原文:TensorFlow 2.0 Quick Start Guide
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
第 1 部分:TensorFlow 2.00 Alpha 简介
在本部分中,我们将介绍 TensorFlow 2.00 alpha。 我们将首先概述该机器学习生态系统的主要功能,并查看其使用示例。 然后我们将介绍 TensorFlow 的高级 Keras API。 我们将在本节结尾处研究人工神经网络技术。
本节包含以下章节:
- 第 1 章“TensorFlow 2 简介”
- 第 2 章“Keras,TensorFlow 2 的高级 API”
- 第 3 章“TensorFlow 2 和 ANN 技术”
一、TensorFlow 2 简介
TensorFlow 于 2011 年以 Google 的内部封闭源代码项目 DisBelief 诞生。 DisBelief 是采用深度学习神经网络的机器学习系统。 该系统演变为 TensorFlow,并在 2015 年 11 月 9 日根据 Apache 2.0 开源许可证发布到开发人员社区。版本 1.0.0 于 2017 年 2 月 11 日出现。此后有许多版本发布。 合并了许多新功能。
在撰写本书时,最新版本是 TensorFlow 2.0.0 alpha 版本,该版本在 2019 年 3 月 6 日的 TensorFlow 开发峰会上宣布。
TensorFlow 的名字来源于张量。 张量是向量和矩阵到更高维度的一般化。 张量的等级是唯一指定该张量的每个元素所用的索引数。 标量(简单数字)是等级 0 的张量,向量是等级 1 的张量,矩阵是等级 2 的张量,三维数组是等级 3 的张量。张量具有数据类型和形状(张量中的所有数据项必须具有相同的类型)。 4 维张量的示例(即等级 4)是图像,其中维是例如batch,height,width和color通道内的示例:
image1 = tf.zeros([7, 28, 28, 3]) # example-within-batch by height by width by color
尽管 TensorFlow 通常可以用于许多数值计算领域,尤其是机器学习,但其主要研究和开发领域是深层神经网络(DNN)的应用,它已在语音和声音识别等不同领域使用,例如,在如今广泛使用的声控助手中; 基于文本的应用,例如语言翻译器; 图像识别,例如系外行星搜寻,癌症检测和诊断; 以及时间序列应用(例如推荐系统)。
在本章中,我们将讨论以下内容:
- 现代 TensorFlow 生态系统
- 安装 TensorFlow
- 急切操作
- 提供有用的 TensorFlow 操作
现代 TensorFlow 生态系统
让我们讨论急切执行。 TensorFlow 的第一个化身包括构造由操作和张量组成的计算图,随后必须在 Google 所谓的会话中对其进行评估(这称为声明性编程)。 这仍然是编写 TensorFlow 程序的常用方法。 但是,急切执行的功能(以研究形式从版本 1.5 开始可用,并从版本 1.7 被烘焙到 TensorFlow 中)需要立即评估操作,结果是可以将张量像 NumPy 数组一样对待(这被称为命令式编程)。
谷歌表示,急切执行是研究和开发的首选方法,但计算图对于服务 TensorFlow 生产应用将是首选。
tf.data是一种 API,可让您从更简单,可重复使用的部件中构建复杂的数据输入管道。 最高级别的抽象是Dataset,它既包含张量的嵌套结构元素,又包含作用于这些元素的转换计划。 有以下几种类:
Dataset包含来自至少一个二进制文件(FixedLengthRecordDataset)的固定长度记录集Dataset由至少一个 TFRecord 文件(TFRecordDataset)中的记录组成Dataset由记录组成,这些记录是至少一个文本文件(TFRecordDataset)中的行- 还有一个类表示通过
Dataset(tf.data.Iterator)进行迭代的状态
让我们继续进行估计器,这是一个高级 API,可让您构建大大简化的机器学习程序。 估计员负责训练,评估,预测和导出服务。
TensorFlow.js 是 API 的集合,可让您使用底层 JavaScript 线性代数库或高层 API 来构建和训练模型。 因此,可以训练模型并在浏览器中运行它们。
TensorFlow Lite 是适用于移动和嵌入式设备的 TensorFlow 的轻量级版本。 它由运行时解释器和一组工具组成。 这个想法是您在功率更高的机器上训练模型,然后使用工具将模型转换为.tflite格式。 然后将模型加载到您选择的设备中。 在撰写本文时,使用 C++ API 在 Android 和 iOS 上支持 TensorFlow Lite,并且具有适用于 Android 的 Java 包装器。 如果 Android 设备支持 Android 神经网络(ANN)API 进行硬件加速,则解释器将使用此 API,否则它将默认使用 CPU 执行。
TensorFlow Hub 是一个旨在促进机器学习模型的可重用模块的发布,发现和使用的库。 在这种情况下,模块是 TensorFlow 图的独立部分,包括其权重和其他资产。 该模块可以通过称为迁移学习的方法在不同任务中重用。 这个想法是您在大型数据集上训练模型,然后将适当的模块重新用于您的其他但相关的任务。 这种方法具有许多优点-您可以使用较小的数据集训练模型,可以提高泛化能力,并且可以大大加快训练速度。
例如,ImageNet 数据集以及许多不同的神经网络架构(例如inception_v3)已非常成功地用于解决许多其他图像处理训练问题。
TensorFlow Extended(TFX)是基于 TensorFlow 的通用机器学习平台。 迄今为止,已开源的库包括 TensorFlow 转换,TensorFlow 模型分析和 TensorFlow 服务。
tf.keras是用 Python 编写的高级神经网络 API,可与 TensorFlow(和其他各种张量工具)接口。 tf.k eras支持快速原型设计,并且用户友好,模块化且可扩展。 它支持卷积和循环网络,并将在 CPU 和 GPU 上运行。 Keras 是 TensorFlow 2 中开发的首选 API。
TensorBoard 是一套可视化工具,支持对 TensorFlow 程序的理解,调试和优化。 它与急切和图执行环境兼容。 您可以在训练期间使用 TensorBoard 可视化模型的各种指标。
TensorFlow 的一项最新开发(在撰写本文时仍处于实验形式)将 TensorFlow 直接集成到 Swift 编程语言中。 Swift 中的 TensorFlow 应用是使用命令性代码编写的,即命令急切地(在运行时)执行的代码。 Swift 编译器会自动将此源代码转换为一个 TensorFlow 图,然后在 CPU,GPU 和 TPU 上以 TensorFlow Sessions 的全部性能执行此编译后的代码。
在本书中,我们将重点介绍那些使用 Python 3.6 和 TensorFlow 2.0.0 alpha 版本启动和运行 TensorFlow 的 TensorFlow 工具。 特别是,我们将使用急切的执行而不是计算图,并且将尽可能利用tf.keras的功能来构建网络,因为这是研究和实验的现代方法。
安装 TensorFlow
TensorFlow 的最佳编程支持是为 Python 提供的(尽管确实存在 Java,C 和 Go 的库,而其他语言的库正在积极开发中)。
Web 上有大量信息可用于为 Python 安装 TensorFlow。
Google 也建议在虚拟环境中安装 TensorFlow,这是一种标准做法,该环境将一组 API 和代码与其他 API 和代码以及系统范围的环境隔离开来。
TensorFlow 有两种不同的版本-一个用于在 CPU 上执行,另一个用于在 GPU 上执行。 最后,这需要安装数值库 CUDA 和 CuDNN。 Tensorflow 将在可能的情况下默认执行 GPU。 参见这里。
与其尝试重新发明轮子,不如跟随资源来创建虚拟环境和安装 TensorFlow。
总而言之,可能会为 Windows 7 或更高版本,Ubuntu Linux 16.04 或更高版本以及 macOS 10.12.6 或更高版本安装 TensorFlow。
有关虚拟环境的完整介绍,请参见这里。
Google 的官方文档中提供了有关安装 TensorFlow 所需的所有方面的非常详细的信息。
安装后,您可以从命令终端检查 TensorFlow 的安装。 这个页面有执行此操作,以及安装 TensorFlow 的夜间版本(其中包含所有最新更新)的说明。
急切的操作
我们将首先介绍如何导入 TensorFlow,然后介绍 TensorFlow 编码风格,以及如何进行一些基本的整理工作。 之后,我们将看一些基本的 TensorFlow 操作。 您可以为这些代码片段创建 Jupyter 笔记本,也可以使用自己喜欢的 IDE 创建源代码。 该代码在 GitHub 存储库中都可用。
导入 TensorFlow
导入 TensorFlow 很简单。 请注意几个系统检查:
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution is: {}".format(tf.executing_eagerly()))
print("Keras version: {}".format(tf.keras.__version__))
TensorFlow 的编码风格约定
对于 Python 应用,Google 遵守 PEP8 标准约定。 特别是,他们将 CamelCase 用于类(例如hub.LatestModuleExporter),将snake_case用于函数,方法和属性(例如tf.math.squared_difference)。 Google 还遵守《Google Python 风格指南》,该指南可在这个页面中找到。
使用急切执行
急切执行是 TensorFlow 2 中的默认设置,因此不需要特殊设置。
以下代码可用于查找是否正在使用 CPU 或 GPU,如果它是 GPU,则该 GPU 是否为#0。
我们建议键入代码,而不要使用复制和粘贴。 这样,您将对以下命令有所了解:
var = tf.Variable([3, 3])
if tf.test.is_gpu_available():
print('Running on GPU')
print('GPU #0?')
print(var.device.endswith('GPU:0'))
else:
print('Running on CPU')
声明急切变量
声明 TensorFlow 急切变量的方法如下:
t0 = 24 # python variable
t1 = tf.Variable(42) # rank 0 tensor
t2 = tf.Variable([ [ [0., 1., 2.], [3., 4., 5.] ], [ [6., 7., 8.], [9., 10., 11.] ] ]) #rank 3 tensor
t0, t1, t2
输出将如下所示:
(24,
<tf.Variable 'Variable:0' shape=() dtype=int32, numpy=42>,
<tf.Variable 'Variable:0' shape=(2, 2, 3) dtype=float32, numpy=
array([[[ 0., 1., 2.],
[ 3., 4., 5.]],
[[ 6., 7., 8.],
[ 9., 10., 11.]]], dtype=float32)>)
TensorFlow 将推断数据类型,对于浮点数默认为tf.float32,对于整数默认为tf.int32(请参见前面的示例)。
或者,可以显式指定数据类型,如下所示:
f64 = tf.Variable(89, dtype = tf.float64)
f64.dtype
TensorFlow 具有大量的内置数据类型。
示例包括之前看到的示例tf.int16,tf.complex64和tf.string。 参见这里。 要重新分配变量,请使用var.assign(),如下所示:
f1 = tf.Variable(89.)
f1
# <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=89.0>
f1.assign(98.)
f1
# <tf.Variable 'Variable:0' shape=() dtype=float32, numpy=98.0>
声明 TensorFlow 常量
TensorFlow 常量可以在以下示例中声明:
m_o_l = tf.constant(42)
m_o_l
# <tf.Tensor: id=45, shape=(), dtype=int32, numpy=42>
m_o_l.numpy()
# 42
同样,TensorFlow 将推断数据类型,或者可以像使用变量那样显式指定它:
unit = tf.constant(1, dtype = tf.int64)
unit
# <tf.Tensor: id=48, shape=(), dtype=int64, numpy=1>
调整张量
张量的形状通过属性(而不是函数)访问:
t2 = tf.Variable([ [ [0., 1., 2.], [3., 4., 5.] ], [ [6., 7., 8.], [9., 10., 11.] ] ]) # tensor variable
print(t2.shape)
输出将如下所示:
(2, 2, 3)
张量可能会被重塑并保留相同的值,这是构建神经网络经常需要的。
这是一个示例:
r1 = tf.reshape(t2,[2,6]) # 2 rows 6 cols
r2 = tf.reshape(t2,[1,12]) # 1 rows 12 cols
r1
# <tf.Tensor: id=33, shape=(2, 6), dtype=float32,
numpy= array([[ 0., 1., 2., 3., 4., 5.], [ 6., 7., 8., 9., 10., 11.]], dtype=float32)>
这是另一个示例:
r2 = tf.reshape(t2,[1,12]) # 1 row 12 columns
r2
# <tf.Tensor: id=36, shape=(1, 12), dtype=float32,
numpy= array([[ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11.]], dtype=float32)>
张量的等级(尺寸)
张量的等级是它具有的维数,即指定该张量的任何特定元素所需的索引数。
张量的等级可以这样确定,例如:
tf.rank(t2)
输出将如下所示:
<tf.Tensor: id=53, shape=(), dtype=int32, numpy=3>
(the shape is () because the output here is a scalar value)
指定张量的元素
正如您期望的那样,通过指定所需的索引来指定张量的元素。
以这个为例:
t3 = t2[1, 0, 2] # slice 1, row 0, column 2
t3
输出将如下所示:
<tf.Tensor: id=75, shape=(), dtype=float32, numpy=8.0>
将张量转换为 NumPy/Python 变量
如果需要,可以将张量转换为numpy变量,如下所示:
print(t2.numpy())
输出将如下所示:
[[[ 0\. 1\. 2.] [ 3\. 4\. 5.]] [[ 6\. 7\. 8.] [ 9\. 10\. 11.]]]
也可以这样:
print(t2[1, 0, 2].numpy())
输出将如下所示:
8.0
查找张量的大小(元素数)
张量中的元素数量很容易获得。 再次注意,使用.numpy()函数从张量中提取 Python 值:
s = tf.size(input=t2).numpy()
s
输出将如下所示:
12
查找张量的数据类型
TensorFlow 支持您期望的所有数据类型。 完整列表位于这里,其中包括tf.int32(默认整数类型),tf.float32(默认浮动点类型)和tf.complex64(复数类型)。
要查找张量的数据类型,请使用以下dtype属性:
t3.dtype
输出将如下所示:
tf.float32
指定按元素的基本张量操作
如您所料,使用重载运算符+,-,*和/来指定逐元素基本张量操作,如下所示:
t2*t2
输出将如下所示:
<tf.Tensor: id=555332, shape=(2, 2, 3), dtype=float32, numpy= array([[[ 0., 1., 4.], [ 9., 16., 25.]], [[ 36., 49., 64.], [ 81., 100., 121.]]], dtype=float32)>
广播
按元素张量操作以与 NumPy 数组相同的方式支持广播。 最简单的示例是将张量乘以标量:
t4 = t2*4
print(t4)
输出将如下所示:
tf.Tensor( [[[ 0\. 4\. 8.] [12\. 16\. 20.]] [[24\. 28\. 32.] [36\. 40\. 44.]]], shape=(2, 2, 3), dtype=float32)
在该示例中,在概念上至少将标量乘法器 4 扩展为一个数组,该数组可以与t2逐元素相乘。 在上对广播进行了非常详细的讨论,网址为。
转置 TensorFlow 和矩阵乘法
要紧急转置矩阵和矩阵乘法,请使用以下命令:
u = tf.constant([[3,4,3]])
v = tf.constant([[1,2,1]])
tf.matmul(u, tf.transpose(a=v))
输出将如下所示:
<tf.Tensor: id=555345, shape=(1, 1), dtype=int32, numpy=array([[14]], dtype=int32)>
再次注意,默认整数类型为tf.int32,默认浮点类型为tf.float32。
可用于构成计算图一部分的张量的所有操作也可用于急切执行变量。
在这个页面上有这些操作的完整列表。
将张量转换为另一个(张量)数据类型
一种类型的 TensorFlow 变量可以强制转换为另一种类型。 可以在这个页面中找到更多详细信息。
请看以下示例:
i = tf.cast(t1, dtype=tf.int32) # 42
i
输出将如下所示:
<tf.Tensor: id=116, shape=(), dtype=int32, numpy=42>
截断后,将如下所示:
j = tf.cast(tf.constant(4.9), dtype=tf.int32) # 4
j
输出将如下所示:
<tf.Tensor: id=119, shape=(), dtype=int32, numpy=4>
声明参差不齐的张量
参差不齐的张量是具有一个或多个参差不齐尺寸的张量。 参差不齐的尺寸是具有可能具有不同长度的切片的尺寸。
声明参差不齐的数组的方法有很多种,最简单的方法是常量参差不齐的数组。
以下示例显示了如何声明一个常数的,参差不齐的数组以及各个切片的长度:
ragged =tf.ragged.constant([[5, 2, 6, 1], [], [4, 10, 7], [8], [6,7]])
print(ragged)
print(ragged[0,:])
print(ragged[1,:])
print(ragged[2,:])
print(ragged[3,:])
print(ragged[4,:])
输出如下:
<tf.RaggedTensor [[5, 2, 6, 1], [], [4, 10, 7], [8], [6, 7]]>
tf.Tensor([5 2 6 1], shape=(4,), dtype=int32)
tf.Tensor([], shape=(0,), dtype=int32)
tf.Tensor([ 4 10 7], shape=(3,), dtype=int32)
tf.Tensor([8], shape=(1,), dtype=int32)
tf.Tensor([6 7], shape=(2,), dtype=int32)
注意单个切片的形状。
创建参差不齐的数组的常用方法是使用tf.RaggedTensor.from_row_splits()方法,该方法具有以下签名:
@classmethod
from_row_splits(
cls,
values,
row_splits,
name=None
)
在这里,values是要变成参差不齐的数组的值的列表,row_splits是要拆分该值列表的位置的列表,因此行ragged[i]的值存储在其中 ragged.values[ragged.row_splits[i]:ragged.row_splits[i+1]]:
print(tf.RaggedTensor.from_row_splits(values=[5, 2, 6, 1, 4, 10, 7, 8, 6, 7],
row_splits=[0, 4, 4, 7, 8, 10]))
RaggedTensor如下:
<tf.RaggedTensor [[5, 2, 6, 1], [], [4, 10, 7], [8], [6, 7]]>
提供有用的 TensorFlow 操作
在这个页面上有所有 TensorFlow Python 模块,类和函数的完整列表。
可以在这个页面中找到所有数学函数。
在本节中,我们将研究一些有用的 TensorFlow 操作,尤其是在神经网络编程的上下文中。
求两个张量之间的平方差
在本书的后面,我们将需要找到两个张量之差的平方。 方法如下:
tf.math.squared.difference( x, y, name=None)
请看以下示例:
x = [1,3,5,7,11]
y = 5
s = tf.math.squared_difference(x,y)
s
输出将如下所示:
<tf.Tensor: id=279, shape=(5,), dtype=int32, numpy=array([16, 4, 0, 4, 36], dtype=int32)>
请注意,在此示例中,Python 变量x和y被转换为张量,然后y跨x广播。 因此,例如,第一计算是(1 - 5)^2 = 16。
求平均值
以下是tf.reduce_mean()的签名。
请注意,在下文中,所有 TensorFlow 操作都有一个名称参数,当使用急切执行作为其目的是在计算图中识别操作时,可以安全地将其保留为默认值None。
请注意,这等效于np.mean,除了它从输入张量推断返回数据类型,而np.mean允许您指定输出类型(默认为float64):
tf.reduce_mean(input_tensor, axis=None, keepdims=None, name=None)
通常需要找到张量的平均值。 当在单个轴上完成此操作时,该轴被称为减少了。
这里有些例子:
numbers = tf.constant([[4., 5.], [7., 3.]])
求所有轴的均值
求出所有轴的平均值(即使用默认的axis = None):
tf.reduce_mean(input_tensor=numbers)
#( 4\. + 5\. + 7\. + 3.)/4 = 4.75
输出将如下所示:
<tf.Tensor: id=272, shape=(), dtype=float32, numpy=4.75>
求各列的均值
用以下方法找到各列的均值(即减少行数):
tf.reduce_mean(input_tensor=numbers, axis=0) # [ (4\. + 7\. )/2 , (5\. + 3.)/2 ] = [5.5, 4.]
输出将如下所示:
<tf.Tensor: id=61, shape=(2,), dtype=float32, numpy=array([5.5, 4\. ], dtype=float32)>
当keepdims为True时,缩小轴将保留为 1:
tf.reduce_mean(input_tensor=numbers, axis=0, keepdims=True)
输出如下:
array([[5.5, 4.]]) (1 row, 2 columns)
求各行的均值
使用以下方法找到各行的均值(即减少列数):
tf.reduce_mean(input_tensor=numbers, axis=1) # [ (4\. + 5\. )/2 , (7\. + 3\. )/2] = [4.5, 5]
输出将如下所示:
<tf.Tensor: id=64, shape=(2,), dtype=float32, numpy=array([4.5, 5\. ], dtype=float32)>
当keepdims为True时,缩小轴将保留为 1:
tf.reduce_mean(input_tensor=numbers, axis=1, keepdims=True)
输出如下:
([[4.5], [5]]) (2 rows, 1 column)
生成充满随机值的张量
开发神经网络时,例如初始化权重和偏差时,经常需要随机值。 TensorFlow 提供了多种生成这些随机值的方法。
使用tf.random.normal()
tf.random.normal()输出给定形状的张量,其中填充了来自正态分布的dtype类型的值。
所需的签名如下:
tf. random.normal(shape, mean = 0, stddev =2, dtype=tf.float32, seed=None, name=None)
以这个为例:
tf.random.normal(shape = (3,2), mean=10, stddev=2, dtype=tf.float32, seed=None, name=None)
ran = tf.random.normal(shape = (3,2), mean=10.0, stddev=2.0)
print(ran)
输出将如下所示:
<tf.Tensor: id=13, shape=(3, 2), dtype=float32, numpy= array([[ 8.537131 , 7.6625767], [10.925293 , 11.804686 ], [ 9.3763075, 6.701221 ]], dtype=float32)>
使用tf.random.uniform()
所需的签名是这样的:
tf.random.uniform(shape, minval = 0, maxval= None, dtype=tf.float32, seed=None, name=None)
这将输出给定形状的张量,该张量填充了从minval到maxval范围内的均匀分布的值,其中下限包括在内,而上限不包括在内。
以这个为例:
tf.random.uniform(shape = (2,4), minval=0, maxval=None, dtype=tf.float32, seed=None, name=None)
输出将如下所示:
tf.Tensor( [[ 6 7] [ 0 12]], shape=(2, 2), dtype=int32)
请注意,对于这两个随机操作,如果您希望生成的随机值都是可重复的,则使用tf.random.set_seed()。 还显示了非默认数据类型的使用:
tf.random.set_seed(11)
ran1 = tf.random.uniform(shape = (2,2), maxval=10, dtype = tf.int32)
ran2 = tf.random.uniform(shape = (2,2), maxval=10, dtype = tf.int32)
print(ran1) #Call 1
print(ran2)
tf.random.set_seed(11) #same seed
ran1 = tf.random.uniform(shape = (2,2), maxval=10, dtype = tf.int32)
ran2 = tf.random.uniform(shape = (2,2), maxval=10, dtype = tf.int32)
print(ran1) #Call 2
print(ran2)
Call 1和Call 2将返回相同的一组值。
输出将如下所示:
tf.Tensor(
[[4 6]
[5 2]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[9 7]
[9 4]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[4 6]
[5 2]], shape=(2, 2), dtype=int32)
tf.Tensor(
[[9 7]
[9 4]], shape=(2, 2), dtype=int32)
使用随机值的实际示例
这是一个适合从这个页面执行的小示例。
请注意,此示例显示了如何通过调用 TensorFlow 函数来初始化急切变量。
dice1 = tf.Variable(tf.random.uniform([10, 1], minval=1, maxval=7, dtype=tf.int32))
dice2 = tf.Variable(tf.random.uniform([10, 1], minval=1, maxval=7, dtype=tf.int32))
# We may add dice1 and dice2 since they share the same shape and size.
dice_sum = dice1 + dice2
# We've got three separate 10x1 matrices. To produce a single
# 10x3 matrix, we'll concatenate them along dimension 1.
resulting_matrix = tf.concat(values=[dice1, dice2, dice_sum], axis=1)
print(resulting_matrix)
示例输出如下:
tf.Tensor(
[[ 5 4 9]
[ 5 1 6]
[ 2 4 6]
[ 5 6 11]
[ 4 4 8]
[ 4 6 10]
[ 2 2 4]
[ 5 6 11]
[ 2 6 8]
[ 5 4 9]], shape=(10, 3), dtype=int32)
查找最大和最小元素的索引
现在,我们将研究如何在张量轴上查找具有最大值和最小值的元素的索引。
这些函数的签名如下:
tf.argmax(input, axis=None, name=None, output_type=tf.int64 )
tf.argmin(input, axis=None, name=None, output_type=tf.int64 )
以这个为例:
# 1-D tensor
t5 = tf.constant([2, 11, 5, 42, 7, 19, -6, -11, 29])
print(t5)
i = tf.argmax(input=t5)
print('index of max; ', i)
print('Max element: ',t5[i].numpy())
i = tf.argmin(input=t5,axis=0).numpy()
print('index of min: ', i)
print('Min element: ',t5[i].numpy())
t6 = tf.reshape(t5, [3,3])
print(t6)
i = tf.argmax(input=t6,axis=0).numpy() # max arg down rows
print('indices of max down rows; ', i)
i = tf.argmin(input=t6,axis=0).numpy() # min arg down rows
print('indices of min down rows ; ',i)
print(t6)
i = tf.argmax(input=t6,axis=1).numpy() # max arg across cols
print('indices of max across cols: ',i)
i = tf.argmin(input=t6,axis=1).numpy() # min arg across cols
print('indices of min across cols: ',i)
输出将如下所示:
tf.Tensor([ 2 11 5 42 7 19 -6 -11 29], shape=(9,), dtype=int32)
index of max; tf.Tensor(3, shape=(), dtype=int64)
Max element: 42
index of min: tf.Tensor(7, shape=(), dtype=int64)
Min element: -11
tf.Tensor( [[ 2 11 5] [ 42 7 19] [ -6 -11 29]], shape=(3, 3), dtype=int32)
indices of max down rows; tf.Tensor([1 0 2], shape=(3,), dtype=int64)
indices of min down rows ; tf.Tensor([2 2 0], shape=(3,), dtype=int64)
tf.Tensor( [[ 2 11 5] [ 42 7 19] [ -6 -11 29]], shape=(3, 3), dtype=int32)
indices of max across cols: tf.Tensor([1 0 2], shape=(3,), dtype=int64)
indices of min across cols: tf.Tensor([0 1 1], shape=(3,), dtype=int64)
使用检查点保存和恢复张量值
为了保存和加载张量值,这是最好的方法(有关保存完整模型的方法,请参见第 2 章和 “Keras,TensorFlow 2” 的高级 API):
variable = tf.Variable([[1,3,5,7],[11,13,17,19]])
checkpoint= tf.train.Checkpoint(var=variable)
save_path = checkpoint.save('./vars')
variable.assign([[0,0,0,0],[0,0,0,0]])
variable
checkpoint.restore(save_path)
print(variable)
输出将如下所示:
<tf.Variable 'Variable:0' shape=(2, 4) dtype=int32, numpy= array([[ 1, 3, 5, 7], [11, 13, 17, 19]], dtype=int32)>
使用tf.function
tf.function是将采用 Python 函数并返回 TensorFlow 图的函数。 这样做的好处是,图可以在 Python 函数(func)中应用优化并利用并行性。 tf.function是 TensorFlow 2 的新功能。
其签名如下:
tf.function(
func=None,
input_signature=None,
autograph=True,
experimental_autograph_options=None
)
示例如下:
def f1(x, y):
return tf.reduce_mean(input_tensor=tf.multiply(x ** 2, 5) + y**2)
f2 = tf.function(f1)
x = tf.constant([4., -5.])
