应对数据爆炸时代,揭秘向量数据库如何成为AI开发者的新宠,各数据库差异对比
随着大模型的爆火,向量数据库也越发成为开发者关注的焦点。为了方便大家更好地了解向量数据库,我们特地推出了《Hello, VectorDB》系列,本文将从宏观角度、向量数据库与其他算法库的区别、技术难点及如何选择向量数据库等方面,带大家认识真正的向量数据库。
在正式开始前,先来了解一个背景:非结构化数据呈爆炸式增长,而我们可以通过机器学习模型,将非结构化数据转化为 embedding 向量,随后处理分析这些数据。在此过程中,向量数据库应运而生。向量数据库是一种为了高效存储和索引 AI 模型产生的向量嵌入(embedding)数据而专门设计的数据库。
1.宏观解读向量数据库
如今,强大的机器学习模型配合 Milvus 等向量数据库的模式已经为电子商务、推荐系统、语义检索、计算机安全、制药等领域和应用场景带来变革。而对于用户而言,除了足够多的应用场景,向量数据库还需要具备更多重要的特性,包括:
- 可灵活扩展、支持调参:当向量数据库中存储的非结构化数据量增长至数亿或数十亿时,支持跨节点水平扩展这一特性显得至关重要。因为,没有人愿意通过每 3 个月在服务器中手动插入一次 RAM 内存条这种方法来实现扩展。此外,由于数据插入速率、查询速度和基础硬件条件会根据应用场景而有所变化,所以向量数据库还需要支持灵活调参。
- 多租户、数据隔离:为每一个新用户的数据创建一个全新向量数据库,显然不合常理。因此向量数据库需要支持多租户。同时,通过支持数据隔离,只有 collection 所有者允许共享数据时,collection 数据才对其他用户可见。否则,在向量数据库中对任何一个 collection 进行数据插入、删除、查询等操作时,其他用户均不可见。
- 完整的 API:如果没有完整的 API 和 SDK,基本算不上是真正的数据库。Milvus 向量数据库就提供了 Python、Node、Go 和 Java 等语言的 SDK,方便用户轻松连接和管理 Milvus 向量数据库。
- 直观的用户界面或管理控制台:直观的用户界面可以大大降低学习成本。用户可以通过界面来体验向量数据库发布的新功能和工具。
1.1 向量数据库与 ANN 算法库的区别
我们经常听到一个这样的错误观念——向量数据库只是在 ANN(approximate nearest neighbor,近似最近邻)算法上封装了一层。但这种说法大错特错。
- 向量数据库可以处理大规模数据,而 ANN 算法库只能处理小型的数据集
从本质上来看,以 Milvus 为代表的向量数据库是一套完整的非结构化数据解决方案,具备诸多功能——云原生、多租户、可扩展性等。但诸如 FAISS 等都是轻量级 ANN 算法库,这些算法库的主要用于构建向量索引(一种数据结构),从而加速多维向量的最近邻检索。这些算法库可以轻松应对小型数据集。但是,随着数据集和用户数量不断增长,这些算法库无法处理大规模数据。
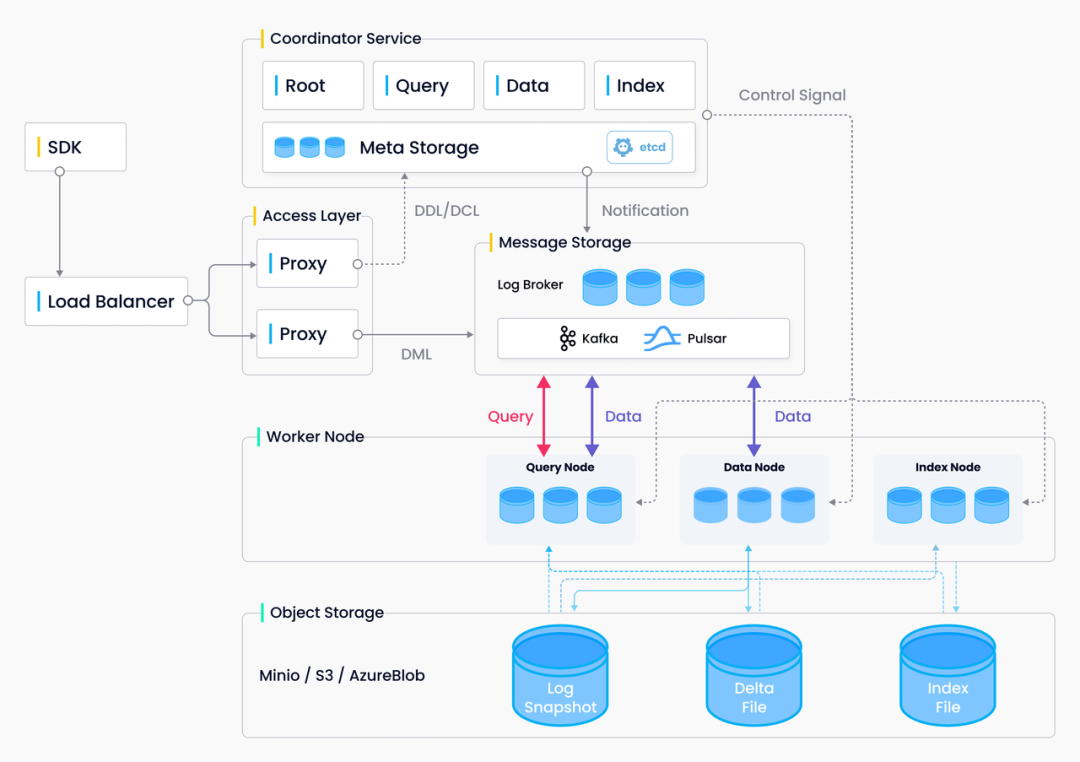
Milvus 架构图
- 向量数据库是一套完整的解决方案,而 ANN 算法库只是其中一部分
以 Milvus 为代表的向量数据库与 ANN 算法库另一大不同之处在于:Milvus 是一套完整的服务,而算法库是需要被集成到应用中去的。因此,从某种意义上而言,算法库是向量数据库的组件之一。这有点类似于 Elasticsearch 是一套基于 Apache Lucene 的搜索引擎解决方案。
为了具体说明这种区别, 我们来举一个例子。
在 Milvus 向量数据库中插入非结构化数据只需要三行代码即可。
from pymilvus import Collection
collection = Collection('book')
mr = collection.insert(data)
但对于 FAISS 或 ScaNN 这样的算法库,没有这样可以简单插入数据的方法。即使自己通过代码实现插入数据,ANN 算法库仍然缺乏可扩展性和多租户等特性。
- 算法库距离生产可用的产品,差了一个向量数据库的距离
对于一个想要将向量检索功能集成进生产环境的用户,即使完成了算法库集成的开发,想要让其生产可用,更需要让其能够被运维:
- 动态的可扩展性,在系统的压力较大时能做到扩容,提供多个可读副本
- 高可用性,在发生异常时能够继续提供降级服务
- 正确的快速恢复,在发生异常状态后能够快速恢复到正常的状态,并且保证数据的一致性和完整性
- 多租户,足够的权限控制
- 对于系统状态可监控,能够让运维团队乃至开发者快速发现系统异常并且处理,等等
而这些功能,是算法库本身并不具备的,往往需要成熟的数据库产品 / 服务来提供。
1.2 向量数据库与传统数据库向量检索插件的区别**
越来越多的传统关系型数据库和检索系统(如 Clickhouse、Elasticsearch 等)开始提供内置的向量检索插件。
例如,Elasticsearch 8.0 支持通过 Restful API 来插入向量和开展 ANN 检索。但是,向量检索插件的问题显而易见——无法提供 embedding 向量管理和检索的全栈方法。这些插件仅可在现有的架构基础上用作优化方案,使用场景十分有限。在传统数据库基础上开发非结构化数据应用就如同在汽油车中安装锂电池和电动机一样不合常理。向量检索插件不支持灵活调参,也不提供易用的 API 或 SDK。但这两点是向量数据库的基本特性。
为了展示向量数据库与向量检索插件的区别,文本将以 Elasticsearch ANN 搜索引擎为例,其他向量检索插件运行方式类似,因此不进一步展开。
Elasticsearch 的 dense_vector 字段支持向量数据类型,且可以通过 knnsearch endpoint 进行向量查询。
PUT index
{"mappings": {"properties": {"image-vector": {"type": "dense_vector","dims": 128,"index": true,"similarity": "l2_norm"}}}}
PUT index/_doc
{"image-vector": [0.12, 1.34, ...]}
GET index/_knn_search
{"knn": {"field": "image-vector","query_vector": [-0.5, 9.4, ...],"k": 10,"num_candidates": 100}}
Elasticsearch 的 ANN 插件仅支持 HNSW 一种索引和 L2(欧式距离)一种距离计算方法。但下面,让我们来使用向量数据库 Milvus(以 pymilvus 为例)。
>>> field1 = FieldSchema(name='id', dtype=DataType.INT64, description='int64', is_primary=True)
>>> field2 = FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, description='embedding', dim=128, is_primary=False)
>>> schema = CollectionSchema(fields=[field1, field2], description='hello world collection')
>>> collection = Collection(name='my_collection', data=None, schema=schema)
>>> index_params = {
'index_type': 'IVF_FLAT',
'params': {'nlist': 1024},
"metric_type": 'L2'}
>>> collection.create_index('embedding', index_params)
>>> search_param = {
'data': vector,
'anns_field': 'embedding',
'param': {'metric_type': 'L2', 'params': {'nprobe': 16}},
'limit': 10,
'expr': 'id_field > 0'
}
>>> results = collection.search(**search_param)
虽然 Elasticsearch 和 Milvus 都支持创建索引、插入 embedding 向量、执行 ANN 向量检索,但从以上示例中可以明显看出,Milvus 具备更直观的向量检索 API(可更好服务用户),支持更多样的向量索引类型和距离计算公式(方便用户灵活调参)。Milvus 还计划在未来支持更多的索引类型,并允许用户通过类似 SQL 语句进行查询,从而进一步提升向量数据库的可用性。
简而言之,诸如 Milvus 的向量数据库比向量检索插件更好用。因为 Milvus 是从零开始构建的向量数据库,相较而言,具备更丰富的功能和更适合非结构化数据的系统架构。
1.3 向量数据库的优势
向量数据库的主要应用领域为相似性检索、机器学习、人工智能等。与传统数据库比较,向量数据库具备以下几点优势:
- 高维向量检索:向量数据库可以高效进行高维向量相似性检索,非常适用于机器学习和人工智能应用中,如:图片识别、自然语言处理、推荐系统等。
- 灵活性:向量数据库可以处理多样的向量数据类型,包括稀疏向量和稠密向量。此外,向量数据库还可以处理其他的数据类型,包括:数字、文本、二进制数据(Binary)。
- 性能:相较于传统数据,使用向量数据库进行相似性检索更高效。
- 支持选择不同索引结构:向量数据库支持用户根据不同的应用场景和数据类型构建不同的索引结构。
总结一下,向量数据库在相似性检索和机器学习场景中具有显著优势,能够快速、高效检索和召回高维向量数据。
1.4 选择向量数据库时需要考量的点
-
性能
如上述,查询性能(查询的响应时间,系统的吞吐能力)是在选型向量数据库时的一个重要参考点,市面上现有的向量数据库的 Benchmark 有:- ANN-Benchmark 是一种用于评估各种向量数据库和近似最近邻(ANN)算法性能的工具
- VectorDBBench 是一款开源的对于各种主流向量数据库和云服务的性能对比工具,提供了 QPS / 成本 / 响应延时等多个维度的比较,提供了方便的 Web UI
- LeaderBoard TL;DR VectorDBBench 的 “太长不看” 版本
-
成本
由于 AIGC 浪潮的火热, 大量新的开发者涌入这个领域,因此在选择向量数据库产品时,成本也是用户具体做出决策的重要指标。在产品初期,数据体量不大的情况下,能够用最少的成本达到应用需求的响应时间和系统吞吐,是开发者最希望达到的目标。
- 功能和易用性
除了性能之外,一款流行的数据库必然也提供了生产可用的产品特性,如:
- 高可用,快速恢复
- 成熟的指标监测体系及告警系统
- 定期备份及恢复
并且相较于算法库,能够对于用户屏蔽许多底层细节:
- 根据存储 / 性能考量,自动选择向量索引类型
- 根据需要的召回率(Recall)动态决定搜索参数
这些往往是用户在性能之外,选择向量数据库时考量的点。
2.向量检索实战&向量数据库如何选择
2.1 快速入门向量检索
2.1.1 Python-NumPy实现
向量数据库具有快速计算向量相似度的优势,能在 N 个向量中找出与目标向量在高维空间中最相似的前 K 个向量。然而,这种能力并非仅有向量数据库所具备。例如,我们可以通过使用 Python 的 NumPy 库,用不到 20 行代码就能实现最近邻算法。
以下是一个简单的例子:
import numpy as np
#Function to calculate euclidean distance
def euclidean_distance(a, b):
return np.linalg.norm(a - b)
#Function to perform knn
def knn(data, target, k):
#Calculate distances between target and all points in the data
distances = [euclidean_distance(d, target) for d in data]
#Combine distances with data indices
distances = np.array(list(zip(distances, np.arange(len(data)))))
#Sort by distance
sorted_distances = distances[distances[:, 0].argsort()]
#Get the top k closest indices
closest_k_indices = sorted_distances[:k, 1].astype(int)
#Return the top k closest vectors
return data[closest_k_indices]
我们可以试着生成 100 个 2 维向量,然后找出与向量 [0.5,0.5] 最近的邻居。
代码如下:
#Define some 2D vectors
data = np.random.rand(100, 2)
#Define a target vector
target = np.array([0.5, 0.5])
#Define k
k = 3
#Perform knn
closest_vectors = knn(data, target, k)
#Print the result
print("The closest vectors are:")
print(closest_vectors)
这种方法具有很大的灵活性,且实现起来成本低。如果你符合以下情况,我会推荐你使用 NumPy 或其他机器学习库进行向量搜索:
- 快速进行原型验证。
- 没有数据持久化的需求。
- 数据量小于一百万,且没有标量过滤的需求。
- 对查询性能要求不高。
2.1.2 FAISS 的向量检索
相对地,如果你需要快速构建原型系统并对性能有一定要求,FAISS 可能是一个好选择。FAISS 是 Meta 开源的一个库,用于高效相似性搜索和密集向量聚类。它能处理任意大小的向量集合,甚至是无法全部装入内存的集合。FAISS 还包含了用于评估和参数调优的工具。FAISS 是用 C++ 编写的,但提供了完整的 Python/NumPy 接口。
以下是一个基于 FAISS 的向量检索代码:
import numpy as np
import faiss
#Generate some example data
dimension = 64 # dimension of the vector space
database_size = 10000 # size of the database
query_size = 100 # number of queries to perform
np.random.seed(123) # make the random numbers predictable
#Generating vectors to index in the database (db_vectors)
db_vectors = np.random.random((database_size, dimension)).astype('float32')
#Generating vectors for query (query_vectors)
query_vectors = np.random.random((query_size, dimension)).astype('float32')
#Building the index
index = faiss.IndexFlatL2(dimension) # using the L2 distance metric
print(index.is_trained) # should return True
#Adding vectors to the index
index.add(db_vectors)
print(index.ntotal) # should return database_size (10000)
#Perform a search
k = 4 # we want to see 4 nearest neighbors
distances, indices = index.search(query_vectors, k)
#Print the results
print("Indices of nearest neighbors: \n", indices)
print("\nL2 distances to the nearest neighbors: \n", distances)
看起来足够简单,性能似乎也足够快,也能够应付小规模的生产场景。当然,还可以通过量化、降维、使用 GPU 等方案进一步提升查询性能。
然而,尽管向量搜索库如 Faiss 提供了强大和高效的向量搜索功能,但在实际生产环境中,它们存在一些限制。例如,Faiss 并没有提供处理数据的实时增删、缺乏多语言的支持,无法提供远程调用、不支持标量过滤、也不提供数据的持久化,可扩展性和容灾等问题的解决方案。
2.1.3 向量数据库之间的对比
正是因为这些原因,向量数据库应运而生,为我们提供了一种更完整、更适合实际应用场景的解决方案。向量数据库战场目前主要分为四个类别:
- 基于 PG、Clickhouse 等进行魔改或者插件化实现的向量数据库。这类解决方案以现有的关系数据库或列存数据库作为基础,通过修改或插件扩展的方式添加向量搜索功能,PG Vector 是这类解决方案的代表产品。
- 基于传统倒排搜索添加稠密向量索引支持的向量数据库。这类解决方案以倒排索引搜索引擎作为基础,通过扩展索引机制以支持向量搜索,ElasticSearch 是这类解决方案的代表产品。
- 基于向量检索库实现的轻量级向量数据库。这类解决方案以向量搜索库(如 Faiss)为核心,围绕其构建数据库功能。这些产品通常具有较小的体积和较高的运行效率,Chroma 是这类解决方案的代表产品。
- 基于原生向量设计的分布式向量云原生数据数据库。这类解决方案从零开始设计和实现向量数据库,整个系统从底层到顶层都针对向量搜索进行了优化,通常提供了更完整和高级的功能,包括分布式计算、容灾备份、数据持久化等,Zilliz Cloud/Milvus 是这类解决方案的代表产品。
不过,"Not All Vector Database are born equal"(并非所有向量数据库都生来平等)。在各类向量数据库中,每种解决方案都有其独特的优点和限制,并且它们各自适合于不同的应用场景。
在所有的向量数据库方案中,我个人对基于 PG、Clickhouse 等 进行魔改或者插件化实现的向量数据库(如 PG Vector)以及基于原生向量设计的分布式向量云原生数据数据库(例如 Zilliz Cloud/Milvus)这两种截然不同的解决方案特别看好。
接下来我们需要从用户场景需求,向量数据库的发展历史,向量检索的特殊性等多个角度来综合分析原因。
2.2 专用向量数据库的价值
向量数据库最早诞生于 2019 年,由 Zilliz 公司推出并开源了全球首款向量数据库 Milvus。在那个时期,向量数据库的功能相对比较简单,主要是基于向量检索库 Faiss 的基础上,封装了远程过程调用(RPC)接口,并支持了基于 Write-Ahead Logging(WAL)的持久化能力。
相比于传统的向量检索方法,Milvus 1.0 的最大意义在于解耦了业务逻辑、模型和数据存储这三者之间的紧密关联。这意味着应用开发者不再需要关注底层基础设施的维护工作,这些工作包括但不限于集群的部署、数据的持久化和数据的迁移等。因此,Milvus 1.0 为许多用户提供了从传统烟囱式的人工智能开发模式向大模型时代(在这个时代,开发者常常使用如下的开发模式:大语言模型(LLM)+ 编排工具 + 向量数据库)的过渡。
传统的向量检索应用场景包括了推荐系统、以图搜图、问答机器人、内容风控,面向的主要是具备较强 AI 能力和运维能力的企业级用户,用户关注的主要是查询能力、性能、大数据量下的可扩展性以及可运维性、可观测性、安全性等企业级能力。
随着大模型技术的蓬勃发展,向量数据库开始进入 2.0 时代,更多的个人开发者涌入赛道,对向量数据库的关注也逐渐迁移到开发效率、部署简单以及面向大模型加强场景的功能需求。也正是这波狂热的浪潮下诞生了诸如 Chroma 这样的套壳向量数据库,其跟存储引擎相关的代码不过寥寥十个文件。
不止 Chroma,DataStax、Redislab 等传统数据库厂商也纷纷加入战局。正如上文中提到的,基于 numpy 或者 Faiss 可以五分钟快速实现一个 "向量数据库"。然而,向量数据库绝不仅仅是用来进行简单的向量检索,要想真正提升开发者的开发效率和使用成本,需要系统开发者深入理解硬件、存储、数据库、AI、高性能计算、分布式系统、编译原理、云原生等方方面面,以确保其稳定性、性能和易用性。
构建向量数据库就像搭积木一样,需要分模块、分层次
- 数据持久化和低成本存储
作为一个数据库,数据不丢是最低的底线。许多单机和轻量级的向量数据库并没有关注数据的可靠性,Milvus 基于对象存储和消息队列的存储方案既通过存储计算分离提升了系统的弹性和扩展性,又保证了系统的可持久化性。更为重要的是,大多数 ANN 索引都是纯内存加载的,需要消耗大量内存才能执行检索。Milvus 是全球第一款支持磁盘索引的向量数据库,相比磁盘索引可以提供 10 倍以上的存储性价比。
- 高性能查询
查询性能是选择 ANN 而非 KNN 暴力搜索的核心需求。经过测试,市面上大量传统数据库向量检索插件其查询性能只有 Milvus 十分之一,且由于没有对索引进行分片,索引构造的时间和效率会随着数据量的增长大幅下降,因此只能适用于千万级数据量且不存在频繁增删的场景。
作为一个计算密集型应用,向量数据库的重要关注点在于充分压榨 CPU 算力,甚至利用异构算力实现加速。根据我们的内部测试结果,GPU 向量索引可以实现在千万数据集下万级别的 QPS,单机性能高于传统 CPU 索引一个数量级。向量数据库既是一个数据库,也是一个高性能计算系统,开发者需要拥有很强的 Hardware sympathy,这也是我认为我们需要 Purpose built 向量数据库的重要原因。
- 数据分布
传统数据库的分库分表分片往往基于主键或者分区键。对于传统数据库而言这种设置非常合理,原因是用户查询时往往给出确切的查询条件并路由到对应的分片。对于向量数据库而言,查询往往是找到全局与目标向量相似的向量,此时查询往往需要像 MPP 数据库一样在所有分区执行,算力需求随着数据量增长而增加。
向量原生数据库将向量作为一等公民,可以根据向量数据分布设置合理的分区策略,并充分利用数据分布信息设置查询策略来提升查询性能和查询精度。
- 易于使用
关于究竟什么是易用,不同的用户应该有自己的定义。向量数据库市场上,基于 GRPC 实现的多语言客户端,原生 Restful 接口和 SQL 接口都不乏拥簇。
见证了过去 10 年 NoSQL 到 NewSQL 的发展历程,我更愿意相信 SQL 这种表达能力更加丰富的查询语句才是最终的解决方案。除了基本的标量过滤,我们已经见到了用户对于聚合函数(Count,Groupby),函数和 Pagination 等传统数据库能力的需求。这也是我更看好基于 PG、Clickhouse 等进行魔改或者插件化实现的向量数据库的实现路径的一个原因。在对向量检索性能扩展性要求不高的场景下,这种实现方式的功能覆盖面更广,且与传统用户的使用心智更为接近。
与此同时,向量数据库的功能和数据模型必须贴近用户的应用场景。对于 AIGC 用户来讲,动态 Schema、多向量打分、标量向量混合打分、基于距离的范围查询这些查询能力都非常贴近业务场景,而这些场景并非简单的基于开源向量检索库就可以快速实现。
- 稳定可用
向量数据库是典型的 Big Data Serving 系统。一方面,向量数据库的写入来源于上游的推理系统,存在非常明显的离线和批量特性。另一方面,向量数据库很多应用场景面向在线查询,有严格的查询时延限制和高吞吐要求。在向量数据库的使用场景中,很多用户都要求单机故障能在分钟级恢复,同时也有越来越多的关键场景提出了主备容灾甚至跨机房容灾的需求。基于向量数据库的使用场景,传统基于 Raft/Paxos 的复制策略存在着资源浪费严重,数据预先分片困难等问题。Milvus 基于分布式存储和消息队列实现数据的可用性,基于 K8s 实现无状态故障恢复的无疑更省资源,故障恢复时间也更短。
向量数据库的稳定性另一个重要挑战是资源管理。传统数据库更加关注磁盘、网络等 IO 资源的调度管理,而向量数据库的核心瓶颈是计算和内存。Milvus 社区也有大量关于内存的管理和算力的调度的 PR,这些能力很难短期之内通过改造传统数据库或者在 Chroma 这种轻量级向量数据库中实现。
- 可运维可观测
想要成为一个企业级数据库,Milvus 不仅仅是提供软件,打包发布这么简单。Milvus 支持多种部署模式,例如 K8s Operator 和 Helm chart、docker compose、pip install 等,并提供了基于 grafana、prometheus 和 Loki 的监控报警体系。Zilliz 还开源了向量数据库可视化管理组件 Attu 以及向量数据库可视化工具 Feder,大大降低了向量数据库的管理难度,提升了向量检索的可解释程度。
得益于 Milvus 2.0 的分布式云原生架构,Milvus 也是业内首款支持多租户隔离、RBAC、Quota 限流、滚动升级的向量数据库。由于向量数据库计算、内存密集型的特性,传统数据库的隔离和限流能力很难在不做改造的情况下直接发挥作用。
- 智能化
Milvus 是一个 DB4AI 的系统,同时也是做了大量 AI4DB 的尝试。向量数据库与传统数据库的最大区别来源于对数据的返回准确度要求不同。传统数据库要求百分之百正确的返回结果,而向量数据库的 ANN 计算天生就属于近似匹配。通过 AI 改造向量数据库系统,其空间远远大于传统数据库进行调优或辅助问题排查。
基于 Milvus 打造的全托管企业级向量检索服务 Zilliz Cloud 创造性地提出了 AutoIndex,通过模型预测 recall 设置对应的查询参数,在大数据量下可以在 recall 几乎无损的情况实现 2-3 倍 的性能优化。不仅如此,量化技术,降维,ranking 等传统 AI 领域的技术也被广泛应用于向量数据库中,传统数据库开发者明显缺乏对这些技术的理解。
参考文档
尽管构建向量数据库的是一件复杂的工作,使用向量数据库却是一件如使用 numpy、Faiss 般简单的工作,即使对 AI 并不了解的同学也可以在十分钟内基于 Milvus 快速实现向量检索。想要体验高性能,强扩展性的向量检索服务,仅仅需要三步:
1)请先参考 Milvus 部署文档 https://milvus.io/docs/install_standalone-docker.md 部署 Milvus 服务。
2)参考 Hello Milvus 文档 https://milvus.io/docs/example_code.md,50 行代码即可实现向量检索功能。
3)查看 Towhee 的范例文档 https://github.com/towhee-io/examples/,了解向量数据库的应用场景,包括图片检索、知识增强、图文问答、视频去重等应用场景。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。