索引下推是Mysql5.6推出的一个查询优化方案,主要目的是减少数据库查询中不必要的数据读取和计算。
它的原理是将查询条件尽可能地推送到索引层进行过滤,减少了从磁盘读取的数据量和后续的计算开销。
简单通过一个案例说明一下实现原理
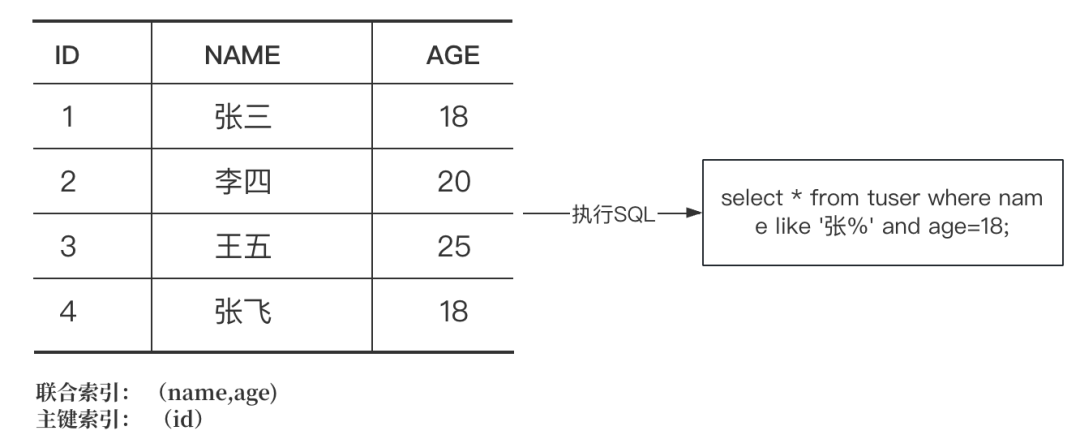
有一张用户表User,并创建了一个联合索引(name,age),现在需要从这个表里面检索名字是姓张,且年龄是18岁的所有用户。
在没有开启索引下推之前,Mysql的查询方式是:
先从二级索引中根据name匹配到姓张的人的所有数据行,得到主键索引id分别是1和4。
分别用1和4去聚簇索引中找到匹配的数据行。
然后再Mysql的Server层再对数据使用age=18这个条件进行过滤。
这种方式会涉及到多次回表,对性能的影响较大。而索引下推就是针对这个场景的优化,把过滤的功能下推到存储引擎。
具体的实现逻辑是,当根据(name,age)进行查询的时候,直接在存储引擎中根据name和age进行过滤,得到匹配的数据后在回表查询,在上面这个例子中,就只需要一次回表就能获取到匹配的数据。
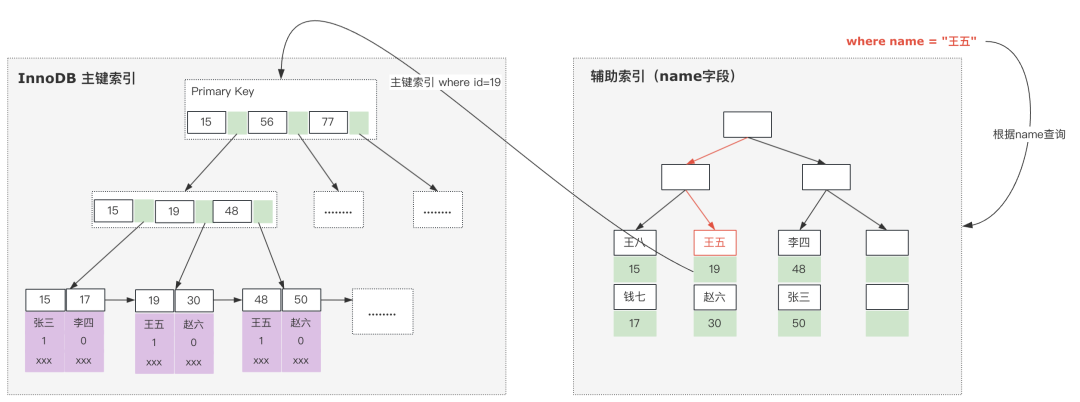
第二个,什么是回表,要理解回表,就需要了解InnoDB中的索引构成关系。
我们知道在InnoDB引擎中,所有的数据存储在聚簇索引中的,一个表有且只有一个聚簇索引,但是可以存在多个非聚簇索引。
当我们基于非聚簇索引进行查询数据时,如果返回的列不能满足查询结果列的需求的时候,就需要从聚簇索引中去查找。
比如执行select * from user where name = '王五'这个语句,由于返回的字段在二级索引中不存在,需要从聚簇索引中去获取,我们把这个过程称为回表。

第三个,什么是索引覆盖,理解了前面两个概念,就很容易理解索引覆盖了,在这样一个索引结构中,如果执行的sql语句是select name from user where name='王五'
由于sql语句中返回的结果列在二级索引中都能获取到,这样就不再需要回表,而是直接返回对应的数据内容即可。
这种情况就称为索引覆盖。