人类自从进入文明社会以来,有了书本、有了读书人,我们的价值观就一直是崇尚智力而不是暴力,认为你有再强的力量都不如我有知识。现在是时候重新审视这个认识了。
人的肌肉力量是非常有限的,你就是一天吃五顿饭又能多长几斤肉。工程机械的力量可以很大很大,但是能做的事情很有限,毕竟文明需要的更多的是精细而不是大力,没有谁以“我们国家有世界最大的起重机”为荣,更何况起重机的力量也有上限。对比之下,知识似乎是无穷的,你可以无上限地使用,所以崇尚知识很有道理。
但是现在有一种力量却是无上限的,它的增长速度远远超过了任何领域中知识积累的速度。这个力量就是计算机算力。
这跟审美、跟道德都没关系,纯粹是力量的对比。在现在这个局面下,你指望知识,就不如指望算力。
我要说的第二个教训是,算力就是王道。
✵
DeepMind有一位计算机科学家叫理查德·萨顿(Richard S. Sutton),他是「强化学习」这个AI算法的奠基人之一。

早在2019年,萨顿就在他的个人网站贴出一篇文章,叫《苦涩的教训》[1]。他说,过去70年的AI研究给我们最大的教训,就是撬动算力才是最有效的方法。
我们先看几段历史 ——
1997年,AI下国际象棋打败了卡斯帕罗夫,而当时大多数研究用计算机下国际象棋的科研人员对此不是感到兴奋,而是感到失望。他们原本的想法是把人类的国际象棋知识教给AI,让AI像人类棋手一样思考 —— 可是没想到,居然是一个只会大规模深度搜索的、纯粹依靠计算机的蛮力的程序最终胜出了。
这不是不讲理吗?从此一直都有人说,对国际象棋可以这么干,但是对围棋就不行了,因为围棋过于复杂……
二十年后,AlphaGo下围棋击败人类世界冠军,用的还是暴力破解。那个AI不但不懂、而且根本没学过什么围棋知识,而且它还反过来为人类创造了一些新的围棋知识。
在语音识别领域,上世纪七十年代的主流方法是把人类的语音知识 —— 什么单词、音素、声道 —— 教给计算机……结果最终胜出的却是根本不管那些知识,纯粹用统计方法自行发现规律的模型。
在计算机视觉领域,科学家一开始也发明了一些知识 —— 什么去哪里找图形的边缘、什么“广义圆柱体”等等 —— 结果那些知识也是啥用都没有,最终解决问题的是深度学习神经网络。
现在GPT语言模型更是如此:以前的研究者搞的那些知识 —— 什么句法分析、语义分析、自然语言处理(NLP)—— 全都没用上,GPT直接把海量的语料学一遍就什么都会了。
在无穷的算力面前,人类的知识都只不过是一些小聪明而已。
萨顿总结了一个历史规律,分四步 ——
1. 人类研究者总想构建一些知识教给AI;
2. 这些知识在短期内总是有用的;
3. 但是从长远看,这些人类构建的知识有个明显的天花板,会限制发展;
4. 让AI自行搜索和学习的暴力破解方法,最终带来了突破性进展。
算力才是王道,知识只是干扰。
✵
AI的暴力破解是怎么做到的呢?我们前面讲过三种最流行的神经网络算法:监督学习、无监督学习和强化学习。现在我们经历了那么多,可以把这三种“学习”方法重新审视一遍。
监督学习(supervised learning)是最基本的神经网络算法,它需要先把训练素材打上标签,让AI知道什么是对的。它的作用是「判断」,它追求的是「是不是」。
