作业一:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接:https://gitee.com/li-zimusuidao/data-fusion
实验:
from selenium import webdriver
import time
import pymysql
class Spider():
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 1
# def initDriver(self):
# count = 1
driver = webdriver.Edge(executable_path='C:\Program Files (x86)\Microsoft\Edge\Application\msedgedriver.exe')
driver.get('http://quote.eastmoney.com/center/gridlist.html')
def getInfo(self):
print("Page", self.count)
self.count += 1
self.StockInfo()
try:
keyInput = self.driver.find_element_by_class_name("paginate_input")
keyInput.clear()
keyInput.send_keys(self.count)
# keyInput.send_keys(self.count.ENTER)
GoButton = self.driver.find_element_by_class_name("paginte_go")
GoButton.click()
time.sleep(3)
self.getInfo()
except:
print("err")
time.sleep(3)
self.getInfo()
def StockInfo(self):
odds = self.driver.find_elements_by_class_name("odd")
evens = self.driver.find_elements_by_class_name("even")
for i in range(len(odds)):
self.StockDetailInfo(odds[i])
self.StockDetailInfo(evens[i])
def StockDetailInfo(self, elem):
tds = elem.find_elements_by_tag_name("td")
count = tds[0].text
num = tds[1].text # 编号
name = tds[2].text # 名称
value = tds[4].text # 最新价
Quote_change = tds[5].text # 涨跌幅
Ups_and_downs = tds[6].text # 涨跌额
Volume = tds[7].text # 成交量
Turnover = tds[8].text # 成交额
amplitude = tds[9].text # 振幅
highest = tds[10].text # 最高
lowest = tds[11].text # 最低
today_begin = tds[12].text # 进开
last_day = tds[13].text # 昨收
# print(count,num,name,value,Quote_change,Ups_and_downs,Volume,Turnover,amplitude,highest,lowest,today_begin,last_day)
self.writeMySQL(count, num, name, value, Quote_change, Ups_and_downs, Volume, Turnover, amplitude, highest,
lowest, today_begin, last_day)
# for value in values:
# print(num,name,values[0].text,values[1].text)
def initDatabase(self):
try:
serverName = "127.0.0.1"
# userName = "sa"
passWord = "********"
self.con = pymysql.connect(host=serverName, port=3307, user="root", password=passWord, database="Stock",
charset="utf8")
self.cursor = self.con.cursor()
self.cursor.execute("use Stock")
print("init DB over")
self.cursor.execute("select * from stock")
except:
print("init err")
def writeMySQL(self, count, num, name, value, Quote_change, Ups_and_downs, Volume, Turnover, amplitude, highest,
lowest, today_begin, last_day):
try:
print(count, num, name, value, Quote_change, Ups_and_downs, Volume, Turnover, amplitude, highest, lowest,
today_begin, last_day)
self.cursor.execute(
"insert stock(count,num,name,value,Quote_change,Ups_and_downs,Volume,Turnover,amplitude,highest,lowest,today_begin,last_day) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(count, num, name, value, Quote_change, Ups_and_downs, Volume, Turnover, amplitude, highest, lowest,
today_begin, last_day))
self.con.commit()
except Exception as err:
print(err)
# self.opened = False
spider = Spider()
spider.initDatabase()
spider.getInfo()
结果:

心得体会:
本次实验我使用了Selenium框架+ MySQL数据库存储技术完成对Ajax网页数据与等待HTML元素的爬取,难点在于多页爬取。主要的解决方法是:一是查找数据接口,找到不同数据页面所需要的请求格式,二是使用selenium找到解析html源码,找到按钮标签。
作业二:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接:https://gitee.com/li-zimusuidao/data-fusion
实验:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def init(self):
print("初始化爬虫中......")
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.page = 0
self.no=0
try:
#与数据库建立连接
self.con = pymysql.connect(host="127.0.0.1", port=3306, user="root", passwd="a570846984", charset="utf8",
db="mydb")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table mooc")
except:
pass
try:
#建立数据表
sql = """create table mooc(Id varchar(8),cCource varchar(64),cCollege varchar(64),cTeacher varchar(64),
cTeam varchar(64),cCount varchar(64),cBrief varchar(256))ENGINE=InnoDB DEFAULT CHARSET=utf8"""
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
print("初始化完成,准备进行登录")
def login(self,account,password,loginurl):
print("登录中")
#获取登录页面
self.driver.get(loginurl)
#点击“以其他登录方式登录”按钮(否则要扫码登录)
self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div[2]/span").click()
#点击手机号登录按钮切换至手机号登录
self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div/div[1]/div/div[1]/div[1]/ul/li[2]").click()
#由于登录框是一个弹出窗口,需要切换frame,否则会找不到元素
self.driver.switch_to.frame(self.driver.find_element_by_xpath("/html/body/div[4]/div[2]/div/div/div/div/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe"))
#定位到输入账号的位置,输入账号
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input").send_keys(account)
#定位到输入密码的位置,输入密码
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]").send_keys(password)
#点击登录按钮
self.driver.find_element_by_xpath("/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a").click()
print("登录成功")
def choose(self,key,url):
#获取网页
print("正在搜索关键词{}......".format(key))
self.driver.get(url)
time.sleep(1)
#定位到搜索框,将关键词输入到搜索框
keyInput = self.driver.find_element_by_xpath("//div[@class='u-baseinputui']/input[@type='text']")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
time.sleep(2)
print("搜索完成,准备开始爬取")
def download(self):
try:
#统计爬取的当前页
self.page+=1
print("爬取第{}页".format(self.page))
#爬取的各个课程数据列表
datalist=self.driver.find_elements_by_xpath("//div[@class='cnt f-pr']")
time.sleep(2)
for data in datalist:
# 有些课程格式不符合规范,如没有开课学校的,使用except略过,否则会因为格式问题报错,影响爬取
try:
#待爬取的各项数据
cCource=data.find_element_by_xpath("./div[@class='t1 f-f0 f-cb first-row']").text
cCollege=data.find_element_by_xpath(".//a[@class='t21 f-fc9']").text
cTeacher=data.find_element_by_xpath(".//a[@class='f-fc9']").text
cTeam=data.find_element_by_xpath(".//a[@class='f-fc9']").text
cCount=data.find_element_by_xpath(".//span[@class='hot']").text
cBrief=data.find_element_by_xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']").text
#统计爬取的课程个数,用做序号数据项
self.no += 1
#将爬取的数据插入到mysql数据库中
self.cursor.execute("insert into mooc values(%s,%s,%s,%s,%s,%s,%s)",(self.no,
cCource,cCollege,cTeacher,cTeam,cCount,cBrief))
#提交到命令行执行
self.con.commit()
#简单记录爬取过程
print(cCource)
except:
pass
try:
#查找是否可以翻页,如果找到不可翻页标记则说明到了最后一页,程序结束,否则进入except
self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-disable-gh']")
print("爬取结束")
except:
#点击翻页,然后递归调用download
nextpage=self.driver.find_element_by_xpath("//li[@class='ux-pager_btn ux-pager_btn__next']/a[@class='th-bk-main-gh']")
nextpage.click()
time.sleep(3)
self.download()
except Exception as err:
print(err)
def prccess(self,url,loginurl):
self.init()
print("请输入账号:")
account = input()
print("请输入密码:")
passward = input()
self.login(account,passward,loginurl)
print("请输入要爬取的关键词:")
key=input()
self.choose(key,url)
self.download()
url="https://www.icourse163.org"
loginurl="https://www.icourse163.org/member/login.htm#/webLoginIndex"
spider=MySpider()
spider.prccess(url,loginurl)
结果:

心得体会:
本次实验我使用了Selenium框架+ MySQL数据库存储技术完成对mooc网课程资源信息的爬取,难点在于多页爬取。主要的解决方法是:一是查找数据接口,找到不同数据页面所需要的请求格式,二是使用selenium找到解析html源码,找到按钮标签。
作业三:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
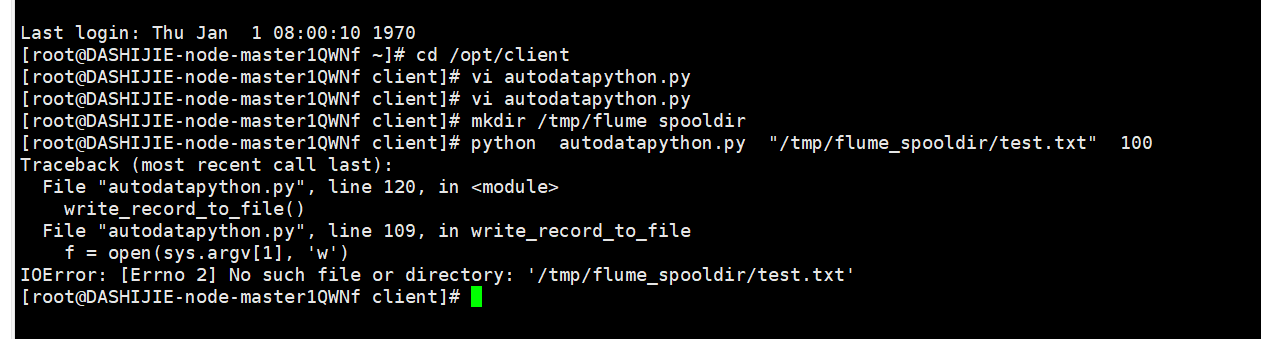
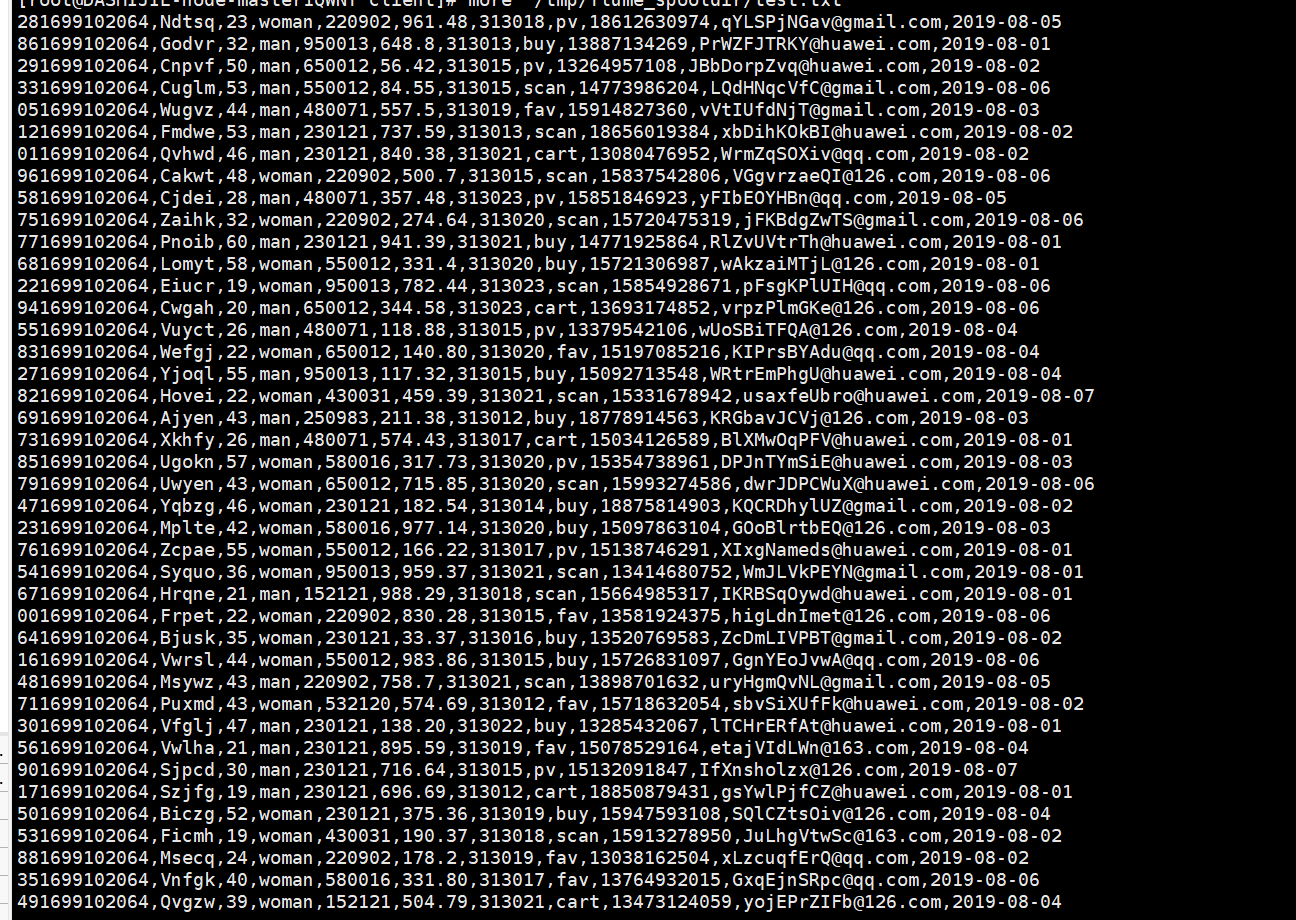
任务一:Python脚本生成测试数据
任务二:配置Kafka
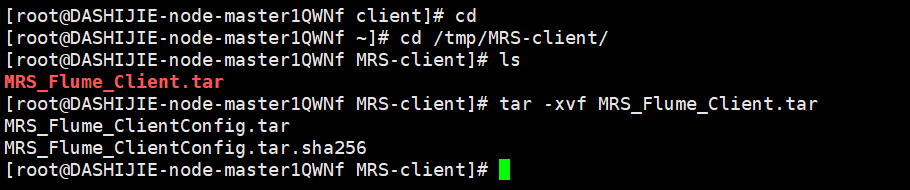
任务三: 安装Flume客户端
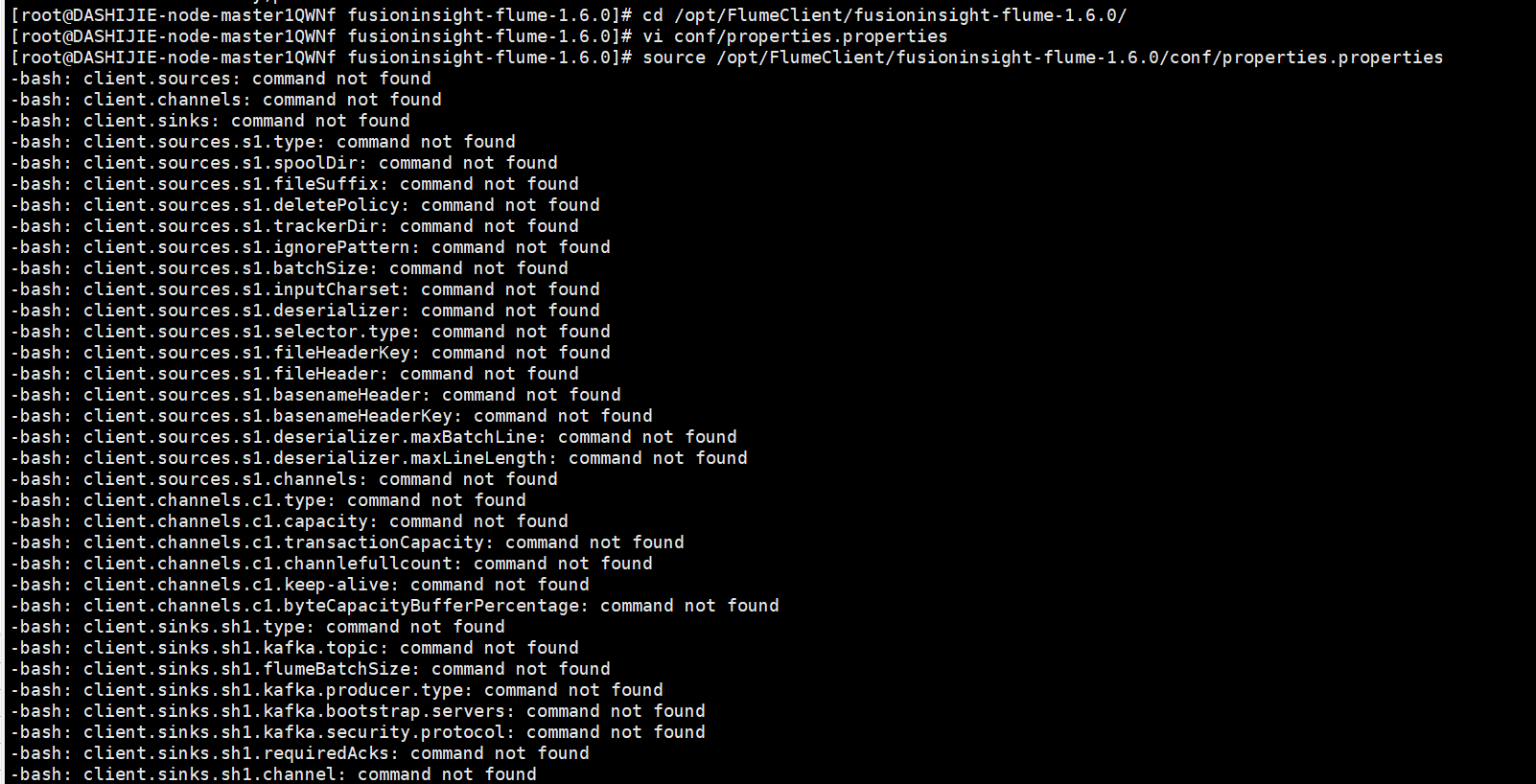
任务四:配置Flume采集数据
输出:实验关键步骤或结果截图。
结果:



心得体会:
本次任务开始非常困难,后来,经过一系列不断的调试之后,我的华为云平台的数据实践终于成功了。