 约束:InnoDB 引警会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
count(1):InnoDB引警遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
按照效率的话,count(字段)<count(主键 id )<count(1)≈count(*)
InnoDB默认是行级锁,只要事务没提交,就会被锁。
在一个窗口中开启
begin;
update course set name = 'javaEE' where id = 1;在另一个窗口开启
begin;
update course set name = 'Kafka' where id = 4;不会相互影响,因为InnoDB默认是行级锁
但是如果以无索引字段搜索,加的不是行级锁而是表锁
比如:
update course set name = 'spring' where name = 'PHP';此时是表锁,其他事务不能对此表进行操作。
但是如果对name建立索引后,那么加的就是行级锁而不是表锁了。
比如:
begin;
create index idx_course_name on course(name);
update course set name = 'spring' where name = 'PHP';InnoDB的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
InnoDB引擎有三大特性:事务,外键,行级锁
我们在更新字段时,要按照索引更新。
-
可以避免锁的冲突。
-
提高更新效率,减少资源消耗。
-