- 导包
导入requests发起请求包、bs4解析器、os文件操作等相关的包
import requests from bs4 import BeautifulSoup import os #文件
- url设置 selector的选择
- 设置url 对url使用requests发出请求 ,再同通过bs4的beautifSoup解析器对获取的内容进行解析
-
-
url = 'http://www.teamifortner.com/bqg/8251/' #小说网站 没有反扒的网站 主页 = requests.get(url) #request发起请求 主页解析 = BeautifulSoup(主页.content,'lxml') #解析
-
-
- 通过select选择器通过selector路径 对内容进行定位操作
章节 = 主页解析.select('body > div.container > div.row.row-section > div > div:nth-child(4) > ul > li > a') #select定位 复制selector
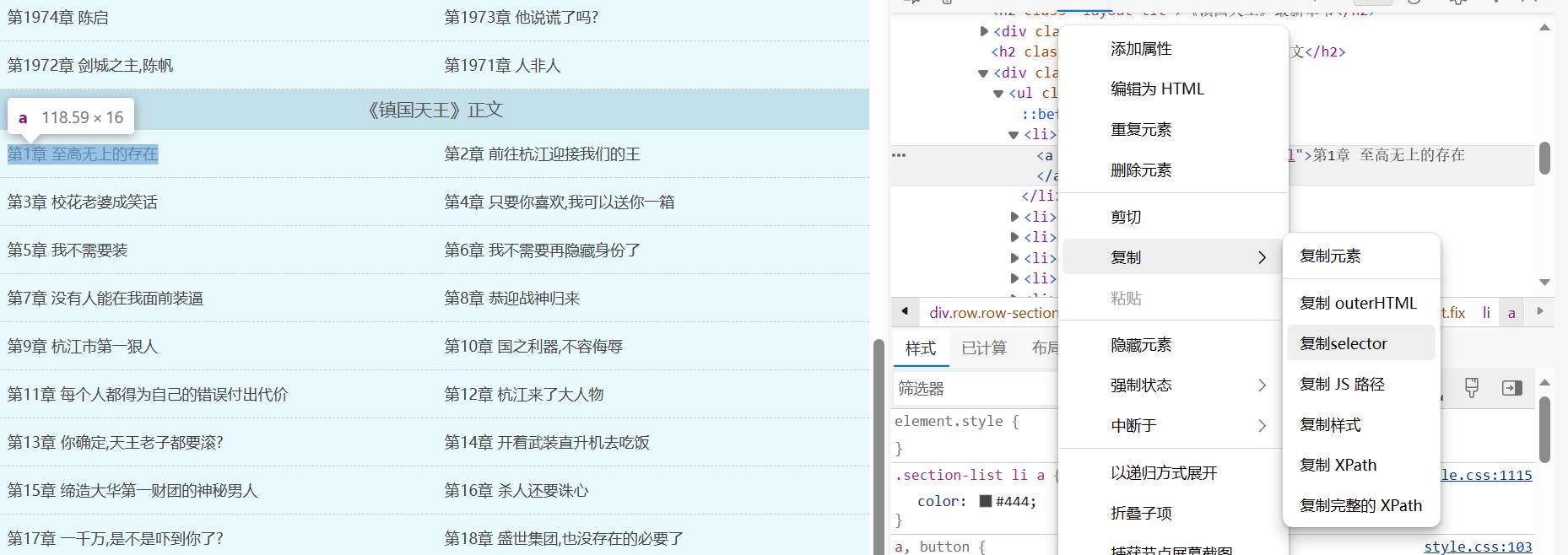
- 通过select获取的是 一个章节的列表 ul > li > a获取是统一路径下的标题 ------ 列表
- 通过for循环章节中的每一章 获取每一章的内容
- 标题 通过 .text ------ 获取标题文本
- 链接 通过 .get('href') ------ 获取一章的链接 这里的链接是部分的 需要拼接原网址
-
章节名 = 某一章节.text 章节链接 = 某一章节.get('href') #.get 属性名 章节链接 = 'http://www.teamifortner.com'+章节链接
- 重复 上述对小说内容的request发出请求步骤一样 再对 单独一章小说内容 发出请求
章节内容 = requests.get(章节链接) 章节解析 =BeautifulSoup(章节内容.content,'lxml') 内容 = 章节解析.select('#content')
- 通过for循环章节中的每一章 获取每一章的内容
- 创建并保存数据
写入 = open('e:/镇国天王/'+章节名+'.txt','a',encoding='utf-8') #a追加 写入.write(str(内容)) 写入.close()
全部代码
import requests from bs4 import BeautifulSoup import os #文件 url = 'http://www.teamifortner.com/bqg/8251/' 主页 = requests.get(url) #request发起请求 主页解析 = BeautifulSoup(主页.content,'lxml') #解析 章节 = 主页解析.select('body > div.container > div.row.row-section > div > div:nth-child(4) > ul > li > a') #select定位 复制selector os.mkdir('e:/镇国天王') #创建文件夹 for 某一章节 in 章节 : 章节名 = 某一章节.text 章节链接 = 某一章节.get('href') #.get 属性名 章节链接 = 'http://www.teamifortner.com'+章节链接 章节内容 = requests.get(章节链接) 章节解析 =BeautifulSoup(章节内容.content,'lxml') 内容 = 章节解析.select('#content') 写入 = open('e:/镇国天王/'+章节名+'.txt','a',encoding='utf-8') #a追加 写入.write(str(内容)) 写入.close()
url = 'http://www.teamifortner.com/bqg/8251/'
主页 = requests.get(url) #request发起请求
主页解析 = BeautifulSoup(主页.content,'lxml') #解析