本文对核方法(kernel method)进行简要的介绍(https://www.jianshu.com/p/8e2649a435c4)。
核方法的主要思想是基于这样一个假设:“在低维空间中不能线性分割的点集,通过转化为高维空间中的点集时,很有可能变为线性可分的” ,例如下图
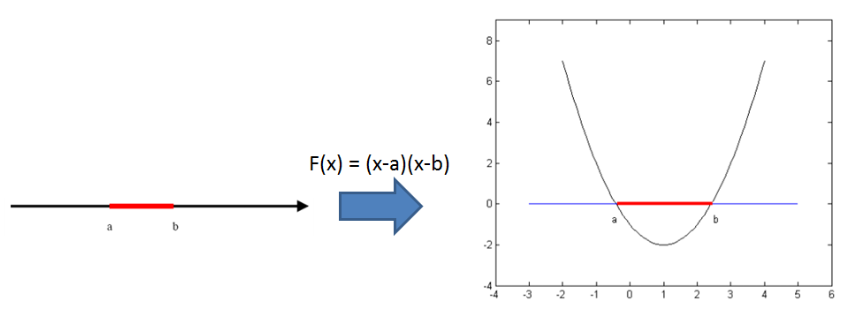

左图的两类数据要想在一维空间上线性分开是不可能的,然而通过F(x)=(x-a)(x-b)把一维空间上的点转化为右图上的二维空间上,就是可以线性分割的了。
然而,如果直接把低维度的数据转化到高维度的空间中,然后再去寻找线性分割平面,会遇到两个大问题,一是由于是在高维度空间中计算,导致curse of dimension问题;二是非常的麻烦,每一个点都必须先转换到高维度空间,然后求取分割平面的参数等等;怎么解决这些问题?答案是通过核戏法 (kernel trick)。
(pku, shinningmonster, sewm)
Kernel Trick: 定义一个核函数K(x1,x2) = <\phi(x1), \phi(x2)>, 其中x1和x2是低维度空间中点(在这里可以是标量,也可以是向量),\phi(xi)是低维度空间的点xi转化为高维度空间中的点的表示,< , > 表示向量的内积。
这里核函数K(x1,x2)的表达方式一般都不会显式地写为内积的形式,即我们不关心高维度空间的形式。核函数巧妙地解决了上述的问题,在高维度中 向量的内积通过低维度的点的核函数就可以计算了。这种技巧被称为Kernel trick。这里还有一个问题:“为什么我们要关心向量的内积?”,一般地,我们可以把分类(或者回归)的问题分为两类:参数学习的形式和基于实例的学习 形式。
参数学习的形式就是通过一堆训练数据,把相应模型的参数给学习出来,然后训练数据就没有用了,对于新的数据,用学习出来的参数即可以得到相应的结论;
而基于实例的学习(又叫基于内存的学习)则是在预测的时候也会使用训练数据,如KNN算法。而基于实例的学习一般就需要判定两个点之间的相似程度,一般就通过向量的内积来表达。从这里可以看出,核方法不是万能的,它一般只针对基于实例的学习。
紧接着,我们还需要解决一个问题,即核函数的存在性判断和如何构造? 既然我们不关心高维度空间的表达形式,那么怎么才能判断一个函数是否是核函数呢?
Mercer 定理:任何半正定的函数都可以作为核函数。所谓半正定的函数f(xi,xj),是指拥有训练数据 集合(x1,x2,...xn),我们定义一个矩阵的元素aij = f(xi,xj),这个矩阵式n*n的,如果这个矩阵是半正定的,那么f(xi,xj)就称为半正定的函数。这个mercer定理不是核函数必要条件,只 是一个充分条件,即还有不满足mercer定理的函数也可以是核函数。常见的核函数有高斯核,多项式核等等,在这些常见核的基础上,通过核函数的性质(如 对称性等)可以进一步构造出新的核函数。SVM是目前核方法应用的经典模型。
上述是目前我所理解到的核方法的主要精神。
======================================================
核函数方法简介
(1)核函数发展历史
早在1964年Aizermann等在势函数方法的研究中就将该技术引入到机器学习领域,但是直到1992年Vapnik等利用该技术成功地将线性
SVMs推广到非线性SVMs时其潜力才得以充分挖掘。而核函数的理论则更为古老,Mercer定理可以追溯到1909年,再生核希尔伯特空间
(ReproducingKernel
Hilbert Space, RKHS)研究是在20世纪40年代开始的。
(2)核函数方法原理
根据模式识别理论,低维空间线性不可分的模式通过非线性映射到高维特征空间则可能实现线性可分,但是如果直接采用这种技术在高维空间进行分类或回归,则存
在确定非线性映射函数的形式和参数、特征空间维数等问题,而最大的障碍则是在高维特征空间运算时存在的“维数灾难”。采用核函数技术可以有效地解决这样问
题。
设x,z∈X,X属于R(n)空间,非线性函数Φ实现输入间X到特征空间F的映射,其中F属于R(m),n<<m。根据核函数技术有:
K(x,z) =<Φ(x),Φ(z)
>
(1)
其中:<,
>为内积,K(x,z)为核函数。从式(1)可以看出,核函数将m维高维空间的内积运算转化为n维低维输入空间的核函数计算,从而巧妙地解决了在高维特征空间中计算的“维数灾难”等问题,从而为在高维特征空间解决复杂的分类或回归问题奠定了理论基础。
(3)核函数特点
核函数方法的广泛应用,与其特点是分不开的:
1)核函数的引入避免了“维数灾难”,大大减小了计算量。而输入空间的维数n对核函数矩阵无影响,因此,核函数方法可以有效处理高维输入。
2)无需知道非线性变换函数Φ的形式和参数.
3)核函数的形式和参数的变化会隐式地改变从输入空间到特征空间的映射,进而对特征空间的性质产生影响,最终改变各种核函数方法的性能。
4)核函数方法可以和不同的算法相结合,形成多种不同的基于核函数技术的方法,且这两部分的设计可以单独进行,并可以为不同的应用选择不同的核函数和算法。
(4)常见核函数
核函数的确定并不困难,满足Mercer定理的函数都可以作为核函数。常用的核函数可分为两类,即内积核函数和平移不变核函数,如:
1)高斯核函数K(x,xi) =exp(-||x-xi||2/2σ2;
2)多项式核函数K(x,xi)=(x·xi+1)^d,
d=1,2,…,N;
3)感知器核函数K(x,xi) =tanh(βxi+b);
4)样条核函数K(x,xi) = B2n+1(x-xi)。
(5)核函数方法实施步骤
核函数方法是一种模块化(Modularity)方法,它可分为核函数设计和算法设计两个部分,具体为:
1)收集和整理样本,并进行标准化;
2)选择或构造核函数;
3)用核函数将样本变换成为核函数矩阵,这一步相当于将输入数据通过非线性函数映射到高维
特征空间;
4)在特征空间对核函数矩阵实施各种线性算法;
5)得到输入空间中的非线性模型。
显然,将样本数据核化成核函数矩阵是核函数方法中的关键。注意到核函数矩阵是l×l的对称矩阵,其中l为样本数。
(6)核函数在模式识别中的应用
1)新方法。主要用在基于结构风险最小化(Structural Risk Minimization,SRM)的SVM中。
2)传统方法改造。如核主元分析(kernel PCA)、核主元回归(kernel PCR)、核部分最小二乘法(kernel PLS)、核Fisher判别分析(Kernel Fisher Discriminator, KFD)、核独立主元分析(Kernel Independent Component Analysis,KICA)等,这些方法在模式识别等不同领域的应用中都表现了很好的性能。
======================================================
【Kernel Method】Kernel Method核方法介绍
引言
核方法是20世纪90年代模式识别与机器学习领域兴起的一场技术性革命。其优势在于允许研究者在原始数据对应的高维空间使用线性方法来分析和解决问题,且能有效地规避“ 维数灾难”。在模式识别的特征抽取领域,核方法最具特色之处在于其虽等价于先将原数据通过非线性映射变换到一高维空间后的线性特征抽取手段,但其不需要执行相应的非线性变换,也不需要知道究竟选择何种非线性映射关系。目前,核方法已大量应用到机器学习、模式识别、生物特征识别、生物信息学、数据挖掘、机器学习、图像去噪等领域。
核
方法在实际应用中仍然面临大训练集下实现效率低甚至不能实时应用的缺点。一方面,核方法对一个样本进行特征抽取时,需计算该样本与所有训练样本之间的核函
数,因此,核方法的特征抽取效率会随着训练样本集的增大而下降。另一方面,核方法作为一类学习方法,依赖和期待利用大训练集来提高方法的泛化性能。这样的
特点阻碍了核方法的推广和应用。
解决模式识别问题的技术框架
模式识别的目标是依据一个物体的描述数据,区分其所属类别。一个模式识别系统主要包括数据采集、预处理、特征抽取(或特征选择)、分类或匹配等主要 步骤。其中,特征抽取主要采用变换的技术实现,在某些情景中,特征选择代替了特征抽取,特征选择一般是从原始数据的所有分量中挑选出若干便于区分各类目标 的分量。分类步骤借助于分类器并依据样本的特征抽取结果,识别出一个样本所对应的类别。
特征抽取与变换技术
特征抽取有两方面作用:一是寻找针对模式的最具鉴别性的描述,以使此类模式的特征能最大程度地区别于彼类;二是在适当的情况下实现模式数据描述的维数压缩。
在特征抽取的众多方法里,其中主流的是基于空间变换的方法。其目标是将原始数据变换到一个新空间,以使在新空间中不同类别间数据有最大分离性,或使新空间中的数据对原数据有最好的描述能力。基于变换特征抽取技术分为线性和非线性两部分,常用的线性变换技术包括主成分分析(PCA)、线性鉴别分析(LDA)等。线性变换技术一般是一种性能较优的降维技术,但其很难根本改变原始数据的线性可分离性。
非线性变换与特征抽取
上图显示了原始数据空间到特征空间(feature space)的变换(Φ : R² -> R³ ,即(x1,x2) -> (z1,z2,z3)=(x1²,√2x1x2,x2²)。这样由二维数据转换为三维数据之后,决策边界(decision boundary)由一个椭圆变换成为一个超平面(hyperplane),因此,在特征空间中,问题简化成根据映射的数据去估计线性的分界面(即超平 面)的问题。
于是我们可知,该变换用到的是多项式核函数。
常用核函数
常用的核函数包括多项式核函数、sigmoid核函数、高斯核函数,其分别定义如下
多项式核函数:
sigmoid核函数:
高斯核函数:
本文小结
理论上讲,核方法可将原样本数据映射到一个非常高甚至无穷维的空间,但是它所对应的特征方程中矩阵的维数仅为训练样本个数;换言之,虽然核方法本质上将数据变换到高维空间,但它不需直接在高维空间中求解;其问题求解空间的维数仅等于其训练样本个数。实际上,这正是核方法作为一种非线性方法能克服维数灾难的关键。
参考文献:
1、模式识别中的核方法及其应用,徐勇 张大鹏 杨健著
2、Learning with Kernels
======================================================
======================================================
REF:
http://blog.csdn.net/xianlingmao/article/details/7719122
http://blog.sina.com.cn/s/blog_5dd2e9270100bs2z.html
http://www.jianshu.com/p/4cb9c25be860