最终的实现是新增了一个lua的模块,这个模块能够在Windows下执行utf-8编码的字符串命令,未来可能会增加IO相关的函数。
其实这是一个老生常谈的问题了,Windows在中文环境下的代码页936也就是GBK编码,我们平时看到的ANSI编码的文本文件里面其实就是GBK编码。
在我刚入门编程的时候就遇到了这种问题。
痛苦的回忆开始(可跳过)
本文较长,6000多字,写了一个多星期,痛苦的回忆这节基本上都是我的碎碎念,没什么有营养的东西,请直接跳转到正文。
1、html中遇到的编码问题
例如下示h5代码:
<!DOCTYPE html>
<html>
<head>
<title>哈哈哈哈</title>
</head>
<body>
<h1>NGINX中文网页测试</h1>
<p>手持两把锟斤拷</p>
</body>
</html>
在网页上看是这样的:
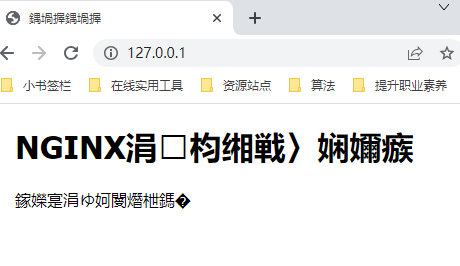
当时年轻不懂事,又是notepad手写html代码,就直接把编码改成了GBK,但是实际上应该使用<meta charset="utf-8" />,那也就类似于javac编译时加个参数咯。
对于网页的编码问题,php也是同理,倒不是什么大问题。
2、Java中遇到的编码问题
比如说编写一个java程序,源程序使用UTF-8编码,然后使用System.out输出一个GBK中没有的字符,比如说:
public class Main{
public static void main(String[] args){
System.out.println("输出中文测试");
System.out.println("୧꒰•̀ᴗ•́꒱୨");
}
}
然后用javac编译,就会报错:
Main.java:6: 错误: 编码GBK的不可映射字符
System.out.println("喹ш挵鈥⑻?岽椻?⑻侁挶喹?");
甚至注释掉都无法通过编译,但解决方法又很简单,有两种,一是直接把源程序保存为ANSI编码,即GBK,就可以编译成功了,但是带来的问题是,原先的字符串被破坏了,并且无法恢复,来看一下原理,比如说这个:୧꒰字符串,它由两个字符构成,其UTF-8编码为:E0 AD A7 EA 92 B0,三个字节组成一个字符,而如果将其转为GBK编码,就会变成两个问号?看编码可以知道变成了3F 3F,这个过程不可逆,即就算转回UTF-8,还是3F 3F;二是在编译的时候添加参数,指定编码-encoding utf-8,当然对于Linux来说,如果源文件是GBK编码,编译时也会出现相同问题,encoding选择gbk便行了,不过从个人强迫症的角度看,源文件还是存为UTF-8为好,Windows上加个编译参数也谈不上损失。
思考实验1——encoding参数的作用
我猜想encoding参数的作用是不同编码的文件编译成同一个class文件。
源代码如下:
public class Main{
public static void main(String[] args){
System.out.println("输出中文测试");
}
}
将源代码改成ANSI、UTF-8、UTF-16然后使用如下命令分别编译
javac Main.java #ANSI
javac -encoding GBK Main.java #ANSI
javac -encoding UTF-8 Main.java #UTF-8
javac -encoding UTF-16 Main.java #UTF-16
