常见的碎片类型
·Segment Fragmentation:段产生了碎片;没有按照数据的顺序存储,或者在数据页之间有空的页
·Tablespace Fragmentation:表空间中存储的是非连续的文件系统块
·Table Fragmentation:表中数据不是按照主键的顺序存储的。或者表的页有大量空闲空间。比如,表定义成了堆表。 data is stored not following the primary key order (heap tables), or table pages have a significant amount of free space (heap tables or index tables).
·Index Fragmentation: 索引通常是按照索引的顺序(b-tree)或无序的(hash索引)。碎片表示索引中有空闲的索引页
·Row Fragmentation: 单个行跨越了多个页
局部性原则
虽然局部性原则通常与处理器和高速缓存访问模式有关,但它也适用于一般的数据访问。这一原则描述了两种数据访问模式:空间局部性和时间局部性。
时间局部性意味着最近被检索的数据更容易在短时间内被再次需要。空间局部性告诉我们,某种程度上相关的数据(接近)往往会被一起访问。如果你的数据是按照局部性原则组织的,那么数据访问将更有效率。
碎片是如何影响数据的局部性的?
表和索引的碎片化常常导致数据库页包含大量的空闲空间。这降低了将经常访问的数据存储在一起的概率,违背了时间局部性原则。
表碎片化也会影响到空间局部性,因为它将相关数据存储在不同的数据库页上。关于表空间和段碎片,现代存储系统倾向于减少这些类型的碎片的影响。
行碎片的情况则有些不同。通常有三种可能:不支持行碎片,通过行链支持(部分行有一个指向另一个页面的指针,该行在那里继续),或者只支持大数据类型。在最后一种情况下,Blobs通常被存储在一个单独的区域中。这种类型的分片可以提高性能和效率。
InnoDB的碎片
在InnoDB中,所有东西都是一个索引。主键很重要,因为它们定义了数据在表中的排序方式。这种设计的效果之一是没有因无序的数据而产生的碎片。但是我们仍然可以有由表页的空闲空间引起的碎片。
分裂或不分裂,是个问题
InnoDB将行存储在页中。一条新的记录会根据主键放在一个特定的页。但是,当一个页满了,会发生什么?InnoDB必须分配一个新的页来存储新的行。在这里,InnoDB是相当聪明的。大多数RDBMS执行页分割:创建一个新的页,并且将完整页的一半内容移到最近分配的页上,留下两个半满的页。InnoDB所做的是分析和插入模式,如果它是连续的,则创建一个页并将新行放在那里。这对于连续的主键插入是非常有效的。
插入不需要是纯粹连续,它们需要遵循一个方向:递增或递减。我们将不介绍内部原理;只是告诉你,每个索引离开页都有元数据来表明最近插入的方向,以及在它之后插入了多少行。
随机与顺序插入对碎片的影响
正如上面所解释的,InnoDB有一个聪明的方法来识别新行是否必须插入到一个空页中,或者是否有必要进行分页。这种方法对于顺序插入来说是非常有效的,因为它产生的额外页数量最少,而在传统上,这种方法对于非顺序插入(当主键是随机的或者未知的时候)被认为是有害的。
我们将回顾一下顺序和随机插入的过程,以了解行是如何被插入的。但首先,让我们看看一个空页的内容。最初,我们有一些元数据和用于新数据的空闲空间。

一旦我们开始向这个页插入数据,数据是否连续并不重要;页面将开始填充。

但是一旦低于1/16的空闲空间,就必须分配新的页面。如何分配和填充新的页面,取决于插入是顺序的还是随机的。对于顺序插入,我们有这样的模式:

新的数据被插入到新的叶子页中。但是对于随机插入,我们有一个不同的行为:

我们必须在这两个页面上保留空闲空间,因为我们不能假设新行将被插入的位置。
随着新行的插入,顺序插入将以低碎片化的方式继续:
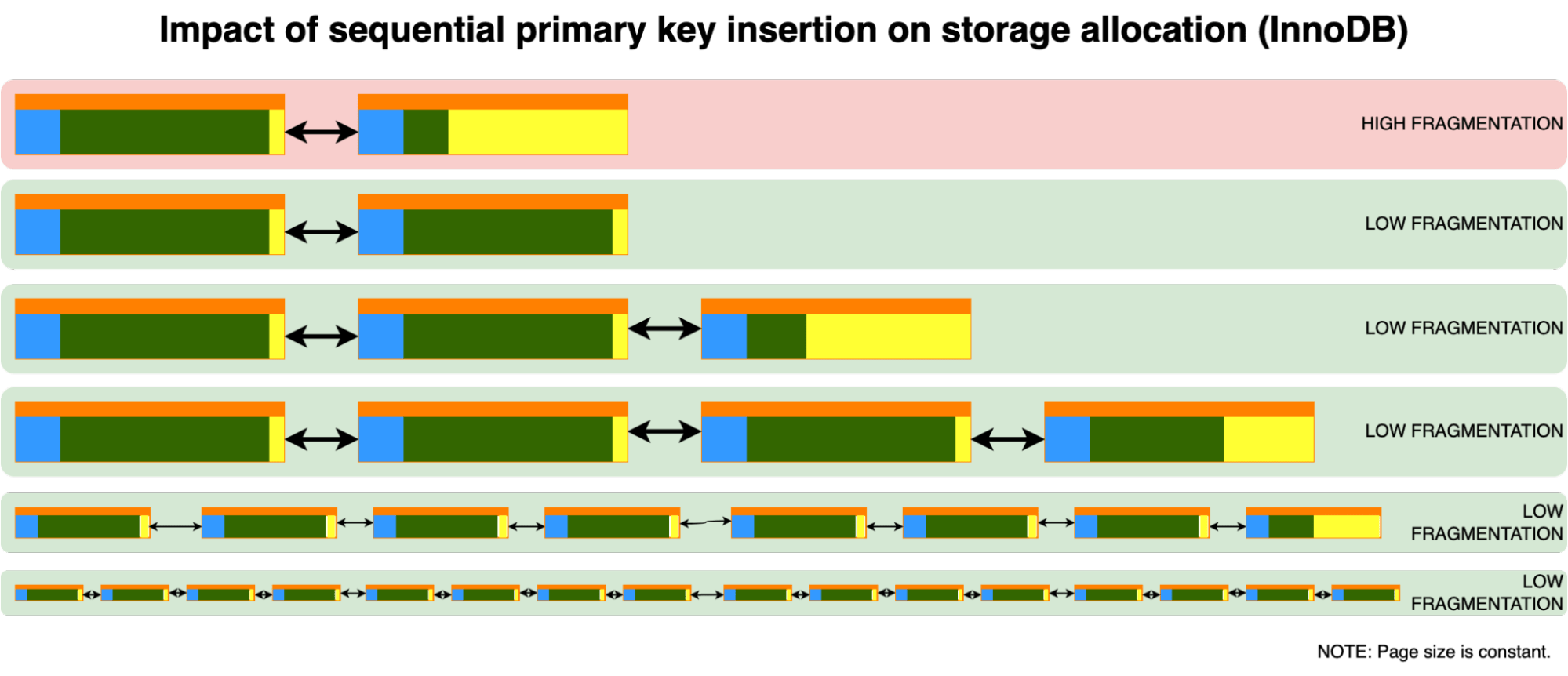
但是,随机插入会发生什么?为了简单起见,我们假设主键是均匀分布的。
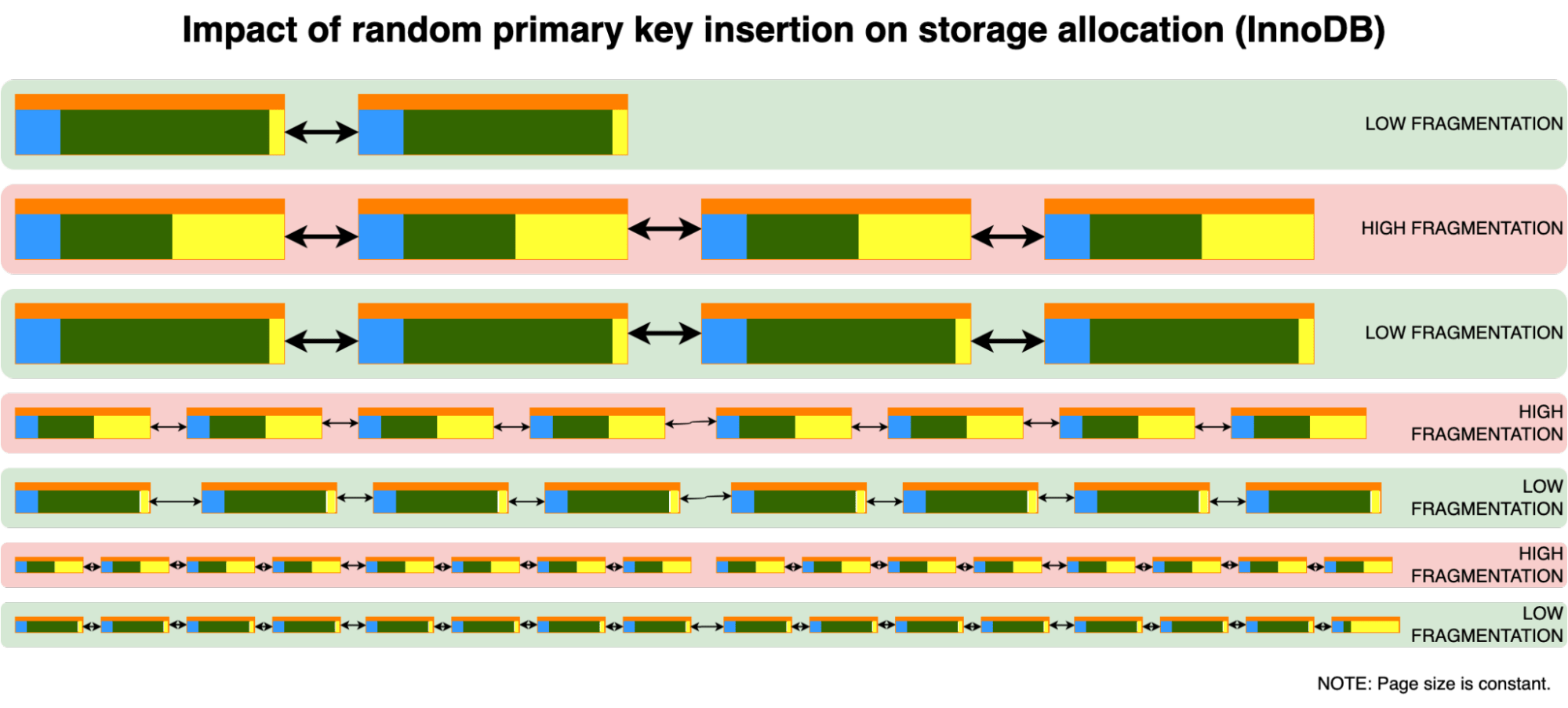
在这里我们看到一个有趣的现象,当碎片化程度较低时,新的插入可能会触发页分割,从而增加碎片化程度。但是一旦达到一定的碎片化水平,几乎所有的页面都会有足够的空闲空间来接受新的行而不进行拆分。直到达到阈值,新的拆分将再次发生。
这意味着,随机插入会导致暂时性的碎片化。
随机插入和删除
前面的案例涵盖了只插入数据的情况,但当删除数据时,会发生什么?通常情况下,我们有一些定期清除旧行的表。如果它们是按主键排序的,就不会有任何问题:空页将从索引表的开头被完全删除。
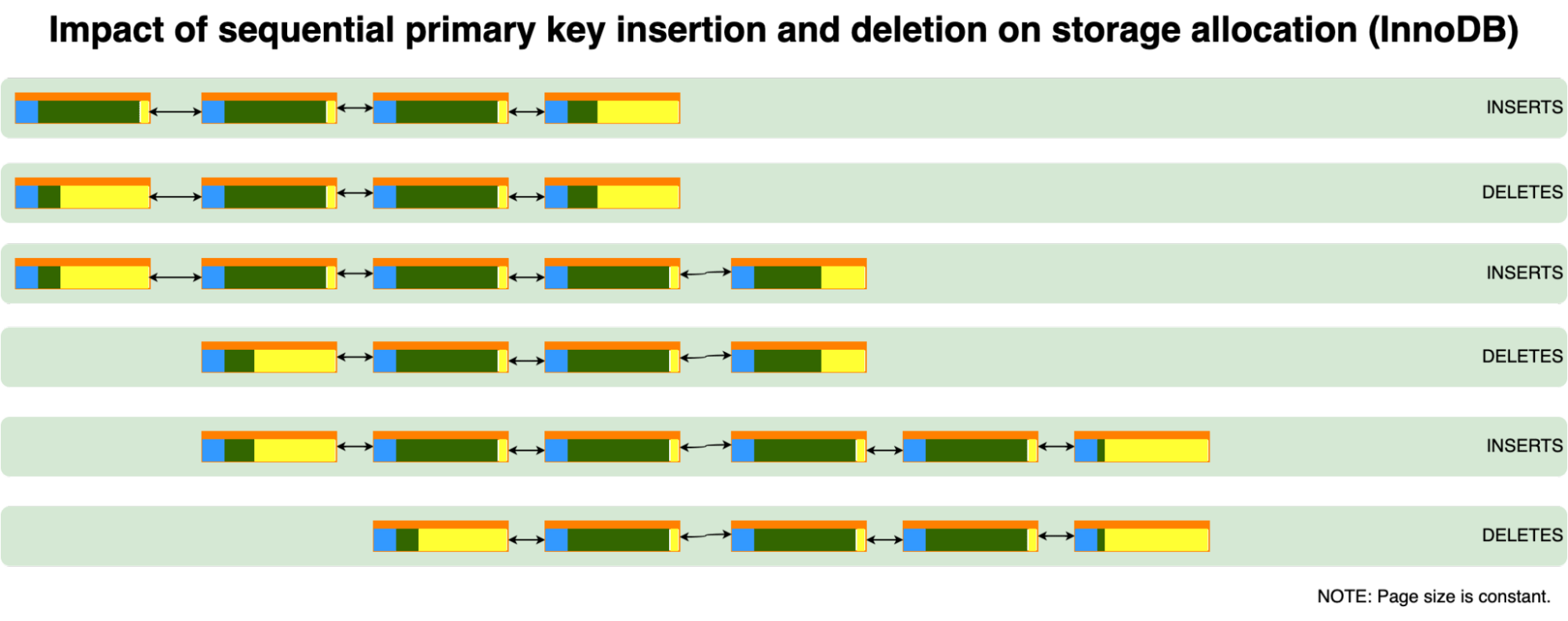
我们在这里看到的是,旧的行属于相同的页,一旦它们被移除,就有可能将该页返回到表空间。稍后,这个页面将被再次分配给新的行使用。
但是当插入和删除是随机的时候,会发生什么呢?删除也是随机的,这个假设是正确的,因为数据是随机分布的。
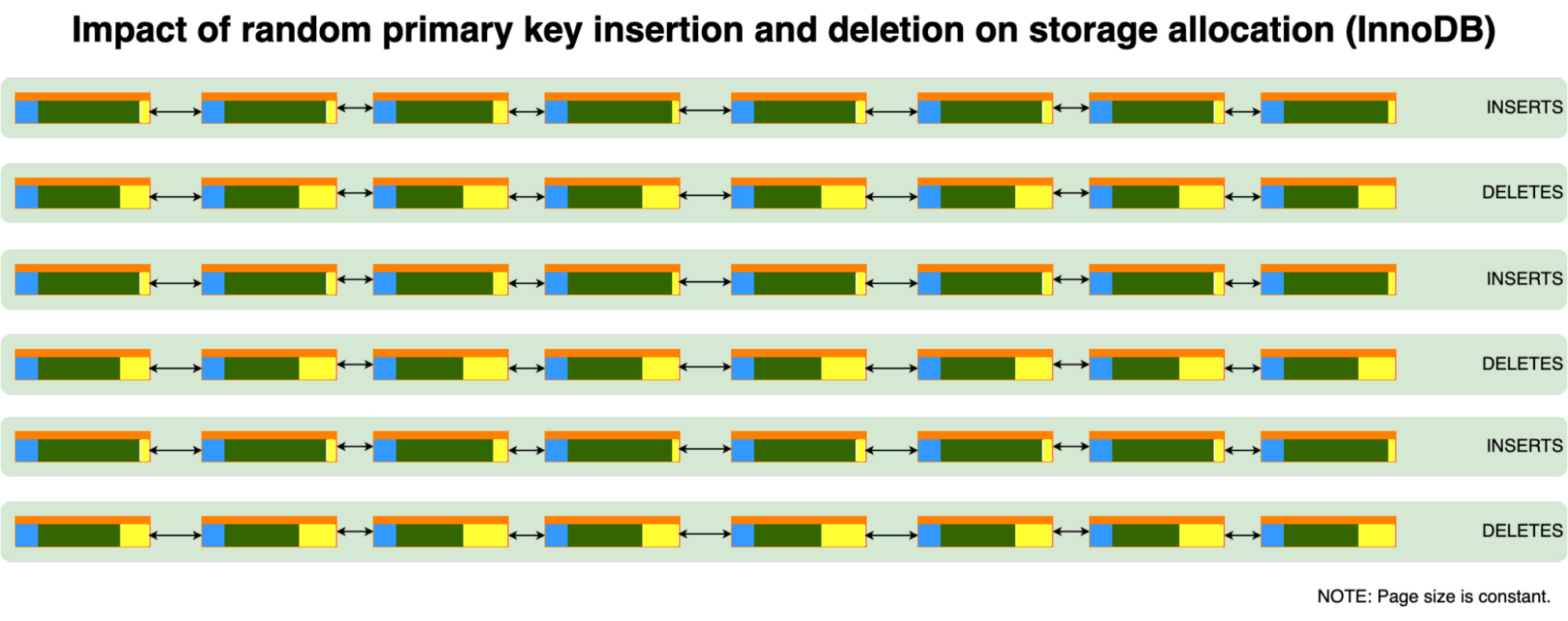
我们可以看到,只要删除和插入的行数大致相等,这种模式就不会明显增加(或减少)碎片。
随机插入和删除的理想情况是有足够的空间来插入新的行而不达到分裂点。
分裂的其他原因
有三个因素定义了碎片化的额外原因。上面一直在分析第一个:数据是如何插入的。另外两个是数据修改(更新)和数据删除(删除)。
当一个空字段被填入数据或一个varchar字段内容被一个较长的文本取代时,页面必须为这个额外的数据腾出空间。如果没有足够的空闲空间会怎样?InnoDB将把页面分成两个半满的页面。这就增加了碎片化的程度。为了避免这种情况,InnoDB为每个页面保留1/16的数据修改空间。这种保留是不考虑插入模式的。
如果你增加了许多行的大小,也就会产生碎片化。
碎片检测
目前,还没有简单的方法来测量页碎片。
测量页分裂
识别碎片化正在发生的一个间接方法是测量页分裂的数量。不幸的是,我们不可能测量在插入或更新一个特定的表时产生的分裂的数量。
关于InnoDB页分裂的全局统计数据被存储在information_schema.innodb_metrics中。
这些统计数据必须通过使用innodb_monitor_enable全局变量来启用。
InnoDB Ruby
使用一个名为InnoDB Ruby的外部开源工具可以分析InnoDB的结构。Jeremy Cole已经开发了这个工具,可以在这里访问:https://github.com/jeremycole/innodb_ruby
还有一个wiki页面,记录了程序的使用:https://github.com/jeremycole/innodb_ruby/wiki
为了获得一个特定表的碎片的概况,你可以使用以下命令:
innodb_space -f space-extents-illustrate
这条命令返回一个表空间的图形,使用不同的格式在每一页上显示空间分配。

减少碎片
一旦表出现碎片,减少碎片的唯一方法就是重建表。通过重建表来减少碎片的问题在于,随机插入会很快使表碎片化。由于新行是随机插入的,而碎片的减少会导致没有空闲空间来存放新行,因此碎片会很快出现。
重建表可能会在重建后不久导致碎片的大量增加,因为页面分裂会使我们几乎所有的页面都是半满的。
Innodb填充因子(Innodb_fill_factor)
理想情况下,如果我们执行随机插入,我们必须在全表重建后为新的插入分配足够的空间。有一个全局变量可以实现这个功能:innodb_fill_factor。
"innodb_fill_factor定义了在建立排序索引过程中,每个B树页面被填充的空间百分比,剩余的空间保留给未来的索引增长。例如,将innodb_fill_factor设置为80,则为每个B树页面保留20%的空间用于将来的索引增长。实际的百分比可能会有所不同。innodb_fill_factor设置被解释为一个提示,而不是硬性限制"。
这意味着,如果我们执行随机插入和删除,并且使用足够大的填充因子来重建表,以容纳清除前的所有插入,表将保持较低的碎片水平。
随机插入和删除测试和填充因子的推荐
我们用不同的填充因子进行了多次测试。所进行的测试包括以下内容:
1.创建一个表。
2.插入2,000,000条记录,使用md5作为生成哈希值的函数。
3.将填充因子设置为测试值。
4.优化该表。
5.重复400次
·在表中插入10,000行。
·从表中删除10,000行。
·测量分片情况。
我们用这些填充因子进行测试: 75, 80, 82, 83, 85, and 100.
文件总的大小
这个图表显示了初始和最终的空间分配。
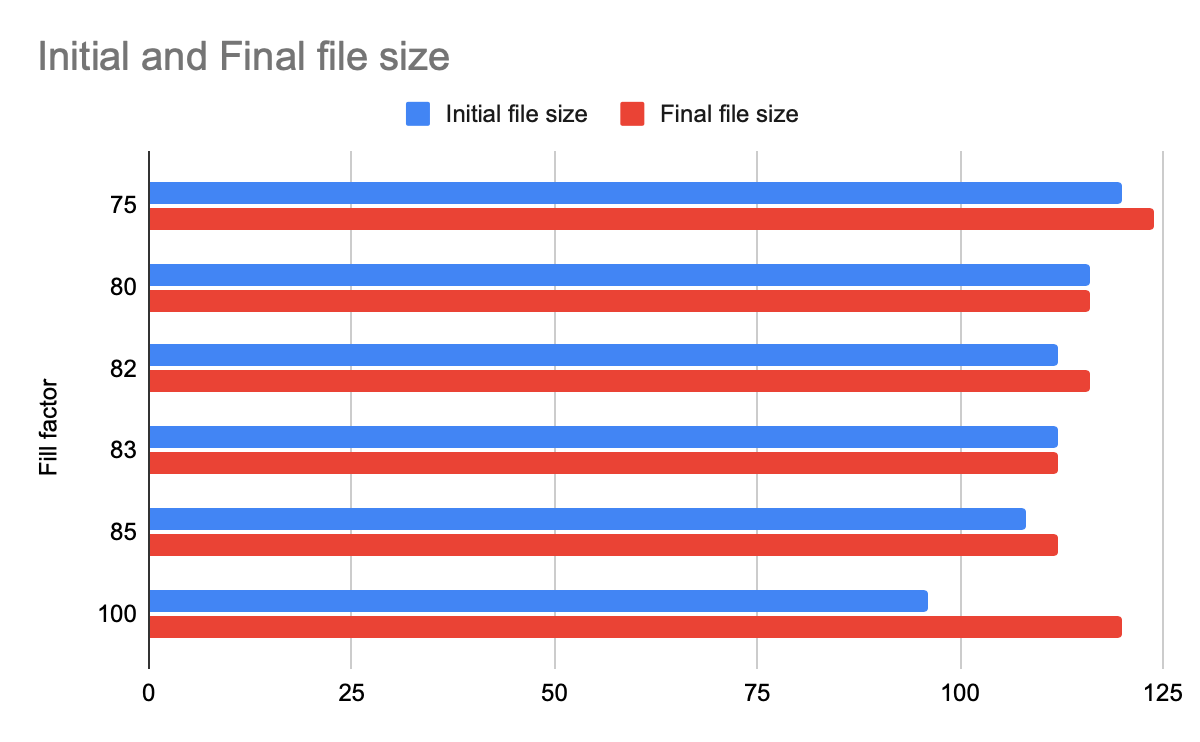
正如我们所看到的,使用83的填充因子为该测试提供了最佳结果。
页分裂与合并
我们还分析了页拆分的次数(一行不适合相应页面,页面需要拆分成两页的次数)和页面合并的次数(删除操作后,页面低于50%,InnoDB尝试将其与相邻页面合并的次数)。
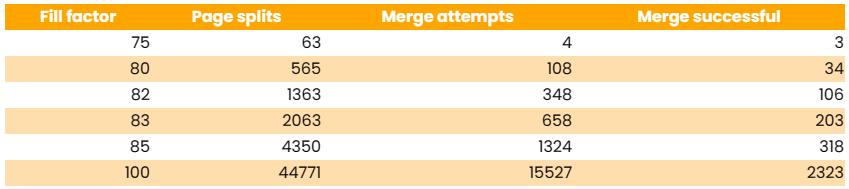
对应每个填充因子都有若干页分裂。当填充因子为100时,每处理89行就有一次页分裂,而当填充因子为83时,每处理1930行就有一次页分裂。
碎片映射
我们提供了填充因子分别为75、83和100,迭代400次后的碎片图。

结论
对于InnoDB表来说,碎片通常不是个问题。InnoDB处理碎片的效率很高,很少需要重建表。
只有一种边缘情况,即数据是按照随机主键插入的。在这种情况下,结果将取决于表的结构、键的分布以及数据插入或删除的频率。
在我们的测试中,innodb_fill_factor的值在83%左右是最佳的。它使碎片得到了控制。更小的填充因子没有提供额外的好处。具体情况可能会有所不同。
如果你有一个随机插入的大表,我们建议使用innodb_ruby这样的工具来监控碎片,并分析表是否需要使用不同的填充因子重建。