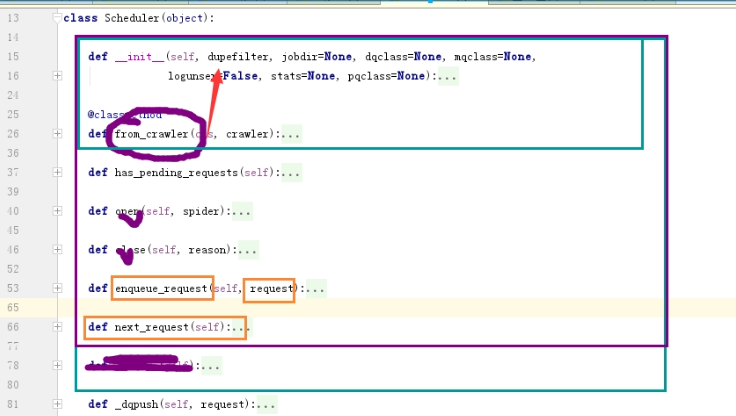
部分配置文件详解:
1 # -*- coding: utf-8 -*- 2 3 # Scrapy settings for test001 project 4 # 5 # For simplicity, this file contains only settings considered important or 6 # commonly used. You can find more settings consulting the documentation: 7 # 8 # https://doc.scrapy.org/en/latest/topics/settings.html 9 # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html 10 # https://doc.scrapy.org/en/latest/topics/spider-middleware.html 11 12 # 爬虫名字 13 BOT_NAME = 'test001' 14 15 # 爬虫应用路径 16 SPIDER_MODULES = ['test001.spiders'] 17 NEWSPIDER_MODULE = 'test001.spiders' 18 19 20 # Crawl responsibly by identifying yourself (and your website) on the user-agent 21 # 客户端user-agent请求头 22 #USER_AGENT = 'test001 (+http://www.yourdomain.com)' 23 # 正常浏览器访问 24 #user-agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36 25 26 # 遵守目标网站的爬虫规则 27 # Obey robots.txt rules 28 ROBOTSTXT_OBEY = False 29 30 # 并发请求最大数 31 # Configure maximum concurrent requests performed by Scrapy (default: 16) #默认16个 32 #CONCURRENT_REQUESTS = 32 33 34 # Configure a delay for requests for the same website (default: 0) 35 # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay 36 # See also autothrottle settings and docs 37 # 设置延迟下载时间,单位秒 38 # DOWNLOAD_DELAY = 3 39 40 41 # The download delay setting will honor only one of: 42 # 单域名访问并发数,并且延迟下次秒数也应用在每个域名 43 #CONCURRENT_REQUESTS_PER_DOMAIN = 16 44 # 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP 45 #CONCURRENT_REQUESTS_PER_IP = 16 46 47 # Disable cookies (enabled by default) 48 # 是否支持cookie,cookiejar进行操作cookie 49 #COOKIES_ENABLED = False #response返回,是否携带(拿)cookies 50 #COOKIES_DEBUG = True #输入命令运行时,每次请求都将cookie打印出来 51 52 # Disable Telnet Console (enabled by default) 53 #Telnet用于查看当前爬虫的信息,操作爬虫等... 54 #TELNETCONSOLE_ENABLED = True #Telnet用于查看当前爬虫的信息,操作爬虫等... 55 #TELNETCONSOLE_HOST = '127.0.0.1' 56 #TELNETCONSOLE_PORT = [6023,] 57 #打开命令行,开启Telnet功能,然后使用telnet ip port ,然后通过命令操作 58 59 # 默认请求头 60 # Override the default request headers: 61 #DEFAULT_REQUEST_HEADERS = { 62 # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 63 # 'Accept-Language': 'en', 64 #} 65 66 67 # 自定义扩展,基于信号进行调用 68 from scrapy.extensions.telnet import TelnetConsole #默认调用扩展 69 # Enable or disable extensions 70 # See https://doc.scrapy.org/en/latest/topics/extensions.html 71 # EXTENSIONS = { 72 # # 'scrapy.extensions.telnet.TelnetConsole': None, 73 # 'test001.extensions.MyExtend':300, 74 # } 75 76 # Configure item pipelines 77 # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html 78 # 自定义pipeline处理请求 79 ITEM_PIPELINES = { 80 'test001.pipelines.Test001Pipeline': 200, #值越小,优先级越高 81 'test001.pipelines.Test001Pipeline2': 300, 82 # 'test001.pipelines.Test001Pipeline3': 500, 83 84 } 85 86 # 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度,用作Request请求递归。 87 DEPTH_LIMIT = 3 88 89 # 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo 90 # DEPTH_PRIORITY = 0 #0 or 1 深度优先(递归实现)和广度优先(队列实现)、 91 # 详细可参考:http://www.cnblogs.com/cjj-zyj/p/10036771.html 92 # 后进先出,深度优先 93 # DEPTH_PRIORITY = 0 94 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue' 95 # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue' 96 97 # 先进先出,广度优先 98 # DEPTH_PRIORITY = 1 99 # SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue' 100 # SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue' 101 102 103 #访问url去重处理 104 # DUPEFILTER_CLASS = "test001.duplication.RepeatFilter" 105 106 #自定义数据库或文件名(需大写) 107 # DB = "data.log" 108 109 # 调度器队列 110 SCHEDULER = 'scrapy.core.scheduler.Scheduler' 111 from scrapy.core.scheduler import Scheduler #查看源码 112 # class Scheduler(object): 113 # 114 # def __init__(self, dupefilter, jobdir=None, dqclass=None, mqclass=None, 115 # logunser=False, stats=None, pqclass=None): 116 # self.df = dupefilter 117 # self.dqdir = self._dqdir(jobdir) 118 # self.pqclass = pqclass 119 # self.dqclass = dqclass 120 # self.mqclass = mqclass 121 # self.logunser = logunser 122 # self.stats = stats 123 # 124 # @classmethod 125 # def from_crawler(cls, crawler): 126 # settings = crawler.settings 127 # dupefilter_cls = load_object(settings['DUPEFILTER_CLASS']) 128 # dupefilter = dupefilter_cls.from_settings(settings) 129 # pqclass = load_object(settings['SCHEDULER_PRIORITY_QUEUE']) 130 # dqclass = load_object(settings['SCHEDULER_DISK_QUEUE']) 131 # mqclass = load_object(settings['SCHEDULER_MEMORY_QUEUE']) 132 # logunser = settings.getbool('LOG_UNSERIALIZABLE_REQUESTS', settings.getbool('SCHEDULER_DEBUG')) 133 # return cls(dupefilter, jobdir=job_dir(settings), logunser=logunser, 134 # stats=crawler.stats, pqclass=pqclass, dqclass=dqclass, mqclass=mqclass) 135 # 136 # def has_pending_requests(self): 137 # return len(self) > 0 138 # 139 # def open(self, spider): 140 # self.spider = spider 141 # self.mqs = self.pqclass(self._newmq) 142 # self.dqs = self._dq() if self.dqdir else None 143 # return self.df.open() 144 # 145 # def close(self, reason): 146 # if self.dqs: 147 # prios = self.dqs.close() 148 # with open(join(self.dqdir, 'active.json'), 'w') as f: 149 # json.dump(prios, f) 150 # return self.df.close(reason) 151 # 152 # def enqueue_request(self, request): 153 # if not request.dont_filter and self.df.request_seen(request): 154 # self.df.log(request, self.spider) 155 # return False 156 # dqok = self._dqpush(request) 157 # if dqok: 158 # self.stats.inc_value('scheduler/enqueued/disk', spider=self.spider) 159 # else: 160 # self._mqpush(request) 161 # self.stats.inc_value('scheduler/enqueued/memory', spider=self.spider) 162 # self.stats.inc_value('scheduler/enqueued', spider=self.spider) 163 # return True 164 # 165 # def next_request(self): 166 # request = self.mqs.pop() 167 # if request: 168 # self.stats.inc_value('scheduler/dequeued/memory', spider=self.spider) 169 # else: 170 # request = self._dqpop() 171 # if request: 172 # self.stats.inc_value('scheduler/dequeued/disk', spider=self.spider) 173 # if request: 174 # self.stats.inc_value('scheduler/dequeued', spider=self.spider) 175 # return request
Telnet补充:

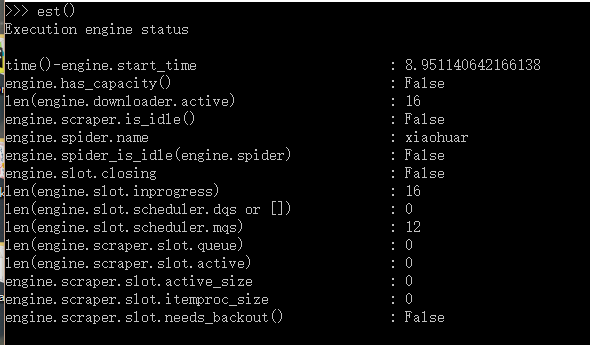
命令列表:
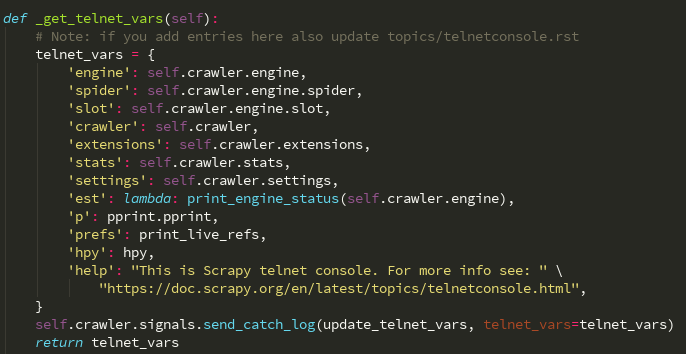
调度器: