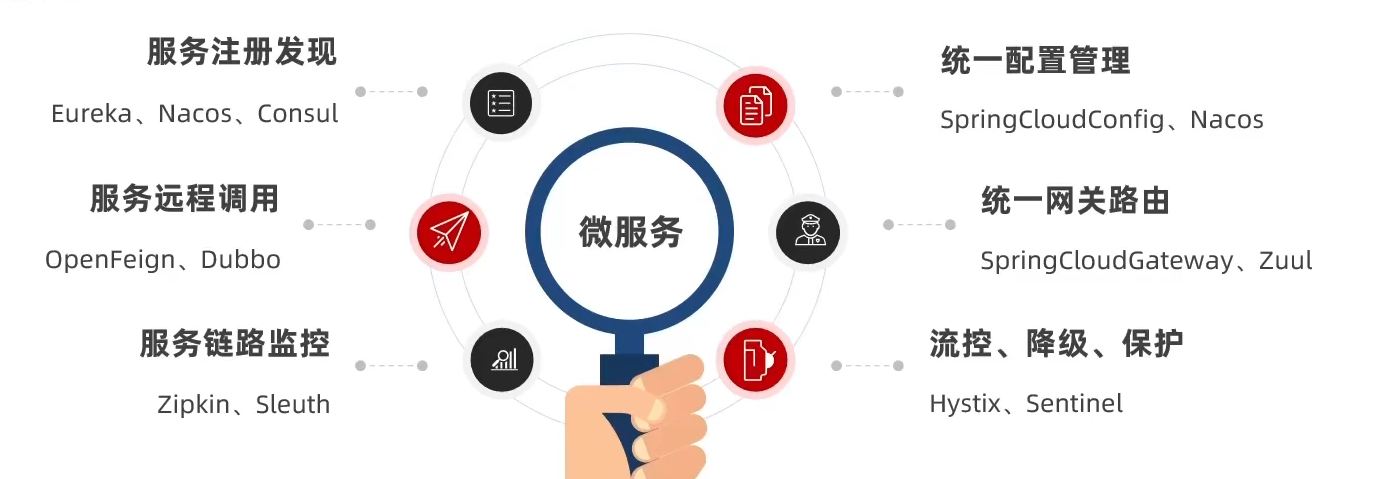
- 简介:

- 注册中心:记录各种服务的ip地址以及服务内容,当需要调用时就从这里取信息;
- 配置中心:对所有服务的配置文件进行统一管理,需要更改什么配置,就从配置中心发信息通知修改
- 服务网关:检测用户能否通行+告诉用户该访问哪一个服务
- 分布式搜索:对于海量信息的搜索分布式缓存也做不了,只能靠分布式搜索
- 消息队列:服务一调用服务二时,可以发送消息通知二,之后一就结束了,提高性能
- 分布式日志服务:记录所有服务的日志信息,方便定位错误
- 系统监控链路追踪:疾苦所有服务的运行状态,cpu使用率等,出现问题及时定位
- JenKins:进行服务的自动化部署
- docker:打包形成镜像并发送
- Kubernetes&RANCHER:持续化部署
- 技术分类总结:
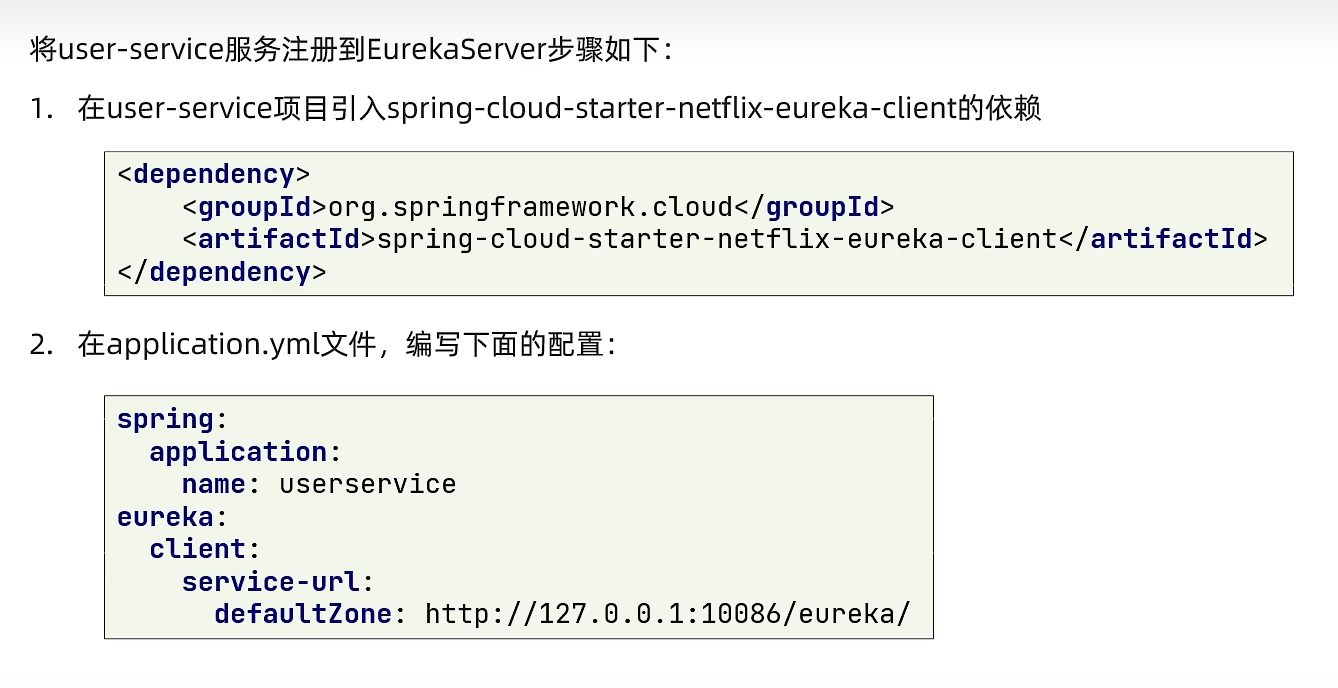
- 注册中心:记录各个服务的信息,每30s确认一遍是否更新(某个端口新增或消失),消费者从注册中心获取服务者的信息后采用负载均衡算法挑取一个实例进行使用
1. euraka

- 创建euraka注册中心:创建一个服务,在服务内部进行复杂配置(导入依赖,编写启动类,书写配置文件)
- 服务注册:每一个服务都要导入依赖+书写配置文件
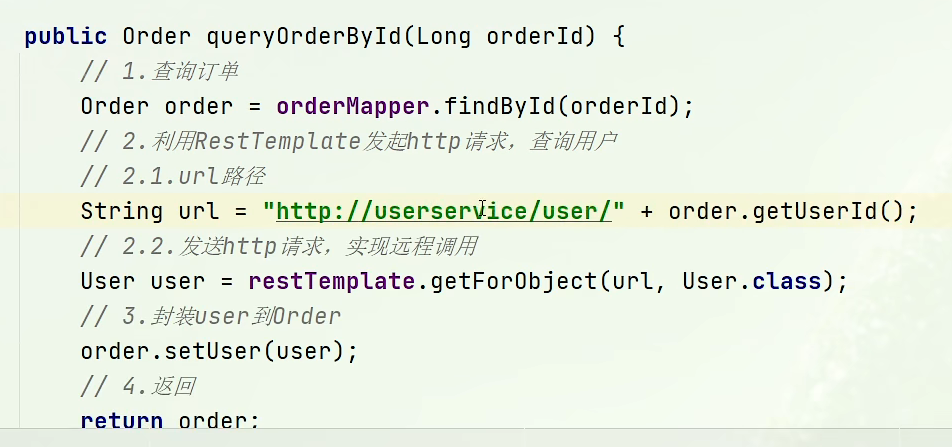
- 服务发现:在消费者配置类创建一个Bean ->RestTemplate,我们想办法在service中创建RestTemplate对象后,在方法中模仿浏览器访问url路径(路径不写端口,写该服务在euraka中的名称)
 、
、
- 请求转发:请求过来分析要转到什么服务去
- 负载均衡:请求转发过来的请求分析要转到这个服务的哪一个服务器去。默认是轮询算法,我们可以统一修改为其他算法(启动类),也可以在单独一个服务中修改本服务的负载均衡算法(yml)。可以选择开启饥饿加载(服务器启动时就加载)
- nacos(注册中心):
- 创建nacos启动中心:父工程配置文件,各个服务的配置文件和yml文件修改问nacos
- nacos集群:每一个服务都有多个实例,为了不让机房事故影响所有实例,一个机房是一个集群,一个集群可能包含多个服务的实例。可以在服务的yml文件中添加集群属性与负载均衡规则。对于一个集群下同一服务的不同实例的选择一般来说是轮询,我们也可以在nacos控制台调整权重。
- euraka和nacos的区别:
- nacos将实例分为临时施例和非临时实例,临时实例和eruaka一致,一旦不健康就剔除,非临时实例不健康后nacos会等待其变为健康。
- 相比较与euraka30s检测一次,nacos对于临时实例采用心跳检测,非临时实例采用主动检测。
- nacos(配置中心):将各个服务的核心配置文件放于nacos的配置文件中,当我们需要修改的时候就不用重启所有有关的服务,并且我们希望实现不重启就生效(热更新)。
- 配置管理服务:nacos控制台创建一个配置文件,为了让服务在启动时能够获得nacos地址,我们在服务内创建一个bootstrap.yml文件获取nacos配置文件的地址,获取nacos配置文件后与本地服务的配置文件合并作为配置文件。
- 热更新的实现:建议采用@ConfigrationProperties注解,将此注解写在需要被获取的配置类上方。
- nacos环境:有时候我们开发,测试算做两个不同的环境,我们可以将其隔离。可以实现多环境间的数据共享。nacos控制台创建usrservice.yml书写共享的配置
- nacos作为配置中心介意将配置文件都卸载nacos上,命名空间下建配置文件,每个配置文件有组。cloud程序中用bootstrap配置一下让程序读取nacos配置中心配置的就行了。
- feign:解决服务内部的调用问题。为了代码中不出现url,代替RestTemplate使用(有时候一些操作是联动的,需要调用多个module实现)
 @EnableFeifnClient
@EnableFeifnClient
- 简单使用:引入依赖,调用端写注解,定义一个接口,方法定义仿照controller定义,在service需要发送url请求的时候/需要调用的此方法的时候自动装配此接口调用这个方法即可。
- 性能优化:为了让fergn支持连接池导入httpclient依赖,yml中配置一下参数就可以了
- 最佳实践:
1. 因为我们定义的新接口是仿照controller写的,所以直接可以定义一个父接口,使得新接口与controller都继承他,但是这样会造成紧耦合。
2. 新创建一个module作为api,书写所有的公共部分(client,config,各种实体类),使得单一服务(module)内只有与自身相关的代码,之后再导入依赖就可以使用了。由于自动装配的是别的module内的bean,我们需要在消费者的启动类的EnableFeignClient注解添加一些参数。

- GateWay网关:拦截通过固定端口的请求,实现路由(分析响应应该转到哪一个服务)与负载均衡
- 创建:新建module,导入依赖,写yml配置文件实现路由与负载均衡。
- 断言:可以用来判断请求是否符合规范(路径,时间等是否符合规规范)(配置文件中)
- 过滤器:对请求和响应做各种各样的处理(配置文件中)也有全局过滤器
- docker:每个应用都需要不同的函数库与依赖,docker讲这些应用及其所需要的函数库和依赖打包成一个镜像放到容器中,每个容器都认为自己是计算机内的唯一进程,容器间隔离。
1. dockerHub
- 使用:docker安装在CentOs上,需要安装镜像时,我们要去DockerHub网站搜索镜像并在终端输入命令进行安装,要熟悉部分docker命令的使用。安装后要进行容器的部署,部署命令要dockerHub内查找相应镜像源找到run命令
- 数据卷:我们对于容器内文件的修改很不方便,修改也无法同步到其他容器内,因此我们创建了数据卷,将容器内某个文件映射到容器外,这样方便我们进行修改文件。数据卷的创建与容器的部署同步:
docker run --name name(容器名称) -p 80:80 -v name(数据卷名称,这个地方也可以写数据卷的地址):/usr/share/nginx/html(文件在容器内的实际位置,在dockerHub上找) -d nginx
2. 构建别人的镜像:
- 将DockerFile导入到linux内,执行命令即可 docker build -t name:tag . (空格加点)
3. dockerCompose,集群化部署各种镜像:就是把原本的docker run命令改成指令运行,要提前安装dockerCompose。
- MQ:
- 同步消息:(打电话)消息传递后发送方等待响应。
- 异步消息:(发微信)消息传递后发送方服务结束,事件代理负责发送消息。
- RabbitMQ:负责消息的发送与接收
1. 基本消息队列:发送方——>队列——>一个消费者
2. 工作消息队列:发送方——>队列——>多个消费者
. Application.yml文件中配置Prefetch属性进行控制两个消费者对于消息的分配
3. 发布订阅:发送方——>交换机——>队列——>消费者
. 交换机和队列是多对多
. Fanout:将交换机接收到的所有消息都发送到与其绑定的队列
. Direct:根据key来判别消息应该如何发送到队列
. Topic:与Direct相似,只是支持通配符,可以进行模糊的匹配
"#"匹配零个或多个单词,"*"匹配一个单词。
- 消息转换器:我么发送的消息是Object类型,但是如果消息不是String类型,就需要在发送这和消费者同时配置消息转换器进行消息的序列化和反序列化。
- ElasticSearch:分布式搜索。
- 为什么快:mysql是正排索引,模糊搜索的时候需要逐条搜索关键字,找到主键再取通过主键取数据。而es是倒排索引,形成表的时候,拆分词条作为主键,这样就可以直接进行匹配。
- 概念对比:

- mapping约束:

- 操作索引库:
1. 创建:(可以添加all字段方便查询) 2. 查询和删除:


3. 无法修改库,只能新增字段

- 操作文档:
1. 新增: 2. 查询(根据id)和删除:

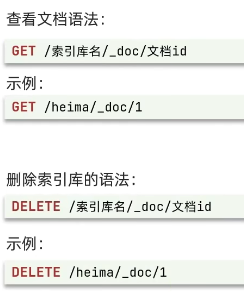
3. 修改:(全量,id不存在自动新增) (增量,只修改部分量)


- ES的查询功能:
。全文查询:

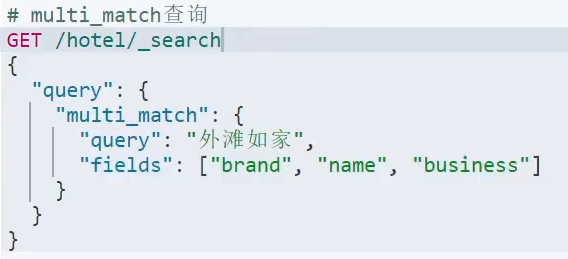
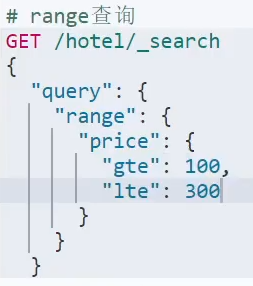
。范围查询: 。精确查询:

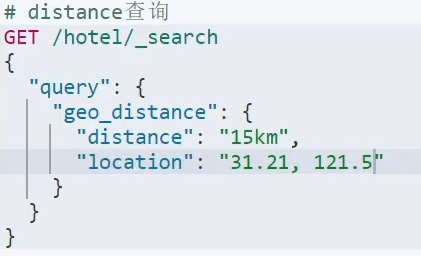
。地理查询:
。相关性算分:根据搜索关键字按照TF—IDF或者BM25公式计算相关性分数
。FunctionScoreQuery:按照需求修改相关性算分并重新排序
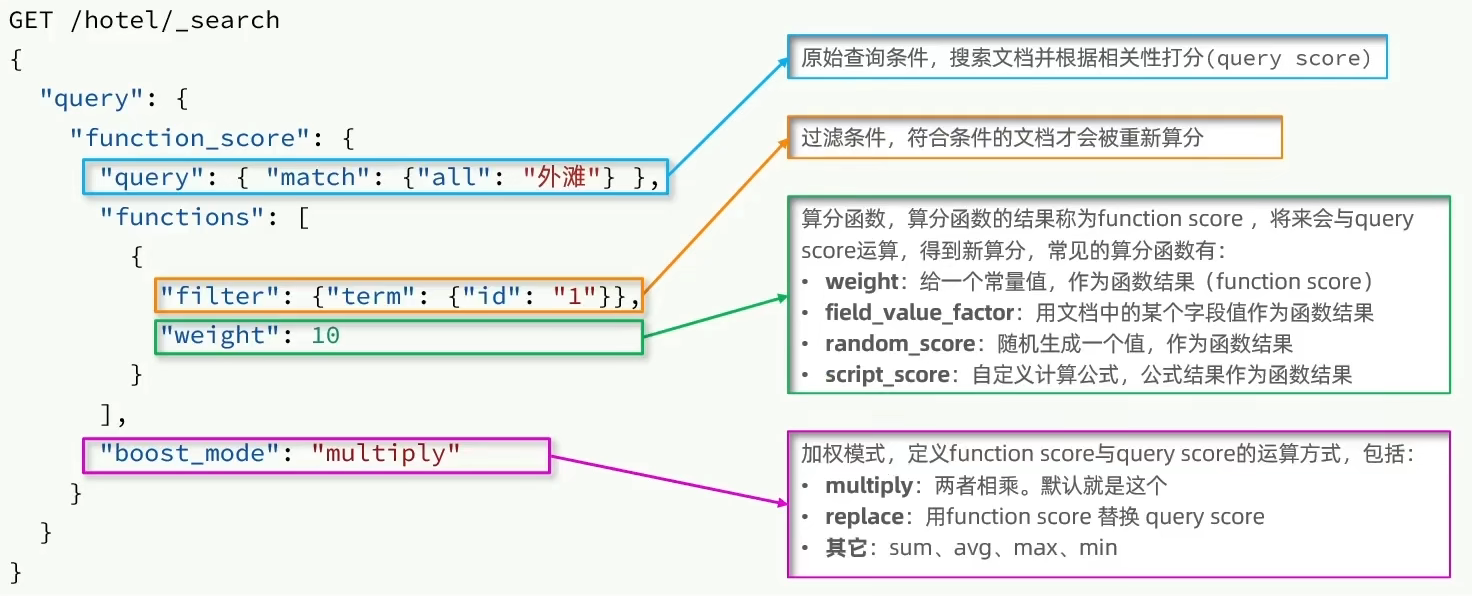
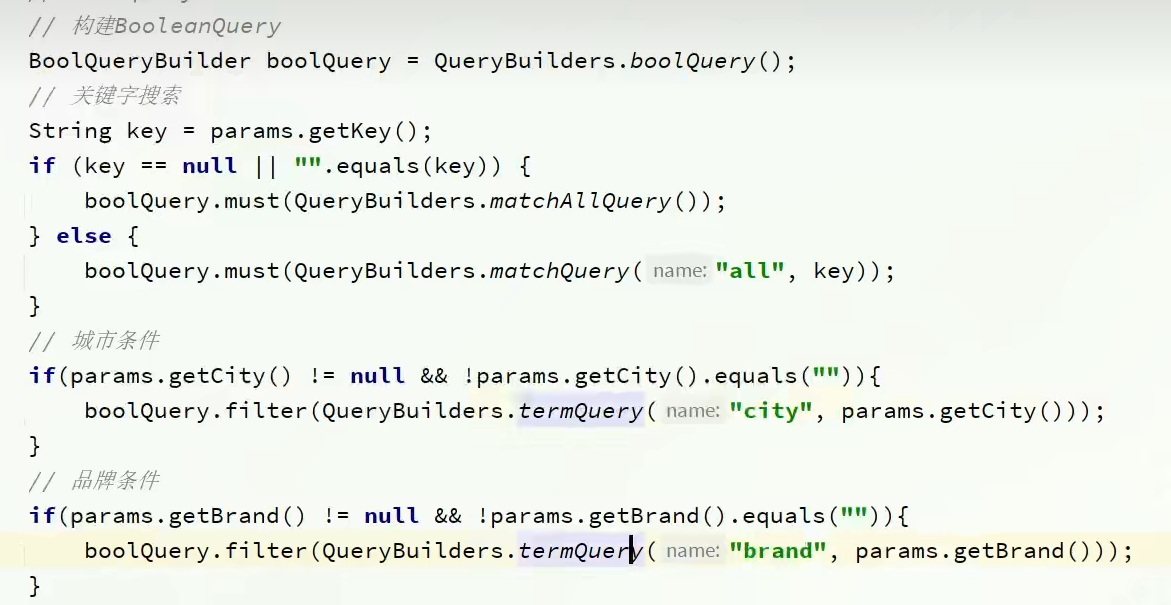
。BooleanQuery:复合查询,关键的使用must。其余都用filter


。搜索结果排序:


。搜索结果分页:
普通分页:
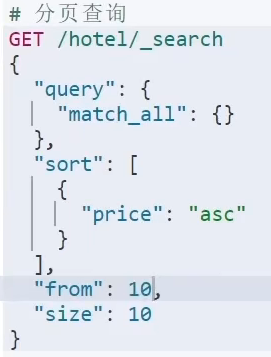
after-search分页:没有查询上限,但是不能随机翻页,适合滚动反页
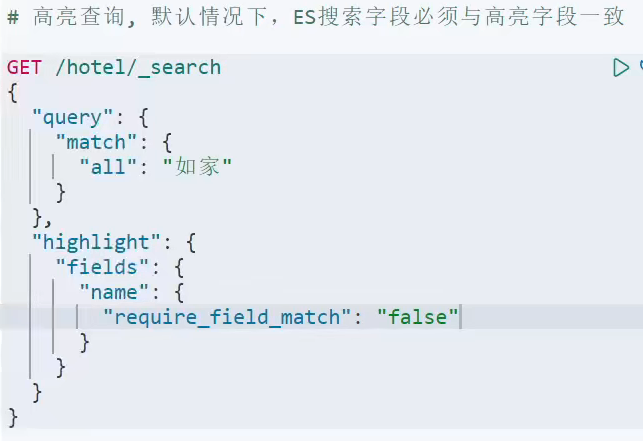
。搜索结果高亮:
可以在fields里面添加多个需要拥有高亮的字段
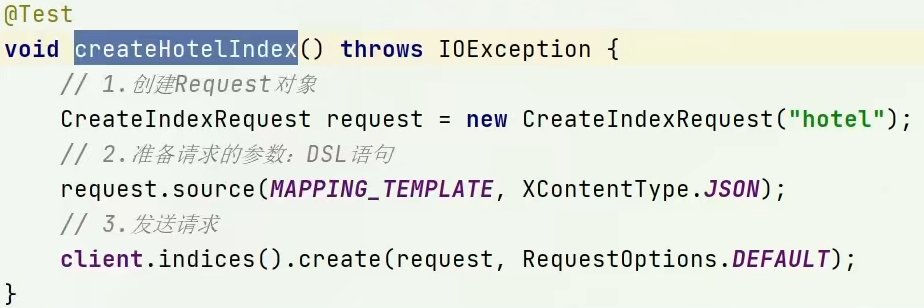
- RestClient操作索引库
导入依赖,初始化RestClient,编写创建删除查询函数操作索引库。
。创建:
。删除:

。查询:

- RestClient操作文档:
。批量新增:
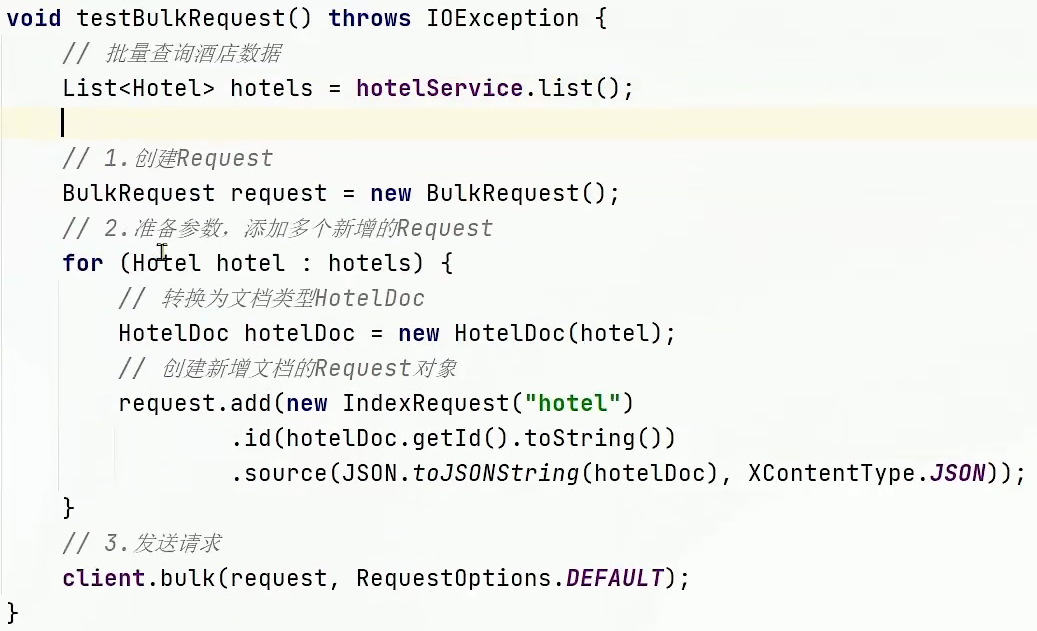
。删除:

。更新:

。查询:
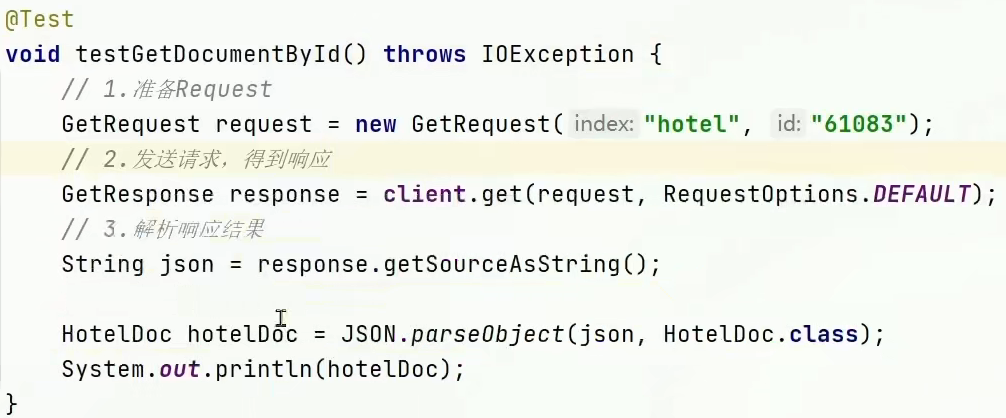
- RestClient实现查询功能:
。 各种查询只需要修改query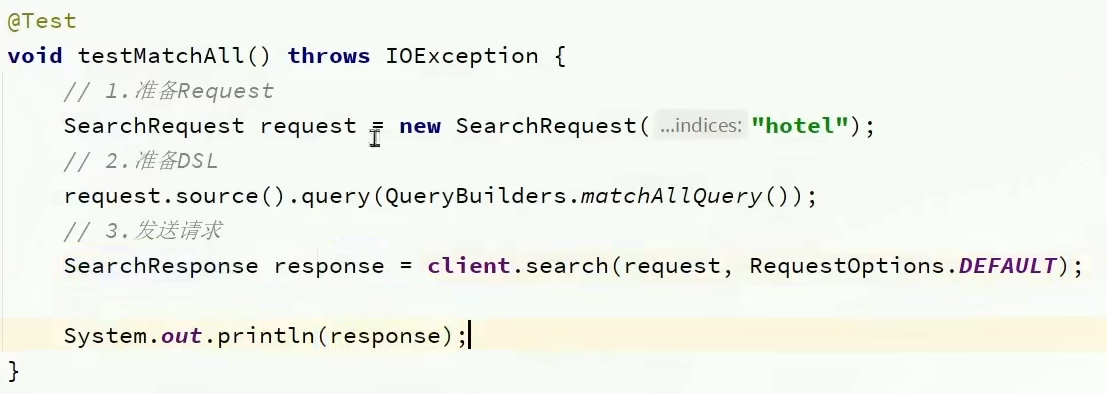


查询结果操作需要request.source()后面跟相应操作即可
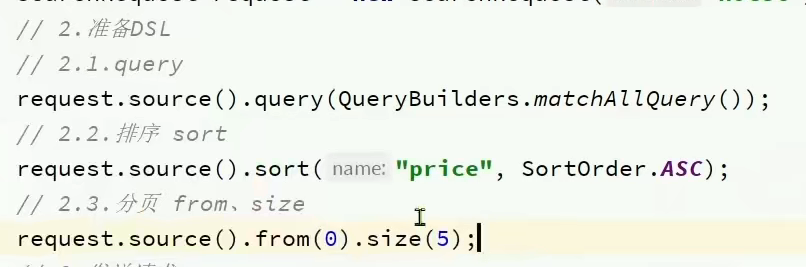


BooleanQuery:修改request.source().query(修改此处)
FunctionScoreQuery:修改request.source().query(修改此处)

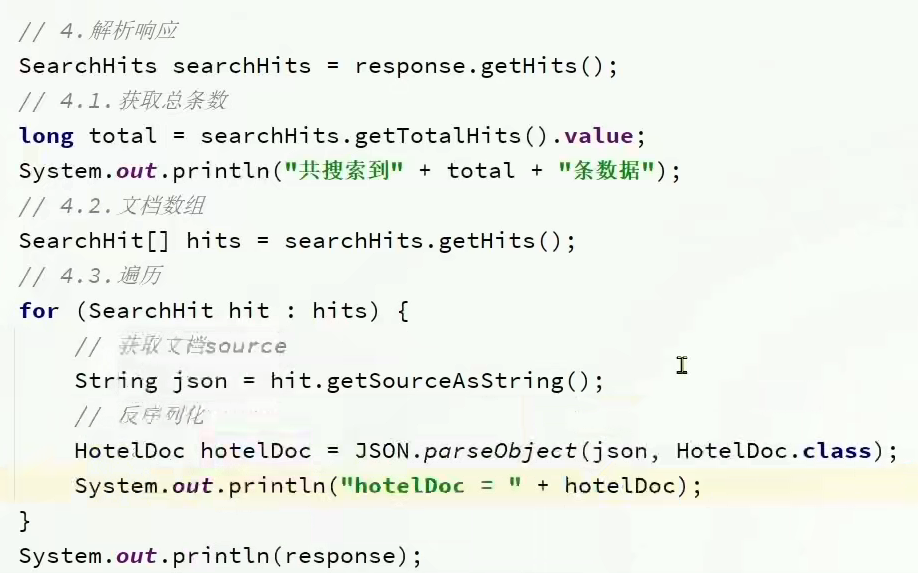
解析查询结果
- 数据聚合
。聚合分类: 
。Bucket聚合:(指定范围内进行分类) 。Metric聚合:(分类后再对每个类的分数做最大最小平均等分析)


。RestClient实现聚合:

