数据表设计
| id | parent_id | name | level |
|---|---|---|---|
| 1 | 0 | 食物 | 1 |
| 2 | 1 | 蔬菜 | 2 |
| 3 | 1 | 水果 | 2 |
| 4 | 2 | 茄果类 | 3 |
| 5 | 2 | 叶菜类 | 3 |
| 6 | 3 | 浆果类 | 3 |
| 7 | 3 | 瓜果类 | 3 |
| 8 | 4 | 番茄 | 4 |
| 9 | 4 | 辣椒 | 4 |
| 10 | 5 | 生菜 | 4 |
| 11 | 6 | 桑葚 | 4 |
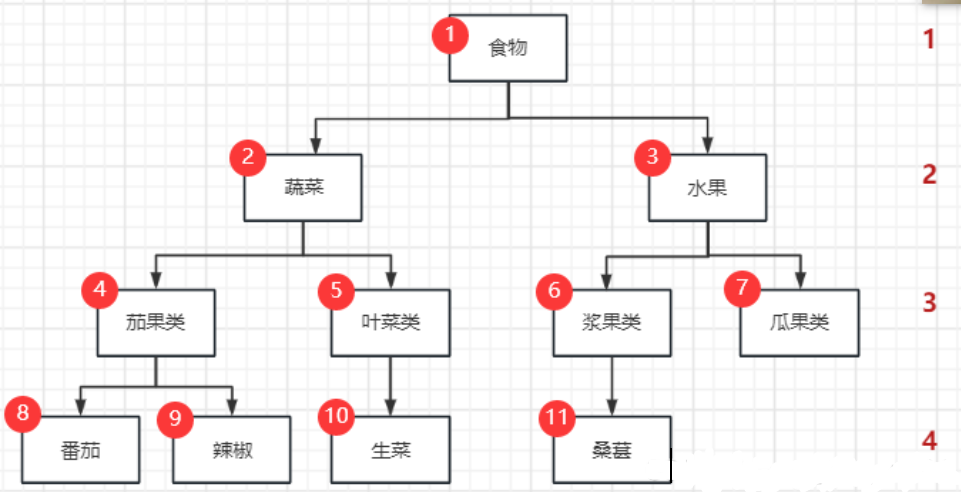
id:自增
parent_id:其父结点的id(如图,食物为根结点,所以没有parent_id,或为0)
level:树的深度
生成树(递归方式)
@Override
public List<CorpusTagsDTO> selectTagTree(String id) {
//在数据库中查询所有数据
List<Tags> trees = tagsMapper.selectList(new QueryWrapper<Tags>());
// 根节点默认为0,即第一层权限的pid为0
return getChildren(trees, id);
}
/**
* 递归查询pId的所有子树
*
* @param trees 全树列表
* @param pId 当前id
* @return 子树列表
*/
private List<CorpusTagsDTO> getChildren(List<Tags> trees, String pId) {
// 筛选出pId权限的子权限
List<Tags> childPrivs = trees.stream()
.filter(i -> i.getParentId().equals(pId)).collect(Collectors.toList());
// 转vo
List<CorpusTagsDTO> children = childPrivs.stream()
.map(i -> {
CorpusTagsDTO corpusTagsDTO = new CorpusTagsDTO();
corpusTagsDTO.setId(i.getId());
corpusTagsDTO.setParentId(i.getParentId());
corpusTagsDTO.setName(i.getName());
corpusTagsDTO.setLevel(i.getLevel());
return corpusTagsDTO;
}).collect(Collectors.toList());
// 退出递归条件,无子权限
if (children.isEmpty()) {
return null;
}
// 遍历当前所有子权限
for (CorpusTagsDTO i : children) {
// 开始递归查询
i.setChildren(getChildren(trees, i.getId()));
}
return children;
}
CorpusTagsDTO
@Data
public class CorpusTagsDTO {
/** 结点ID */
private String id;
/** 父ID */
private String parentId;
/** 结点名称 */
private String name;
/** 深度*/
private Integer level;
/** 子结点 */
private List<CorpusTagsDTO> children;
}
根据节点cId返回所有的父节点pId
public String[] selectParent(String cId) {
//在数据库中查询
List<Tags> trees = tagsMapper.selectList(new QueryWrapper<Tags>());
// 根节点默认为0,即第一层权限的pid为0
return getParents(trees,cId);
}
/**
* 根据子节点查找父节点
* @param trees
* @param cId 子节点
* @return java.lang.String[]
*/
public String[] getParents(List<Tags> trees,String cId) {
Map<String, String> collect= trees.stream().collect(
Collectors.toMap(
Tags::getId,
it -> (it.getParentId() == "0") ? it.getId() : it.getParentId(),
(v1, v2) -> v2
)
);
Set<String> resSet = new HashSet<>();
//找父节点
findParent(resSet, collect, cId);
String a[]=resSet.stream()
.map(String::valueOf).sorted()
.toArray(String[]::new);
System.out.println(a);//["12","1201","12011"]
return a;
}
/**
* 路径压缩,查询父节点
* @param orgSet
* @param orgMap
* @param cId 子节点
*/
private void findParent(Set<String> orgSet, Map<String,String > orgMap , String cId) {
if (ObjectUtil.isNotNull(cId)){
while (!cId.equals(orgMap.get(cId))) {
//如果不加一下判断的话,如果orgMap.get(cId))为空时(当部门有父级Id,但是父级部门又不存在数据库时),会进入死循环
if (ObjectUtil.isNotNull(orgMap.get(cId))){
orgSet.add(cId);
String parent = orgMap.get(cId);
if (ObjectUtil.isNotNull(parent)) {
orgMap.put(cId, orgMap.get(parent));
cId = parent;
}
orgSet.add(cId);
}else {
//若cId为空时则移除,当父级pId存在,但是却没有父级部门信息时,应移除pId
orgSet.remove(cId);
break;
}
}
}
}