编译之后的class文件二进制完全一致。也就是说,当指定了encoding参数,javac就会编译出一种标准的class文件,由于字符串没有进行加密的操作,于是我直接用文本方式打开class文件,确实class文件中的字符串为UTF-8编码。如下图:
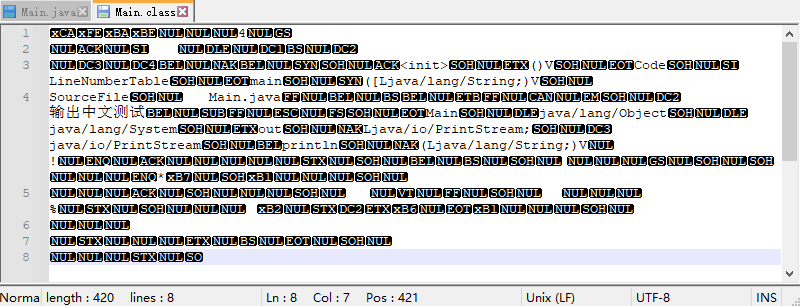
也就是说javac编译出class文件的时候,是将字符串原来的编码转成UTF-8编码,在指定了encoding参数的时候,javac能够清楚地知道源码文件是什么编码,进而把该编码转为UTF-8;而不指定 encoding参数的话,假设能够编译通过,那javac应该是用当前系统的编码字符集去进行编译,然后将字符串转为UTF-8,比如说源文件本来就是UTF-8了,然后javac把它当作GBK,然后再转为UTF-8。
为了验证这个想法,我采用不加encoding参数编译UTF-8编码的文件。然后文本方式打开class文件:
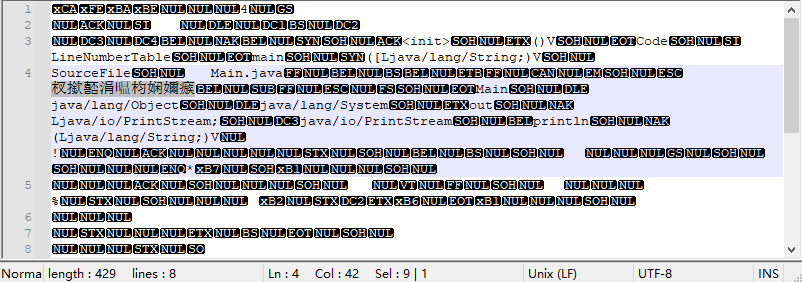
这个乱码是UTF-8编码,我们可以模拟一下,新建一个txt文件,编码为UTF-8,文件就写输出中文测试,将其以GBK编码打开,得到`杈撳嚭涓枃娴嬭,复制下来,将编码再改为UTF-8,粘贴,可以看到一字不差。
总结
如果不指定encoding参数的情况下,javac会按照系统的编码字符集进行encoding,javac进行encoding的时候,就会把源码文件按照encoding的编码进行编译,最终得到一个class文件,这个class文件中的内容为UTF-8编码(主要体现在字符串的编码上)。
思考实验2——java运行时对编码做了什么
在Windows下,中文环境下代码页936,即GBK编码,那么cmd中如果能够正常显示一个中文字符串的话,那么这个中文字符串就一定是GBK编码(从结果看是这样,但是936下能够显示韩文,所以CMD显示用的字符编码应该是别的编码)。假设我们通过encoding编译出一个标准的class文件(即class文件中的字符串 以UTF-8编码进行解读不会有问题),那么class文件中的字符串为UTF-8编码,能够在cmd中正常输出,说明java运行时也进行了编码转换,将UTF-8编码转为GBK编码再输出到cmd。
其实也就是说,一般情况下运行class文件的时候,我们不用执行其他什么操作,java运行时会默认认为执行的class文件是一个标准的class文件,然后会根据所处的环境自动转换编码。
那特殊情况下就是,这个class文件中包含的字符串并不是UTF-8编码,那么在java运行时,就必须指定参数,告知javaclass文件的编码,这样才能够成功运行,参数为-Dfile.encoding=XXX。
但这个又要分情况,比如说,我在Windows下将UTF-8编码的源文件以-encoding GBK进行编译,得到的class文件。
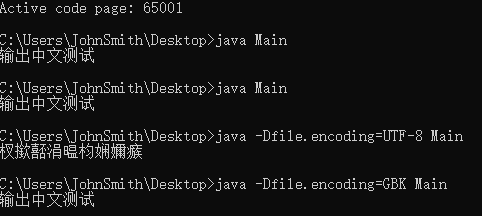
在Windows下,中文环境936代码页,CMD执行这个class文件,不加参数和-Dfile.encoding=UTF-8还有-Dfile.encoding=GBK输出的内容都是杈撳嚭涓枃娴嬭瘯:
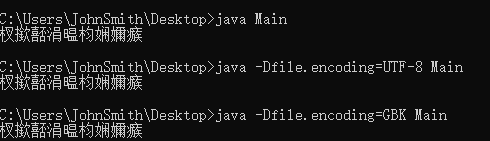
而如果将cmd的代码页切换为65001,不加参数和-Dfile.encoding=GBK的情况下输出正常中文,-Dfile.encoding=UTF-8输出乱码:
在Linux下,我们知道Linux的环境是UTF-8嘛,所以正常情况下运行这个class文件就会乱码,所以就要告知java这个class文件是GBK编码的,如下图:
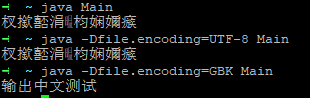
这个结果让我觉得有点诧异,因为WindowsCMD的代码页为65001时,环境应该UTF-8,所以不加参数输出应该是乱码,即和Linux应该是一样的。
总结
java运行时会根据指定文件字符编码去解析class文件,将其中的字符串转换为当前系统的编码字符集,如果没有指定的话,就会以当前系统的编码字符集去进行解析。
3、C/C++遇到的编译问题
C/C++遇到的问题和java是类似的,源文件如下,为GBK编码:
#include <stdio.h>
int main(){
printf("输出中文测试");
}
不加其他参数,直接使用gcc编译后运行,cmd中输出是正常的,而把源文件改为UTF-8编码后,cmd输出是乱码,也就是说gcc进行编译的时候,如果没有添加什么参数的话,会直接按照源文件是什么编码来进行编译,但不是什么编码都能够进行gcc编译的,比如说我尝试用gcc编译UTF-16编码的源文件,会报错,当然正常情况下,在中国大陆的我们,在Windows下进行gcc编译要么是GBK编码,要么是UTF-8编码。
如果想输出正常的中文的话,类似于javac和java的操作,gcc编译的时候也可以添加参数fexec-charset=xxx,如参数的名称所示,意思是设置编译产生的可执行程序的字符集,比如说源程序是UTF-8,那我编译的时候设置的参数为fexec-charset=GBK,这样编译产生的可执行程序就可以在代码页936的cmd中正常输出中文。
而对于如下代码:
#include <stdio.h>
int main(){
printf("୧꒰•̀ᴗ•́꒱୨");
}
编译时添加参数fexec-charset=GBK则会编译失败,这与java是类似的,因为目标字符在GBK字符集中没有映射,所以无法将୧꒰•̀ᴗ•́꒱୨编译出一个GBK的版本出来,要想编译通过只能UTF-8,但是普通的中文在cmd中又不能正常显示,解决方法有二:一是不去使用类似的字符,编译时添加参数fexec-charset=GBK,二是坚持使用UTF-8,在cmd中使用chcp 65001,将环境改为UTF-8。我个人的做法是不去使用类似的字符,因为cmd下,即使是chcp 65001,也无法显示类似的字符,应该是显示的时候最终系统会将UTF-8字符串转为GBK显示到cmd,但是GBK中没有对应的字符映射,所以就显示问号了,所以我个人不喜欢改代码页的做法,治标不治本。
总结
其实没什么好总结的,就是Windows下本地代码页相关的编码问题造成的不便。
痛苦的回忆结束
正文
CMD下的乱码与文件名
从CMD谈起吧,比如要在CMD中创建一个文件,使用echo kksk > XXX,即echo输出重定向到文件。在代码页936下,CMD可以正常输出重定向到英文和中文的文件,打开CMD,输入echo kksk > 국민以及echo kksk > ୧꒰•̀ᴗ•́꒱୨,可以清楚地看到文件被输出出来了,即便后者在CMD中显示是乱码,但仍旧成功地输出为文件,CMD其实具有兼容性,即便在GBK中没有这个字符(判断GBK中有没有该字符,只要将该字符转为GBK,看会不会变成问号?即可),也能正常地使用该字符(但也有些会变成乱码)
从而引出我的疑问:
疑问1 CMD中使用的是什么编码?文件名是什么编码?
CMD中如果直接用类似more、type命令输出一个UTF-8的文本文件的内容的话,不出意外就是乱码,和C/C++还有java输出UTF-8中文乱码是一个道理,因为在代码页936下,它会以为你输出的文件的编码是GBK,因为它就会以GBK编码去解释这些UTF-8的内容。所以这么直接来看的话,好像CMD在代码页936下使用的是GBK编码?
但又不是,因为在CMD使用dir命令输出路径下的文件时,如果存在文件名为韩文的话是能够正常输出韩文(GBK中没有韩文,但是有日文片假名和平假名),结果如下:
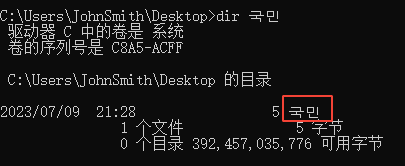
虽然很没有意义,但我还是安装了一台韩国WIN10虚拟机,结果也是显而易见,这台虚拟机的代码页不完全支持中文,也就是部分中文在其字符集中找不到,会变成?,而dir命令却能够显示完整的中文字符串。
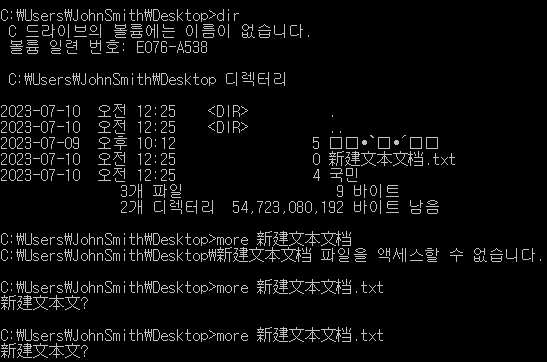
所以综上,我猜想代码页936的CMD,用于显示的编码不是GBK,而是Unicode编码,而之前给我造成CMD使用GBK编码用于显示的假象的原因是:CMD在输出的时候,会告诉系统它要使用GBK编码显示,所以才会把UTF-8编码的字符串以GBK编码进行解释,从而产生乱码。
于是带着这个疑问,我询问了GPT。

GPT提供的答案和我想的差不多,但是还不太对,因为GPT猜的和我之前想的一样,说CMD会把编码转为GBK显示出来,但是韩文文件名为何能够显示呢,我又进一步问它

这里也不是说完全信GPT,至少GPT说的这部分是对的,Windows的文件系统中存储文件名肯定是以一种通用的方式进行存储,然后再根据系统设置的语言进行编码转换显示,不然全球这么多字符集,每种语言下都用其对应的字符集去保存文件名的话,天知道多麻烦,万一一更换语言包,不就直接崩了嘛。
于是带着关键字Windows UTF-16进行搜索,找到一个网址https://www.codenong.com/10764920/,里面说CMD更换字体,于是我一拍脑袋,CMD中无法正常显示୧꒰•̀ᴗ•́꒱୨这个文件名,可能并不是不支持,而是CMD使用的字体中没有对应的字符。但无论如何这个疑问算是结束了,日后有机会再找找有什么字体能够正常显示一些特殊的字符串。
LUA与Windows
提到CMD下的乱码与文件,其实主要还是要从我遇到的问题说起,我在编写一个lua的脚本,它会调用ffmpeg命令行批量去合并哔哩哔哩下载的视频的视频流和音频流。由于lua太轻量级了,以至于没有操作文件系统的功能,比如说创建目录啊,打开目录啊,不过这并不重要,因为目录结构我是清楚的,只要遍历就可以了,最大的问题还是在于,哔哩哔哩下载视频会带一个json文件,json文件是UTF-8编码的,最初时我的做法是获取到视频标题后就用iconv转编码为GBK,但一些视频的标题会带上一些特殊的符号,通过查询可以知道emoji的范围嘛,于是就再进行过滤之后再转GBK,但是有一些符号它不是emoji,比较特殊的地方在于,这些字符和很多中文字符都是三字节的UTF-8编码字符,并且和很多中文字符的编码范围重合了,就没办法直接过滤,所以才会有这篇研究编码问题的文章。
lua在简中的Windows下的问题主要如下:
1.使用io.open打开一个文件时,若文件名出现中文,必须使用GBK编码,否则找不到文件,打开就是nil,当然可以用iconv将UTF-8字符串转为GBK,这可以解决绝大部分的问题,但是也如上所述,遇到emoji可以过滤但是遇到特殊字符就不行了;
2.使用os.execute(cmd)执行命令行,命令行字符串也和上述文件的问题一样。
其实我的脚本原先是有一个Python版本的,Python基本上把编码问题处理得天衣无缝,我不写Python的主要原因还是学的人太多了,培训机构都在鼓吹学Python怎么怎么好,挺反感的,毕竟卷不过别人。
C与LUA
而提到lua,就不得不提到C,在简体中文的Windows下使用C,用fopen打开一个文件,那么文件路径必须是GBK,否则必定找不到文件路径,如下代码:
#include <stdio.h>
int main(){
FILE* pF = fopen("哈喽","w");
if(pF == NULL){