y = tf.constant([2., 3.])
# f1 and f2 return the same value, but f2 executes as a TensorFlow graph
assert f1(x,y).numpy() == f2(x,y).numpy()
断言通过,因此没有输出。
总结
在本章中,我们通过查看一些说明一些基本操作的代码片段开始熟悉 TensorFlow。 我们对现代 TensorFlow 生态系统以及如何安装 TensorFlow 进行了概述。 我们还研究了一些管家操作,一些急切操作以及各种 TensorFlow 操作,这些操作在本书的其余部分中将是有用的。 在 www.youtube.com/watch?v=k5c-vg4rjBw 上对 TensorFlow 2 进行了出色的介绍。
另请参阅“附录 A”,以获得tf1.12到tf2转换工具的详细信息。 在下一章中,我们将介绍 Keras,这是 TensorFlow 2 的高级 API。
二、Keras:TensorFlow 2 的高级 API
在本章中,我们将讨论 Keras,这是 TensorFlow 2 的高级 API。Keras 是由 FrançoisChollet 在 Google 上开发的。 Keras 在快速原型制作,深度学习模型的构建和训练以及研究和生产方面非常受欢迎。 Keras 是一个非常丰富的 API。 正如我们将看到的,它支持急切的执行和数据管道以及其他功能。
自 2017 年以来,Keras 已可用于 TensorFlow,但随着 TensorFlow 2.0 的发布,其用途已扩展并进一步集成到 TensorFlow 中。 TensorFlow 2.0 已将 Keras 用作大多数深度学习开发工作的首选 API。
可以将 Keras 作为独立模块导入,但是在本书中,我们将集中精力在 TensorFlow 2 内部使用 Keras。因此,该模块为tensorflow.keras。
在本章中,我们将介绍以下主题:
- Keras 的采用和优势
- Keras 的特性
- 默认的 Keras 配置文件
- Keras 后端
- Keras 数据类型
- Keras 模型
- Keras 数据集
Keras 的采用和优势
下图显示了 Keras 在工业和研究领域的广泛应用。 PowerScore 排名由 Jeff Hale 设计,他使用了 7 个不同类别的 11 个数据源来评估框架的使用,兴趣和受欢迎程度。 然后,他对数据进行了加权和合并,如 2018 年 9 月的这篇文章所示:

Keras 具有许多优点,其中包括:
- 它专为新用户和专家而设计,提供一致且简单的 API
- 通过简单,一致的接口对用户友好,该接口针对常见用例进行了优化
- 它为用户错误提供了很好的反馈,这些错误很容易理解,并且经常伴随有用的建议
- 它是模块化且可组合的; Keras 中的模型是通过结合可配置的构建块来构建的
- 通过编写自定义构建块很容易扩展
- 无需导入 Keras,因为它可以作为
tensorflow.keras获得
Keras 的特性
如果您想知道 TensorFlow 随附的 Keras 版本,请使用以下命令:
import tensorflow as tf
print(tf.keras.__version__)
在撰写本文时,这产生了以下内容(来自 TensorFlow 2 的 Alpha 版本):
2.2.4-tf
Keras 的其他功能包括对多 GPU 数据并行性的内置支持,以及 Keras 模型可以转化为 TensorFlow Estimators 并在 Google Cloud 上的 GPU 集群上进行训练的事实。
Keras 可能是不寻常的,因为它具有作为独立开源项目维护的参考实现,位于 www.keras.io 。
尽管 TensorFlow 在tf.keras模块中确实具有 Keras 的完整实现,但它独立于 TensorFlow 进行维护。 默认情况下,该实现具有 TensorFlow 特定的增强功能,包括对急切执行的支持。
急切的执行意味着代码的执行是命令式编程环境,而不是基于图的环境,这是在 TensorFlow(v1.5 之前)的初始产品中工作的唯一方法。 这种命令式(即刻)风格允许直观的调试,快速的开发迭代,支持 TensorFlow SavedModel格式,并内置支持对 CPU,GPU 甚至 Google 自己的硬件张量处理单元(TPU)进行分布式训练。
TensorFlow 实现还支持tf.data,分发策略,导出模型(可通过 TensorFlow Lite 部署在移动和嵌入式设备上)以及用于表示和分类结构化数据的特征列。
默认的 Keras 配置文件
Linux 用户的默认配置文件如下:
$HOME/.keras/keras.json
对于 Windows 用户,将$HOME替换为%USERPROFILE%。
它是在您第一次使用 Keras 时创建的,可以进行编辑以更改默认值。 以下是.json文件包含的内容:
{ "image_data_format": "channels_last", "epsilon": 1e-07, "floatx": "float32", "backend": "tensorflow" }
默认值如下:
-
image_data_format:这是图像格式的字符串,"channels_last"或channels_first。 在 TensorFlow 之上运行的 Keras 使用默认值。 -
epsilon:这是一个浮点数,是一个模糊常数,用于在某些操作中避免被零除。 -
floatx:这是一个字符串,指定默认的浮点精度,为"float16","float32"或"float64"之一。 -
backend:这是一个字符串,指定 Keras 在"tensorflow","theano"或"cntk"中的一种之上发现自己的工具。
对于所有这些值,在keras.backend中有获取器和设置器方法。 参见这里。
例如,在以下集合中,供 Keras 使用的浮点类型为floatx,其中floatx参数是以下命令中所示的三种精度之一:
keras.backend.set_floatx(floatx)
Keras 后端
由于其模型级别的库结构,Keras 可能具有处理低级操作(例如卷积,张量乘积等)的不同张量操纵引擎。 这些引擎称为后端。 其他后端可用; 我们在这里不考虑它们。
相同的链接可带您使用许多keras.backend函数。
使用 Keras backend的规范方法是:
from keras import backend as K
例如,以下是有用函数的签名:
K.constant(value, dtype=None, shape=None, name=None)
value是要赋予常数的值,dtype是创建的张量的类型,shape是创建的张量的形状,name是可选名称。
实例如下:
from tensorflow.keras import backend as K
const = K.constant([[42,24],[11,99]], dtype=tf.float16, shape=[2,2])
const
这将产生以下恒定张量。 注意,由于启用了急切执行,(默认情况下)在输出中给出常量的值:
<tf.Tensor: id=1, shape=(2, 2), dtype=float16, numpy= array([[42., 24.], [11., 99.]], dtype=float16)>
急切不启用,输出将如下所示:
<tf.Tensor 'Const:0' shape=(2, 2) dtype=float16>
Keras 数据类型
Keras 数据类型(dtypes)与 TensorFlow Python 数据类型相同,如下表所示:
| Python 类型 | 描述 |
|---|---|
tf.float16 |
16 位浮点 |
tf.float32 |
32 位浮点 |
tf.float64 |
64 位浮点 |
tf.int8 |
8 位有符号整数 |
tf.int16 |
16 位有符号整数 |
tf.int32 |
32 位有符号整数 |
tf.int64 |
64 位有符号整数 |
tf.uint8 |
8 位无符号整数 |
tf.string |
可变长度字节数组 |
tf.bool |
布尔型 |
tf.complex64 |
由两个 32 位浮点组成的复数-一个实部和虚部 |
tf.complex128 |
由两个 64 位浮点组成的复数-一个实部和一个虚部 |
tf.qint8 |
量化运算中使用的 8 位有符号整数 |
tf.qint32 |
量化运算中使用的 32 位有符号整数 |
tf.quint8 |
量化运算中使用的 8 位无符号整数 |
Keras 模型
Keras 基于神经网络模型的概念。 主要模型称为序列,是层的线性栈。 还有一个使用 Keras 函数式 API 的系统。
Keras 顺序模型
要构建 Keras Sequential模型,请向其中添加层,其顺序与您希望网络进行计算的顺序相同。
建立模型后,您可以编译; 这样可以优化要进行的计算,并且可以在其中分配优化器和希望模型使用的损失函数。
下一步是使模型拟合数据。 这通常称为训练模型,是所有计算发生的地方。 可以分批或一次将数据呈现给模型。
接下来,您评估模型以建立其准确率,损失和其他指标。 最后,在训练好模型之后,您可以使用它对新数据进行预测。 因此,工作流程是:构建,编译,拟合,评估,做出预测。
有两种创建Sequential模型的方法。 让我们看看它们中的每一个。
创建顺序模型的第一种方法
首先,可以将层实例列表传递给构造器,如以下示例所示。
在下一章中,我们将对层进行更多的讨论。 目前,我们将仅作足够的解释,以使您了解此处发生的情况。
采集数据。 mnist是手绘数字的数据集,每个数字在28 x 28像素的网格上。 每个单独的数据点都是一个无符号的 8 位整数(uint8),如标签所示:
mnist = tf.keras.datasets.mnist
(train_x,train_y), (test_x, test_y) = mnist.load_data()
epochs变量存储我们将数据呈现给模型的次数:
epochs=10
batch_size = 32 # 32 is default in fit method but specify anyway
接下来,将所有数据点(x)归一化为float32类型的浮点数范围为 0 到 1。 另外,根据需要将标签(y)投射到int64:
train_x, test_x = tf.cast(train_x/255.0, tf.float32), tf.cast(test_x/255.0, tf.float32)
train_y, test_y = tf.cast(train_y,tf.int64),tf.cast(test_y,tf.int64)
模型定义如下。
注意在模型定义中我们如何传递层列表:
Flatten接受28 x 28(即 2D)像素图像的输入,并产生 784(即 1D)向量,因为下一个(密集)层是一维的。Dense是一个完全连接的层,意味着其所有神经元都连接到上一层和下一层中的每个神经元。 下面的示例有 512 个神经元,其输入通过 ReLU(非线性)激活函数传递。Dropout随机关闭上一层神经元的一部分(在这种情况下为 0.2)。 这样做是为了防止任何特定的神经元变得过于专业化,并导致模型与数据过拟合,从而影响测试数据上模型的准确率指标(在后面的章节中将对此进行更多介绍)。- 最后的
Dense层具有一个称为softmax的特殊激活函数,该函数将概率分配给可能的 10 个输出单元中的每一个:
model1 = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512,activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10,activation=tf.nn.softmax)
])
model.summary()函数是一种有用的同义词方法,并为我们的模型提供以下输出:

401920的数字来自输入28 x 28 = 784 x 512(dense_2层)输出784 * 512 = 401,408以及每个dense_1层神经元的偏置单元 ,则401,408 + 512 = 401,920。
5130的数字来自512 * 10 + 10 = 5,130。
接下来,我们编译模型,如以下代码所示:
optimiser = tf.keras.optimizers.Adam()
model1.compile (optimizer= optimiser, loss='sparse_categorical_crossentropy', metrics = ['accuracy'])
optimizer是一种方法,通过该方法可以调整模型中加权连接的权重以减少损失。
loss是模型所需输出与实际输出之间差异的度量,而metrics是我们评估模型的方式。
为了训练我们的模型,我们接下来使用fit方法,如下所示:
model1.fit(train_x, train_y, batch_size=batch_size, epochs=epochs)
调用fit()的输出如下,显示了周期训练时间,损失和准确率:
Epoch 1/10 60000/60000 [==============================] - 5s 77us/step - loss: 0.2031 - acc: 0.9394 ...
Epoch 10/10 60000/60000 [==============================] - 4s 62us/step - loss: 0.0098 - acc: 0.9967
最后,我们可以使用evaluate方法检查我们训练有素的模型的准确率:
model1.evaluate(test_x, test_y)
这将产生以下输出:
10000/10000 [==============================] - 0s 39us/step [0.09151900197149189, 0.9801]
这表示测试数据的损失为 0.09,准确率为 0.9801。 精度为 0.98 意味着该模型平均可以识别出 100 个测试数据点中的 98 个。
创建顺序模型的第二种方法
对于同一体系结构,将层列表传递给Sequential模型的构造器的替代方法是使用add方法,如下所示:
model2 = tf.keras.models.Sequential();
model2.add(tf.keras.layers.Flatten())
model2.add(tf.keras.layers.Dense(512, activation='relu'))
model2.add(tf.keras.layers.Dropout(0.2))
model2.add(tf.keras.layers.Dense(10,activation=tf.nn.softmax))
model2.compile (optimizer= tf.keras.Adam(), loss='sparse_categorical_crossentropy',
metrics = ['accuracy'])
如我们所见,fit()方法执行训练,使用模型将输入拟合为输出:
model2.fit(train_x, train_y, batch_size=batch_size, epochs=epochs)
然后,我们使用test数据评估模型的表现:
model2.evaluate(test_x, test_y)
这给我们带来了0.07的损失和0.981的准确率。
因此,这种定义模型的方法产生的结果与第一个结果几乎相同,这是可以预期的,因为它是相同的体系结构,尽管表达方式略有不同,但具有相同的optimizer和loss函数。 现在让我们看一下函数式 API。
Keras 函数式 API
与以前看到的Sequential模型的简单线性栈相比,函数式 API 使您可以构建更复杂的体系结构。 它还支持更高级的模型。 这些模型包括多输入和多输出模型,具有共享层的模型以及具有剩余连接的模型。
这是函数式 API 的使用的简短示例,其架构与前两个相同。
设置代码与先前演示的相同:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(train_x,train_y), (test_x, test_y) = mnist.load_data()
train_x, test_x = train_x/255.0, test_x/255.0
epochs=10
这是模型定义。
注意如何在tensor上调用层并返回张量作为输出,然后如何使用这些输入和输出张量来定义模型:
inputs = tf.keras.Input(shape=(28,28)) # Returns a 'placeholder' tensor
x = tf.keras.layers.Flatten()(inputs)
x = tf.layers.Dense(512, activation='relu',name='d1')(x)
x = tf.keras.layers.Dropout(0.2)(x)
predictions = tf.keras.layers.Dense(10,activation=tf.nn.softmax, name='d2')(x)
model3 = tf.keras.Model(inputs=inputs, outputs=predictions)
请注意,此代码如何产生与model1和model2相同的体系结构:

None出现在这里是因为我们没有指定我们有多少输入项(即批量大小)。 这确实意味着未提供。
其余代码与前面的示例相同:
optimiser = tf.keras.optimizers.Adam()
model3.compile (optimizer= optimiser, loss='sparse_categorical_crossentropy', metrics = ['accuracy'])
model3.fit(train_x, train_y, batch_size=32, epochs=epochs)
model3.evaluate(test_x, test_y)
对于相同的体系结构,这同样会产生0.067的损失和0.982的精度。
接下来,让我们看看如何对 Keras model类进行子类化。
子类化 Keras 模型类
Keras Model类可以被子类化,如下面的代码所示。 Google 指出,纯函数风格(如前面的示例所示)比子类风格更可取(我们在此包括其内容是出于完整性的考虑,因为它很有趣)。
首先,请注意如何在构造器(.__init__())中分别声明和命名层。
然后,注意在call()方法中各层如何以函数风格链接在一起。 此方法封装了前向传播:
class MyModel(tf.keras.Model):
def __init__(self, num_classes=10):
super(MyModel, self).__init__()
# Define your layers here.
inputs = tf.keras.Input(shape=(28,28)) # Returns a placeholder tensor
self.x0 = tf.keras.layers.Flatten()
self.x1 = tf.keras.layers.Dense(512, activation='relu',name='d1')
self.x2 = tf.keras.layers.Dropout(0.2)
self.predictions = tf.keras.layers.Dense(10,activation=tf.nn.softmax, name='d2')
def call(self, inputs):
# This is where to define your forward pass
# using the layers previously defined in `__init__`
x = self.x0(inputs)
x = self.x1(x)
x = self.x2(x)
return self.predictions(x)
model4 = MyModel()
该定义可以代替本章中的任何较早的模型定义使用,它们具有相同的数据下载支持代码,以及相似的用于训练/评估的代码。 下面的代码显示了最后一个示例:
model4 = MyModel()
batch_size = 32
steps_per_epoch = len(train_x.numpy())//batch_size
print(steps_per_epoch)
model4.compile (optimizer= tf.keras.Adam(), loss='sparse_categorical_crossentropy',
metrics = ['accuracy'])
model4.fit(train_x, train_y, batch_size=batch_size, epochs=epochs)
model4.evaluate(test_x, test_y)
结果是0.068的损失,准确率为0.982; 再次与本章中其他三种模型构建风格产生的结果几乎相同。
使用数据管道
也可以使用以下代码将数据作为tf.data.Dataset()迭代器传递到fit方法中(数据获取代码与先前描述的相同)。 from_tensor_slices()方法将 NumPy 数组转换为数据集。 注意batch()和shuffle()方法链接在一起。 接下来,map()方法在输入图像x上调用一种方法,该方法在y轴上随机翻转其中的两个,有效地增加了图像集的大小。 标签y在这里保持不变。 最后,repeat()方法意味着在到达数据集的末尾(连续)时,将从头开始重新填充该数据集:
batch_size = 32
buffer_size = 10000
train_dataset = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(32).shuffle(10000)
train_dataset = train_dataset.map(lambda x, y: (tf.image.random_flip_left_right(x), y))
train_dataset = train_dataset.repeat()
test设置的代码类似,除了不进行翻转:
test_dataset = tf.data.Dataset.from_tensor_slices((test_x, test_y)).batch(batch_size).shuffle(10000)
test_dataset = train_dataset.repeat()
现在,在fit()函数中,我们可以直接传递数据集,如下所示:
steps_per_epoch = len(train_x)//batch_size # required because of the repeat on the dataset
optimiser = tf.keras.optimizers.Adam()
model5.compile (optimizer= optimiser, loss='sparse_categorical_crossentropy', metrics = ['accuracy'])
model.fit(train_dataset, batch_size=batch_size, epochs=epochs, steps_per_epoch=steps_per_epoch)
编译和评估代码与之前看到的类似。
使用data.Dataset迭代器的优点在于,管道可以处理通常用于准备数据的大部分管道,例如批量和改组。 我们也已经看到,各种操作可以链接在一起。
保存和加载 Keras 模型
TensorFlow 中的 Keras API 具有轻松保存和恢复模型的能力。 这样做如下,并将模型保存在当前目录中。 当然,这里可以通过更长的路径:
model.save('./model_name.h5')
这将保存模型体系结构,权重,训练状态(loss,optimizer)和优化器的状态,以便您可以从上次中断的地方继续训练模型。
加载保存的模型的步骤如下。 请注意,如果您已经编译了模型,那么负载将使用保存的训练配置来编译模型:
from tensorflow.keras.models import load_model
new_model = load_model('./model_name.h5')
也可以仅保存模型权重并以此加载它们(在这种情况下,必须构建体系结构以将权重加载到其中):
model.save_weights('./model_weights.h5')
然后使用以下内容加载它:
model.load_weights('./model_weights.h5')
Keras 数据集
可从 Keras 中获得以下数据集:boston_housing,cifar10,cifar100,fashion_mnist,imdb,mnist和reuters。
它们都可以通过load_data()函数访问。 例如,要加载fashion_mnist数据集,请使用以下命令:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
可以在这个页面中找到更多详细信息。
总结
在本章中,我们使用通用注释和见解探索了 Keras API,然后以四种不同的方式表示相同的基本体系结构,以训练mnist数据集。
在下一章中,我们将通过探索许多监督的学习场景,包括线性回归,逻辑回归和 K 近邻,开始认真使用 TensorFlow。
三、TensorFlow 2 和 ANN 技术
在本章中,我们将讨论并举例说明 TensorFlow 2 的那些部分,这些部分对于构建,训练和评估人工神经网络及其推理的利用目的是必需的。 最初,我们不会提供完整的申请。 相反,在将所有概念和技术放在一起并在随后的章节中介绍完整的模型之前,我们将重点关注它们。
在本章中,我们将介绍以下主题:
- 将数据呈现给人工神经网络(ANN)
- 神经网络层
- 梯度下降算法的梯度计算
- 损失函数
将数据呈现给人工神经网络
Google 推荐的将数据呈现给 TensorFlow ANN 的规范方法是通过由tf.data.Dataset对象和tf.data.Iterator方法组成的数据管道。 tf.data.Dataset对象由一系列元素组成,其中每个元素包含一个或多个张量对象。 tf.data.Iterator是一种用于遍历数据集以便可以访问其中的连续单个元素的方法。
我们将研究构建数据管道的两种重要方法,首先是从内存中的 NumPy 数组,其次是从逗号分隔值(CSV)文件。 我们还将研究二进制 TFRecord 格式。
将 NumPy 数组与数据集结合使用
首先让我们看一些简单的例子。 这是一个 NumPy 数组:
import tensorflow as tf
import numpy as np
num_items = 11
num_list1 = np.arange(num_items)
num_list2 = np.arange(num_items,num_items*2)
这是使用from_tensor_slices()方法创建数据集的方法:
num_list1_dataset = tf.data.Dataset.from_tensor_slices(num_list1)
这是使用make_one_shot_iterator()方法在其上创建iterator的方法:
iterator = tf.compat.v1.data.make_one_shot_iterator(num_list1_dataset)
这是使用get_next方法将它们一起使用的方法:
for item in num_list1_dataset:
num = iterator1.get_next().numpy()
print(num)
请注意,由于我们使用的是单次迭代器,因此在同一程序运行中两次执行此代码会引发错误。
也可以使用batch方法批量访问数据。 请注意,第一个参数是每个批次中要放置的元素数,第二个参数是不言自明的drop_remainder参数:
num_list1_dataset = tf.data.Dataset.from_tensor_slices(num_list1).batch(3, drop_remainder = False)
iterator = tf.compat.v1.data.make_one_shot_iterator(num_list1_dataset)
for item in num_list1_dataset:
num = iterator.get_next().numpy()
print(num)
还有一种zip方法,可用于一起显示特征和标签:
dataset1 = [1,2,3,4,5]
dataset2 = ['a','e','i','o','u']
dataset1 = tf.data.Dataset.from_tensor_slices(dataset1)
dataset2 = tf.data.Dataset.from_tensor_slices(dataset2)
zipped_datasets = tf.data.Dataset.zip((dataset1, dataset2))
iterator = tf.compat.v1.data.make_one_shot_iterator(zipped_datasets)
for item in zipped_datasets:
num = iterator.get_next()
print(num)
我们可以使用concatenate方法如下连接两个数据集:
ds1 = tf.data.Dataset.from_tensor_slices([1,2,3,5,7,11,13,17])
ds2 = tf.data.Dataset.from_tensor_slices([19,23,29,31,37,41])
ds3 = ds1.concatenate(ds2)
print(ds3)
iterator = tf.compat.v1.data.make_one_shot_iterator(ds3)
for i in range(14):
num = iterator.get_next()
print(num)
我们还可以完全取消迭代器,如下所示:
epochs=2
for e in range(epochs):
for item in ds3:
print(item)
请注意,此处的外部循环不会引发错误,因此在大多数情况下将是首选方法。
将逗号分隔值(CSV)文件与数据集一起使用
CSV 文件是一种非常流行的数据存储方法。 TensorFlow 2 包含灵活的方法来处理它们。 这里的主要方法是tf.data.experimental.CsvDataset。
CSV 示例 1
使用以下参数,我们的数据集将由filename文件每一行中的两项组成,均为浮点类型,忽略文件的第一行,并使用第 1 列和第 2 列(当然,列编号为 ,从 0 开始):
filename = ["./size_1000.csv"]
record_defaults = [tf.float32] * 2 # two required float columns
dataset = tf.data.experimental.CsvDataset(filename, record_defaults, header=True, select_cols=[1,2])
for item in dataset:
print(item)
CSV 示例 2
在此示例中,使用以下参数,我们的数据集将包含一个必需的浮点数,一个默认值为0.0的可选浮点和一个int,其中 CSV 文件中没有标题,而只有列 1 ,2 和 3 被导入:
#file Chapter_2.ipynb
filename = "mycsvfile.txt"
record_defaults = [tf.float32, tf.constant([0.0], dtype=tf.float32), tf.int32,]
dataset = tf.data.experimental.CsvDataset(filename, record_defaults, header=False, select_cols=[1,2,3])
for item in dataset:
print(item)
CSV 示例 3
对于最后一个示例,我们的dataset将由两个必需的浮点数和一个必需的字符串组成,其中 CSV 文件具有header变量:
filename = "file1.txt"
record_defaults = [tf.float32, tf.float32, tf.string ,]
dataset = tf.data.experimental.CsvDataset(filename, record_defaults, header=False)
or item in dataset:
print(item[0].numpy(), item[1].numpy(),item[2].numpy().decode() )
# decode as string is in binary format.
TFRecord
另一种流行的存储数据选择是 TFRecord 格式。 这是一个二进制文件格式。 对于大文件,这是一个不错的选择,因为二进制文件占用的磁盘空间更少,复制所需的时间更少,并且可以非常有效地从磁盘读取。 所有这些都会对数据管道的效率以及模型的训练时间产生重大影响。 该格式还以多种方式与 TensorFlow 一起进行了优化。 这有点复杂,因为在存储之前必须将数据转换为二进制格式,并在回读时将其解码。
TFRecord 示例 1
我们在此处显示的第一个示例将演示该技术的基本内容。 (文件为TFRecords.ipynb)。
由于 TFRecord 文件是二进制字符串序列,因此必须在保存之前指定其结构,以便可以正确地写入并随后回读。 TensorFlow 为此具有两个结构,即tf.train.Example和tf.train.SequenceExample。 您要做的是将每个数据样本存储在这些结构之一中,然后对其进行序列化,然后使用tf.python_io.TFRecordWriter将其保存到磁盘。
在下面的示例中,浮点数组data被转换为二进制格式,然后保存到磁盘。 feature是一个字典,包含在序列化和保存之前传递给tf.train.Example的数据。 “TFRecord 示例 2”中显示了更详细的示例:
TFRecords 支持的字节数据类型为FloatList,Int64List和BytesList。
# file: TFRecords.ipynb
import tensorflow as tf
import numpy as np
data=np.array([10.,11.,12.,13.,14.,15.])
def npy_to_tfrecords(fname,data):
writer = tf.io.TFRecordWriter(fname)
feature={}
feature['data'] = tf.train.Feature(float_list=tf.train.FloatList(value=data))
example = tf.train.Example(features=tf.train.Features(feature=feature))
serialized = example.SerializeToString()
writer.write(serialized)
writer.close()
npy_to_tfrecords("./myfile.tfrecords",data)
读回记录的代码如下。 构造了parse_function函数,该函数对从文件读回的数据集进行解码。 这需要一个字典(keys_to_features),其名称和结构与保存的数据相同:
dataset = tf.data.TFRecordDataset("./myfile.tfrecords")
def parse_function(example_proto):
keys_to_features = {'data':tf.io.FixedLenSequenceFeature([], dtype = tf.float32, allow_missing = True) }
parsed_features = tf.io.parse_single_example(serialized=example_proto, features=keys_to_features)
return parsed_features['data']
dataset = dataset.map(parse_function)
iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
# array is retrieved as one item
item = iterator.get_next()
print(item)
print(item.numpy())
print(item[2].numpy())
TFRecord 示例 2
在这个例子中,我们看一下这个字典给出的更复杂的记录结构:
filename = './students.tfrecords'
data = {
'ID': 61553,
'Name': ['Jones', 'Felicity'],
'Scores': [45.6, 97.2]
}
使用此方法,我们可以再次使用Feature()方法构造一个tf.train.Example类。 注意我们如何编码字符串:
ID = tf.train.Feature(int64_list=tf.train.Int64List(value=[data['ID']]))
Name = tf.train.Feature(bytes_list=tf.train.BytesList(value=[n.encode('utf-8') for n in data['Name']]))
Scores = tf.train.Feature(float_list=tf.train.FloatList(value=data['Scores']))
example = tf.train.Example(features=tf.train.Features(feature={'ID': ID, 'Name': Name, 'Scores': Scores }))
将此记录串行化并将其写入光盘与“TFRecord 示例 1”相同:
writer = tf.io.TFRecordWriter(filename)
writer.write(example.SerializeToString())
writer.close()
为了回读这一点,我们只需要构造我们的parse_function函数即可反映记录的结构:
dataset = tf.data.TFRecordDataset("./students.tfrecords")
def parse_function(example_proto):
keys_to_features = {'ID':tf.io.FixedLenFeature([], dtype = tf.int64),
'Name':tf.io.VarLenFeature(dtype = tf.string),
'Scores':tf.io.VarLenFeature(dtype = tf.float32)
}
parsed_features = tf.io.parse_single_example(serialized=example_proto, features=keys_to_features)
return parsed_features["ID"], parsed_features["Name"],parsed_features["Scores"]
下一步与之前相同:
dataset = dataset.map(parse_function)
iterator = tf.compat.v1.data.make_one_shot_iterator(dataset)
item = iterator.get_next()
# record is retrieved as one item
print(item)
输出如下:
(<tf.Tensor: id=264, shape=(), dtype=int64, numpy=61553>, <tensorflow.python.framework.sparse_tensor.SparseTensor object at 0x7f1bfc7567b8>, <tensorflow.python.framework.sparse_tensor.SparseTensor object at 0x7f1bfc771e80>)
现在我们可以从item中提取数据(注意,必须解码(从字节开始)字符串,其中 Python 3 的默认值为utf8)。 还要注意,字符串和浮点数数组将作为稀疏数组返回,并且要从记录中提取它们,我们使用稀疏数组value方法:
print("ID: ",item[0].numpy())
name = item[1].values.numpy()
name1= name[0].decode()returned
name2 = name[1].decode('utf8')
print("Name:",name1,",",name2)
print("Scores: ",item[2].values.numpy())
单热编码
单热编码(OHE)是根据数据标签构造张量的方法,在每个标签中,与标签值相对应的每个元素中的数字为 1,其他地方为 0; 也就是说,张量中的位之一是热的(1)。
OHE 示例 1
在此示例中,我们使用tf.one_hot()方法将十进制值5转换为一个单编码的值0000100000:
y = 5
y_train_ohe = tf.one_hot(y, depth=10).numpy()
print(y, "is ",y_train_ohe,"when one-hot encoded with a depth of 10")
# 5 is 00000100000 when one-hot encoded with a depth of 10
OHE 示例 2
在下面的示例中,还使用从时尚 MNIST 数据集导入的示例代码很好地展示了这一点。
原始标签是从 0 到 9 的整数,因此,例如2的标签在进行一次热编码时变为0010000000,但请注意索引与该索引处存储的标签之间的区别:
import tensorflow as tf
from tensorflow.python.keras.datasets import fashion_mnist
tf.enable_eager_execution()
width, height, = 28,28
n_classes = 10
# load the dataset
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
split = 50000
#split feature training set into training and validation sets
(y_train, y_valid) = y_train[:split], y_train[split:]
# one-hot encode the labels using TensorFlow.
# then convert back to numpy for display
y_train_ohe = tf.one_hot(y_train, depth=n_classes).numpy()
y_valid_ohe = tf.one_hot(y_valid, depth=n_classes).numpy()
y_test_ohe = tf.one_hot(y_test, depth=n_classes).numpy()
# show difference between the original label and a one-hot-encoded label
i=5
print(y_train[i]) # 'ordinary' number value of label at index i=5 is 2
# 2
# note the difference between the *index* of 5 and the *label* at that index which is 2
print(y_train_ohe[i]) #
# 0\. 0\. 1\. 0\. 0.0 .0 .0\. 0\. 0.
接下来,我们将检查神经网络的基本数据结构:神经元的层。
层
ANN 使用的基本数据结构是层,许多相互连接的层构成了一个完整的 ANN。 可以将一层设想为神经元的数组,尽管使用单词神经元可能会产生误导,因为在人脑神经元和构成一层的人工神经元之间只有很少的对应关系。 记住这一点,我们将在下面使用术语神经元。 与任何计算机处理单元一样,神经元的特征在于其输入和输出。 通常,神经元具有许多输入和一个输出值。 每个输入连接均带有权重w[i]。
下图显示了一个神经元。 重要的是要注意,激活函数f对于平凡的 ANN 而言是非线性的。 网络中的一般神经元接收来自其他神经元的输入,并且每个神经元的权重为w[i],如图所示,网络通过调整这些权重来学习权重,以便输入生成所需的输出:

图 1:人工神经元
通过将输入乘以权重,将偏差乘以其权重相加,然后应用激活函数,可以得出神经元的输出(请参见下图)。
下图显示了如何配置各个人工神经元和层以创建 ANN:
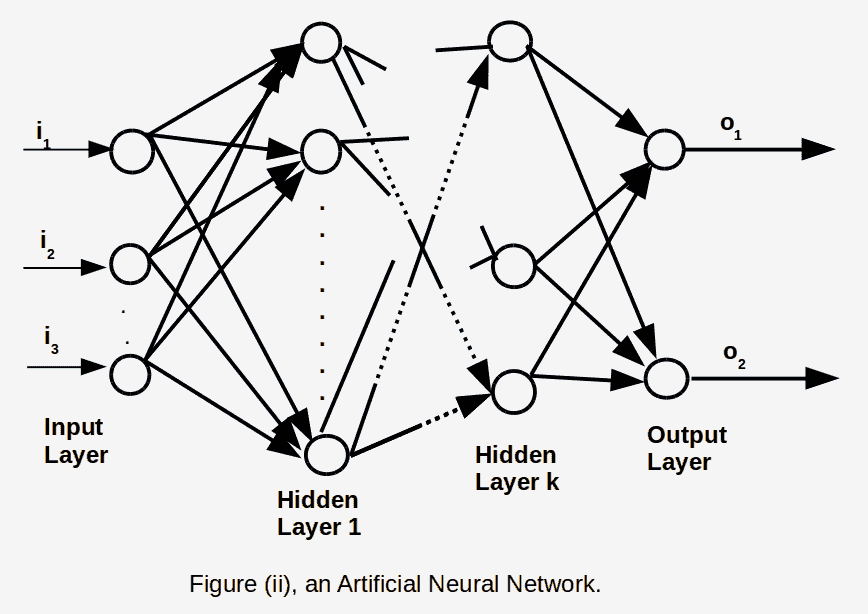
图 2:人工神经网络
层的输出由以下公式给出:

在此, W是输入的权重, X是输入向量, f是非线性激活函数。
层的类型很多,支持大量的 ANN 模型结构。 可以在这个页面中找到非常全面的列表。
在这里,我们将研究一些更流行的方法,以及 TensorFlow 如何实现它们。
密集(完全连接)层
密集层是完全连接的层。 这意味着上一层中的所有神经元都连接到下一层中的所有神经元。 在密集的网络中,所有层都是密集的。 (如果网络具有三个或更多隐藏层,则称为深度网络)。
layer = tf.keras.layers.Dense(n)行构成了一个密集层,其中n是输出单元的数量。
注意,密集层是一维的。 请参考“模型”的部分。
卷积层
卷积层是一层,其中层中的神经元通过使用通常为正方形的过滤器分组为小块,并通过在该层上滑动过滤器来创建。 每个色块由卷积,即乘以滤波器并相加。 简而言之,卷积网或 ConvNets 已经证明自己非常擅长图像识别和处理。
对于图像,卷积层具有部分签名tf.keras.layers.Conv2D(filters, kernel_size, strides=1, padding='valid')。
因此,在下面的示例中,该第一层具有一个大小为(1, 1)的过滤器,并且其填充'valid'。 其他填充可能性是'same'。
区别在于,使用'same'填充,必须在外部填充该层(通常用零填充),以便在卷积发生后,输出大小与该层大小相同。 如果使用'valid'填充,则不会进行填充,并且如果跨度和内核大小的组合不能完全适合该层,则该层将被截断。 输出大小小于正在卷积的层:
seqtial_Net = tf.keras.Sequential([tf.keras.layers.Conv2D( 1, (1, 1), strides = 1, padding='valid')
最大池化层
当窗口在层上滑动时,最大池化层在其窗口内取最大值,这与卷积发生的方式几乎相同。
空间数据(即图像)的最大池签名如下:
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
因此,要使用默认值,您只需拥有以下内容:
layer = tf.keras.maxPooling2D()
批量归一化层和丢弃层
批量归一化是一个接受输入并输出相同数量的输出的层,其中激活的平均值和单位方差为零,因为这对学习有益。 批量标准化规范了激活,使它们既不会变得很小也不会爆炸性地变大,这两种情况都阻止了网络的学习。
BatchNormalization层的签名如下:
tf.keras.layers.BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None)
因此,要使用默认值,只需使用以下命令:
layer = tf.keras.layers.BatchNormalization()
丢弃层是其中一定百分比的神经元在训练过程中(而不是在推理过程中)随机关闭的层。 由于不鼓励单个神经元对其输入进行专门化,因此这迫使网络在泛化方面变得更好。
Dropout层的签名如下:
tf.keras.layers.Dropout(rate, noise_shape=None, seed=None)
rate参数是神经元被关闭的部分。
因此,要使用它,例如,您需要:
layer = tf.keras.layers.Dropout(rate = 0.5)
随机选择的 50% 的神经元将被关闭。
Softmax 层
softmax 层是其中每个输出单元的激活对应于输出单元与给定标签匹配的概率的层。 因此,具有最高激活值的输出神经元是网络的预测。 当要学习的类互斥时使用此函数,以使 softmax 层输出的概率总计为 1。
它被实现为在密集层上的激活。
因此,例如,我们有以下内容:
model2.add(tf.keras.layers.Dense(10,activation=tf.nn.softmax))
这将添加具有 10 个神经元的密集 softmax 层,其中神经元的激活总数为 1。
接下来,我们将进一步讨论激活函数。
激活函数
重要的是要注意,神经网络具有非线性激活函数,即应用于神经元加权输入之和的函数。 除了平凡的神经网络模型外,线性激活单元无法将输入层映射到输出层。
有许多常用的激活函数,包括 Sigmoid,tanh,ReLU 和泄漏的 ReLU。 一个很好的总结,以及这些函数的图表,可以在这里找到。
建立模型
使用 Keras 创建 ANN 模型的方法有四种:
- 方法 1 :参数已传递给
tf.keras.Sequential - 方法 2 :使用
tf.keras.Sequential的.add方法 - 方法 3 :使用 Keras 函数式 API
- 方法 4 :通过将
tf.keras.Model对象子类化
有关这四种方法的详细信息,请参考第 2 章“TensorFlow 2 的高级 API,Keras”。
梯度下降算法的梯度计算
TenorFlow 的一大优势是它能够自动计算梯度以用于梯度下降算法,这当然是大多数机器学习模型的重要组成部分。 TensorFlow 提供了许多用于梯度计算的方法。
启用急切执行时,有四种自动计算梯度的方法(它们也适用于图模式):
tf.GradientTape:上下文记录了计算,因此您可以调用tf.gradient()来获取记录时针对任何可训练变量计算的任何张量的梯度tfe.gradients_function():采用一个函数(例如f())并返回一个梯度函数(例如fg()),该函数可以计算f()的输出相对于f()或其部分参数的梯度tfe.implicit_gradients():这非常相似,但是fg()会针对这些输出所依赖的所有可训练变量计算f()输出的梯度tfe.implicit_value_and_gradients():几乎相同,但fg()也返回函数f()的输出
我们将看看其中最流行的tf.GradientTape。 同样,在其上下文中,随着计算的进行,对这些计算进行记录(录音),以便可以使用tf.gradient()重放磁带,并实现适当的自动微分。
在以下代码中,当计算sum方法时,磁带将在tf.GradientTape()上下文中记录计算结果,以便可以通过调用tape.gradient()找到自动微分。
注意在[weight1_grad] = tape.gradient(sum, [weight1])中的此示例中如何使用列表。
默认情况下,仅可以调用tape.gradient():
# by default, you can only call tape.gradient once in a GradientTape context
weight1 = tf.Variable(2.0)
def weighted_sum(x1):
return weight1 * x1
with tf.GradientTape() as tape:
sum = weighted_sum(7.)
[weight1_grad] = tape.gradient(sum, [weight1])
print(weight1_grad.numpy()) # 7 , weight1*x diff w.r.t. weight1 is x, 7.0, also see below.
在下一个示例中,请注意,参数persistent=True已传递给tf.GradientTape()。 这使我们可以多次调用tape.gradient()。 同样,我们在tf.GradientTape上下文中计算一个加权和,然后调用tape.gradient()来计算每项相对于weight变量的导数:
# if you need to call tape.gradient() more than once
# use GradientTape(persistent=True)
weight1 = tf.Variable(2.0)
weight2 = tf.Variable(3.0)
weight3 = tf.Variable(5.0)
def weighted_sum(x1, x2, x3):
return weight1*x1 + weight2*x2 + weight3*x3
with tf.GradientTape(persistent=True) as tape:
sum = weighted_sum(7.,5.,6.)
[weight1_grad] = tape.gradient(sum, [weight1])
[weight2_grad] = tape.gradient(sum, [weight2])
[weight3_grad] = tape.gradient(sum, [weight3])
print(weight1_grad.numpy()) #7.0
print(weight2_grad.numpy()) #5.0
print(weight3_grad.numpy()) #6.0
接下来,我们将研究损失函数。 这些是在训练神经网络模型期间优化的函数。
损失函数
loss函数(即,误差测量)是训练 ANN 的必要部分。 它是网络在训练期间计算出的输出与其所需输出的差异程度的度量。 通过微分loss函数,我们可以找到一个量,通过该量可以调整各层之间的连接权重,以使 ANN 的计算输出与所需输出更紧密匹配。
最简单的loss函数是均方误差:
 ,
,
在此, y是实际标签值,y_hat是预测标签值。
特别值得注意的是分类交叉熵loss函数,它由以下方程式给出:

当所有可能的类别中只有一类正确时,使用loss函数;当softmax函数用作 ANN 的最后一层的输出时,将使用此loss函数。
请注意,这两个函数可以很好地微分,这是反向传播所要求的。
总结
在本章中,我们研究了许多支持神经网络创建和使用的技术。
我们涵盖了到 ANN 的数据表示,ANN 的各层,创建模型,梯度下降算法的梯度计算,损失函数以及保存和恢复模型的内容。 这些主题是在开发神经网络模型时将在后续章节中遇到的概念和技术的重要前提。
确实,在下一章中,我们将通过探索许多监督的学习场景,包括线性回归,逻辑回归和 K 近邻,来认真地使用 TensorFlow。