0.背景
本文中的MQ基于阿里sofa技术栈的DMS组件,类似于rocketmq。
近段时间存在消息积压情况,经排查是性能问题。
普通消息的接收与投递流程如下图所示:
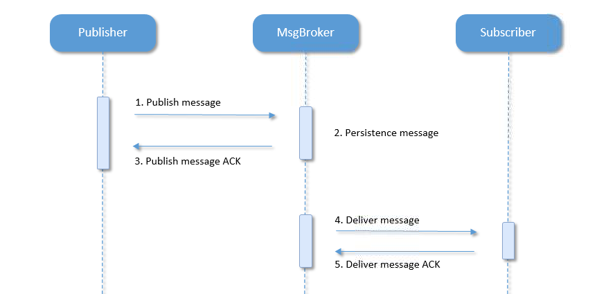
当消息服务器接收到发布方的消息,并在对消费方投递时候出现异常,则是消息积压。
消息投递异常的常见原因如下:
-
订阅端系统未连接到消息代理组件(Message Broker)。
-
订阅端系统收到消息后处理超时,默认消息投递超时时间是10秒。
-
订阅端系统收到消息后处理异常。
-
订阅端系统收到消息后主动回滚。
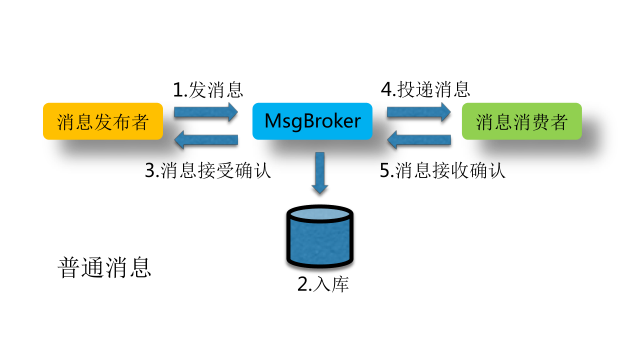
现象:
投递方消息积压,但是应用层面无日志可查。
-
查看msgbroker日志,投递失败记录中,投递失败原因为TIMEOUT。
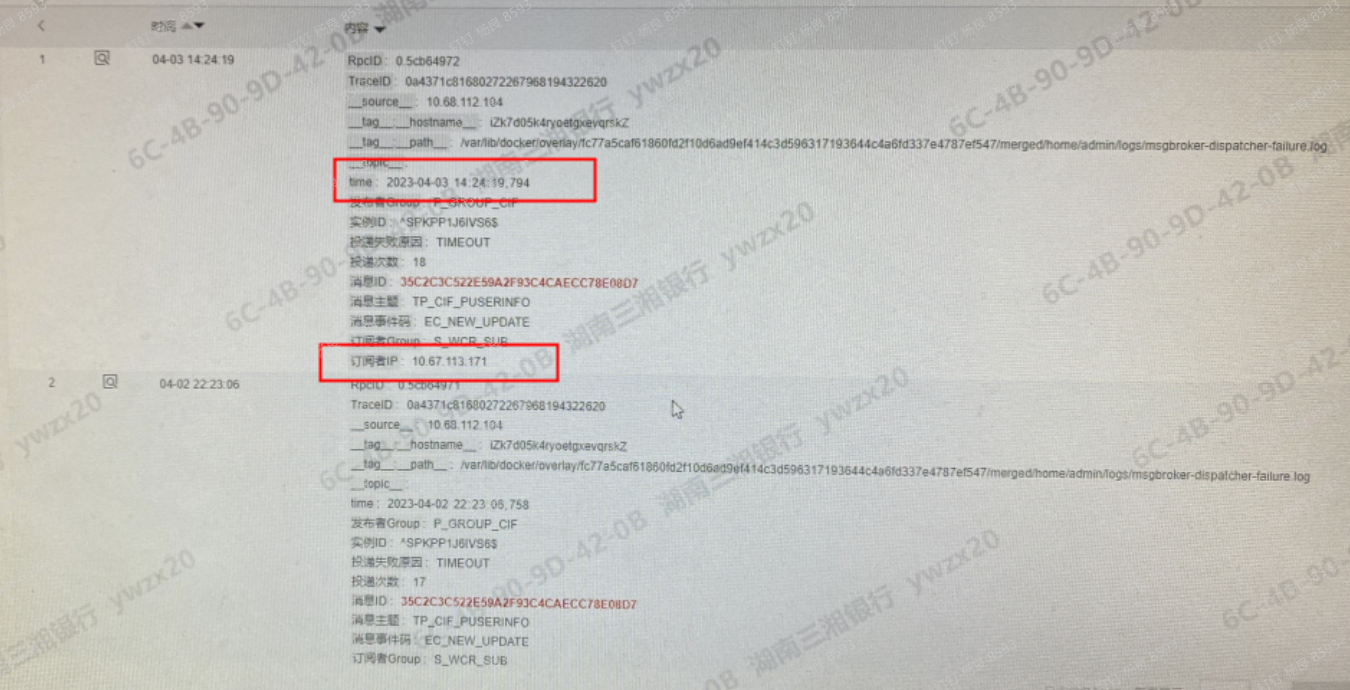
从上方可以看到,broker在4月3日尝试做一次投递,投递的ip是171这个ip,投递超时。
-
查看订阅方应用日志,找不到4月3日的投递日志。
-
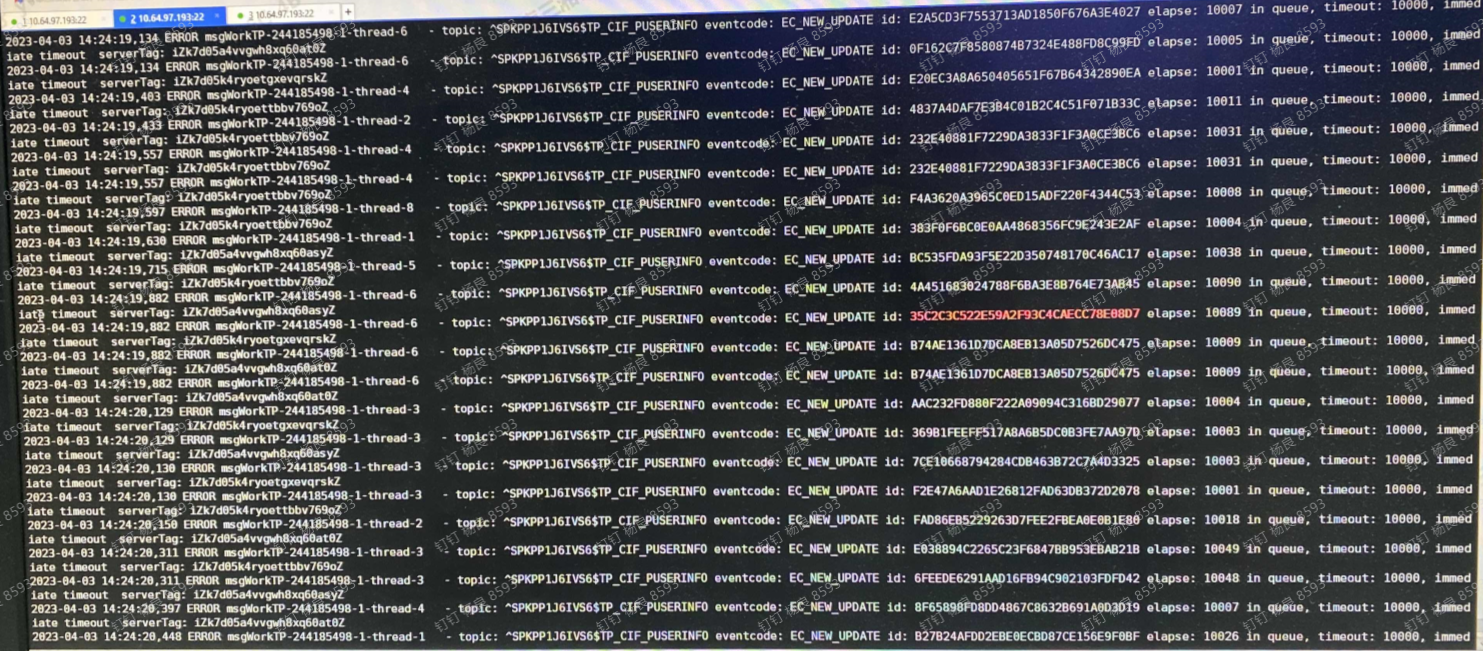
查看订阅方的消息sdk日志,显示消息超时。
注意图中的elapse:10089 in queue,当时我是不理解这里的。
总结下:
上面就是一个典型的消息积压场景,订阅端未按时返回消息回执。
奇怪的是,订阅端应用日志里没有相关的记录。
按理说,收到一个消息后,我做了个耗时较旧的操作,在超过消息投递超时时间后进入积压,这才是比较合理的。
