一、 使用Grafana实现监控指标可视化
1.1使用helm安装grafana
helm pull bitnami/grafana --untar修改values.yaml
vi grafana/values.yaml ##定义storageClass
storageClass: "nfs-client" #两个安装grafana
cd grafana
helm install grafana .执行结果
# helm install grafana .
NAME: grafana
LAST DEPLOYED: Thu Nov 2 20:42:19 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: grafana
CHART VERSION: 9.4.1
APP VERSION: 10.2.0
** Please be patient while the chart is being deployed **
1. Get the application URL by running these commands:
echo "Browse to http://127.0.0.1:8080"
kubectl port-forward svc/grafana 8080:3000 &
2. Get the admin credentials:
echo "User: admin"
echo "Password: $(kubectl get secret grafana-admin --namespace default -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 -d)"使用port-forward 做端口映射
kubectl port-forward svc/grafana --address 192.168.1.230 8087:3000 &查看密码
echo "Password: $(kubectl get secret grafana-admin --namespace default -o jsonpath="{.data.GF_SECURITY_ADMIN_PASSWORD}" | base64 -d)"
Password: 5VN9dacuKR1.2 访问grafana
http://192.168.1.230:8087/login
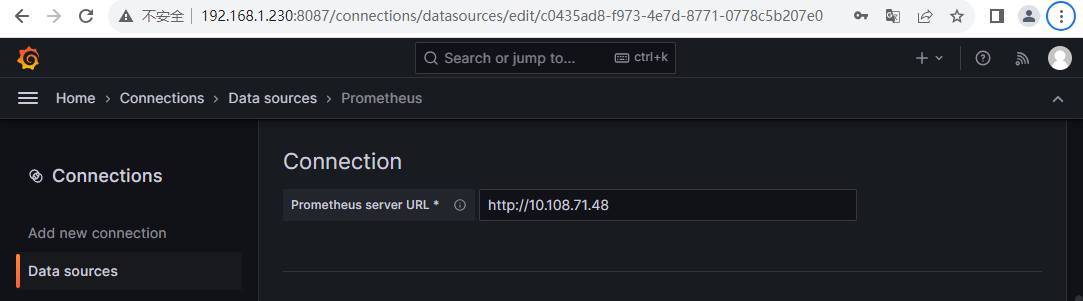
添加数据源

1.3 导入node模板
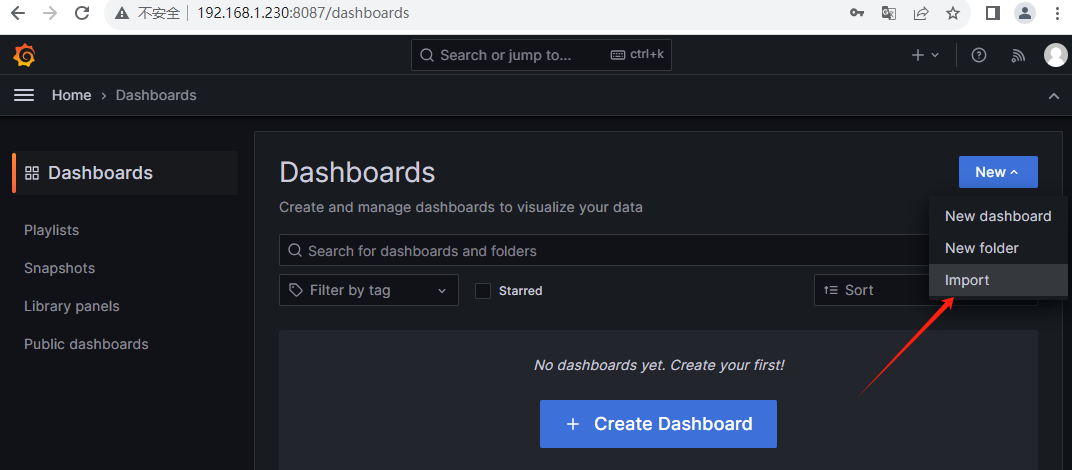
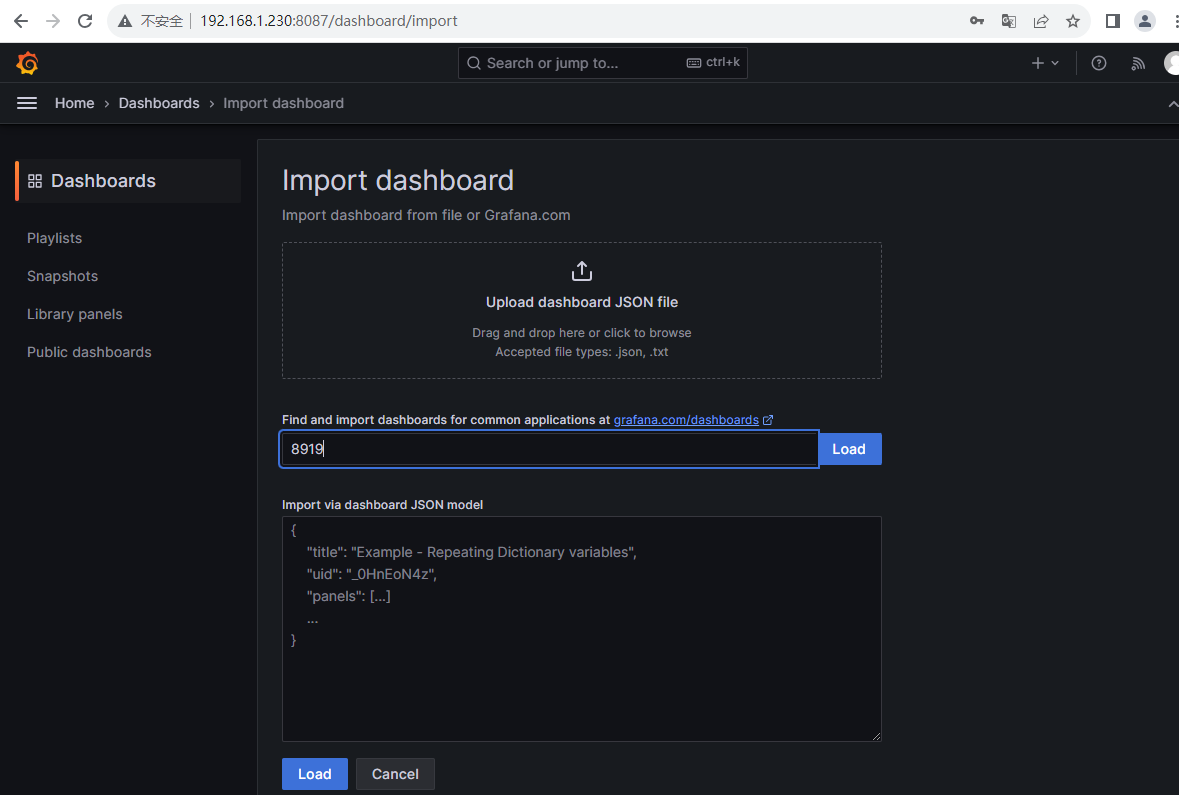
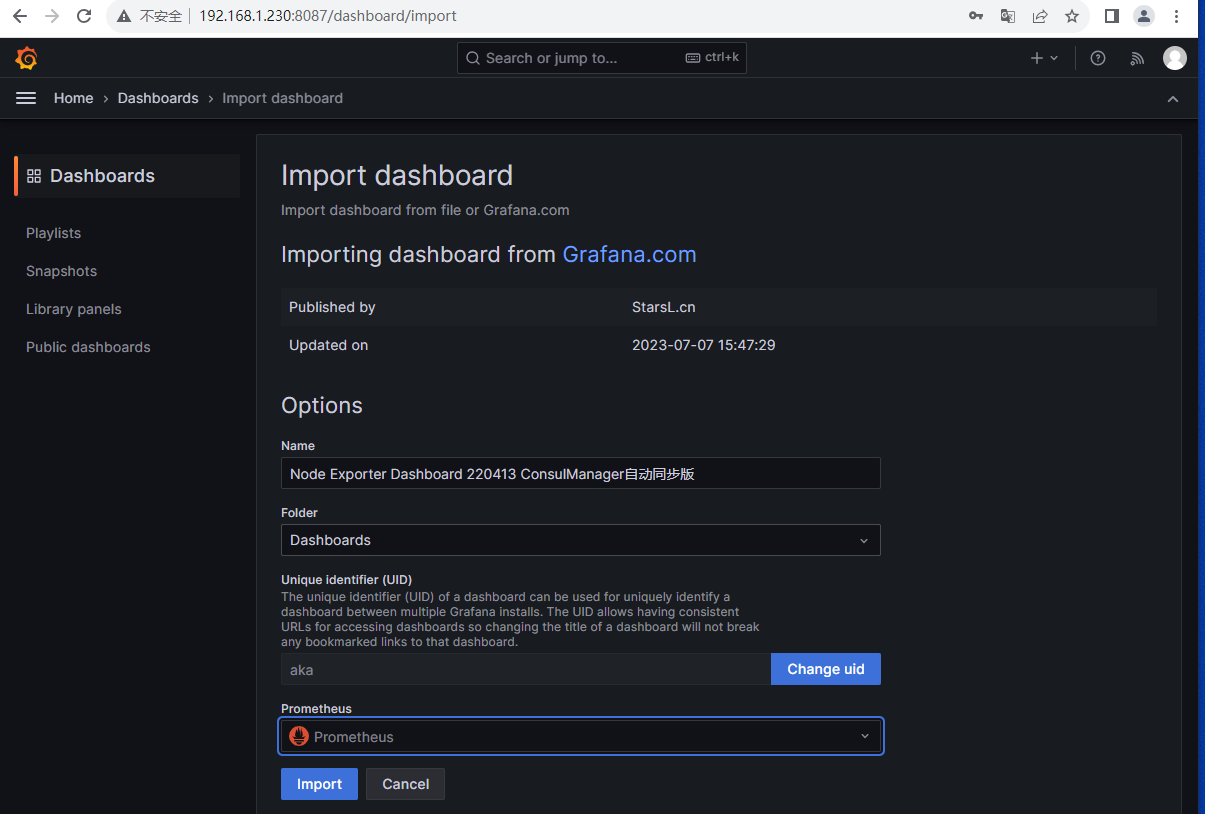
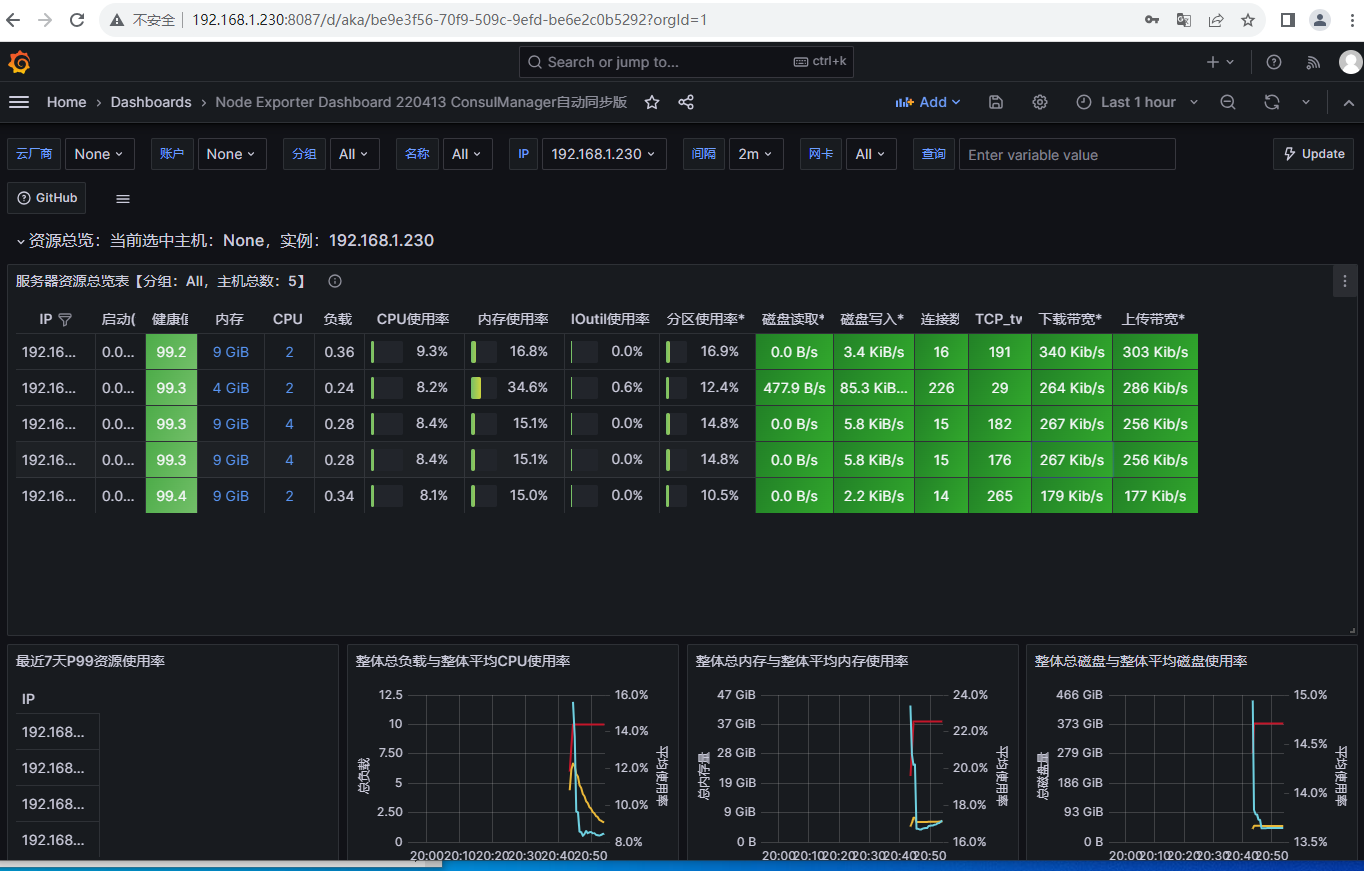
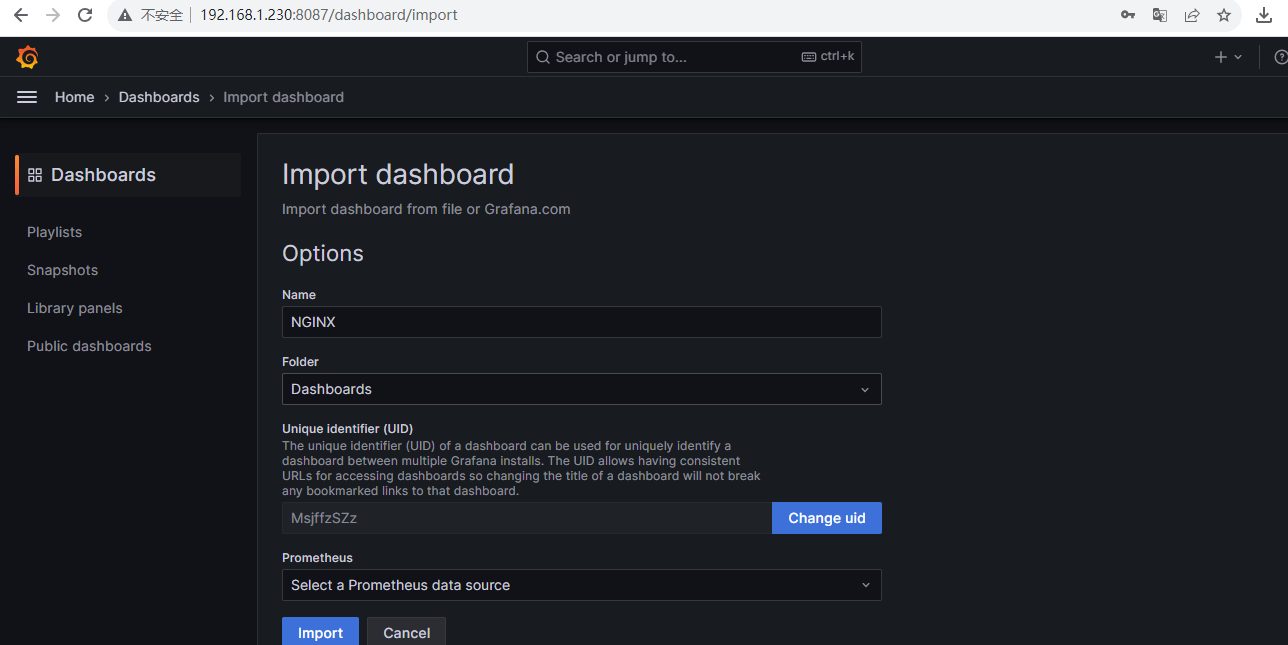
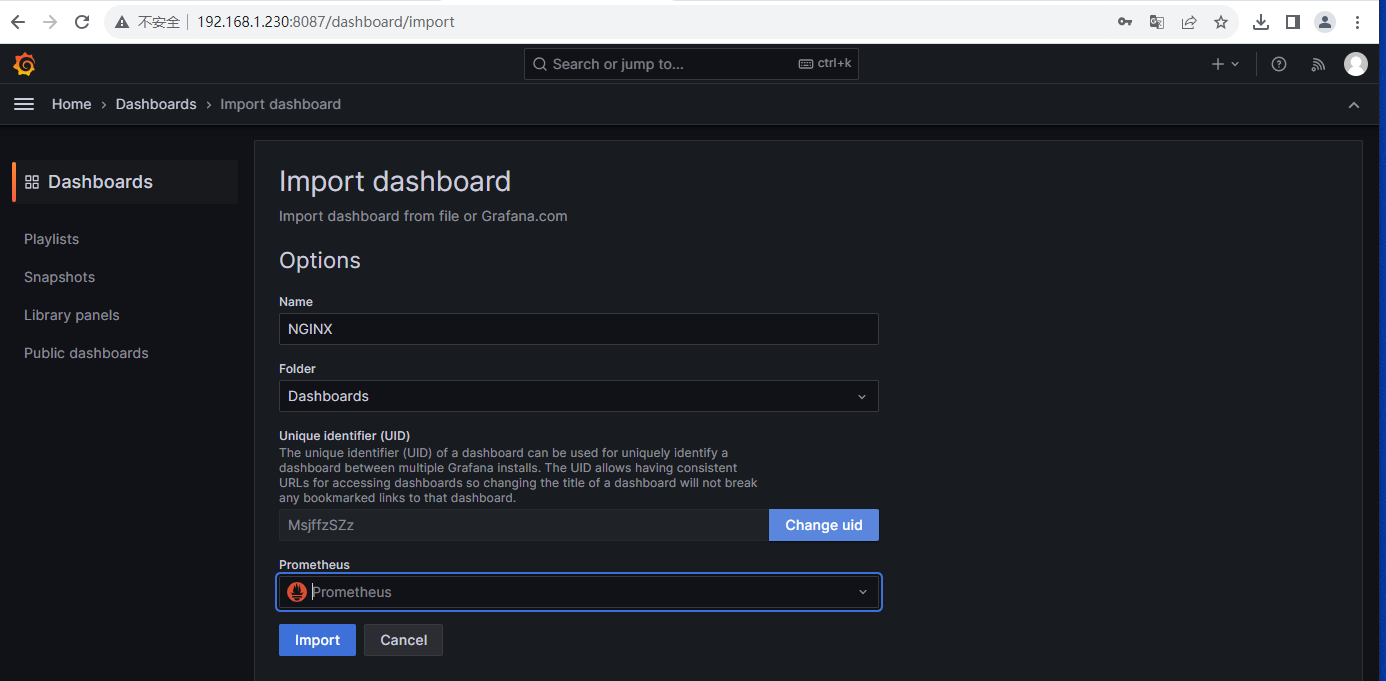
1.4 导入Nginx 模板
下载Nginx模板dashboard.json,访问URL:https://github.com/nginxinc/nginx-prometheus-exporter/blob/main/grafana/dashboard.json
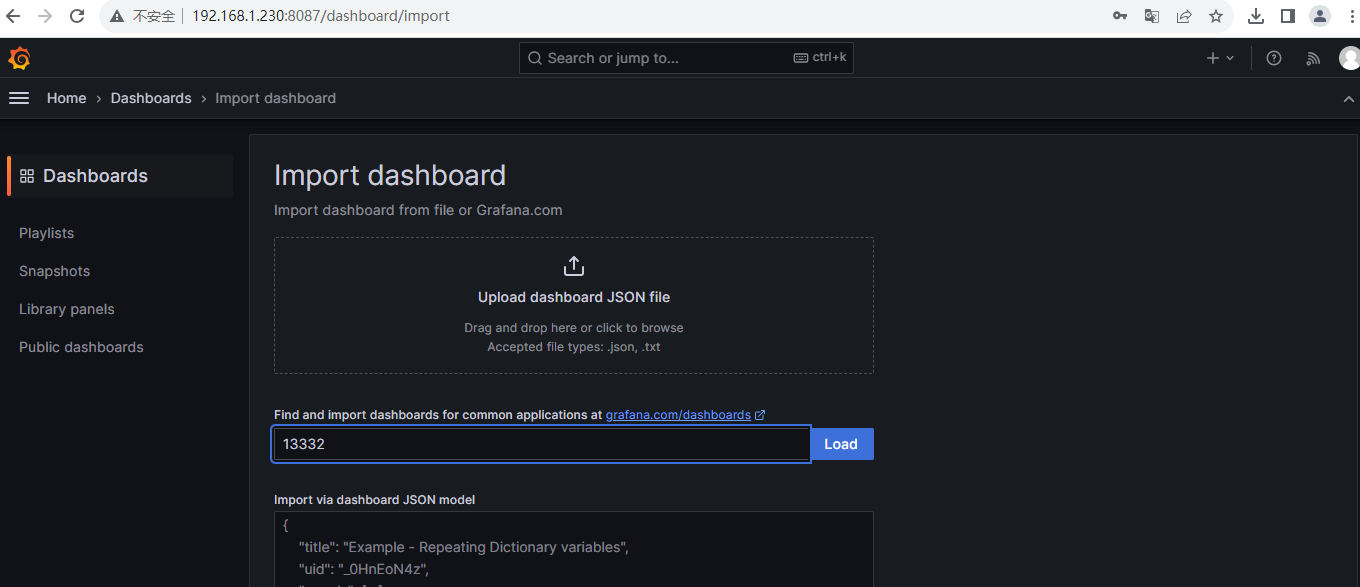
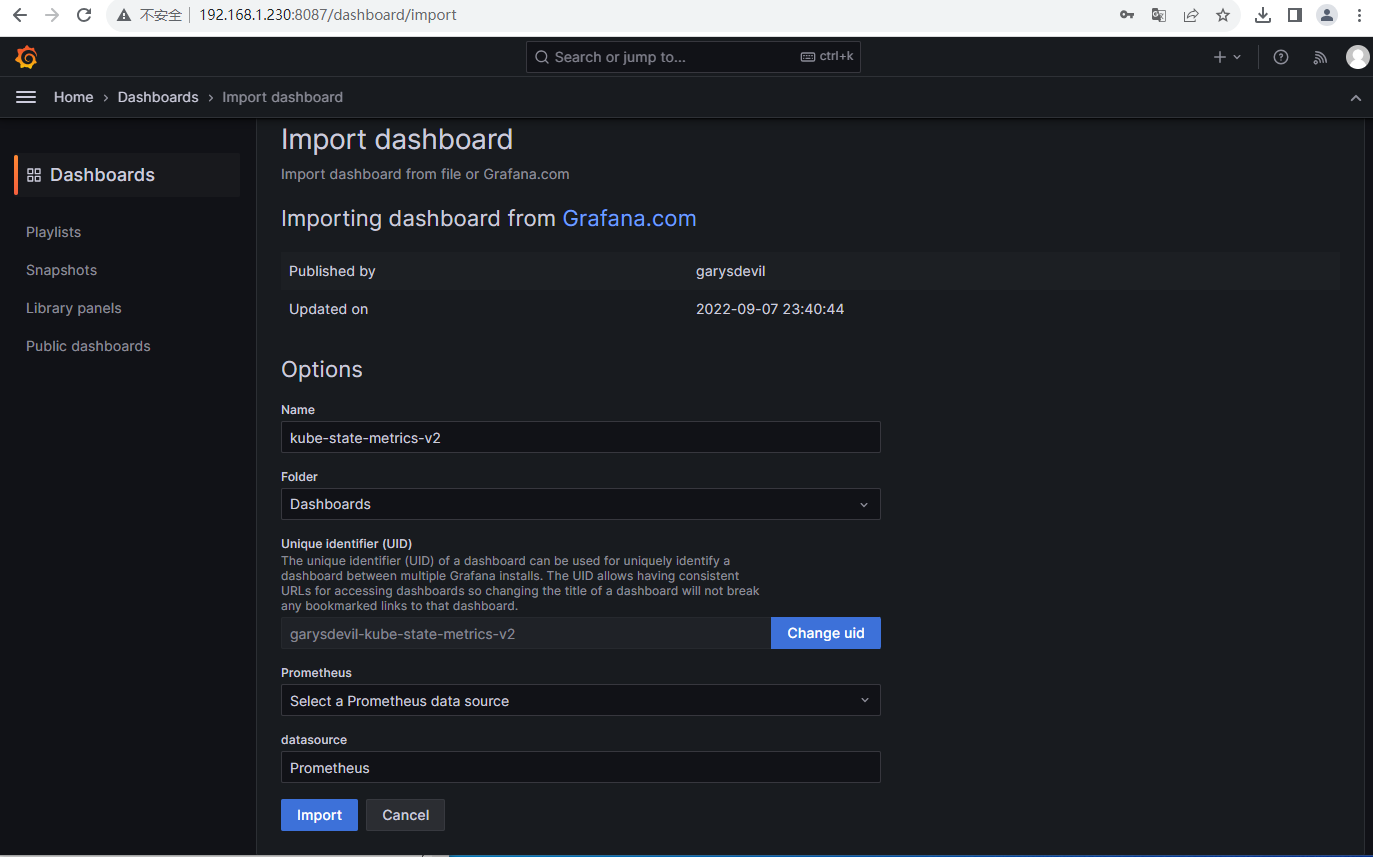
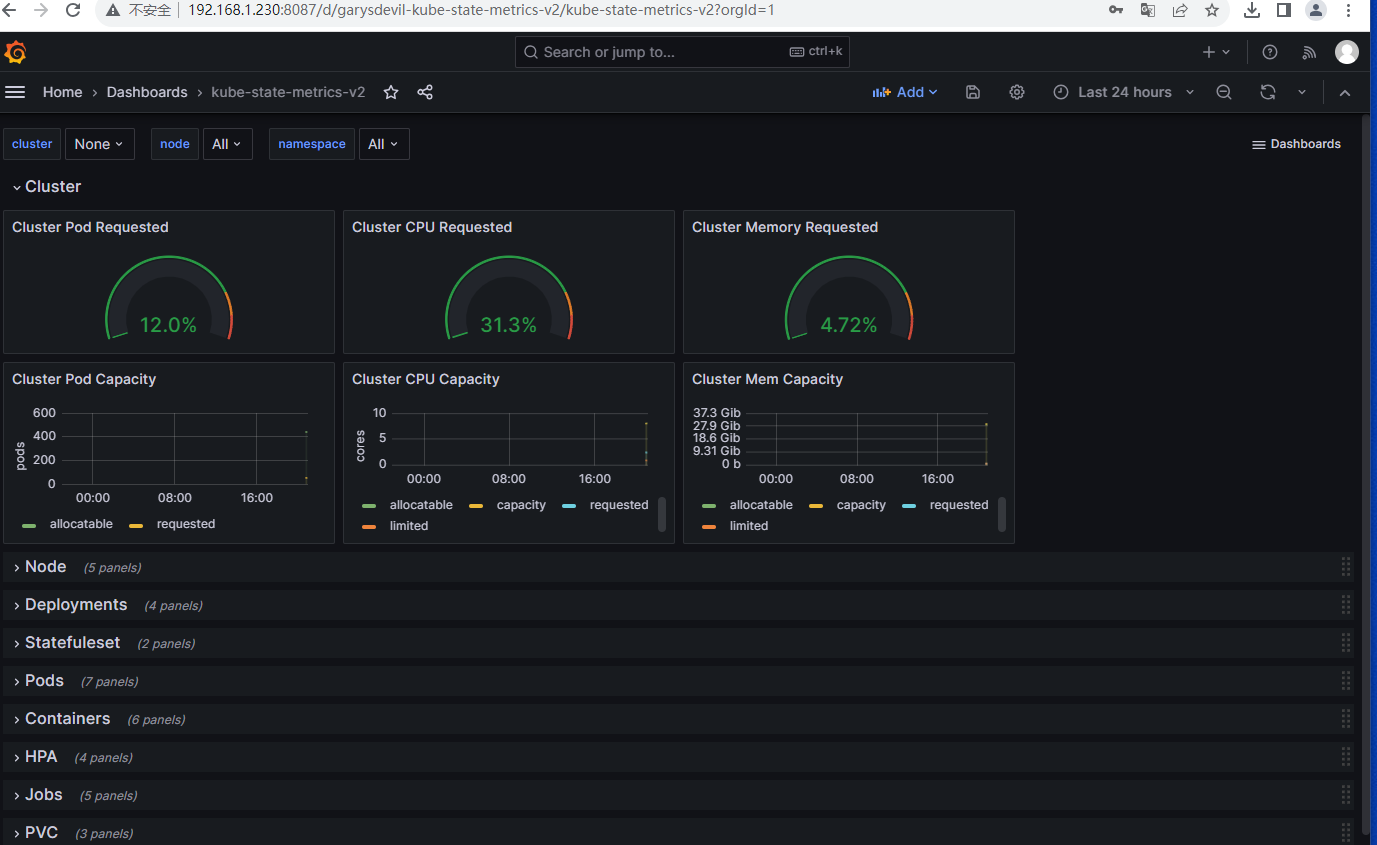
1.5 导入kube-state-metrics dashboard 模板
模板id:13332
二、 AlertManager介绍和安装
2.1 使用helm安装Prometheus,已经安装了Alertmanager
查看service
# kubectl get svc |grep alertm
prometheus-alertmanager LoadBalancer 10.111.175.233 <pending> 80:31222/TCP 3d22h访问Alertmanager
三、 配置Prometheus告警规则
3.1 vim prometheus_config.yaml
kubectl get cm prometheus-server -o yaml > prometheus_config.yaml
找到rules.yaml,将 rules.yaml: '{}' 改为
rules.yaml: |
groups:
- name: hostStatsAlert
rules:
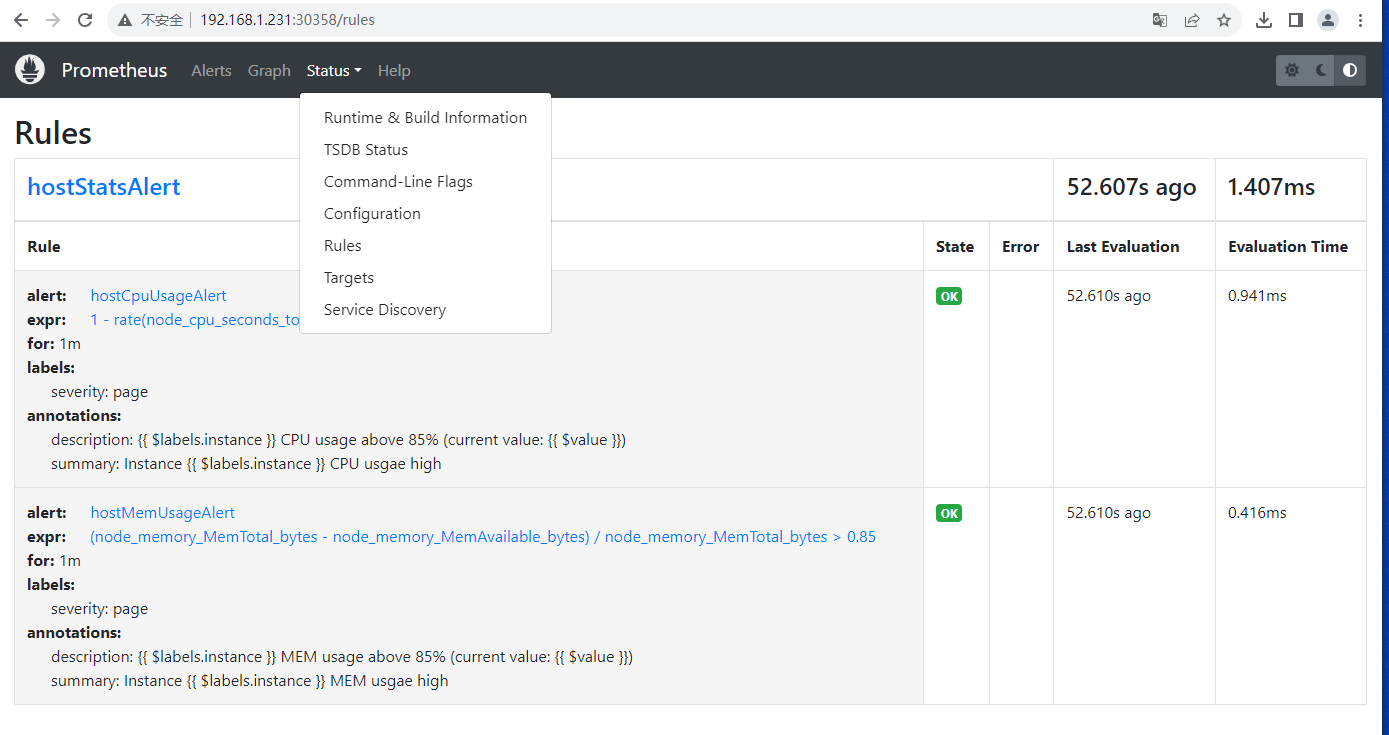
- alert: hostCpuUsageAlert
expr: 1 - rate(node_cpu_seconds_total{mode="idle"}[2m]) > 0.8
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.85
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"重新apply yaml文件
# kubectl delete cm prometheus-server; kubectl apply -f prometheus_config.yaml
configmap "prometheus-server" deleted
configmap/prometheus-server created重启prometheus服务
# kubectl get po |grep prometheus-server |awk '{print $1}' |xargs -i kubectl delete po {}
pod "prometheus-server-78b4b8bf58-8snjt" deleted查看rule配置是否生效
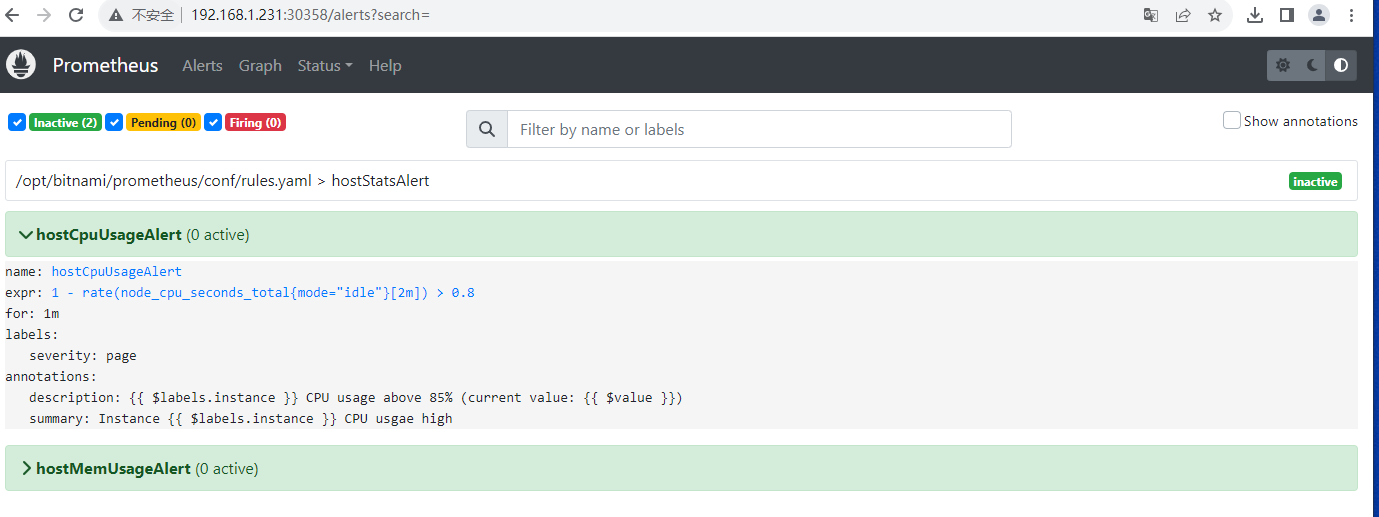
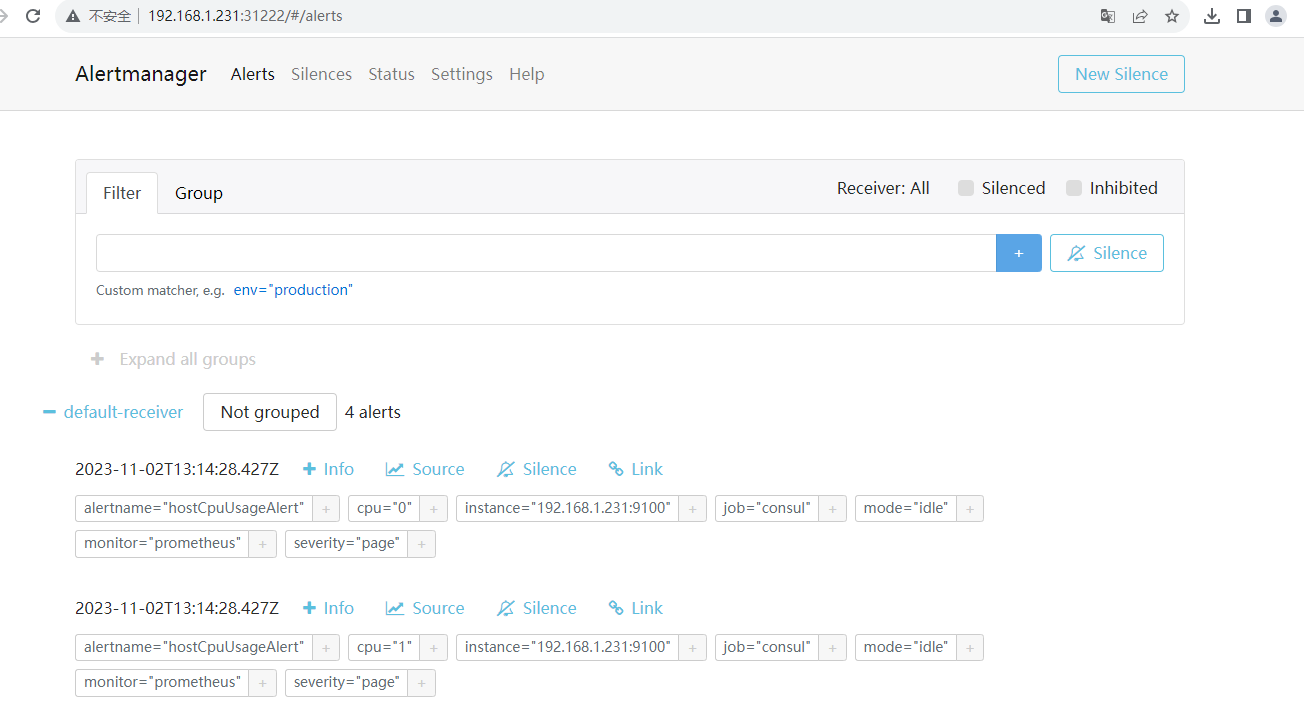
查看Alerts
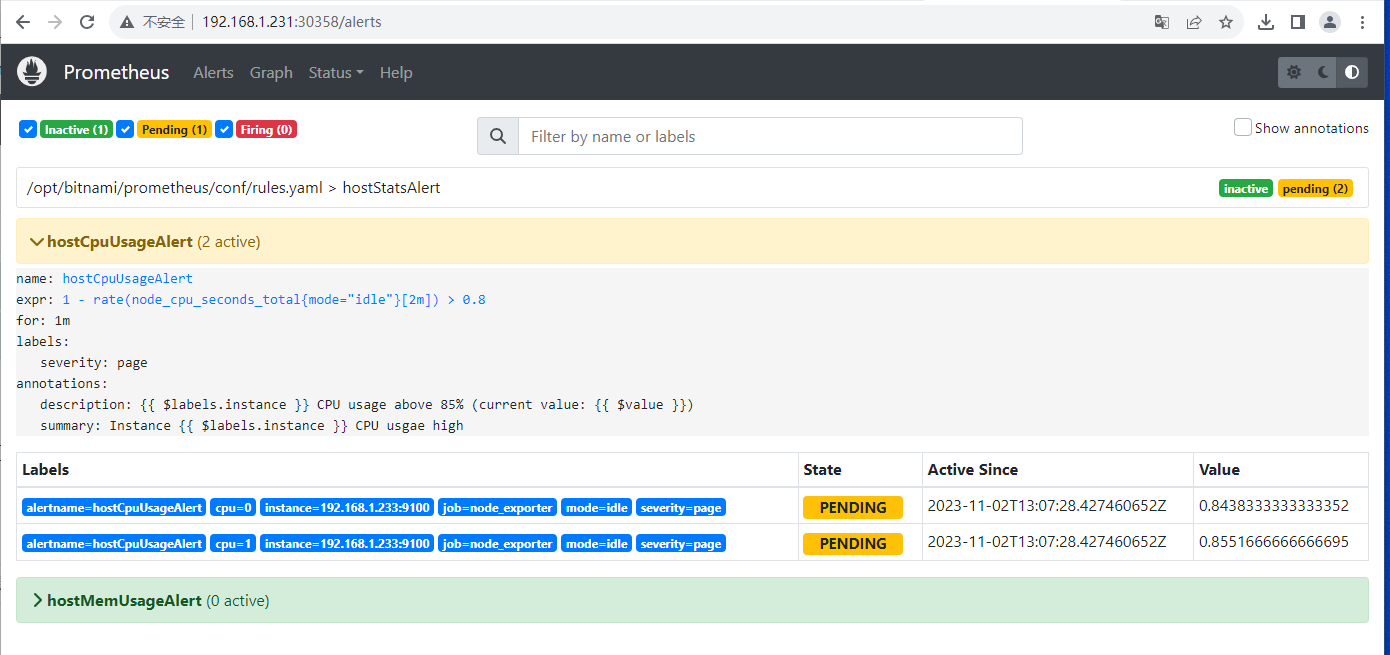
Alertmanager 三种状态
- Inactive:规则还没有触发
- Pending:规则被触发,在评估等待时间范围内
- Firing:规则被触发,超过评估等待时间
测试规则,在node-1-231执行:
cat /dev/zero > /dev/null & #如果你cpu为2核,则需要执行两次,这样才能保证cpu使用率增高到阈值 观察Prometheus alerts页面cpu项状态变化
在Alertmanager查看告警记录
四、 AlertManager配置邮件告警
4.1 将Alertmanager的配置文件导出到yaml
kubectl get cm prometheus-alertmanager -o=yaml > alertmanager_config.yaml4.2 编辑配置文件
vi alertmanager_config.yaml
# cat alertmanager_config.yaml
apiVersion: v1
data:
alertmanager.yaml: |
global:
resolve_timeout: 1h
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'yzj2516@163.com'
smtp_auth_username: 'yzj2516@163.com'
smtp_auth_password: '123456'
smtp_require_tls: false
templates:
- '/bitnami/alertmanager/data/template/email.tmpl'
receivers:
- name: 'default-receiver'
email_configs:
- to: 'yzj2516@163.com'
html: '{{ template "email.html" . }}'
send_resolved: true
route:
group_wait: 10s
group_interval: 5m
receiver: default-receiver
repeat_interval: 3h
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: prometheus
meta.helm.sh/release-namespace: default
creationTimestamp: "2023-10-29T14:45:16Z"
labels:
app.kubernetes.io/component: alertmanager
app.kubernetes.io/instance: prometheus
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: prometheus
app.kubernetes.io/version: 0.26.0
helm.sh/chart: prometheus-0.3.6
name: prometheus-alertmanager
namespace: default
resourceVersion: "529418"
uid: cb2991b5-b562-4fcc-ab0e-8281e0998d55重新apply 配置
# kubectl delete cm prometheus-alertmanager; kubectl apply -f alertmanager_config.yaml
configmap "prometheus-alertmanager" deleted
configmap/prometheus-alertmanager created由于Alertmanager有挂载到nfs,所以/bitnami/alertmanager/data/目录对应到nfs里,在NFS服务端操作
[root@master-1-230 default-data-prometheus-alertmanager-0-pvc-de11fad4-d401-4b66-9fa0-cec7ef38cfe5]# pwd
/data/nfs/default-data-prometheus-alertmanager-0-pvc-de11fad4-d401-4b66-9fa0-cec7ef38cfe5
[root@master-1-230 default-data-prometheus-alertmanager-0-pvc-de11fad4-d401-4b66-9fa0-cec7ef38cfe5]# mkdir template
[root@master-1-230 default-data-prometheus-alertmanager-0-pvc-de11fad4-d401-4b66-9fa0-cec7ef38cfe5]# vim template/email.tmpl
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
<pre>
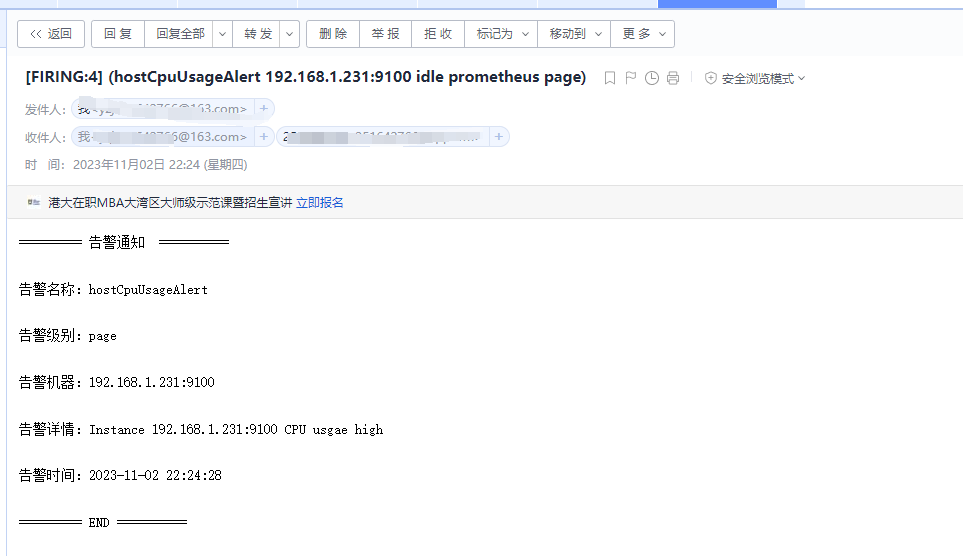
========= 告警通知 ========== <br>
告警名称:{{ .Labels.alertname }} <br>
告警级别:{{ .Labels.severity }} <br>
告警机器:{{ .Labels.instance }} {{ .Labels.device }} <br>
告警详情:{{ .Annotations.summary }} <br>
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
========= END ========== <br>
</pre>
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
<pre>
========= 恢复通知 ========== <br>
告警名称:{{ .Labels.alertname }} <br>
告警级别:{{ .Labels.severity }} <br>
告警机器:{{ .Labels.instance }} <br>
告警详情:{{ .Annotations.summary }} <br>
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
恢复时间:{{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
========= END ========== <br>
</pre>
{{- end }}
{{- end }}
{{- end }}4.3 重启Alertmanager服务
kubectl get po |grep 'prometheus-alertmanager'|awk '{print $1}' |xargs -i kubectl delete po {}
pod "prometheus-alertmanager-0" deleted4.4 模拟cup实用率增加,触发告警。查看是否收到邮件告警
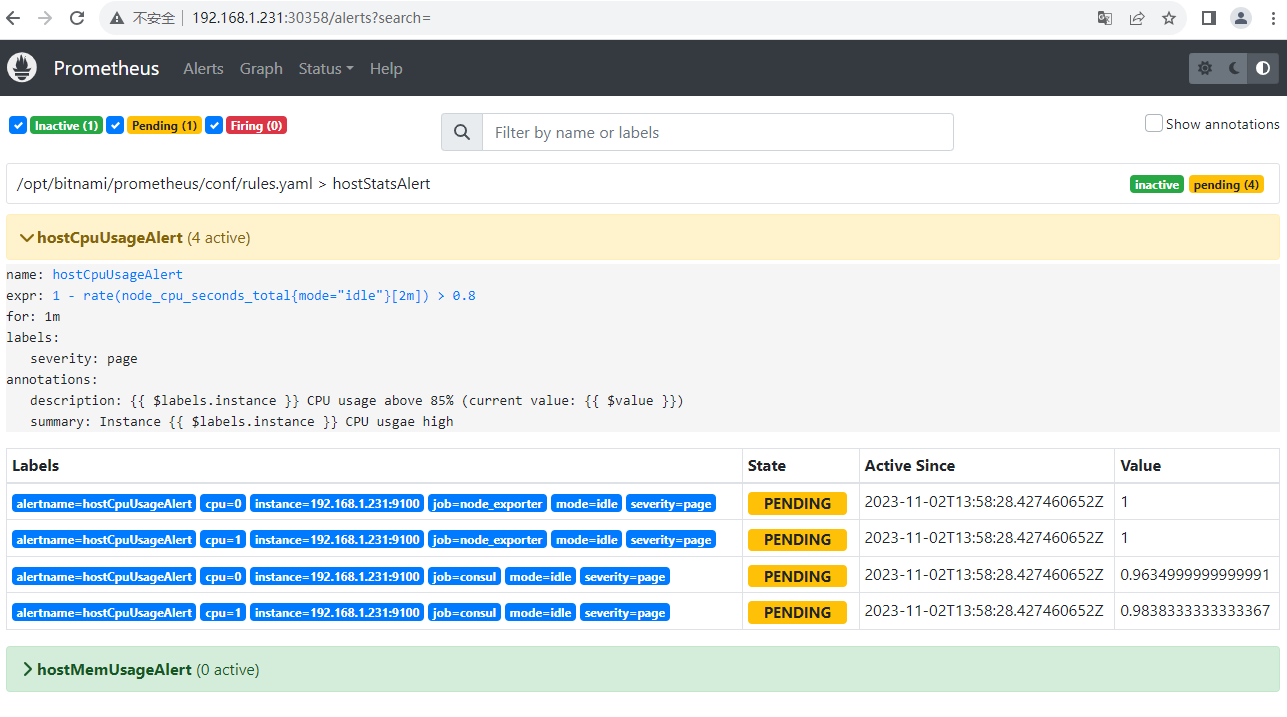
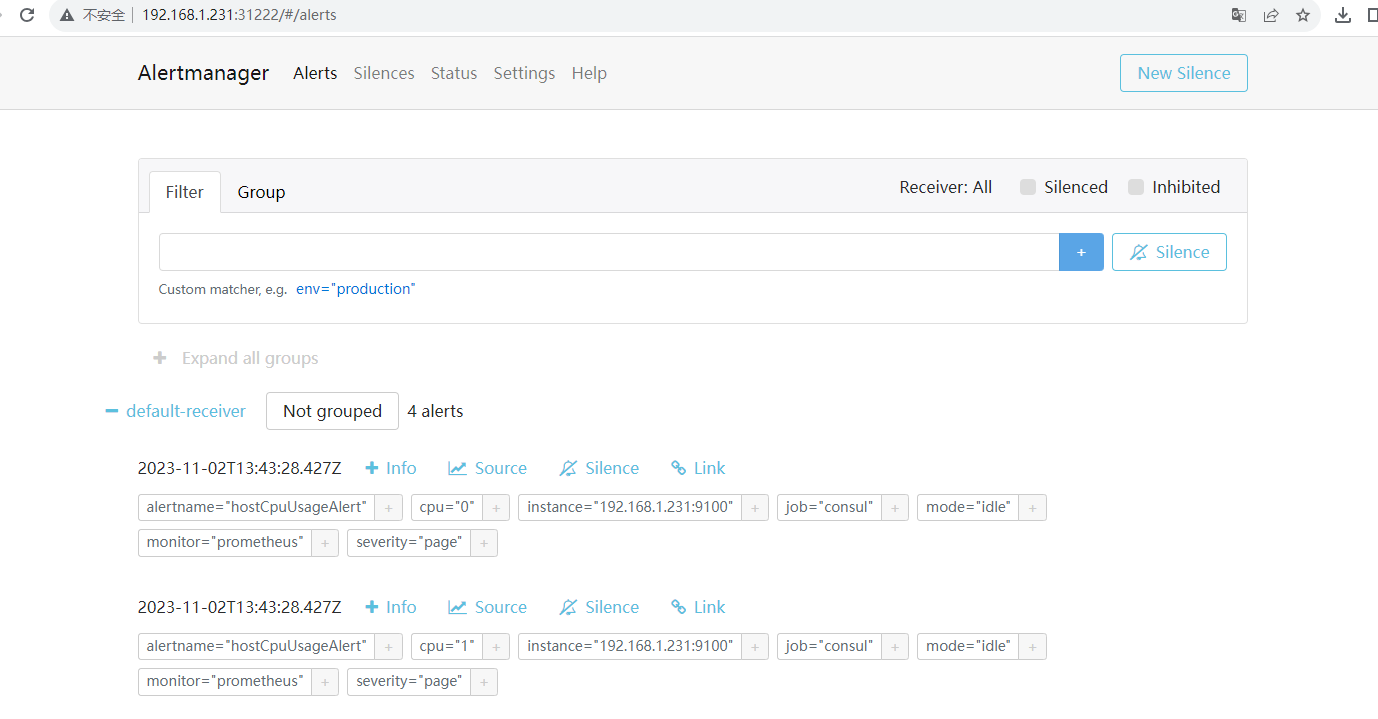
五、 AlertManager配置企业微信告警
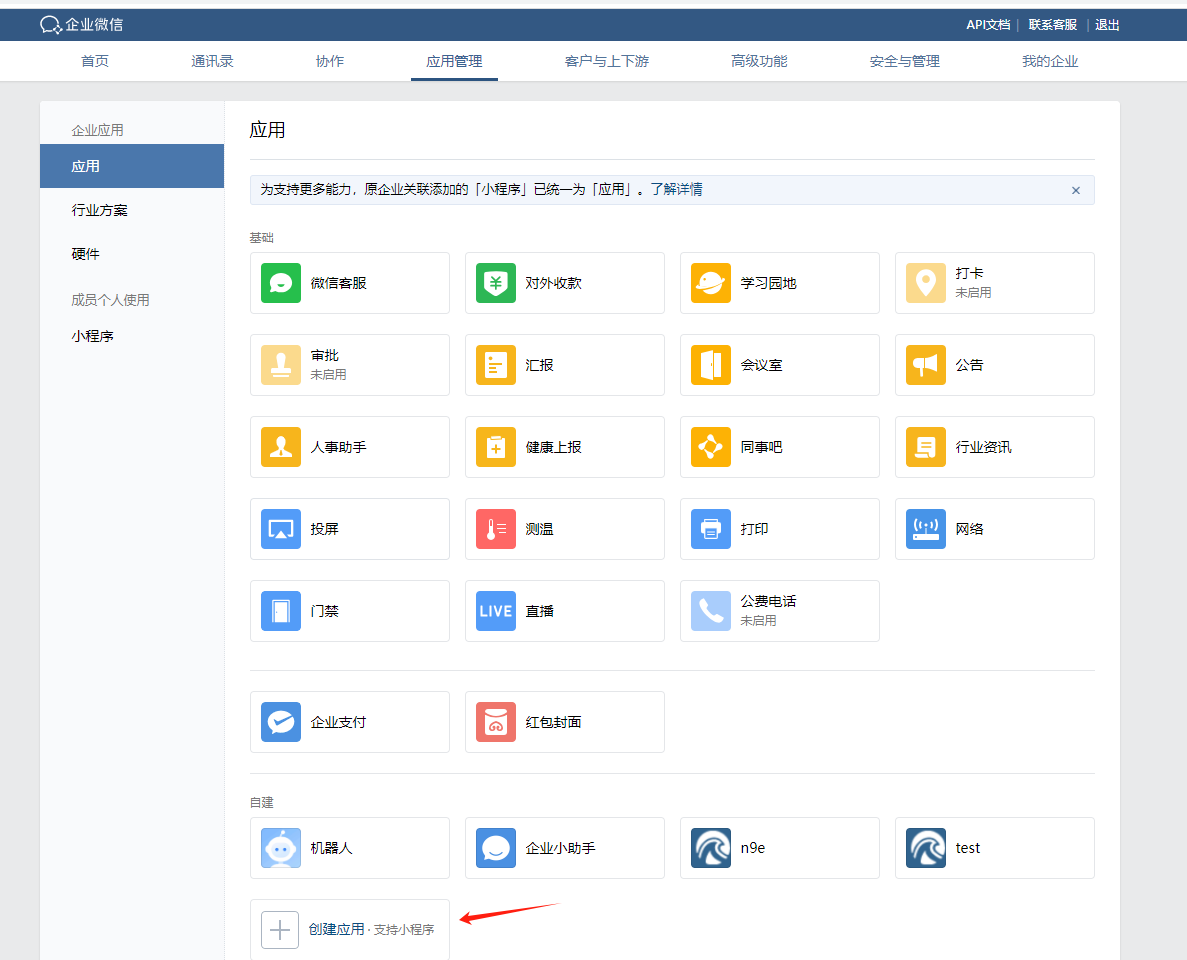
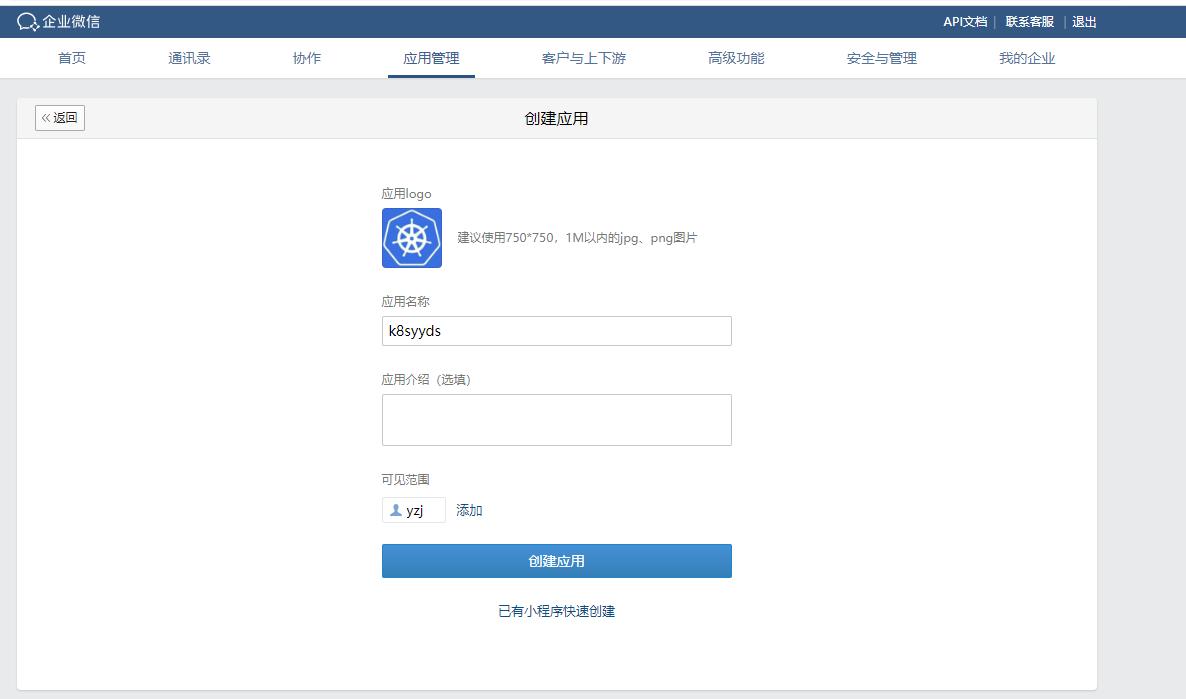
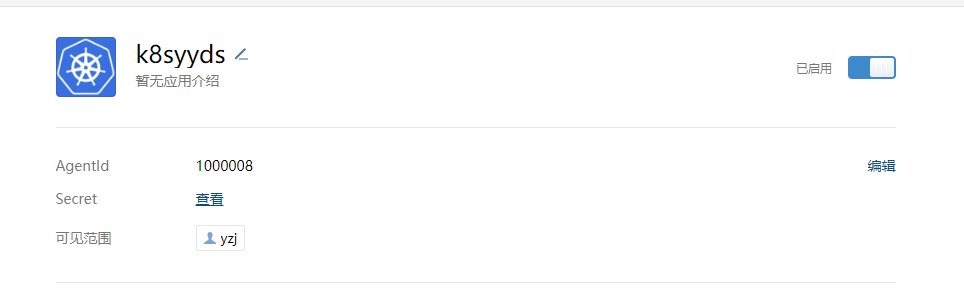
在企业微信创建新应用,应用名称为:“k8syyds”


vim alertmanager_config.yaml
apiVersion: v1
data:
alertmanager.yaml: |
global:
resolve_timeout: 5m
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_corp_id: 'wxa56e78f3d93f0ec6'
templates:
- '/bitnami/alertmanager/data/template/weixin.tmpl'
receivers:
- name: 'wechat'
wechat_configs:
- corp_id: 'wxa56e78f3d93f0ec6'
to_party: '7'
agent_id: '1000008'
api_secret: 'xxxxxx'
send_resolved: true
route:
group_wait: 10s
group_interval: 5m
repeat_interval: 3h
receiver: 'wechat'
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: prometheus
labels:
app.kubernetes.io/component: alertmanager
app.kubernetes.io/instance: prometheus
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: prometheus
helm.sh/chart: prometheus-0.1.3
name: prometheus-alertmanager由于Alertmanager有挂载到nfs,所以/bitnami/alertmanager/data/目录对应到nfs
在NFS服务端操作
cd /data/nfs2/default-data-bitnami-prometheus-alertmanager-0-pvc-47ca7949-a84b-4d72-bdff-f9380f4f2fa1/template
vi weixin.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********告警通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 -}}
**********恢复通知**********
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
{{- end }}
=====================
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.description }}
故障时间: {{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
恢复时间: {{ $alert.EndsAt.Format "2006-01-02 15:04:05" }}
{{ if gt (len $alert.Labels.instance) 0 -}}故障实例: {{ $alert.Labels.instance }}{{- end -}}
{{- end }}
{{- end }}
{{- end }}