1. 逻辑回归
下面是这位大佬的Click.逻辑回归是用于分类的算法,它是在线性回归的基础上添加了一层映射.

这里的\(w\)和\(x\)都是\(vector\),两者的乘积是inner product,从上式中我们可以看出,现在这个\(model\)(\(function\) \(set\))是受\(w\)和\(b\)控制的,因此我们不必要再去像前面一样计算一大堆东西,而是用这个全新的由\(w\)和\(b\)决定的\(model\)——\(Logistic\) \(Regression\)(逻辑回归).也就是之前将几个式子的乘积视为\(w\),而现在逻辑回归我们直接求\(w\).
2. Three Steps of machine learning
介绍一个新的算法,从三步开始.
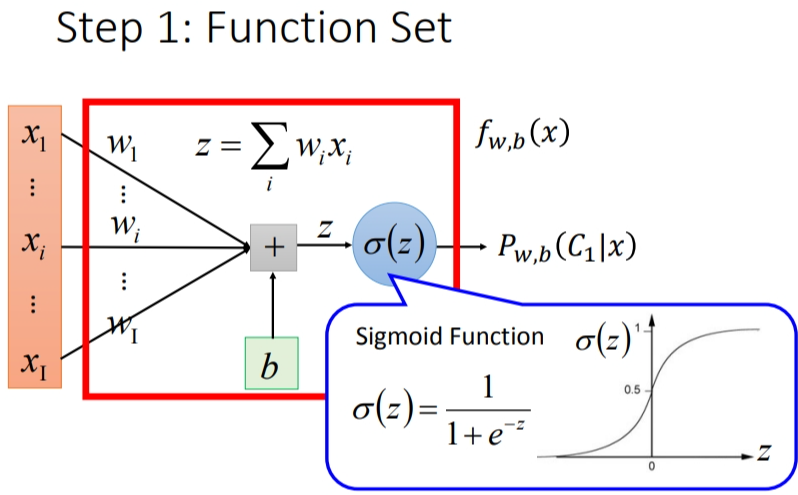
2.1 Step 1: function set
这里的function set就是Logistic Regression——逻辑回归
2.2 Step 2:Goodness of a function
衡量好坏的函数.假设现在我们有N笔Training data,每一笔data都要标注它是属于哪一个class.
假设这些Training data是从我们定义的posterior Probability中产生的(后置概率,某种意义上就是概率密度函数),而w和b就决定了这个posterior Probability,那我们就可以去计算某一组w和b去产生这N笔Training data的概率,利用极大似然估计的思想,最好的那组参数就是有最大可能性产生当前N笔Training data分布的\(w\)和\(b\)
似然函数只需要将每一个点产生的概率相乘即可.注意,这里假定是二元分类,class 2的概率为1减去class 1的概率.

因为我们平时最小化处理比较多,因此将\(L\)取负再取\(Log\)也能达到同样的效果.但是我们可以发现\(ln(1-f_{w,b}(x^3))\)和之前的很难统一.因此Logistic Regression里的所有Training data都打上\(0\)和\(1\)的标签,即\(\hat y = 1\)表示第\(1\)类,\(\hat y = 0\)表示第\(2\)类.于是式子可以改为:
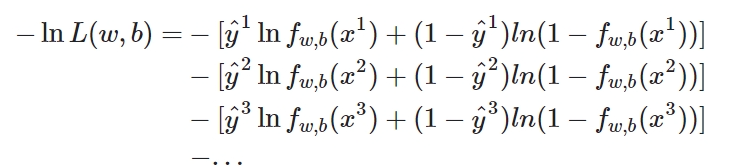
这里有兴趣可以了解一下损失函数的来源,介绍了这个形式的\(loss\) \(function\)是怎么来的,和伯努利分布有关.

现在已经有了统一的格式,我们就可以把要minimize的对象写成一个summation的形式:
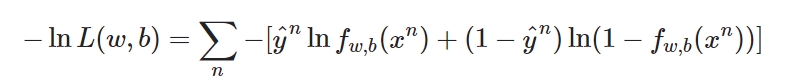
下图中蓝色下划线实际上代表的是两个伯努利分布(0-1分布,两点分布)的 cross entropy(交叉熵).
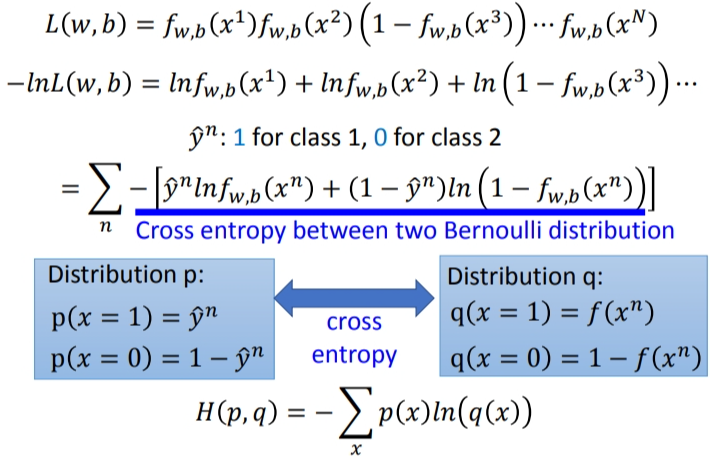
cross entropy什么意思呢?假设有两个分布\(p\)、\(q\),都服从两点分布.它们的交叉熵就是上图\(H(p,q)\).交叉熵代表的含义是这两个分布有多接近,如果两个分布是一模一样的,那计算出的交叉熵就是0.这也就是之前的推导中在\(−lnL(w,b)\)前加一个负号的原因.而这里\(f(x^n)\)表示\(function\)的output,\(y^n\)表示预期的\(target\),因此交叉熵实际上表达的是希望这个\(function\)的\(output\)和它的\(target\)越接近越好.
这实际上也是我们的损失函数.

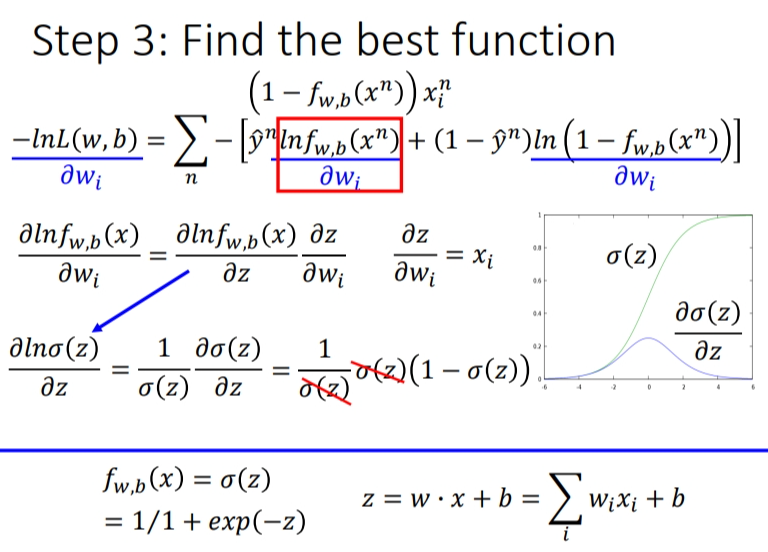
2.3 step 3:Find the best function
实际上就是去找到使loss function即交叉熵之和最小的那组参数\(w\)和\(b\).这里用gradient descent的方法进行运算就ok.假设求\(w_i\)的偏微分,步骤如下: