import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except:
return " "
url = "http://www.baidu.com"
for i in range(20):
print("-------------{}------------".format(i+1))
print(getHTMLText(url))
from bs4 import BeautifulSoup
import re
soup=BeautifulSoup('''<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p id="first">我的第一个段落。</p>
</body>
<table border="1">
<tr>
<td>row 1, cell 1</td>
<td>row 1, cell 2</td>
</tr>
<tr>
<td>row 2, cell 1</td>
<td>row 2, cell 2</td>
</tr>
</table>
</html>''')
print("head标签:\n",soup.head,"\n学号后两位:21")
print("body标签:\n",soup.body)
print("id为first的标签对象:\n",soup.find_all(id="first"))
st=soup.text
pp = re.findall(u'[\u1100-\uFFFDh]+?',st)
print("html页面中的中文字符")
print(pp)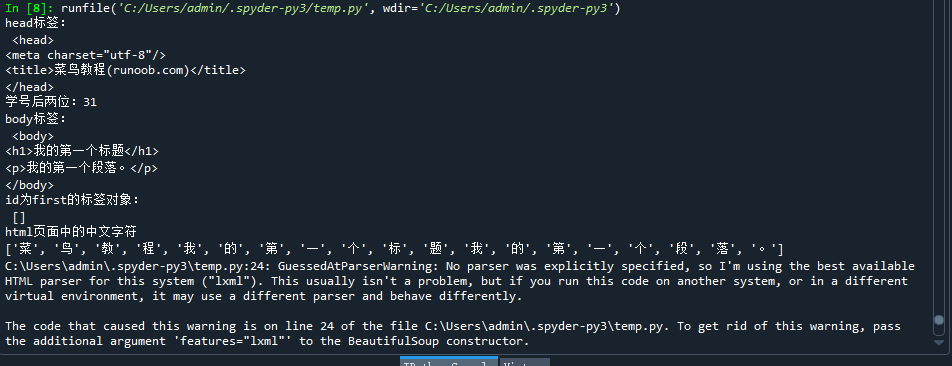
import csv
import os
import requests
from bs4 import BeautifulSoup
allUniv = []
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding ='utf-8'
return r.text
except:
return ""
def fillUnivList(soup):
data = soup.find_all('tr')
for tr in data:
ltd = tr.find_all('td')
if len(ltd)==0:
continue
singleUniv = []
for td in ltd:
singleUniv.append(td.string)
allUniv.append(singleUniv)
def writercsv(save_road,num,title):
if os.path.isfile(save_road):
with open(save_road,'a',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
for i in range(num):
u=allUniv[i]
csv_write.writerow(u)
else:
with open(save_road,'w',newline='')as f:
csv_write=csv.writer(f,dialect='excel')
csv_write.writerow(title)
for i in range(num):
u=allUniv[i]
csv_write.writerow(u)
title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模",
"科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化","学生国际化"]
save_road="E:\\排名.csv"
def main():
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2020.html'
html = getHTMLText(url)
soup = BeautifulSoup(html, "html.parser")
fillUnivList(soup)
writercsv(save_road,30,title)
main()