基于端到端神经网络的机器阅读理解模型大都采用图 1 所示的 4 层架构,详细解释见论文http://ss.zhizhen.com/detail_38502727e7500f26ec06ec0224871b794fe90187181395f71921b0a3ea255101fc1cf1fbb4666ae6c9e750461f20dd51735c417fbd207ec89cfc85a99b71a5aeedea3cb696d09e71623c57fdbc46efdc?&apistrclassfy=0_18_17,0_18_17
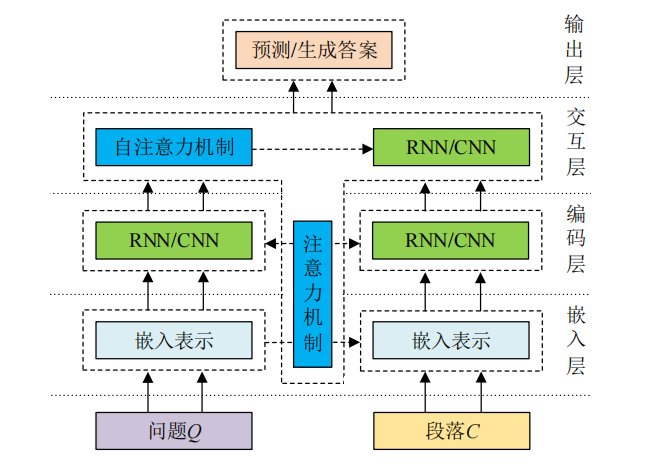
- 嵌入层是什么
嵌入层将单词表示成高维、稠密的实值向量。字符嵌入和词嵌入(Word2Vec 词向量、GloVe 词向量、Fasttext 词向量)以及上下文嵌入、特征嵌入
特征嵌入:特征嵌入本质上就是将单词在句子中的一些固有特征表示成低维度的向量,包括单词的位置特征(position)[14]、词性特征(POS)、命名实体识别特征(NER)、完全匹配特征(em)以及标准化术语频率(NTF)[61]等等,一般会通过拼接的方式将其与字符嵌入、词嵌入、上下文嵌入一起作为最后的词表征,例如,将 GloVe 词向量 GloVe(w)、BERT 上下文向量 BERTw 以及上述特征向量 fw 拼接作为输入,则可表示为
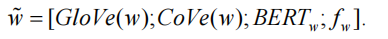
- 什么是消融实验(https://blog.csdn.net/qq_42072073/article/details/119210866)
消融实验的核心是控制变量,提出多个思路提升某个模型的时候,为了验证这几个思路分别都是有效的,做的控制变量实验的工作。比如说你为了提升baseline的性能,给它加了两个模块A,B,加完之后效果果然提高了很多。于是你急急忙忙开始写论文,写到你的贡献,你给了两条:1.模块A,2.模块B。
但是这样写有个问题:尽管AB同时加上去对模型有提升效果,但是你并没有证明A、B两个模块分别都是有意义的。
所以为了验证A、B两个模块是不是真的都有用,你需要做ablation study。方法也很简单:
- 在baseline的基础上加上模块A,看效果。
- 在baseline的基础上加上模块B,看效果。
- 在baseline的基础上同时加上模块AB,看效果。
然后结果可能是,实验1和实验2的结果都不如实验3,那么说明AB都是有用的;然而也有可能你会发现实验1的结果和实验3一样,甚至更好。这就说明你的想法是有问题的,模块B其实并没有起到作用,提升只来自于模块A。
综上所述,ablation study就是你在同时提出多个思路提升某个模型的时候,为了验证这几个思路分别都是有效的,做的控制变量实验的工作。
-
Trischler 等人[103]认为,在完形填空任务中使用何种单词级别的嵌入并不会对后续推理产生很大影响,因此他们简单地按照均匀分布模型将词嵌入随机初始化,最终模型的结果仍然取得了当时的 State-of-the-art
- 什么是OOV(out-of-vocab)问题(https://blog.csdn.net/qq_38244371/article/details/92806233)
未登录词就是训练时未出现,测试时出现了的单词。在自然语言处理或者文本处理的时候,我们通常会有一个字词库(vocabulary)。这个vocabulary要么是提前加载的,或者是自己定义的,或者是从当前数据集提取的。假设之后你有了另一个的数据集,这个数据集中有一些词并不在你现有的vocabulary里,我们就说这些词汇是Out-of-vocabulary,简称OOV。
- 阅读理解比较重要的模型
BiDAF 模型