printf("文件打开失败!");
}else{
fclose(pF);
}
}
当我加上fexec-charset=GBK参数进行编译时,得到的结果是成功输出一个名为哈喽的文件,但是如果不带参数,编译出一个UTF-8版本的exe并执行的话,得到的却是鍝堝柦这个文件,这是以写的方式打开文件,但是如果以读的方式打开文件的话,那势必会找不到文件,我之前就很大聪明,加上fexec-charset=GBK就行了,但是有了前面的铺垫我们可以知道,首先Windows支持显示一些特殊字符作为文件名,其次编码转换无法将那些特殊字符转为GBK,那么问题就出来了,比如说,以读的方式打开୧꒰•̀ᴗ•́꒱୨这个文件,那肯定是打开失败。
然而标准C库给Windows提供了一个函数_wfopen,并且使用L""来作为宽字符串,这个去年实习时在写项目的时候就经历过,因为是开发Windows应用嘛,所以为了避免发生找不到文件路径的错误,经常就和宽字符串打交道。
直接使用L""的话,源文件中就有大量的""和L""以及wchar_t和char,为了保持一致性,项目中经常是导入tchar.h头文件,给Windows提供一个_T("")的宏和TCHAR,当项目中定义了_UNICODE宏之后,_T("")就表示宽字符串,TCHAR表示wchar类型,否则_T("")表示窄字符串,TCHAR表示char类型。但是Linux中不需要解决类似Windows的问题,所以Linux中标准C库并没有提供该头文件,所以可以预见如果要写一个在Windows和Linux通用的文件处理函数,可能需要涉及多个#ifdef:
#ifdef _WIN32
#include <tchar.h>
#else
#define TCHAR char
#define __T(x) x
#define _T(x) __T(x)
#endif
跨平台的事情就先抛在一边吧,既然标准C库给Windows提供了宽字符串的相关函数,那与执行命令行相关的system函数会不会有一个对应的宽字符串的版本呢,查了一下还真的有,叫_wsystem。
那问题就很好办了,专门给lua写一个Windows下执行16进制字符串的命令行的子模块就可以了。但是在动手之前,还是得先看看lua的os.execute的实现。
用VS2019打开CMake项目还是挺方便的,于是搜索execute,找到loslib.c文件,找到了如下的函数注册说明:
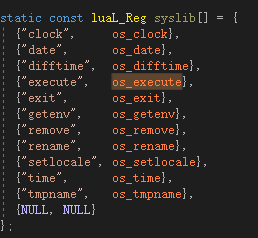
os_execute就是我们平时使用的os.execute,看函数定义:
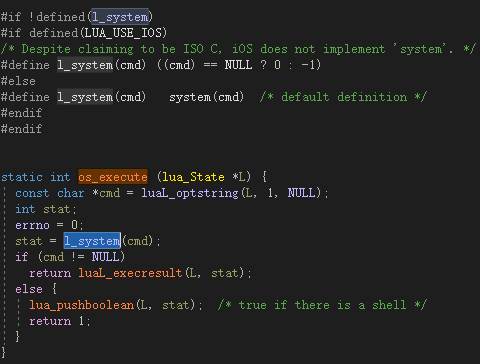
可以看到本质上,os_execute是调用l_system,而l_system实际上就是标准C库提供的system函数,那问题就好解决了,当然我并不倡议直接给os模块添加一个函数,首先是官方的源码可能会更新,所以一旦更新了源代码就得把我增加的功能迁移过去,其次是因为涉及到宽字符串,就需要进行编码转换,而且Linux中也没有宽字符串这玩意,并所以最好还是搞成一个第三方库或者在源代码中添加一个新的库,我不希望污染源代码,所以我决定写一个第三方库。
lua_exforwin库的实现
使用我自己的luaByCMake项目(链接:https://github.com/ThankVinci/luaByCMake),复制libdemo更名为lua-exforwin-module,CMakeLists.txt文件中的模块名修改为efw,然后从loslib.c文件中复制所需的头文件到include/lua_efw.h中:
#ifndef _LIBEX4WIN_H
#define _LIBEX4WIN_H
#include "lprefix.h"
#include <errno.h>
#include <locale.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
#include <stdio.h>
#include "lua.h"
#include "lualib.h"
#include "lauxlib.h"
#endif //_LIBEX4WIN_H
而lua_efw.c文件中则直接从loslib.c文件中复制相关的代码,并加以改动:
#include "lua_efw.h"
#define LIB_NAME "efw"
#define LIB_VERSION "1.0"
#if defined(LUA_BUILD_AS_DLL) /**LUA_BUILD_AS_DLL只有在Windows构建lua时才有这个宏,所以在这个ifdef下面include<wchar.h>
并且以下的模块API定义均在这个宏下面,那么其他平台编译这个模块也没有意义,根本没有符号
*/
#include <wchar.h>
#include <io.h>
#include <fcntl.h>
#include <windows.h>
#if !defined(l_wsystem) //模仿
#if defined(LUA_USE_IOS)
/* Despite claiming to be ISO C, iOS does not implement 'system'. */
#define l_wsystem(cmd) ((cmd) == NULL ? 0 : -1)
#else
#define l_wsystem(cmd) _wsystem(cmd) /* default definition */
#endif
#endif
static int os_execute(lua_State *L) {
//_setmode(_fileno(stdout), _O_U16TEXT);
const char *cmd = luaL_optstring(L, 1, NULL); //获取UTF-8字符串
size_t cmdLength = strlen(cmd)+1;
wchar_t _wcmd[cmdLength*sizeof(wchar_t)];
MultiByteToWideChar(CP_UTF8, 0, cmd, -1, _wcmd, sizeof(_wcmd) / sizeof(wchar_t)); //转为宽字符串即(UTF-16)
int stat;
errno = 0;
stat = l_wsystem(_wcmd);
if (cmd != NULL)
return luaL_execresult(L, stat);
else {
lua_pushboolean(L, stat); /* true if there is a shell */
return 1;
}
}
static const struct luaL_Reg efwlib[] = {
{"execute", os_execute},
{NULL,NULL}
};
LUALIB_API int luaopen_efw (lua_State *L) {
luaL_newlib(L, efwlib);
return 1;
}
#endif //LUA_BUILD_AS_DLL
可以这么说,实际改动的地方只有l_wsystem的那几处,但是就成功实现了我要的效果,所谓的核心功能就是函数接收了UTF-8字符串,然后转为宽字符串(即UTF-16编码),然后交给了_wsystem函数。
编译后放到模块目录中,在lua中的使用demo:
local efw = require "efw" --引入我的exforwin模块
local str = 'echo 哈哈' --当前demo的编码为UTF-8,所以这个字符串是utf-8
os.execute(str) --输出乱码
efw.execute(str) --成功输出'哈哈'
收尾
其实一开始我是很迷惑的,正如我上文所述,我一直以为CMD中使用的就是GBK编码。遇到lua执行命令行因为编码问题发生错误,我在想为什么会这样,在Python中,UTF-8字符串都可以直接跑了对吧。
发现这个编码问题到现在十多天了,不过也一直在摸鱼,思考了好几天,排除了一切不可能剩下的就是可能的,Python肯定是在交给命令行执行前做了什么,那我用lua也做什么就行了,我把一切都理清楚之后,准备动手大干一场,一看lua的源码,瞬间就惊了,是直接调用system函数,不过也确实,标准C库提供的system可以用为何不用,那就简单啦,直接复制一份小改一下就行了。