淘宝的反爬非常厉害,即使模拟了浏览器,仍然会有一大堆验证流程,首先声明这里只是实现了可用的代码,并不实用。
下面是一段示例代码,用于模拟爬取淘宝特定关键词下,按销量排序,商品的价格、店名等数据:
在开始之前,要下载谷歌浏览器和对应的webdriver,Python、以及Python安装selenium,这句话仅用于提示新手。
from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.chrome.options import Options from lxml import etree import time import random import os def get_all_name_prices_sells(html): # 一页50个 xpath_name = '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div[%d]/a/div/div[1]/div[2]/div/span//text()' xpath_prices_int = '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div[%d]/a/div/div[1]/div[3]/span[2]/text()' xpath_prices_float = '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div[%d]/a/div/div[1]/div[3]/span[3]/text()' xpath_sells = '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div[%d]/a/div/div[1]/div[3]/span[4]/text()' xpath_shop_name = '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[3]/div/div[%d]/a/div/div[3]/div[1]/a/text()' data = [] t = etree.HTML(html) for i in range(50): name = t.xpath(xpath_name % i) pi, pf = t.xpath(xpath_prices_int % i), t.xpath(xpath_prices_float % i) sell_num = t.xpath(xpath_sells % i) shop_name = t.xpath(xpath_shop_name % i) if all([name, pi, pf]): data.append([''.join(name), pi[0]+pf[0], sell_num[0][:-3] if sell_num else '', shop_name[0]]) return data def get_tb_by_word(d, name, pages=3, ): driver.get('https://s.taobao.com/search?q='+name) data = [] # d.find_element('xpath', '//*[@id="q"]').send_keys(name) # 搜索框 # d.find_element('xpath', '//*[@id="J_TSearchForm"]/div[1]/button').click() # 搜索按钮 time.sleep(0.3+0.3*random.random()) d.find_element('xpath', '//*[@id="sortBarWrap"]/div[1]/div[1]/div/div[1]/div/div/div/ul/li[2]/div').click() # 按销量排序 time.sleep(0.3+0.3*random.random()) for i in range(pages): d.find_element('xpath', '//body').send_keys(Keys.END) time.sleep(0.3+0.3*random.random()) data_in1 = get_all_name_prices_sells(d.page_source) data += data_in1 if i < pages - 1: # 下一页 try: next_page_bt = d.find_element('xpath', '//*[@id="root"]/div/div[3]/div[1]/div[1]/div[2]/div[4]/div/div/button[2]') d.execute_script('window.scrollBy(0, -500)') next_page_bt.click() time.sleep(0.7+0.5*random.random()) except: # 没有下一页 break return data names = ["笔记本", "风油精"] # 要搜索的关键词if __name__ == '__main__': fn = 'tb_prices.tsv'driver = webdriver.Chrome() idx = 0 _continue = False if os.path.exists(fn): ls = open(fn, encoding='utf-8').read().split('\n')[:-1] if len(ls) > 1: last = ls[-1].split('\t')[0] idx = names.index(last) print('last:', last, 'idx:', idx) _continue = True names = names[idx:] print('前三个:', names[:3]) if _continue: fw = open(fn, 'a', encoding='utf-8') print('继续:', last) else: fw = open(fn, 'w', encoding='utf-8') fw.write('\t'.join(['品类', '商品名', '价格', '销量', '店名']) + '\n') print('全新开始') while True: try: for word in names: print(word) da = get_tb_by_word(driver, word) for items in da: fw.write('\t'.join([word]+items)+'\n') if names: names = names[1:] except Exception as e: print(str(e)) if input('是否完成?\n') == '1': print('break') break else: print('continue') # driver.close() # print('等待3分钟重试') # time.sleep(60*3) # driver = webdriver.Edge()
多次(十几次)使用后,触发淘宝验证机制,每次验证结束后,就在cmd窗口输入换行,继续爬取,如果要结束就输入1加换行。
第一个会遇到的验证窗口是这样的:
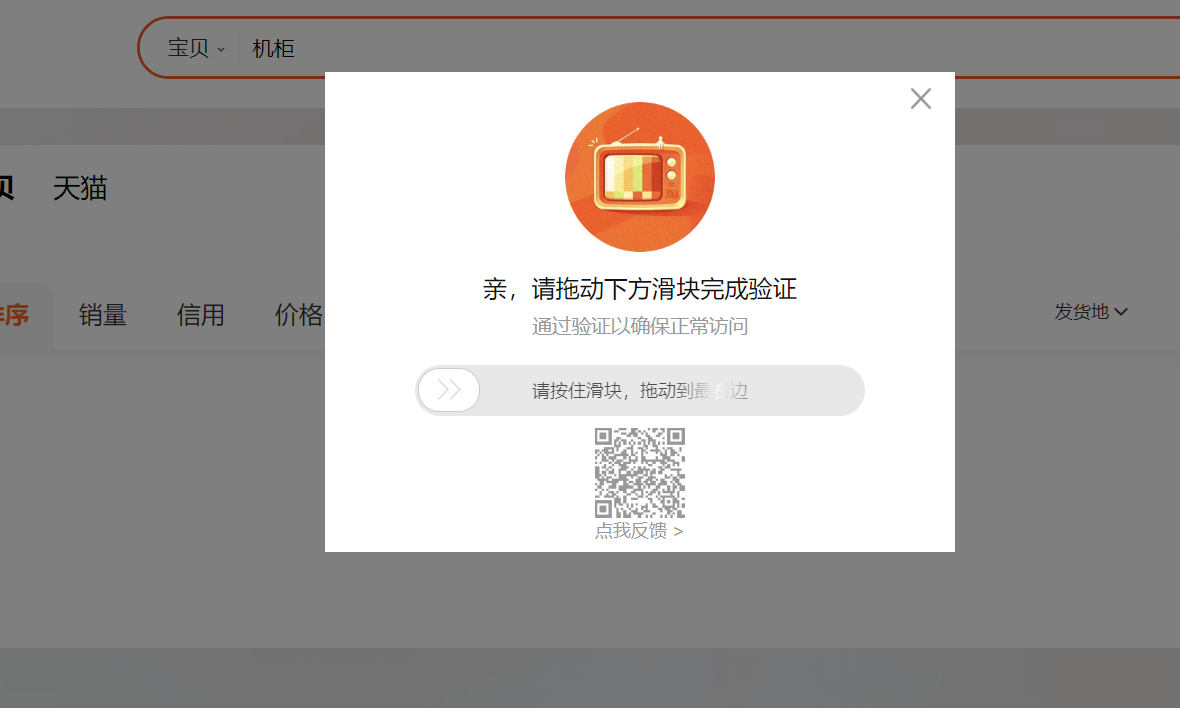
如果是上面的代码,淘宝能识别selenium打开的浏览器,这里就会一直报错:点击框体重试
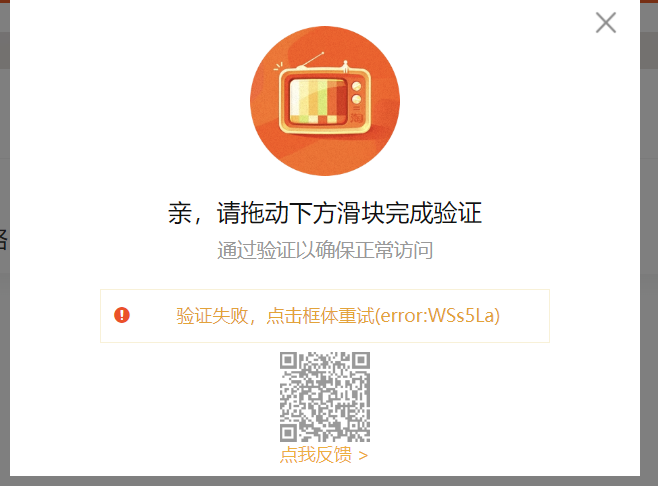
这时候就要用命令行手动打开浏览器,再用selenium的debug模式控制浏览器
命令行(先转到浏览器文件所在目录):
start chrome.exe --remote-debugging-port=9222
此时打开了一个浏览器窗口
再将上面代码中的
driver = webdriver.Chrome()
替换为以下几行:
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=chrome_options)
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
driver = webdriver.Chrome(options=chrome_options)
这样,虽然淘宝还是偶尔报错,但至少能通过。
这里有个小诀窍,就是滑块要慢慢滑到右边试探,但不要到底,这样更容易通过。
这种验证多了以后,会出现另一种识别图像的验证,让你拉一条线,直到识别到它要求的物体为止。
这种验证对于真人来说是没有难度的。
后面主要的问题是,每搜索3个,甚至1个关键词,它就要跳出第一种验证窗口,而且通过的概率大大降低,非常折磨人,建议等待几分钟后再爬。