| 软件工程 | ?https://edu.cnblogs.com/campus/gdgy/CSGrade21-34 |
|---|---|
| 作业要求 | ?https://edu.cnblogs.com/campus/gdgy/CSGrade21-34/homework/13023 |
| GitHub链接 | ?https://github.com/Rfdfz/3121005133 |
| 作业目标 | 设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率 |
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| · Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 106 | 132 |
| · Analysis | 需求分析 (包括学习新技术) | 5 | 20 |
| · Design Spec | 生成设计文档 | 15 | 5 |
| · Design Review | 设计复审 | 3 | 3 |
| · Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 3 | 3 |
| · Design | 具体设计 | 10 | 8 |
| · Coding | 具体编码 | 40 | 30 |
| · Code Review | 代码复审 | 5 | 3 |
| · Test | 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 18 | 73 |
| · Test Report | 测试报告 | 5 | 60 |
| · Size Measurement | 计算工作量 | 3 | 3 |
| · Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 134 | 215 |
需求分析
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
- 原文示例:今天是星期天,天气晴,今天晚上我要去看电影。
- 抄袭版示例:今天是周天,天气晴朗,我晚上要去看电影。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
我们提供一份样例,课堂上下发,上传到班级群,使用方法是:orig.txt是原文,其他orig_add.txt等均为抄袭版论文。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
本次个人项目题目是论文查重系统,该任务是一个典型的自然语言处理任务,根据题目的需求,有两种实现的方法:
- 经典算法:设定一个阈值,使用经典字符串匹配算法进行匹配,若两篇文章中出现一处超过该阈值的子串,则记为一出重复,然而这种方法无法从语义上判断两篇文章是否重复
- 数据挖掘算法:通过某种算法,将两篇高本的文章映射到同一个低维空间中,再通过距离度量两篇文章的相似性
本次项目选择了第二种实现方式,因为这种实现方式考虑到了文章本身的语义,使用的是python3.8,使用到了numpy、scikit-learn、jieba这三个第三方库,实现的流程如下
-
Tokenize:首先需要将一篇文章分成一个一个token(词元:是处理文本的最小单位),我们通过
jieba库进行分词,实现该过程 -
Vectorize:接着通过TF-IDF算法将两篇高维文本映射到低维空间,我们通过
scikit-learn库中的TfidfVectorizer类来实现 -
计算相似度:通过余弦距离或欧几里得距离公式计算两个文本间的相似性,作为重复度
接口设计
本项目中一共设计了一个Tokenizer类和三个功能函数,分别对应文件读取模块、计算相似度模块和文件写入模块,其中Tokenizer类用于构建一个Tokenizer对象,用于实现对于文本的词元化操作,
文件读取模块
def read_file(orig_path, orig_modify_path):
try:
with open(orig_path) as f1, open(orig_modify_path) as f2:
orig_string = f1.read()
orig_modify_string = f2.read()
except FileNotFoundError as e:
print('请输入正确的文件路径:', e)
return FileNotFoundError
else:
return orig_string, orig_modify_string
通过主函数传入的orig_path原始文件路径以及orig_modify_path被修改后文件的路径,来进行文件的读取,其中捕获了由于路径错误导致的异常,这一部分将在单元测试篇章详细讲解
计算相似度模块
def cal_similarity(orig_string, orig_modify_string, similarity_type):
# Tokenize
tokenizer = Tokenizer()
orig_list, orig_modify_list = tokenizer(orig_string), tokenizer(orig_modify_string)
# Vectorize
try:
vectorizer = TfidfVectorizer()
feature = vectorizer.fit_transform([orig_list, orig_modify_list]).toarray()
except ValueError as e:
print('请输入正确的文本:', e)
return ValueError
else:
try:
if similarity_type not in ['cosine_similarity', 'euclidean_distance']:
raise ValueError
except ValueError:
print("请输入正确的相似度类型")
return ValueError
else:
if similarity_type == 'cosine_similarity':
similarity = feature[0] @ feature[1].T / (np.linalg.norm(feature[0]) * np.linalg.norm(feature[1]))
return similarity
elif similarity_type == 'euclidean_distance':
similarity = 1 / (1 + np.exp(-np.linalg.norm(feature[1] - feature[0])))
return similarity
本部分通过实例化Tokenizer对象将两个文本进行词元化,得到两组文本的tokens,接着通过实例化的vectorizer将文本映射到同一个空间中,最后使用距离公式计算距离即可得到相似度
文件写入模块
def save_answer(answer_path, similarity):
try:
if not isinstance(similarity, float):
raise TypeError
elif similarity > 1.0 or similarity < 0:
raise ValueError
except TypeError:
print("相似度类型错误")
return TypeError
except ValueError:
print("相似度计算错误")
return ValueError
# 保存答案
with open(answer_path, mode='w') as f:
f.write("%.2f" % similarity)
该模块在将传入的相似度进行检查后,写入本地相应路径的文件中
性能分析以及覆盖率测试
性能分析
以下Pycharm以Profile模式运行时生成的性能分析图
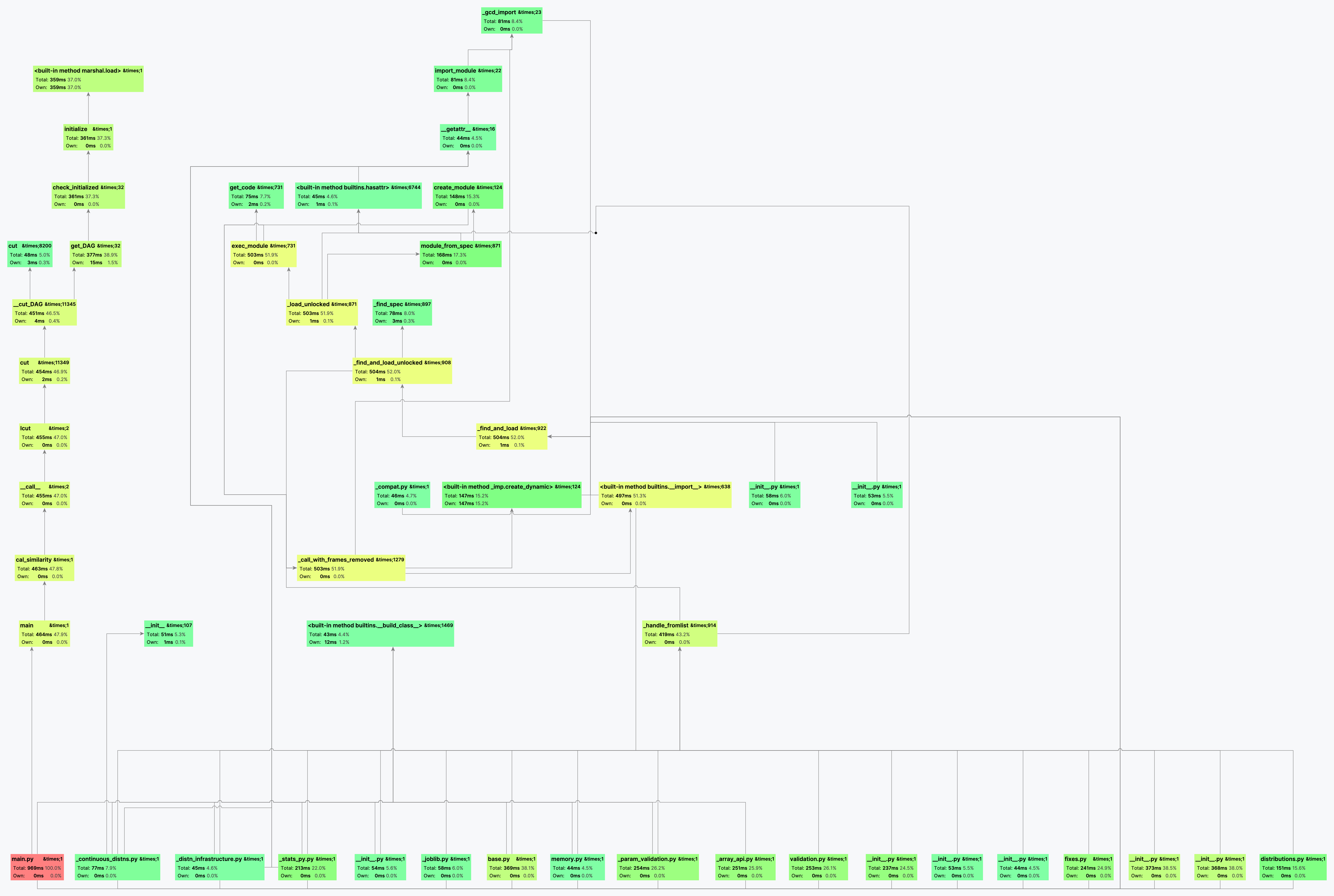
观察该图左下角,main()函数一共执行了464ms,而其中的cal_similarity()函数就执行了463ms,而其中用于分词而调用的jieba.lcut()函数由于其需要调用其语料库进行分词,因此耗时最长455ms,占整个main()函数执行时间的98%、整个程序执行时间的47%,而且该部分无法优化
覆盖率测试
| Name | Stmts | Miss | Cover |
|---|---|---|---|
| main.py | 94 | 35 | 63% |
覆盖率达到了63%,未运行到的行都是用于异常处理,因此程序的效率达到了最高
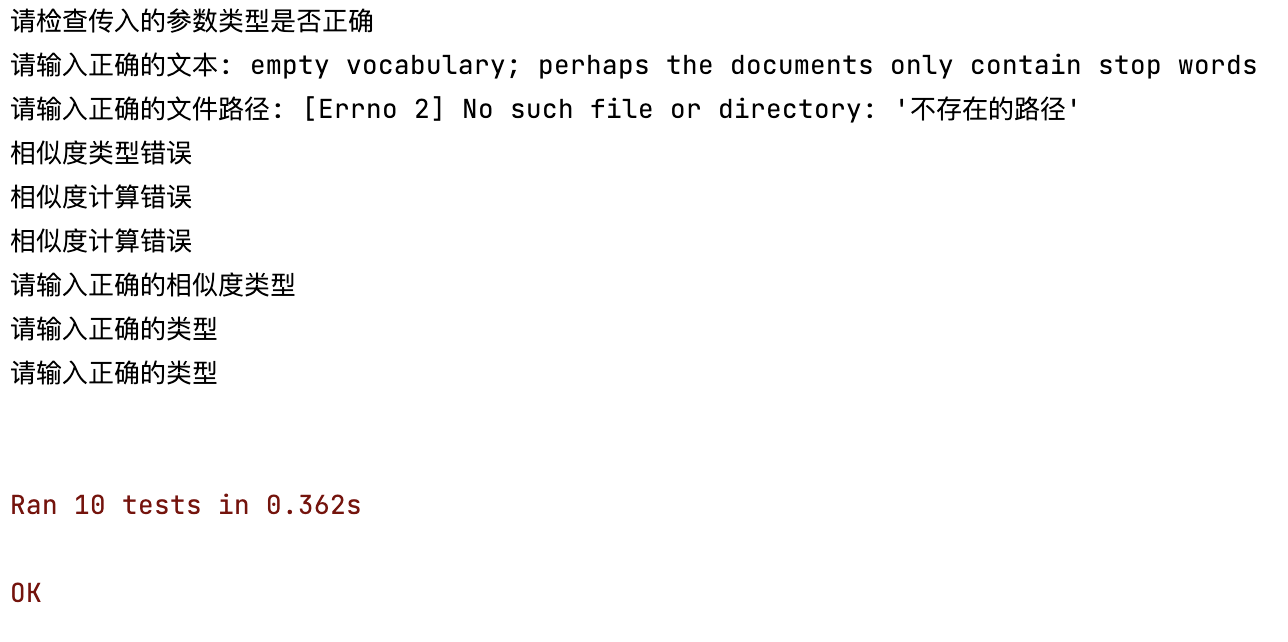
单元测试以及异常处理
本程序一共设置了以下 10 个单元测试,使用python内置库unittest进行,其中包括边界条件的测试以及错误输入的测试
test_same_steingtest_empty_stringtest_read_filetest_args_pasertest_tokenizertest_tokenizer_add_extra_punctuationtest_save_file_similarity_typetest_save_file_similarity_value_positivetest_save_file_similarity_value_negativetest_similarity_type
test_same_string
本测试随机生成了长为 1000 的字符串,然后将该字符串作为orig_string和orig_modify_string传入cal_similarity()函数中,理论的正确结果应该是1.0,代码如下:
def test_same_string(self):
characters = string.ascii_letters + string.digits
random_string = ''.join(random.choice(characters) for _ in range(1000))
self.assertEqual(cal_similarity(random_string, random_string, 'cosine_similarity'), 1.0)
test_empty_string
本测试向cal_similarity()函数中传入两个空字符串,在cal_similarity()中我们通过捕获异常ValueError并返回该异常,来进行单元测试,因此该测试的结果应该为ValueError,并打印'请输入正确的文本',代码如下:
def test_empty_string(self):
empty_string = ''
self.assertEqual(cal_similarity(empty_string, empty_string, 'cosine_similarity'), ValueError)
test_read_file
本测试向read_file传入两个错误的路径,此时我们捕获异常FileNotFoundError,并打印'请输入正确的文件路径',代码如下:
def test_read_file(self):
self.assertEqual(read_file('不存在的路径', '不存在的路径'), FileNotFoundError)
test_args_paser
本测试不向程序传入参数,因此此时参数值为None,我们在paser解析参数后,判断参数的类型是否的字符串,若不是则抛出TypeError异常并将其捕获,打印'请传入正确参数',代码如下:
def test_args_paser(self):
self.assertEqual(main(), TypeError)
test_tokenizer
本测试向实例化后的Tokenizer传入一个整数1,然而tokenizer()应该接受的的参数是字符串,因此我们会判断输入的类型,若非字符串型,则会抛出一个TypeError异常并将其捕获,打印'请输入正确类型',代码如下:
def test_tokenizer(self):
tokenizer = Tokenizer()
self.assertEqual(tokenizer(1), TypeError)
test_tokenizer_add_extra_punctuation
本测试Tokenizer类的add_extra_punctuation方法,我们向该方法传入整数 1,然而该方法应该接受一个字符串,因此我们会判断输入的类型,若非字符串型,则会抛出一个TypeError异常并将其捕获,打印'请输入正确类型',代码如下:
def test_tokenizer_add_extra_punctuation(self):
tokenizer = Tokenizer()
self.assertEqual(tokenizer.add_extra_punctuation(1), TypeError)
test_save_file_similarity_type
本测试测试的是save_file函数的传入的similarity参数的类型,应该是浮点型,我们传入一个字符串,此时我们判断输入的类型,若非浮点型,则会抛出一个TypeError的异常并将其捕获,并打印'相似度类型错误',代码如下:
def test_save_file_similarity_type(self):
self.assertEqual(save_answer('Test.txt', 'Error Type'), TypeError)
test_save_file_similarity_value_positive
本测试测试的是save_file函数的传入的similarity参数的值,其取值区间应该是$[0.0, 1.0]$,我们传入浮点型10.0,此时我们判断输入的大小,若大于 1.0,则会抛出一个ValueError的异常并将其捕获,并打印'相似度计算错误',代码如下:
def test_save_file_similarity_value_positive(self):
self.assertEqual(save_answer('Test.txt', 10.0), ValueError)
test_save_file_similarity_value_negative
本测试测试的是save_file函数的传入的similarity参数的值,其取值区间应该是$[0.0, 1.0]$,我们传入浮点型-10.0,此时我们判断输入的大小,若大于 1.0,则会抛出一个ValueError的异常并将其捕获,并打印'相似度计算错误',代码如下:
def test_save_file_similarity_value_negative(self):
self.assertEqual(save_answer('Test.txt', -10.0), ValueError)
test_similarity_type
本测试测试的是输入cal_similarity的similarity_type参数,若输入一个不存在的度量,则会抛出ValueError异常并将其捕获,并打印'请输入正确的相似度类型',代码如下:
def test_similarity_type(self):
self.assertEqual(cal_similarity("Hello World", "Hello World", "earth_mover_distance"), ValueError)
测试结果
运行并通过了 10 个单元测试,花费了0.362s,