Asymmetric Non-Local Neural Networks for Semantic Segmentation
* Authors: [[Zhen Zhu]], [[Mengdu Xu]], [[Song Bai]], [[Tengteng Huang]], [[Xiang Bai]]
初读印象
comment:: (A Nonlocal)提出非对称非本地神经网络,包含非对称金字塔非本地块(APNB)和非对称融合非本地块(AFNB)。APNB可以减少运算量。AFNB融合不同级别的特征。
Why
卷积无法捕捉长距离依赖。nonlocal耗费计算资源。
What
只要key分支和value分支的尺寸一样,输出尺寸就不会变化。所以只要在key分支和value分支中只采样几个重要的点,就能在不牺牲性能的前提下节省计算资源。
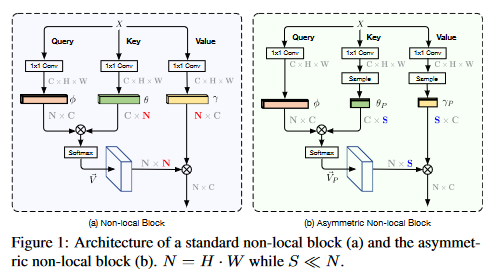 ###How
###How
动机
减少key向量和value向量的数量,就能大大减少矩阵运算的计算量。
前:

后:
 减少这两个向量的数量,可以看作只从原特征图中采样了几个重要的点。#### 解决方法
减少这两个向量的数量,可以看作只从原特征图中采样了几个重要的点。#### 解决方法
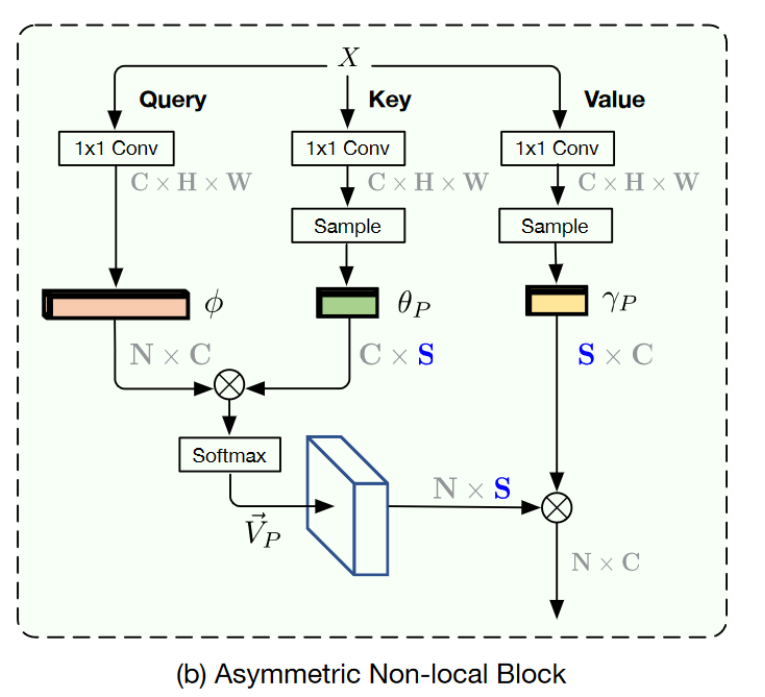
原注意力机制产生的三个张量:
 使用两个采样模块对其进行采样,使\(\theta_P\)和\(\gamma_P\)都是\(\tildeC×S\)的矩阵。
使用两个采样模块对其进行采样,使\(\theta_P\)和\(\gamma_P\)都是\(\tildeC×S\)的矩阵。
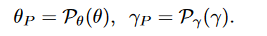
产生相似度矩阵(N×S):
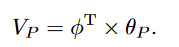 \(V_P\)正则化后,产生注意力矩阵:
\(V_P\)正则化后,产生注意力矩阵:
最终输出是\(O_P\)经过1×1卷积再与输入拼接:
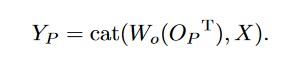 ####Asymmetric Pyramid Non-local Block
####Asymmetric Pyramid Non-local Block
将向量数量减少到S的确显著减少了计算量,但是如何选择S的大小?是否会因为信息丢失导致性能下降?为了解决这些问题,引入金字塔模块以增强全局表示。
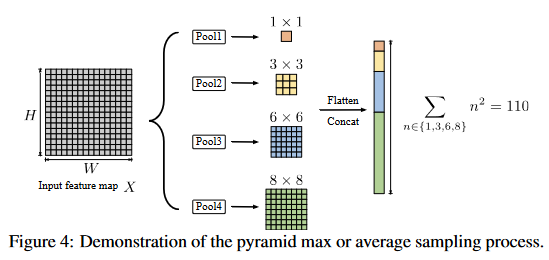
在\(\theta\)和\(\gamma\)后多个平均池化层,每个池化层的输出尺寸是\(n×n\),则最后得到的S大小为:
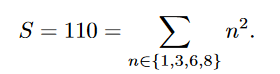
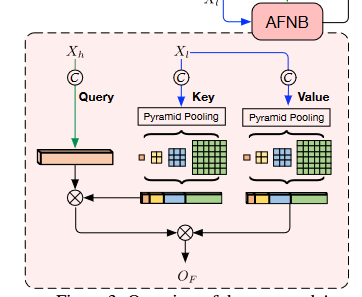
用池化得到的向量进行注意力运算。
Asymmetric Fusion Non-local Block
AFNB需要输入两个图:高层特征图和底层特征图。

同样,\(O_F\)也要经过经过1×1卷积再与输入拼接。
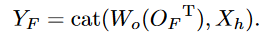 ####网络总体架构
####网络总体架构
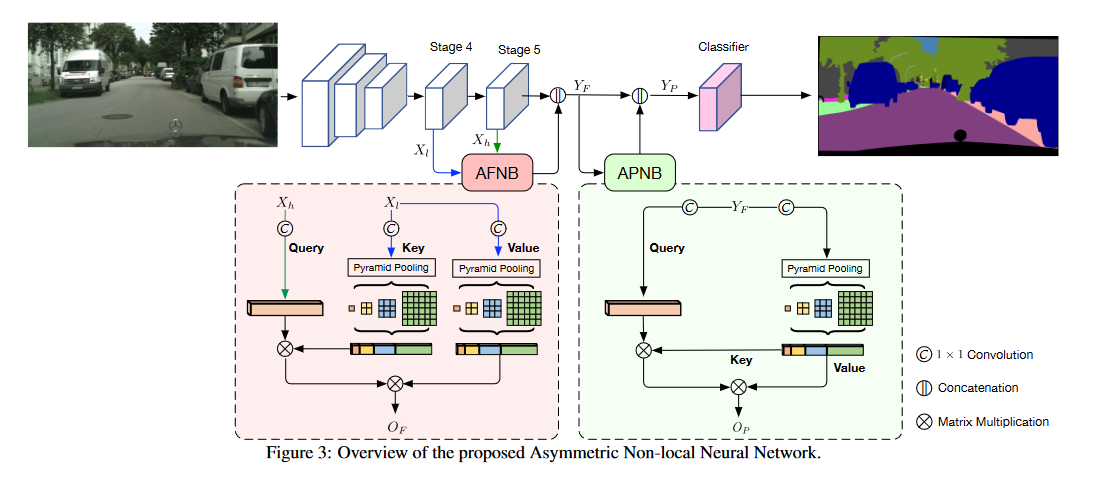
backbone:ResNet-101,最后两个stage不下采样并使用膨胀卷积。
使用AFNB融合stage4和stage5的输出,然后将其输入至APNB计算注意力。
Experiment
网络细节
辅助损失:stage4后有一个分支损失函数(\(\lambda=0.4\))

学习率策略:SGD,poly
初始学习率:0.01 for Cityscapes and PASCAL Context and 0.02 for ADE20K
数据增强:随机缩放(0.5-2.0),随机翻转,随机亮度。
batchsize:8 in Cityscapes experiments and 16 in the other datasets.
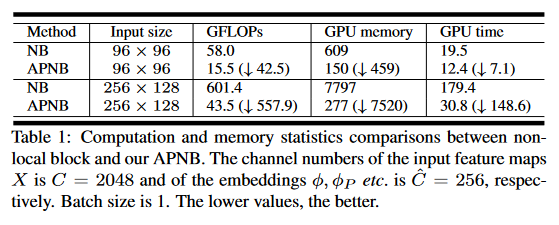
效率比较
单个模块的效率比较
 整个网络的效率比较,尽管推理时间和参数数量大于DenseAspp,但GPU存储器职业显然较小。
整个网络的效率比较,尽管推理时间和参数数量大于DenseAspp,但GPU存储器职业显然较小。
性能比较
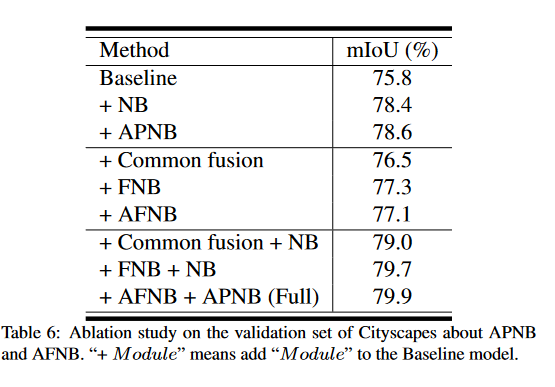
 ####消融实验
####消融实验
- 在FCN-like ResNet-101上增加各种模块。
Conclusion
减少了non-local中key和value向量的数量以减少运算量。同时又使用了金字塔池化结构来弥补损失的性能。在此基础上,还以注意力的形式融合了resnet中stage4和stage5之间的多尺度信息。
如果说EMANet是故事讲的有理有据,这篇就是缝合的天衣无缝,在某种程度上,是更适合模仿的论文。
- Segmentation 注意力 Asymmetric Non-Local Networkssegmentation注意力asymmetric non-local 注意力non-local networks第一次 convolutional segmentation biomedical networks convolutional segmentation networks semantic segmentation注意力attention network high-resolution segmentation注意力deformable non-local asymmetric tri-training unsupervised asymmetric adaptation segmentation