StarRocks简介
- StarRocks(前身为Doris)是新一代极速全场景MPP数据库
- StarRocks高效支持实时数据分析
- 用户可使用StarRocks构建大宽表、星型模型、雪花模型等多种模型
- 快速上手,兼容MySQL Protocol,对现有研发人员非常友好
注:MPP数据库:Massively Parallel Processing 大规模并行处理数据库。通俗来讲:MPP是将任务并行分散到多个服务器和节点上,在每个节点计算完成后,将各自部分的结果汇总在一起得到最终结果
系统架构
:StarRocks系统架构非常简洁,仅有FE(Frontend)与BE(Backend)两类进程。并且这两类模块都可以在线水平扩容
系统架构图

FE(Frontend)
:FE是StarRocks的前端节点,负责管理元数据,管理客户端连接,进行查询规划与查询调度等工作。FE有三种角色:Leader FE,Follower FE,Observer FE。
其中只有Leader FE拥有元数据写操作
BE(Backend)
:BE是StarRocks的后端节点,主要负责数据存储、SQL执行等操作
数据管理
:StarRocks采用列式存储,利用分区分桶机制来进行数据管理。表可按照时间来进行分区,粒度可分为一天或一周。分区内可根据列进行分桶,将数据切割成多个Tablet。下图为数据存储概念图

快速开始
理解数据模型
:建表时,需要指定数据模型(Data Model),这样数据导入至数据模型时,StarRocks会按照排序键对数据进行排序、处理和存储。
注:在明细模型、聚和模型和更新模型中,排序列就是通过各自模型关键字指定的列。从StarRocks 3.0版本起,主键模型解耦了主键列和排序列,排序列通过ORDER BY关键字指定,主键列通过PRIMARY KEY关键字指定
排序键
:数据导入至使用某个数据模型的表时,会按照建表时指定的一列或者多列排序后存储,这部分用于排序的列就称为排序键。
明细模型
:明细模型是默认的建表模型。明细模型适用于日志数据分析等场景,支持追加数据,不支持修改数据,同时数据按照排序键 DUPLICATE KEY 排序,同时排序键不受唯一性约束
CREATE TABLE IF NOT EXISTS detail (
event_time DATETIME NOT NULL COMMENT "datetime of event",
event_type INT NOT NULL COMMENT "type of event",
user_id INT COMMENT "id of user",
device_code INT COMMENT "device code",
channel INT COMMENT ""
)
DUPLICATE KEY(event_time, event_type)
DISTRIBUTED BY HASH(user_id)
PROPERTIES (
"replication_num" = "3"
);
使用说明
-
在建表语句中,排序键必须要定义在其他列之前
-
排序键可以通过 DUPLICATE KEY 显式定义,本文中的排序键为event_time 和 event_type
注:如果未指定排序键,则默认选择表的前三列作为排序键
-
明细模型中排序键可以为部分或者全部维度列
聚和模型
:聚和模型支持定义排序键与指标列,同时为指标列指定聚和函数。当多条数据有相同的排序键时,聚和模型会对指标列使用指定聚和函数进行聚和。通常适用于分析统计与汇总数据
CREATE TABLE IF NOT EXISTS example_db.aggregate_tbl (
site_id LARGEINT NOT NULL COMMENT "id of site",
date DATE NOT NULL COMMENT "time of event",
city_code VARCHAR(20) COMMENT "city_code of user",
pv BIGINT SUM DEFAULT "0" COMMENT "total page views"
)
AGGREGATE KEY(site_id, date, city_code)
DISTRIBUTED BY HASH(site_id)
PROPERTIES (
"replication_num" = "3"
);
使用说明
- 在建表语句中,排序键必须定义在其他列之前
- 排序键可以通过 AGGREGATE KEY显式定义
- 如果 AGGREGATE KEY,未包含全部维度列,即:除指标列之外的列。则会建表失败
- 如果不通过 AGGREGATE KEY 显式定义,则会默认除指标列之外的列均为排序键
- 排序键必须满足唯一性约束,通过列值不会更新
- 通过在列名后指定聚和函数,定义该列为指标列。
更新模型
:更新模型支持定义主键与指标列,查询时返回主键相同数据中的最新数据。更新模型可以视为聚和模型的特殊情况,指标列指定的聚和函数为REPLACE。更新模型适用于支持实时和频繁更新的场景
CREATE TABLE IF NOT EXISTS orders (
create_time DATE NOT NULL COMMENT "create time of an order",
order_id BIGINT NOT NULL COMMENT "id of an order",
order_state INT COMMENT "state of an order",
total_price BIGINT COMMENT "price of an order"
)
UNIQUE KEY(create_time, order_id)
DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"replication_num" = "3"
);
使用说明
- 在建表语句中,主键必须定义在其他列之前
- 主键通过 UNIQUE KEY定义
- 主键必须满足唯一性约束,同时列值不支持修改
主键模型
:主键模型支持分别定义主键和排序键。数据导入后先按照排序键排序后存储。查询时返回主键相同的一组数据中的最新数据。主键模型主要支持实时和频繁等场景的同时,提供高效查询。
原理与区别
:主键模型与更新模型的区别主要在于,主键模型查询时不需要做聚合REPLACE操作。其原理主要是由于主键模型采取的Delete + Insert策略。
该策略主要实现方式
- StarRocks收到更新指令时,会通过主键找到该条记录的位置,并对其标记为删除,再插入
- StarRocks收到删除指令时,同样通过主键找到该条记录位置,对其标记为删除
create table orders (
dt date NOT NULL,
order_id bigint NOT NULL,
user_id int NOT NULL,
merchant_id int NOT NULL,
good_id int NOT NULL,
good_name string NOT NULL,
price int NOT NULL,
cnt int NOT NULL,
revenue int NOT NULL,
state tinyint NOT NULL
) PRIMARY KEY (dt, order_id)
PARTITION BY RANGE(`dt`) (
PARTITION p20210820 VALUES [('2021-08-20'), ('2021-08-21')),
PARTITION p20210821 VALUES [('2021-08-21'), ('2021-08-22')),
PARTITION p20210929 VALUES [('2021-09-29'), ('2021-09-30')),
PARTITION p20210930 VALUES [('2021-09-30'), ('2021-10-01'))
) DISTRIBUTED BY HASH(order_id)
PROPERTIES (
"replication_num" = "3",
"enable_persistent_index" = "true"
);
使用说明
- 建表语句中,主键必须定义在其他列之前
- 主键要通过 PRIMARY KEY定义
- 主键必须满足唯一性约束,同时不会被修改
- 分区列、分区桶必须在主键中
数据分布
:建表时,需要通过PARITION BY & DISTRIBUTED BY来设置分区和分桶。
常见的数据分布方式
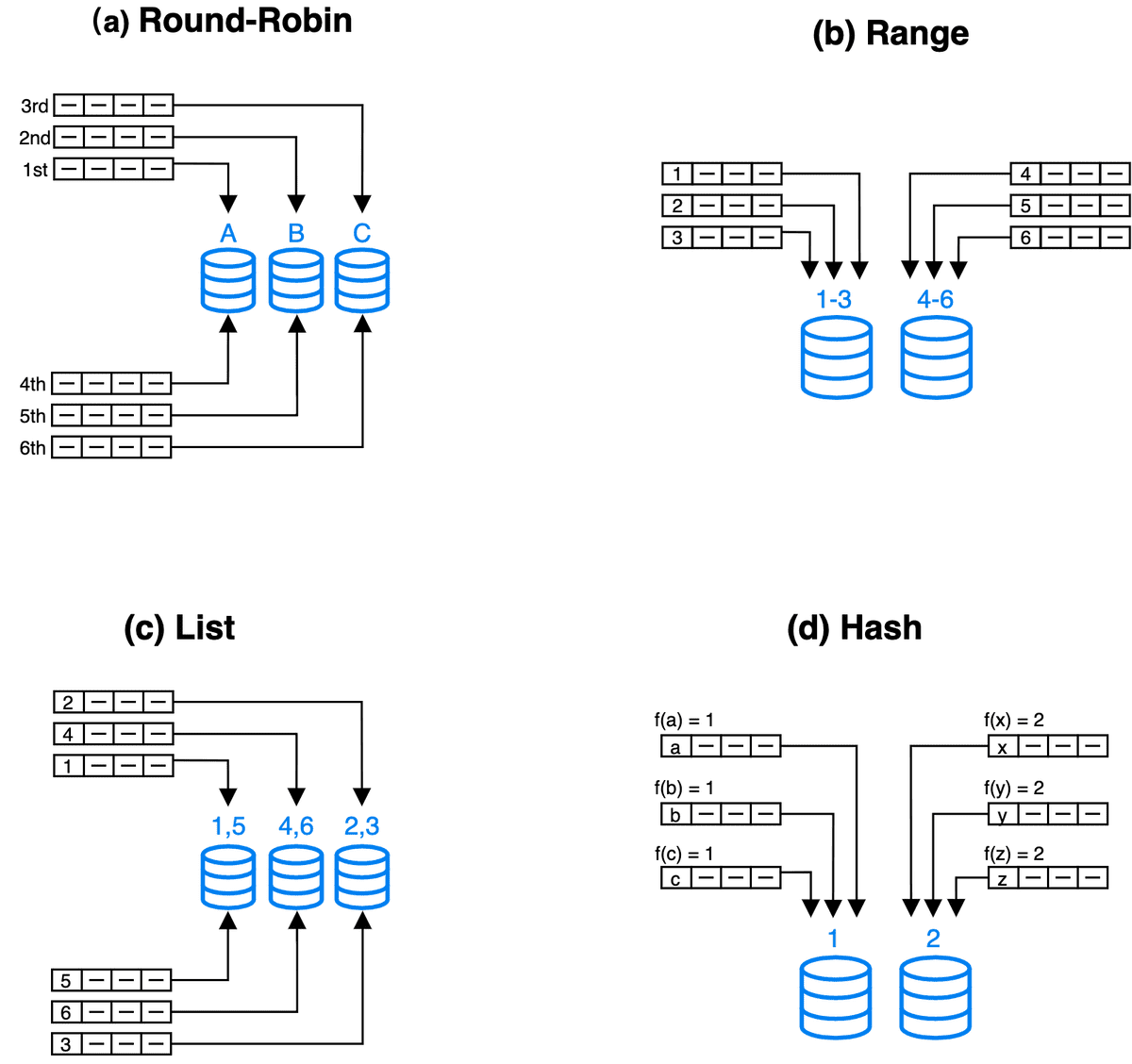
- Round-Robin:以轮询的方式把数据逐个放置在相邻节点
- Range:按规定区间进行数据分布
- List;基于离散数值进行数据分布
- Hash:通过哈希函数进行数据分布
StarRocks的数据分布方式
- Hash数据分布方式:一张表为一个分区,分桶根据Hash函数进行数据划分
- Range+Hash数据分布方式:一张表通过RANGE规定区间后拆分为多个分区,每个分区中的分桶按照Hash函数进行划分
上手使用
:StarRocks前端交互采用了MySql协议,因此研发人员无需再学习SQL语法。同时只需通过配置多数据源即可使用
配置多数据源
spring.datasource.dynamic.datasource.#{多数据源名称}.url=jdbc:mysql:loadbalance://#{数据库链接地址,可连接多个地址,用逗号隔开}/#{数据库名}?useUnicode=true&characterEncoding=UTF8&useSSL=true&serverTimezone=Asia/Shanghai
spring.datasource.dynamic.datasource.#{多数据源名称}.username=#{数据库名}
spring.datasource.dynamic.datasource.#{多数据源名称}.password=#{密文}
spring.datasource.dynamic.datasource.#{多数据源名称}.public-key=#{解密私钥}
注意:由于要定义多个数据源,所以在SpringBoot数据源自动配置类中无法确定导入哪个数据源来进行初始化,因此我们需要禁掉Spring Boot的数据源自动配置类
注解方式
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
配置文件方式
spring.autoconfigure.exclude=com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
使用多数据源
注解方式
// 在使用多数据源的类或者方法上,使用该注解
// package com.baomidou.dynamic.datasource.annotation 包下注解
@DS(value = #{多数据源名称})
例:@DS(value = "StarRocks")
硬编码方式
参考:https://blog.csdn.net/qq_45515182/article/details/126330084
注:推荐使用注解方式