比如让AI从一大堆分子式中判断哪个有可能是一种新型抗生素,就是监督学习。你需要事先知道抗生素大概是什么样的,为此你需要喂给AI一些现成的例子用于训练。
但是如果数据量非常大,一个一个提前标记训练素材是人力难以承受的,为此有个办法叫「自监督学习(self-supervised learning)」,让AI自己去对照答案。比如GPT语言模型的训练过程中有一部分就属于自监督学习。最简单的思路是这样的:拿过来一篇文章,先把上半部分喂给模型,让模型根据上半部分预测文章的下半部分是什么,再把真实的下半部分给它看,让它从反馈中学习。
可以说自监督学习方法进一步解放了AI的生产力。2023年8月,众多研究者在《自然》杂志联名发表了一篇综述文章 [2],列举了当前AI在科学发现上的一系列应用,其中自监督学习起到了很大的作用。
下面这张示意图描写了AI参与新药研发的一个过程 ——
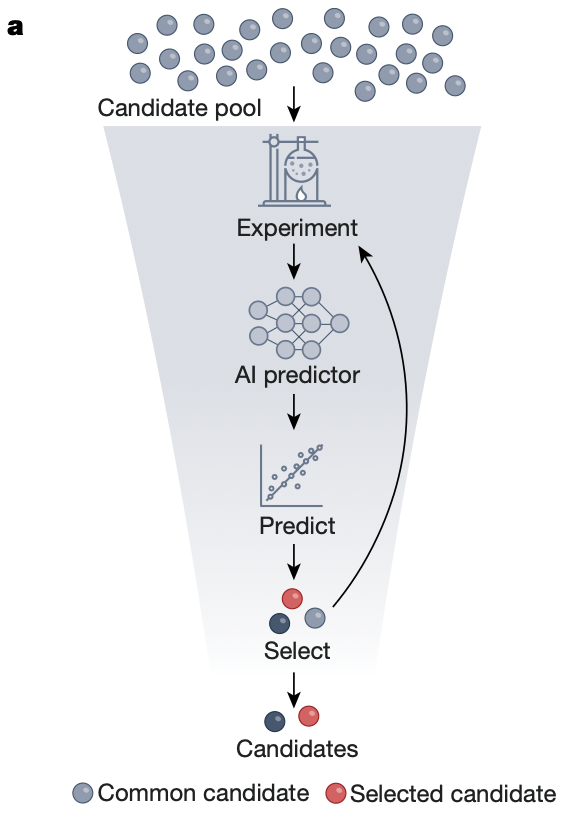
这里研究者先用自监督学习训练一个基本的AI模型。你手里有一大堆药物分子结构和实验结果的数据,但是你没有标记哪个实验结果是你想要的药物。你只需要把那些分子结构都一个个输入给AI模型,让它自己预测这个结构的实验结果,再跟数据中真实实验的结果比较,这样让它对药物结构和实验结果之间的关系有个基本印象。然后你再用有标记的少量数据对这个基本模型进行监督学习的微调,让它学会精确判断哪种结构最有可能得到我们想要的实验结果。最终的AI就可以对海量候选对象进行筛选,判断谁有可能是我们想要的新药了。
无监督学习(unsupervised learning)就更厉害了,因为它根本不需要你对训练素材进行任何预处理,你不要告诉AI你想要什么,直接一股脑地喂给AI就行,AI会自行发现素材中的规律。GPT之所以能学习天量的语料,就是主要使用了无监督学习。
无监督学习主要用于「生成」,它追求的是「像不像」。GPT生成文章、Midjourney生成照片是生成,给几块甲骨文片段让AI帮助补全龟甲中残缺的部分也是生成,给定一小段碱基对让AI生成蛋白质结构也是生成。生成性AI可以做很多事情。
强化学习(reinforcement learning)则是寻求对一些指标进行优化,让它们处于一定的范围之内,它的作用是「控制」,它追求的是「好不好」。像下围棋、自动驾驶、包括我们上一讲说的用AI控制核聚变等离子体构型,都是强化学习。
这些方法的本质都是用一定的输入输出数据训练一个神经网络,再用这个神经网络读取新的输入并生成输出。在这个过程中你眼中可以只有数据:你甚至不需要关心那些数据出自哪个学科,不知道它们的物理意义是什么……
2023年8月,马斯克展示了特斯拉最新版的自动驾驶AI(FSD Beta V12)[3]。这一版的特点是整个程序中没有一行代码告诉AI遇到减速带慢行、避让自行车、交通信号是什么意思等等 —— 系统没有注入任何交通规则,神经网络自己从输入到输出悟出来了一切。
这些方法的细节是相当精巧的,但是跟任何学科的人类知识相比,这些绝对是非常简单的方法。这些方法之所以厉害,根本性的原因是算力:是超强的运算速度和便宜而海量的数据存储成就了这一切。
✵
在算力的加持之下,2022年底以来GPT的表现,给了我们第三个教训:人是简单的。
GPT-3有1750亿个参数。OpenAI没有公布,但是网上传说GPT-4有1.8万亿个参数。这些无疑是非常大的数字,但是在指数增长的算力面前,这些是有限的数字。而就是这样有限的模型,竟然就抓住了人类几乎所有平常的知识。
GPT-4有人类的常识,能看懂照片,它能做包括编程和写作在内人能做的很多事情,它懂的比任何人都多……我认为它就是AGI。它是一个语言模型,它是用语料训练出来的,但是不知怎么,它抓住了语言背后的、难以言传的东西。它可以用语言表达一些我们人类还没有来得及用语言表达的东西。
AI语言、AI画图、AI判断和AI控制,做的是不一样的事情但是基本原理是一样的。为什么?沃尔夫勒姆对此的洞见是,AI只是抓住了“像人”的东西。
而这说明「人」其实是简单的。简单到这么有限的算力就能把你搞明白。「人」究竟是什么?我们能不能借助AI对人有个突破性的新认识?
这肯定意味着一些更大的可能性,但是我们现在所能看到的,是近期有两个展望。
✵
一个是AGI会在所有领域参与人类工作。
当前国内外主流公司都专注于搞自己的大模型,但是对模型的应用还远远没有展开。这可能是因为当前AI算力还太贵,GPT一次能记住的用户本地信息还很有限,不容易搞强烈量身定制的服务。
不过已经有人在做了。一个临时性的办法是把本地信息“矢量化”,也就是进行某种程度的压缩,让GPT能多记住一些;但更根本的办法是把GPT拿过来用本地信息微调。最近OpenAI已经开放了GPT-3.5的微调服务。
所以我们会很快看到像个人助手、家庭医生、一对一家教之类切实为你量身定制、掌握专业知识的AI服务,那才是真正改变生活方式。
✵
另一个展望是所有科研领域都应该用AI。
DeepMind做的事情,基本上等于手里拿着个大规模杀伤性武器,对各个科研领域进行碾压式的打击。除了被广泛报道的围棋、电子游戏、蛋白质折叠、天气预报、包括我们前面讲的控制核聚变等离子体,他们近期还用AI帮助破解了2500年前用楔形文字写成的文本 [4],还开始帮数学家证明定理了 [5]……

还有哪个领域是DeepMind不能进的?他们不是不能进,而是暂时来不及进。DeepMind就如同当初孟子梦想的那个「王道」之师,「东面征而西夷怨,南面征而北狄怨」:他们杀向生物学的时候,物理学家说你们怎么还不过来解决我们的问题,他们杀向考古学的时候,数学家说我们也能用上AI啊!
请问历史上还有哪个东西是这样的?
可能是因为算力还比较贵,更可能是因为大多数人还没学会训练AI,现在的局面是少数会用AI的人四处挑选科研课题做。但是下一步,必定是各路科研人员自己学会用AI,大杀器必定扩散。
如果我是个理工科研究生,我现在立即就要自己学着训练一个AI模型。趁着大多数人还不会用,这是一个能让你在任何领域大杀四方的武器。
✵
世间几乎所有力量的增长都会迅速陷入边际效益递减,从而变慢乃至于停下来,于是都是有上限的。唯独计算机算力的增长,目前似乎还没有衰减的迹象。摩尔定律依然强劲。