1.解决方案
1.1 具体措施
修改线程池参数,在订阅端xml文件中做调整,具体参数为:
<sofa:binding.msg_broker>
<sofa:attributes messageTPCorePoolSize="20" messageTPMaxPoolSize="40" messageTPMaxQueueSize="200" />
</sofa:binding.msg_broker>
<!-- 根据和阿里沟通的经验,上面几个参数,他们一般采用1:2:10的比例调整.例如: 100:200:1000 -->
-
messageTPCorePoolSize
线程池中能够同时执行的最小线程数。
在任务数量不足以填满线程池的情况下,线程池中保持的线程数量就是CorePoolSize的大小。如果任务数量超过了CorePoolSize,线程池会根据需要创建新的线程来处理任务,直到线程池中的线程数量达到MaxPoolSize。
-
messageTPMaxPoolSize
线程池中能够容纳的最大线程数。
当任务数量达到一定程度时,线程池会不断创建新的线程,直到线程数量达到MaxPoolSize。当任务数量超过MaxPoolSize时,任务将被放入任务队列中等待执行,直到任务队列满了。
-
messageTPMaxQueueSize
线程池中任务队列的最大容量。
当任务数量超过CorePoolSize,但线程池中的线程数量已达到MaxPoolSize时,新的任务将被放入任务队列中等待执行。如果任务队列已满,线程池将无法接受新的任务,并采取拒绝策略进行处理。
这些参数的设定可以对线程池的性能、吞吐量、任务响应时间等方面产生影响,需要根据实际应用场景来进行调整。
如果任务数量较少、任务处理时间短,可以适当降低CorePoolSize和MaxPoolSize的大小,减少线程的创建和销毁,降低线程池的开销;
如果任务数量较多、任务处理时间长,可以适当增加CorePoolSize和MaxPoolSize的大小,提高线程池的并发能力。
同时,需要根据任务队列的大小、拒绝策略等方面进行综合考虑,以提高线程池的效率和稳定性。
完整配置可参考下方:
<bean id="xxMessageListener" class="xx.xxMessageListener">
<property name="groupName" value="S_xx_SUB" />
</bean>
<sofa:consumer id="mqConsumer" group="S_XX_SUB">
<sofa:listener ref="xxMessageListener" />
<sofa:channels>
<sofa:channel value="TP_XX">
<sofa:event eventType="direct" eventCode="EC_XX"
persistence="true" />
</sofa:channel>
</sofa:channels>
<sofa:binding.msg_broker>
<sofa:attributes messageTPCorePoolSize="20" messageTPMaxPoolSize="40" messageTPMaxQueueSize="200" />
</sofa:binding.msg_broker>
</sofa:consumer>

1.2 原因分析
假设一下子推送过来1万条消息,而我线程池中可用线程只有10个。
最大也只能跑到MaxPoolSize,那么必然会有多余的消息要等待处理,即MaxQueueSize。
到当等待到能处理时,SDK会校验当前时间和服务器消息时间。
对于超时的,直接返回,是会不进入业务逻辑中的。
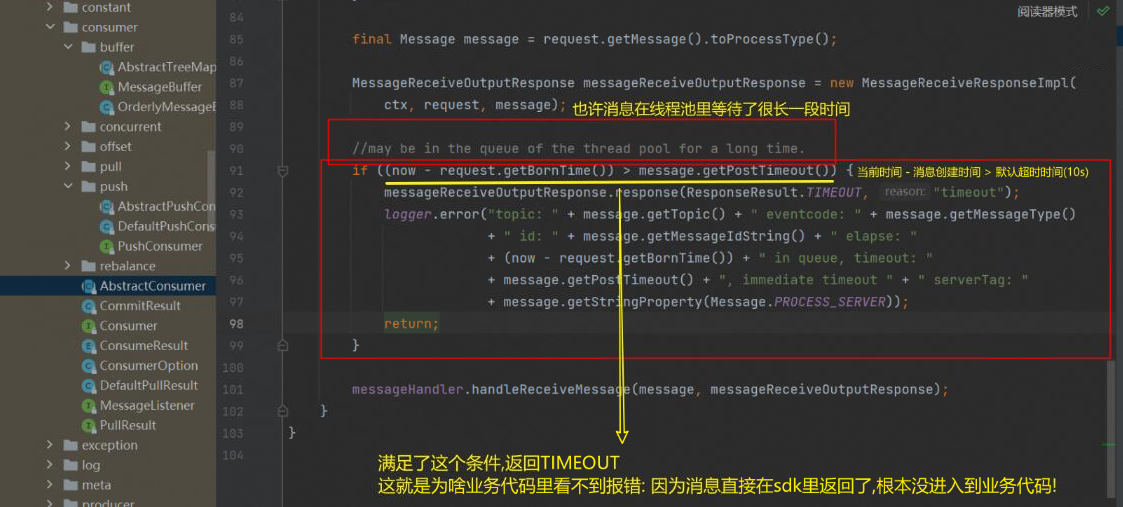
为什么消息投递,broker要设置一个投递超时时间?
在MQ中,当MQ Broker向订阅端投递消息时,为了避免因为某些原因导致消息不能被及时处理而一直阻塞等待,会设置一个投递超时时间。
如果订阅端在超时时间内未能确认消费该条消息,那么MQ Broker会将该条消息重新投递或者将其放入死信队列中。
-
避免消息无限制地阻塞等待
如果消息一直阻塞等待直到订阅端确认处理,那么如果订阅端出现了问题(如宕机、网络异常等),那么MQ Broker就会一直等待,从而导致消息不能被及时处理,进而影响系统的稳定性和可靠性。
-
提高消息的处理速度
如果超时时间设置得太长,那么可能会导致消息不能及时处理,从而影响系统的处理速度和性能。
-
避免资源的浪费
如果消息一直阻塞等待,那么会占用MQ的资源(如存储空间、网络带宽等),从而导致资源的浪费。
因此,在MQ中,设置投递超时时间可以避免消息在阻塞等待的过程中影响系统的稳定性和可靠性,提高系统的处理速度和性能,避免资源的浪费。
2.排查过程
在得出结论之前,我们并不知道是性能问题。
这是在测试环境演示,我的本机ip是10.7.133.108
2.1 检查端口情况
消息服务器的端口是9529,检查本机是否在与broker通讯。
[sxappopt@template-Centos7 ~]$ ss -an|grep 9529
tcp ESTAB 0 0 10.7.133.108:51224 100.100.0.198:9529
tcp ESTAB 0 0 10.7.133.108:36590 100.100.0.188:9529
tcp ESTAB 0 0 10.7.133.108:38538 100.100.0.69:9529
tcp ESTAB 0 0 10.7.133.108:55434 100.100.0.173:9529
以最后一条为例,可以看到
本地的55434端口在与100.100.0.173的9529端口做通讯。
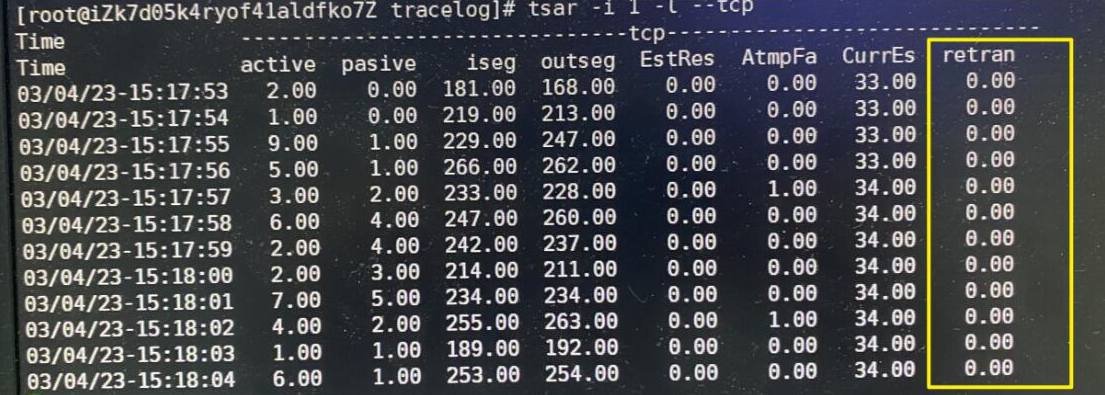
2.2 检查tcp重传
订阅端响应给broker时,看是否有重传,排除网络问题导致的超时。
使用阿里的tsar工具排查
tsar -tcp -C
# 或者图中的命令
2.3 检查cup、磁盘使用情况
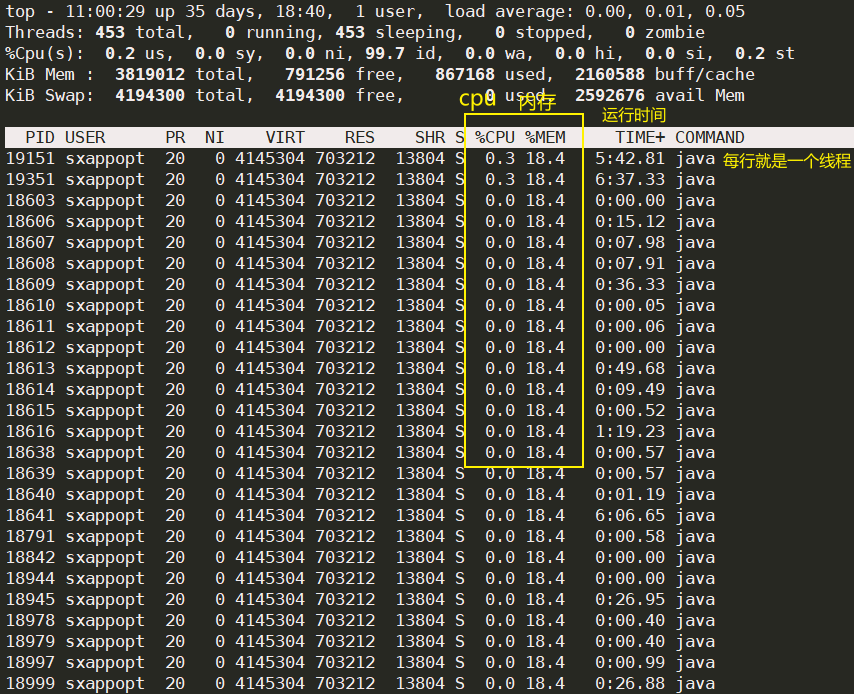
2.4 检查线程使用情况
top -H -p pid
2.5 导出订阅端服务jstack
# jps查看java进程信息
[sxappopt@template-Centos7 ~]$ jps
18603 message-center-executable-20230417.jar
11470 Jps
# jstack输出到txt
jstack 18603 > jstack_result.txt