go的协程和线程都绕不过GMP,关于GMP基本的工作流程,有go开发经验的大致都懂,这边更多关注GMP如何解决一些类似 协程饥渴的问题,以及底层的大致实现原理。
多线程循环
上篇讲了单线程是如何循环的,这里还是为 GMP的出场 大致介绍下。
工作模型
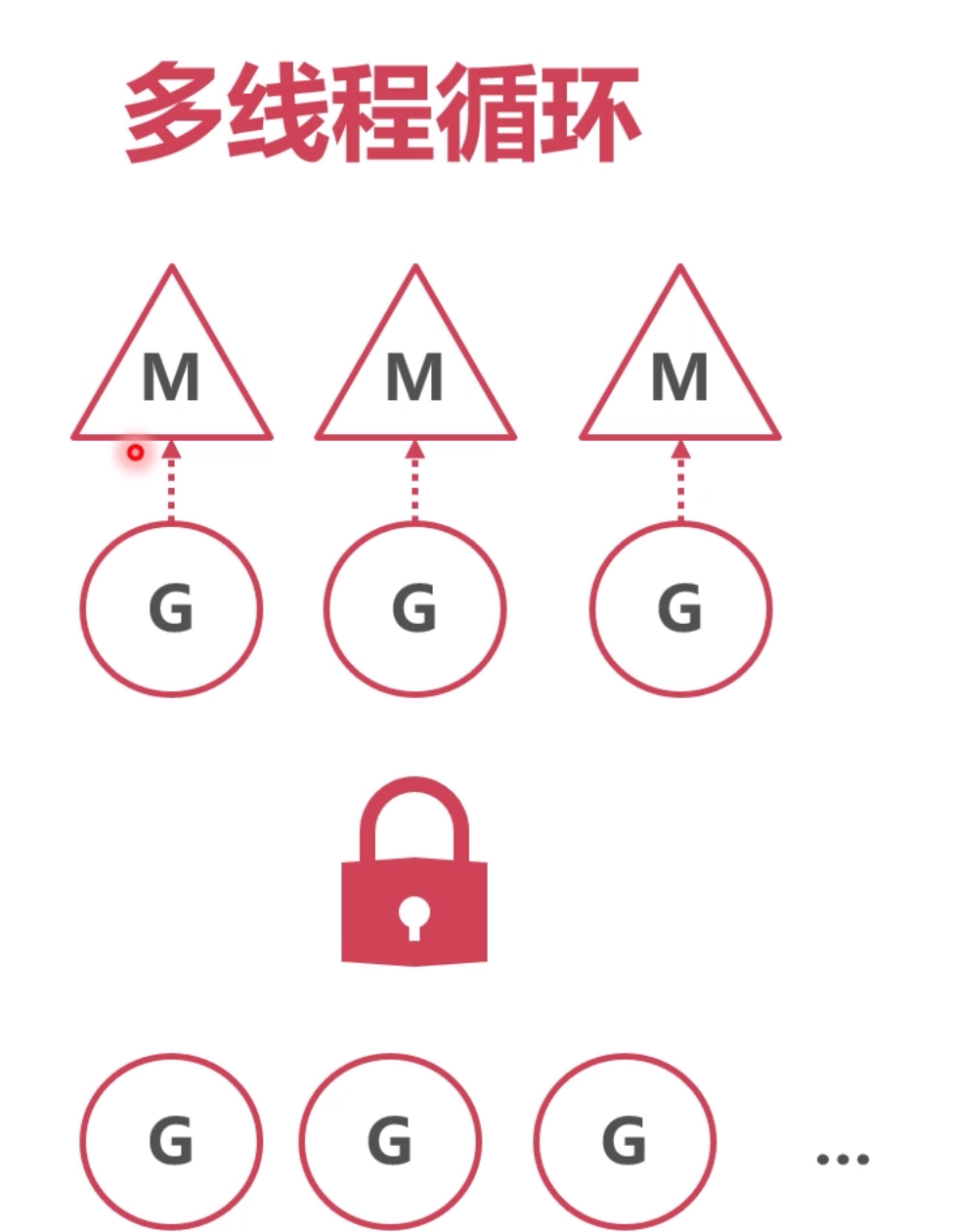
多个M都去全局G的队列中获取 g,所以,全局g的队列需要上锁。
改进版,增加本地队列
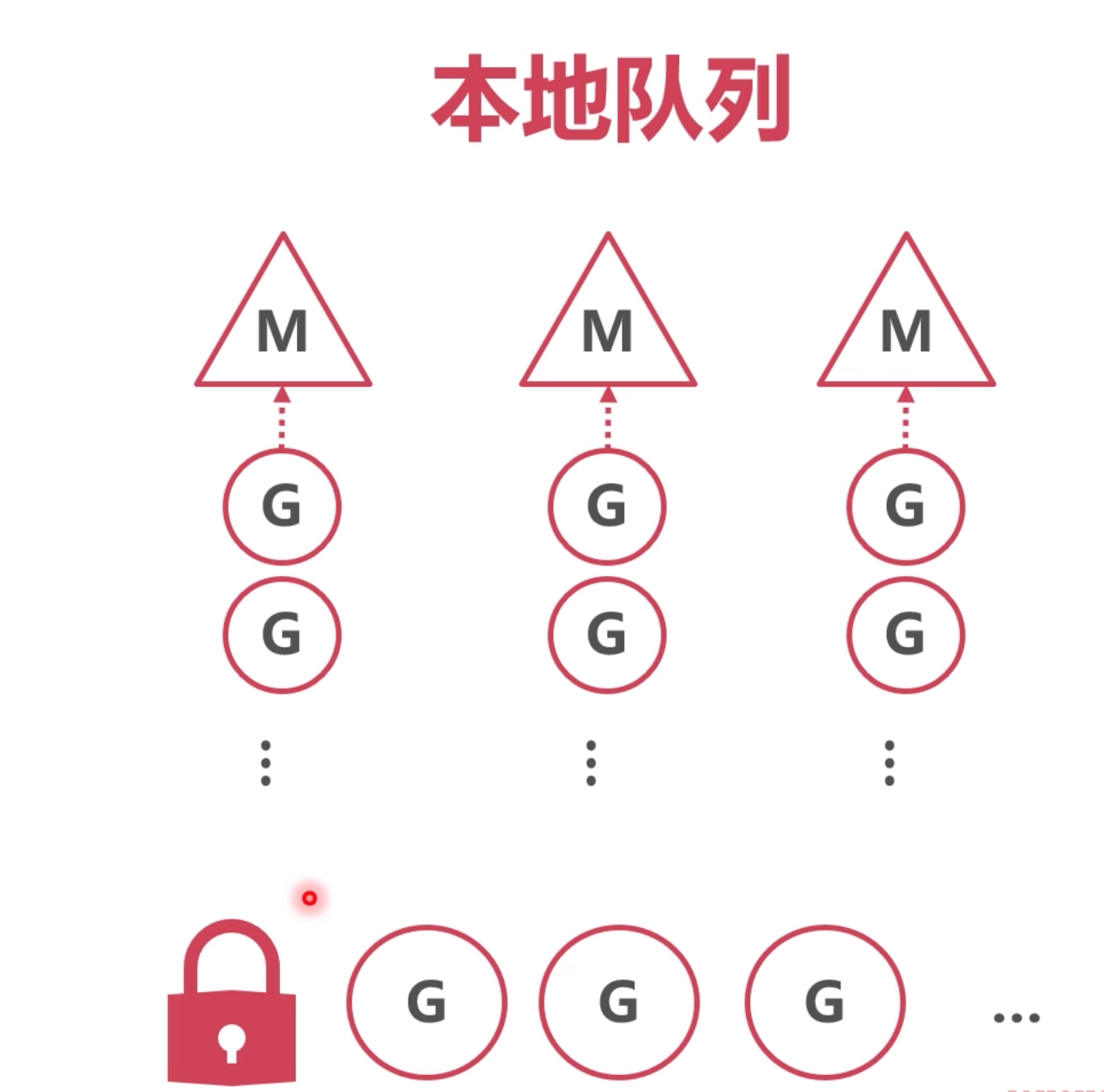
这样每个m都缓存了一个本地队列,避免每次都去全局队列里面拿,而且一次也能拿多个,降低了全局队列锁获取的开销。
这个其实就是 GMP了。P指的就是为M管理要执行的g
P 的定义
在runtime2.go中有定义:
删除了很多源码,只留下和这里讲的相关的代码:
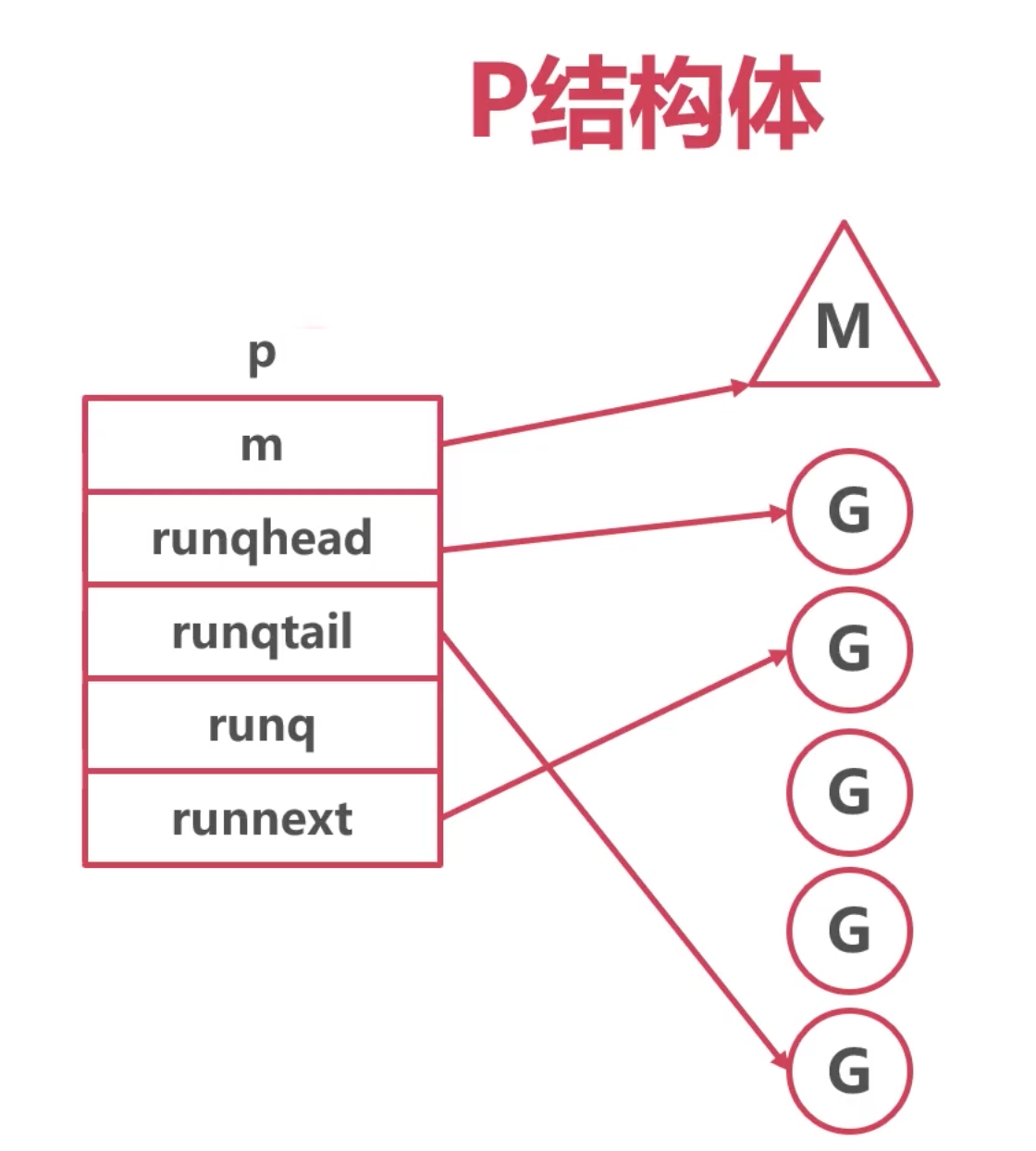
type p struct {
id int32
// M 线程
m muintptr // back-link to associated m (nil if idle)
// 可用的g的队列,进入不用加锁 嘚瑟
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32 // 头尾
runqtail uint32
runq [256]guintptr // 256 的容量
runnext guintptr // 下一个可执行的g
}
整体结构如下:
完整的GMP模型就如下:
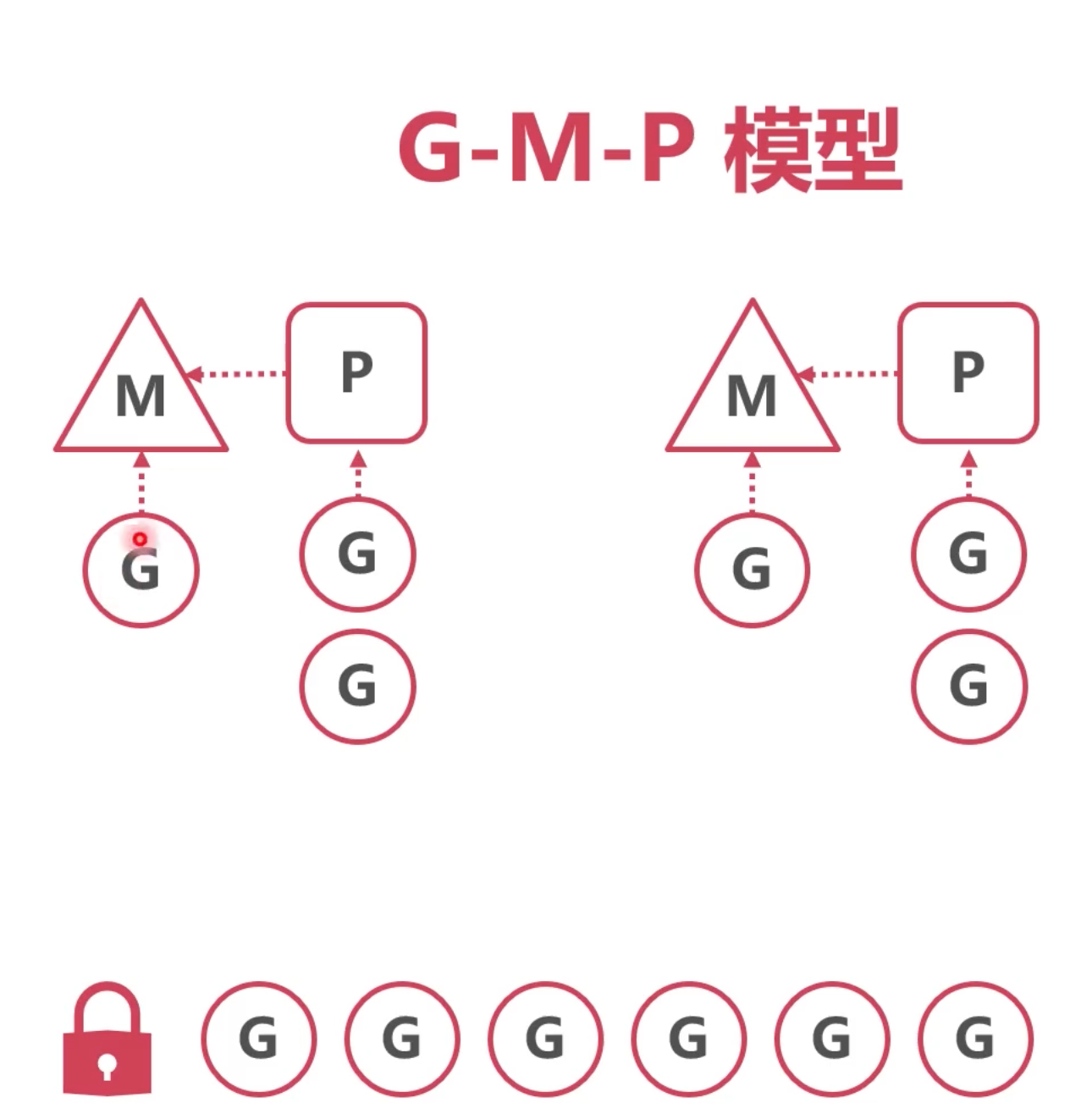
和上面的改进版很像,只是抽象出来一个P,专门来管理
p的作用
1. M与G之间的中介
2. P持有一些G,使得每次获取G的时候不用从全局找
3. 大大减少了并发冲突的情况
代码的逻辑
要回到 schedule(),上篇中有提到:
schedule()中有为 M查找,要运行的g,通过这个方法:
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from local or global queue, poll network.
// 查询一个 能运行的g去执行,尝试去别的p里面偷,或者从 本地、全局队列了获取。
// poll network 涉及到了 epoll 和 poll 和这里没关系
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {
// local runq 本地拿
if gp, inheritTime := runqget(pp); gp != nil {
return gp, inheritTime, false
}
// global runq 全局拿
if sched.runqsize != 0 {
lock(&sched.lock) // 全局队列拿 需要上锁
gp := globrunqget(pp, 0)
unlock(&sched.lock)
}
// 如果还拿不到 就去偷 去别的p里面偷
gp, inheritTime, tnow, w, newWork := stealWork(now)
}
func runqget(pp *p) (gp *g, inheritTime bool) {
// If there's a runnext, it's the next G to run.
next := pp.runnext //从p的next获取的下一个
if next != 0 && pp.runnext.cas(next, 0) {
return next.ptr(), true
}
}
源码都是未截取完整的。
看下全局怎么拿的:
//Try get a batch of G's from the global runnable queue.
// sched.lock must be held.
func globrunqget(pp *p, max int32) *g {
assertLockHeld(&sched.lock)
n := sched.runqsize/gomaxprocs + 1
if n > sched.runqsize {
n = sched.runqsize
}
if max > 0 && n > max {
n = max
}
if n > int32(len(pp.runq))/2 {
n = int32(len(pp.runq)) / 2
}
sched.runqsize -= n
gp := sched.runq.pop()
n--
for ; n > 0; n-- {
gp1 := sched.runq.pop()
runqput(pp, gp1, false)
}
return gp
}
经过了一系列的计算,最终确定拿 n个g放回本地。 因为传过来的 max=0
所以 n 为 len(pp.runq)/ 2 和 sched.runqsize/gomaxprocs + 1 中的数量大的那个。
runq [256]guintptr 声明为256
本地队列容量的一半 128,或者 全局队列的个数除以 gomaxprocs(p的个数) + 1,最多拿128个。
steal
上面逻辑讲了,如果全局也拿不到,就调用 stealWork 去别的p里面拿, 看下代码:
// stealWork attempts to steal a runnable goroutine or timer from any P.
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {
// 具体的逻辑,就不看了。就是遍历里面的p 从符合条件的p的本地队列,拿一半过去。
}
小结:
如果在本地或者全局队列中都找不到G, 去别的P中“偷〞,增强了线程的利用率
协程新建
代码在 proc.go中
func newproc(fn *funcval) {
gp := getg()
pc := getcallerpc()
systemstack(func() {
// 新创建一个 g
newg := newproc1(fn, gp, pc)
pp := getg().m.p.ptr() // 获取当前g 的 p
runqput(pp, newg, true) // 通过这函数,将g放置
})
}
// getg returns the pointer to the current g.
func getg() *g
小结:
1. 优先获取当前的P
(这点上有看到说是随机获取一个p,但是从 getg() 官方描述来看,是获取的当前p,如果这里我未理清楚,可以评论下)
2. 将新协程放入P的runnext(插队)
3. 若P本地队列满,放入全局队列
问题:
目前为止,已经解决了第一个问题
多线程并发时,会抢夺协程队列的全局锁
但是 协程顺序执行,无法并发 ,如一个协程执行时间非常长,一直占着m,就会导致其他g无法及时响应。