前言 本篇文章介绍来自大连理工大学的论文Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation,收录于 ICCV 2023 Oral,研究用于图像融合和分割的多交互特征学习和全时多模态基准。
本文转载自我爱计算机视觉
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

- 文章链接:https://arxiv.org/pdf/2308.02097.pdf
- 论文作者:Jinyuan Liu, Zhu Liu, Guanyao Wu, Long Ma, Risheng Liu, Wei Zhong, Zhongxuan Luo, and Xin Fan
- 代码链接:https://github.com/JinyuanLiu-CV/SegMiF
引言
实现感知友好的视觉表达和精确的语义理解是多模态图像融合的两大基本目标。现有大部分方法都仅考虑提升融合图像的视觉效果,忽略了对下游高级视觉任务的支持。目前也有一些研究尝试通过级联融合与感知网络设计联合框架,结合加权损失函数实现端到端学习。
本文认为这些方案仍存在两个核心挑战:
- 同时为视觉感知与语义理解任务寻找合适的特征是非常困难的。
- 现有的多模态数据集仅关注图像融合效果,或者缺少与图像对应的分割标签,为融合与分割任务的探索带来阻碍。
为了解决上述问题,我们提出了一个语义特征引导多交互式特征学习架构:SegMiF (Multi-interactive Feature learning architecture for image fusion and Segmentation)。
该网络结构包括融合子网络与分割子网络以及分层交互注意力块 Hierarchical Interactive Attention (HIA)。通过引入多任务动态权重因子实现对融合特征自适应学习。
另外,我们还构建了市面上最全标注率(98.16%),高精度配准,15 个类别涵盖多种挑战场景的多模态语义分割数据集 Full-time Multi-modality Benchmark (MFB)。
方法
为了实现融合与后续感知任务的统筹兼顾,本文将融合与分割任务的求解联合定制为一个优化目标:
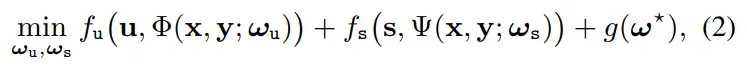
其中 g(·) 是联合优化两个任务约束项,我们通过分层注意力 (HIA) 来实现这一目标。
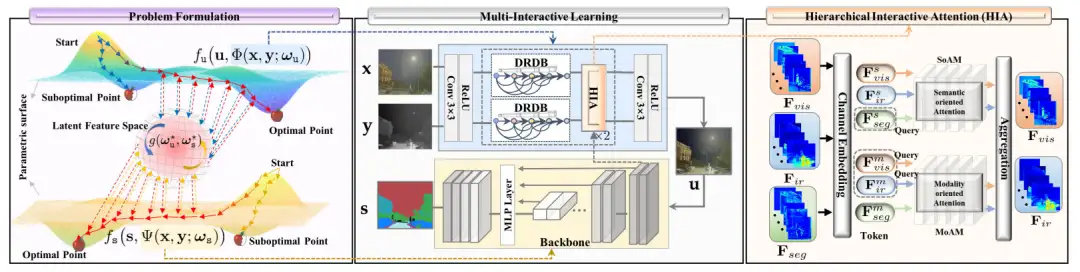
分层注意力机制 HIA 可以构建模态特征 , 和分割特征 的精细映射,从而使模态/语义特征能够完全相互作用,具体如下图所示:
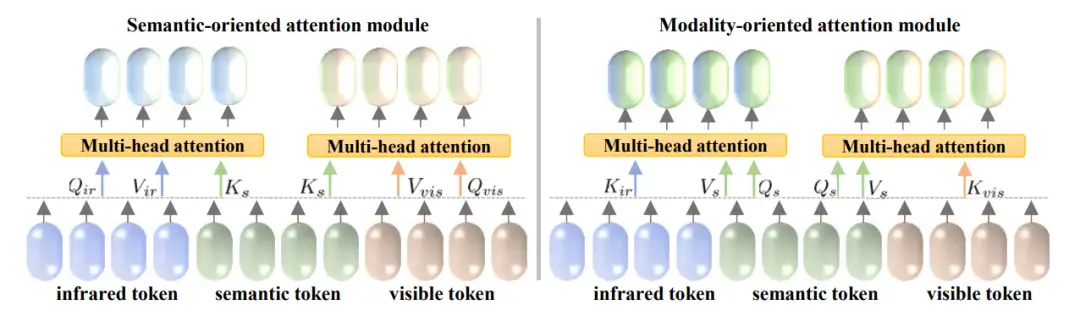
分层注意力机制包括面向语义与面向模态的两类注意力机制,通过引入语义信息,提出机制可以实现融合特征对下游任务的高效表达。
通过观察损失值的下降速率以优化网络的收敛过程,本文引入了任务动态权重因子来自动调整每个任务间相应权重,从而平衡交互特征对应关系,克服了繁琐的手工调整。通过下述公式实现第i个任务的动态权重设置:
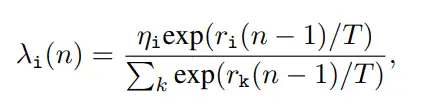
此外,我们构建了一个智能多波段双目成像系统,并收集了一个用于融合和分割且内有15个像素级类别注释的多模态场景解析数据集。该数据集标注率高达98.16%,包含在不同光照条件下的各种真实驾驶场景,还包括带有雨、雾、强光等特殊情况的挑战场景。所提出的数据集克服了领域现存数据类别较少、注释稀疏和场景单调的问题,旨在促进实际的自动驾驶和语义理解任务的发展。


实验
定量实验
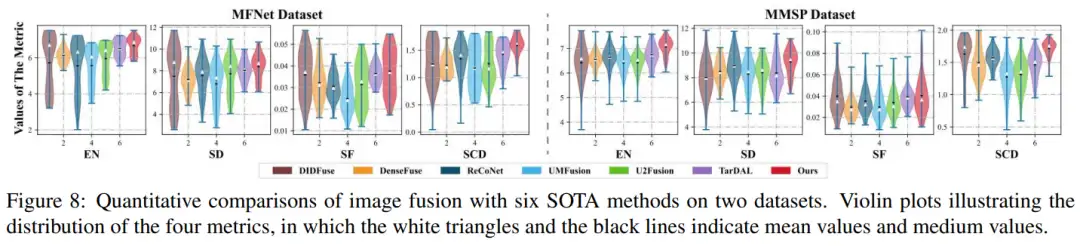
我们在四个指标(EN,SD,SF与SCD)取得了一致的优势,其中最高的 EN 和 SD 表明我们的方法能够显著地保留源图像的大量信息,并拥有较高的像素对比度。
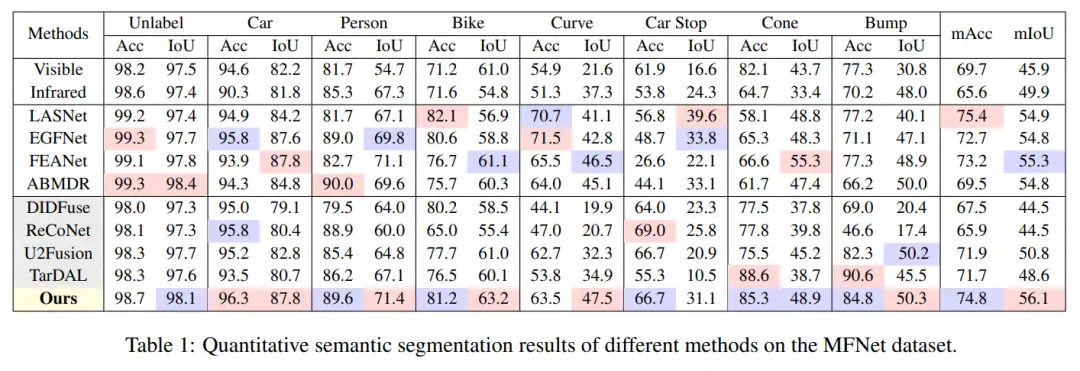
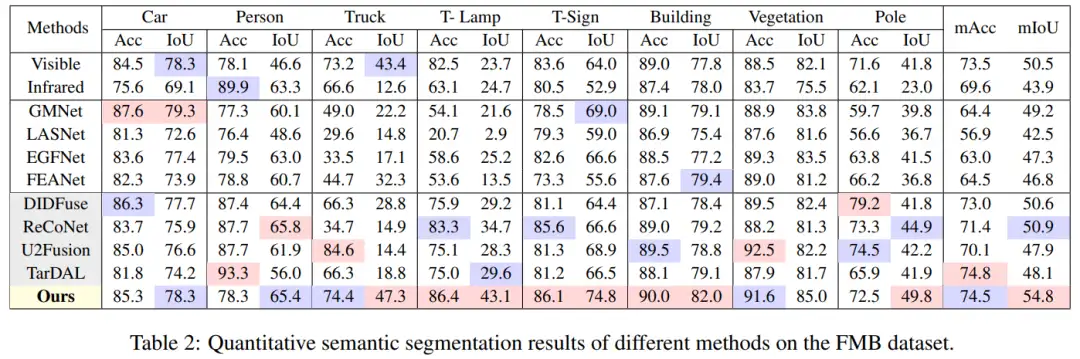
我们在 MFNet 和 MFB 数据集上都取得了最高的 mIoU,与第二名相比提高了 7.66%。同时注意到我们的方法对于人和车的优越结果意味着我们的方法在应用于现实世界感知时有更高的性能。
定性实验

在视觉效果上,本文方法可以有效克服各类可见光降质因素的影响,例如强光干扰与极暗成像条件。一方面本文方法有效提取显著红外目标,例如第一行的行人。另一方面,本文方法可以有效保存纹理细节,更有利于后续语义分割任务。

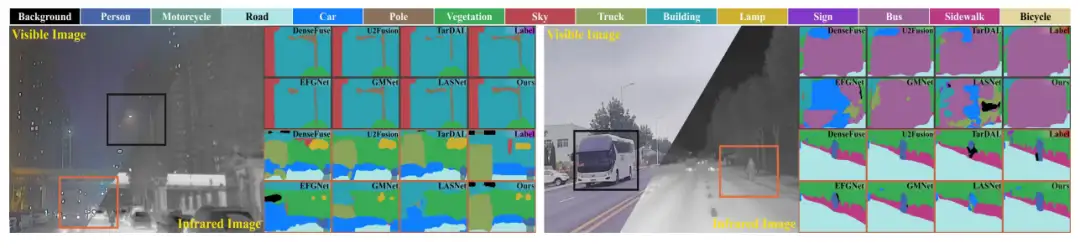
MFNet 和 MFB 数据集上分割的可视化结果如上图所示。本文方法不仅在现有稀疏标注数据集提升明显,也能够有效解决新数据集上各类复杂成像条件的影响。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
RecursiveDet | 超越Sparse RCNN,完全端到端目标检测的新曙光
ICCV 2023 | ReDB:可靠、多样、类平衡的域自适应3D检测新方案!
ICCV2023 | 清华大学提出FLatten Transformer,兼顾低计算复杂度和高性能
ICCV'23 | MetaBEV:传感器故障如何解决?港大&诺亚新方案!
RCS-YOLO | 比YOLOv7精度提高了2.6%,推理速度提高了60%
国产130亿参数大模型免费商用!性能超Llama2-13B支持8k上下文,哈工大已用上
KDD 2023奖项出炉!港中文港科大等获最佳论文奖,GNN大牛Leskovec获创新奖
大连理工联合阿里达摩院发布HQTrack | 高精度视频多目标跟踪大模型
ICCV 2023 | Actformer:从单人到多人,迈向更加通用的3D人体动作生成
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary