paper:https://arxiv.org/pdf/1611.07004.pdf [CVPR 2017]
code:
- https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
- https://phillipi.github.io/pix2pix/ [official]
数据组织:需要成对图像
这是加利福利亚大学在 CVPR 2017 上发表的一篇论文,讲的是如何用条件生成对抗网络实现图像到图像的转换任务。文章目的主要是试图提供一种通用的图像转换问题解决方案,该网络不仅可以学习输入图像到输出图像的映射关系,还能够学习用于训练映射关系的 loss 函数。这使得我们可以使用同一种方法来解决那些传统上需要各种形式 loss 函数的问题。
1 整体架构
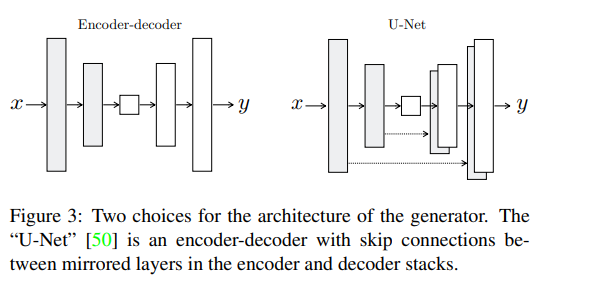
使用 DCGAN 中的生成器和鉴别器结构,其中 Generator 优化了下采用 U-Net 结构的 encoder-decoder。
DCGAN 可参考:https://zhuanlan.zhihu.com/p/434296842
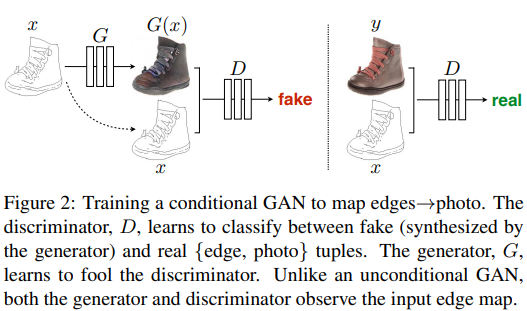
条件 GAN(condition GAN,cGAN)不同于传统 GAN,其将原始样本 x 也作为输入的一部分,训练 G 时将其和随机高斯分布噪声 z 一起输入网络,训练 D 时将其与待判别图片 y 一起输入网络。个人理解这样做是希望通过 x 能一定程度上控制生成的内容,使得 GAN 更加稳定:
2 损失函数
cGAN 的优化目标为:
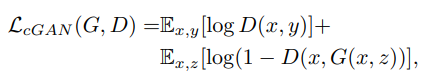
在论文中,作者为了验证对于 D 来说,原始图片 x 作为输入也是有必要的,还做了对比实验,将 x 不作为 D 的输入,此时优化目标公式如下:
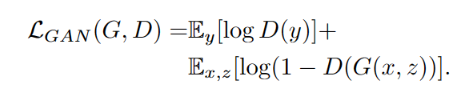
以前的方法发现在 GAN 的训练目标中加上传统的真实图像与生成图像之间的 L2 损失是好的,可以让生成的图像更接近真实图像,所以论文也采用了这个策略,不过是使用 L1 损失,这样能减少模糊:
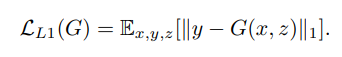
最终的目标函数如下:
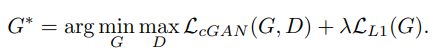
作者发现,不使用 z 时,网络虽然依旧能够学会从 x 到 y 的映射,但是会产生固定的输出,即导致无法拟合除 delta function 以外的概率分布。传统的做法是将高斯噪声 z 和 x 一起作为输入,但是作者发现这样没啥效果,G 轻松的就学会了如何忽略噪声。所以作者的做法是使用 dropout 来引入噪声,在训练和测试时均在网络某些 layers 上应用 dropout。但是结果上来看,网络的输出也仅表现出微小的随机性,故作者认为设计有高度随机输出的 cGANs 也是当前工作的一个重要方向。
3 网络结构
G 和 D 在整体结构中已经说明过了,主要的改进主要有两点。
-
在 U-Net 形式的 Generator 中,使用了 skip-connection,主要是为了将低频信息(例如 edge 等)保留下来,避免其在下采样的过程中丢失
-
使用马尔可夫判别器(PatchGAN),通过图像可以看出,L1、L2 损失虽然会导致模糊的结果,但有足够的能力保留低频信息(整体的结构信息),因此 cGANs 的判别器可以用一个 L1 损失来确保低频信息的正确性,重点在于验证高频信息(边缘、纹理等细节结构信息)。

而为了对高频进行建模,只需要将我们的注意力限制在局部图像块的结构上就足够了,因此作者设计了一种新的 Discriminator 架构,称为 patch-GAN,只在 patch 级别上计算损失。
这个判别器试图对每个 NxN 大小的 patch 进行判断真假,在整张图像上应用判别器卷积,然后用平均结果作为最终输出。(代码中来看,就是 D 不再输出简单的标量,而是输出一组 bs x C x N x N 的向量,论文中 N 取 70)。
关于 patchGAN,详细可参考:https://zhuanlan.zhihu.com/p/359287990
这种鉴别器有效地将图像建模为马尔可夫随机场,假设像素之间的独立性大于一个 patch 直径。 这一联系在[38]( C. Li and M. Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. ECCV, 2016. 2, 4) 中已有探讨,也是纹理模型和风格模型中常见的假设。 因此,PatchGAN 可以被理解为一种纹理/风格 loss。
4 训练
优化过程中几点要说的:
- 先训练 D,再训练 G,并且在反向传播优化 D 的时候,将其优化目标(loss)除以2,降低 D 相对于 G 的学习速度;
- 和传统 GAN 建议的那样,训练最大化\(log D(x,G(x,z))\),而不是训练 \(G\) 来最小化\(log(1-D(x,G(x,z))\);
- 梯度计算时采用 minibatch SGD + Adam 优化网络,学习率设为 1e-4;
5 效果
在多种视觉任务上验证了模型(重建、分割、上色、风格迁移等),详见原论文。
参考:
- Image Image-to-Image Conditional Adversarial Translationimage image-to-image conditional adversarial image image-to-image translation zero-shot image-to-image cycle image cycle-consistent image-to-image text-to-image conditional diffusion control translation back-translation translation augmentation robustness improving conditional translation professor computer assembly