在谈BGP联盟和BGP反射器这两个技术前,我们先来了解一下BGP中存在的路由黑洞问题。
什么是路由黑洞呢?我们以下面这个拓扑来详细的介绍一下:

这是一个典型的BGP应用组网。图中,有3个AS,AS之间运行BGP协议。AS65008域内运行OSPF协议。R1和R5上只运行BGP协议,R2和R4上运行OSPF和BGP协议,R3上只运行OSPF协议。这里先解释下EBGP和IBGP。
EBGP:运行于AS之间两台设备的BGP关系。如图中R1和R2、R4和R5
IBGP:运行于AS内部两台设备的BGP关系。如图中R2和R4
这里读者可能会问:AS内部不是有IGP么,为什么还要建立IBGP关系?
这是因为如果R2和R4之间不建立BGP关系,那么如果R1要把路由传递给R5,经过AS65008时,就只能把BGP路由引入到IGP中,通过IGP进行传递。而把数以10万计的BGP路由引入到IGP中的后果是灾难性的。所以上图中,R2和R4之间建立了IBGP的关系。值得一提的是,如上文所提及,由于BGP是通过静态配置的方式建立TCP连接,所以并非只能在两台直连的设备上建立BGP关系,如上图,R2和R4间通过OSPF路由可达,可以建立IBGP关系。
假设R1上的loopback 1 口ip地址为10.1.1.1/32的主机路由宣告在BGP65007中,那么如下图所示,我们来看该路由是怎么传递到R5上的:
路由传递的过程:
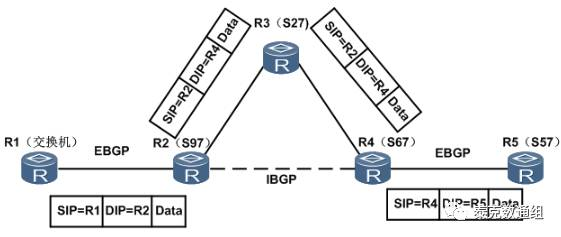
R1—R2:由于两台设备直连,并且建立EBGP关系,R1可以直接发送update报文至R2。
R2—R4:两台路由非直连,但是两台路由建立了IBGP关系,R2将update报文发送给R4。即该update报文的目的IP是R4,于是R2查询自己的路由表,由于域内运行了OSPF协议,通过OSPF,R2查询到去R4的下一跳是R3,于是将该update报文发给R3,R3收到该报文后,虽然没有运行BGP协议,但是根据报文的目的IP,将该update报文发送给R4。
R4—R5:同样,两台设备直连,并且建立EBGP关系,R4可以直接发送update报文至R5。
R5访问R1loopback口时,数据包的传递过程:
R5—R4:R5发送的数据包,源IP是R5,目的IP是R1,于是R5查询路由表,因为从R4收到一条R1的路由,该路由的下一跳标识为R4。于是将数据包发送给R4。
R4—R2:当R4收到从R5发过来的数据包时,该数据包的源IP是R5,目的IP是R1。于是,R4查询路由表,发现去往R1的路由下一跳是R2(我们假定R2上配置了peer next-hop-local命令),由于下一跳非直连,于是R4查询去R2的下一跳。由于域内运行了OSPF,R4发现,去R2的下一跳是R3,于是将数据包发给了R3。当R3收到该数据包时,由于数据包的目的IP是R1的IP,但是R3并没有运行BGP,所以R3上没有R1的路由。于是R3将该数据包丢弃。
这就是经常说到的数据层面的“路由黑洞”。
BGP是一个基于TCP协议的路由协议,源端口号为179。TCP在传递数据前需要建立面向连接的,所以就导致了前面所说的数据层面的路由黑洞问题。解决路由黑洞问题的办法有以下四种,它们分别是:
(1):逻辑全连接方案
(2):BGP联盟
(3):BGP反射器
(4):MPLS
其中逻辑全连接的方案弊端在于数量众多的IBGP连接难于管理,而BGP联盟和BGP反射器这两个技术的出现解决了该问题。
BGP联盟
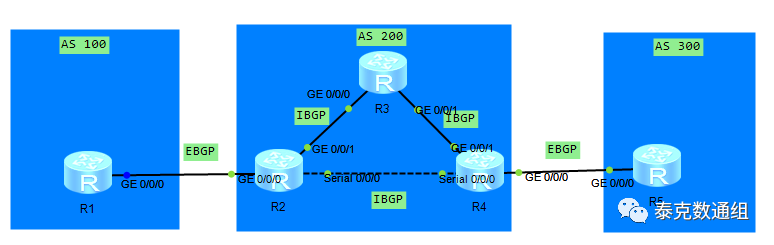
如果采用逻辑全连接的方式,需要建立3个IBGP连接。这只是AS200内只有3台设备的情况,事实上,AS200内如果每增加一台设备,需要建立的IBGP连接数量将呈几何级数上升。
BGP联盟可以将AS分割为多个子自治系统,从而让大型转接AS变得更具管理性。被分割的AS本身将成为联盟,而分割后的子自治系统则成为成员自治系统。联盟之外的AS将整个联盟视为一个AS,看不见成员自治系统。由于成员自治系统对外界来说是隐而不见的,因而成员自治系统可以使用公有或私有AS号(建议采用私有AS号)。
联盟可以极大的降低IBGP连接的数量。在联盟中,只需要在成员自治系统内进行IBGP的全连接,而成员自治系统间使用一种特殊的EBGP连接,我们称之为联盟EBGP。下面看下具体配置。
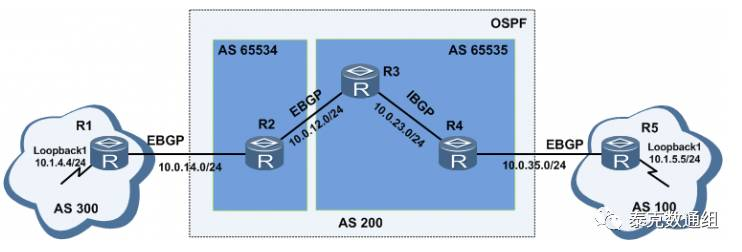
如上图,我们将AS200分成2个成员AS:AS65535和AS65534。而对于R1和R5来说,他们看到的中间的转接AS仍然是AS200。下面截取了R3的一些关键配置:
R3:
#
bgp 65535 //本机AS为成员AS号
confederationid 200 //联盟ID,外部路由器看来,连接AS仍然为200
confederationpeer-as 65534 //说明本机连接了其他哪些成员AS
peer10.0.12.1 as-number 65534 //和成员AS65534建立联盟EBGP连接
peer10.0.23.1 as-number 65535 //和本成员AS内部设备建立IBGP连接
#
ipv4-familyunicast
undosynchronization
peer10.0.12.1 enable
peer10.0.23.1 enable
peer10.0.23.1 next-hop-local //这个配置并不生效,详细会在下文提及。
#
这样,整个AS200内,只需要建立一个IBGP连接和一个EBGP连接,就可以实现路由的传递和数据包的转发。
需要注意的是:联盟AS内仍然需要保证IGP的连通性,才能保证数据包的正确转发。
在联盟内部应遵守以下规则:
1) 联盟外部路由的NEXT-HOP在整个联盟中都是被保留的。
2) 被宣告到联盟之内的路由的MED属性在整个联盟中都被保留。
3) 路由的LOCAL_PREF属性在整个联盟中都被保留,而不仅仅是在为它们赋值的成员AS之内。
4) 在联盟内部需要将成员AS的AS号加入到AS_PATH列表中,但这些AS号不能被宣告到联盟之外。在默认情况下,成员AS号被列在AS_PATH中作为AS_PATH属性类型4,即AS_CONFED_SEQUENCE。如果在联盟中使用了手动聚合命令(aggregate)并配置了关键字as_set,那么位于聚合点之后的成员AS号将被列在AS_PATH中作为AS_PATH属性类型3,即AS_CONFED_SET.
5) AS_PATH中的联盟AS号用于实现环路避免功能,但是在联盟内部进行BGP路由选路过程中,选择最短AS_PATH时,不考虑这些联盟AS号。
上述规则的本质原因是整个联盟都被外界视为一个自治系统。我们通过一个具体例子说明规则1。仍旧以上面交换机的难题为例:
首先,我们在R1上通过Loopback1口发布一条路由:10.1.4.0/24,这条路由通过EBGP连接发送给R2时,NEXT-HOP为R1建立连接的接口地址10.0.14.4/24。正常来说,R2和R3建立的是EBGP连接,R2在将这条路由发送给R3时,会将这条路由的NEXT-HOP修改为自己和R3建立EBGP连接的接口地址10.0.12.1/24,但是我们发现并不是这样:
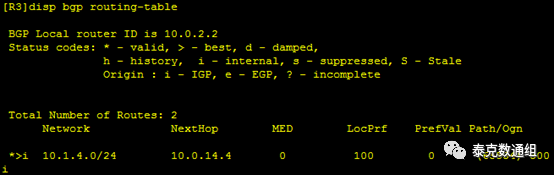
可以看到,R3上10.1.4.0/24路由的NEXT-HOP依然是10.0.14.4。这时,我们在R3上配置命令peer 10.0.23.1 next-hop-local。由于R3和R4之间是IBGP关系,正常来说配置了这条命令之后,R3在把该路由发送给R4时,会将NEXT-HOP设置为本设备接口地址。在R4上查看BGP路由发现,NEXT-HOP依然为10.0.14.4。

这就是由于外部路由的NEXT-HOP在联盟内部都是被保留的。联盟内部必须要保证IGP的连通性,如果联盟内部没有运行IGP,那么R4和R3上将没有到达10.0.14.0/24网段的路由,导致该BGP路由不生效。
接着我们在R5上也通过Loopback1接口引入一条路由10.1.5.0/24,并且在R4上配置命令peer10.0.23.1 next-hop-local。查看R3上的BGP路由表:

可以看到,10.1.5.0/24这条路由的NEXT-HOP被修改为R4建立IBGP的接口地址10.0.23.1。这是因为,peernext-hop-local在仅仅在外部路由在联盟内部传递的情况下是不生效的。
路由反射器
下面是一个路由反射器的示例:

如图,左边组网内有5台设备,如果采用IBGP全连接方式,将会有众多连接需要管理,非常麻烦。我们知道,IBGP有一个防环机制,任何从IBGP收到的路由,都不会发给其IBGP对等体,这是为何我们要建立逻辑全连接的原因。聪明的人们想到,能不能有条件的打破这个规则呢?我们发现,对于左图,如果我们只允许任何一台设备转发从IBGP对等体收到的路由,都是不会产生路由环路的。于是,我们指定其中一台设备可以转发从IBGP对等体收到的路由,则其他设备只需要和该设备建立IBGP连接,就可以保证路由能够传递到所有的设备上。这就是路由反射器的思想。
根据右图,我们先介绍下路由反射器中的一些概念:
l 路由反射器RR(Route Reflector):允许把从IBGP对等体学到的路由反射到其他IBGP对等体的BGP设备,类似OSPF网络中的DR。
l 客户机(Client):与RR形成反射邻居关系的IBGP设备。在AS内部客户机只需要与RR直连。
l 非客户机(Non-Client):既不是RR也不是客户机的IBGP设备。在AS内部所有非客户机与所有RR之间仍然必须建立全连接关系。
l 始发者(Originator):在AS内部始发路由的设备。Originator_ID属性用于防止集群内产生路由环路。这点会在后面详细介绍。
l 集群(Cluster):路由反射器及其客户机的集合。Cluster_List属性用于防止集群间产生路由环路。这点会在后面详细介绍。
RR向IBGP邻居发布路由规则如下:
l 从非客户机学到的路由,发布给所有客户机。
l 从客户机学到的路由,发布给所有非客户机和客户机(发起此路由的客户机除外)。
l 从EBGP对等体学到的路由,发布给所有的非客户机和客户机。
我们看下路由反射器的配置:
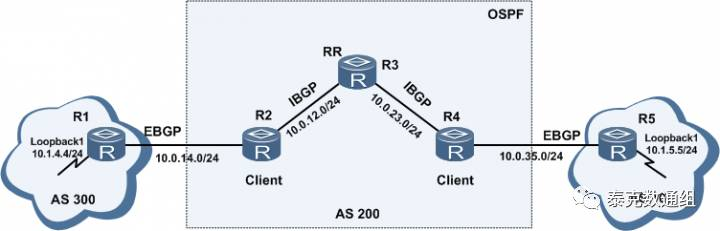
如上图,R2、R3、R4任何一台作为RR都可以,本例我们用R3作为RR。R3的关键配置如下:
#
bgp 200
peer 10.0.12.1 as-number 200
peer 10.0.23.1 as-number 200
#
ipv4-family unicast
undo synchronization
reflector cluster-id 1 //配置cluster-id,缺省为设备router id,可选配置
peer 10.0.12.1 enable
peer 10.0.12.1reflect-client //配置10.0.12.1为客户机
peer 10.0.23.1 enable
peer 10.0.23.1 reflect-client
#
我们在R1上发布10.1.4.0/24这条路由,查看R4的路由表,发现R4已经收到这条路由,在R4上查看这条路由的详细信息:
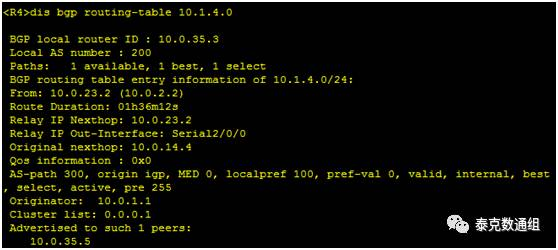
这条路由的NEXT-HOP为10.0.23.2
这条路由的Cluster_list属性中,已经记录了0.0.0.1。集群使用AS内唯一的Cluster ID作为标识。为了防止集群间产生路由环路,路由反射器使用Cluster_List属性,记录路由经过的所有集群的Cluster ID。
l 一条路由第一次被RR反射的时候,RR会把本地Cluster ID添加到Cluster List的前面。如果没有Cluster_List属性,RR就创建一个。
l 当RR接收到一条更新路由时,RR会检查Cluster List。如果Cluster List中已经有本地Cluster ID,丢弃该路由;如果没有本地Cluster ID,将其加入Cluster List,然后反射该更新路由。
当AS内部存在多个集群时,可能会产生集群环路,当RR从其他集群收到Cluster_list中含有1的路由时,将其丢弃,从而防止了集群间的路由环路。
同样我们看到,这条路由的Originator已经被记录为10.0.1.1。这个ID是R2的Router ID。Originator_ID由RR产生,使用的Router ID的值标识AS内这条路由的始发者,这里,10.1.4.0/24这条路由在AS200内的始发者是R2。当RR收到这条路由时,会将R2的Router ID加在这条路由中作为Originator_ID属性。当设备接收到这条路由时,会比较Oringinator_ID和设备本身的Router ID,如果相同,则丢弃该路由。这样就防止了在集群内部的路由环路。
联盟和路由反射器比较
联盟和路由反射器都是在大规模自治系统中减少IBGP对等体数量的有效方法,和联盟相比,路由发射器有以下两个好处:
1)联盟中的所有路由器都必须理解和支持联盟机制,而路由反射方案只需要路由反射器了解路由反射机制即可,客户路由器和RR之间只建立不同的IBGP连接。
2)无论从所需的配置命令还是从拓扑结构的设计上说,路由反射器的实现都更加的简单。
如上面所述就是一个典型的例子,通过路由反射器,只需要在R3上增加一条配置命令,即可解决问题。但是如果希望用各种EBGP机制来管理大规模AS,那么联邦将是一个更优的解决方案。
当然,在某些场景下,联盟和路由反射器同时使用将更加事半功倍。一个简单的例子:
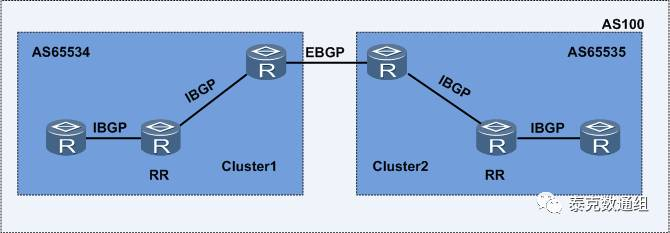
如上图所示,RR与联盟是完全可以配置使用的。